
摘要:恶意移动应用通过动态代码加载等手段绕过移动应用市场安全审核,对终端用户造成威胁。为了实现对这些应用进行事后审计,提出一种基于自然语言处理(NLP)的恶意应用检测模型。通过搜集、处理移动应用市场中用户对应用的评论数据,建立恶意分类检测模型。通过对评论数据的处理分类,判断应用是否存在恶意行为,以此对移动应用进行事后安全检查。实验结果表明,建立的恶意应用检测模型准确率达到81%,可以有效识别恶意移动应用。
0 引 言
随着移动智能终端的普及,移动应用日益增多,移动终端遭受恶意应用的攻击和威胁也日趋增长。恶意扣费、窃取隐私类病毒等对手机用户产生了恶劣的影响,虽然应用分发渠道对应用进行了安全审核,但是恶意应用可以通过动态类加载等技术绕过应用商店或者防病毒引擎的安全检查[1]。
目前,有很多研究工作关注于恶意移动应用程序检测[2-6]。杨欢等[7]采用动静态结合的方法提取能够反映恶意应用行为的组件,函数调用和系统调用类特征构建最优分类器评判Android应用的恶意行为。Gorla等[8]对应用进行聚类,并分析同类应用中API调用异常的应用,寻找潜在的恶意应用。张家旺等[9]提出对APK文件提取权限特征、DVM API调用序列特征以及native程序的OpCodes特征进行N-gram建模,并使用机器学习进行恶意应用检测。这些检测方法都直接以安卓移动应用为检测目标,并没有针对用户评论数据进行深入研究。
在评论数据分析方面,有研究工作探索移动应用属性和行为之间的差异。WHYPER[10]和AutoCog[11]基于用户对应用行为的认知,建立应用描述和其敏感权限之间的映射关系。还有相关工作基于Lin等人[12]提出的众包研究技术展开[13-14],通过静态分析研究敏感权限的使用及其使用意图,研究用户对不同的<应用,权限,意图>组合的评分,为应用提取多维度特征构建特征向量,并对数据集进行预处理,使用机器学习技术建立准确的隐私评级预测模型,评判应用是否存在严重的风险。
本文以一种以用户评论数据为基础,建立了一种恶意应用检测模型,自动化检测应用存在的安全威胁。目前,大部分应用市场都提供接口供用户提交针对应用的评论。用户评论数据可分为功能、性能、用户体验等几个方面。当然,用户也可以通过此渠道发布应用的安全问题评论。通过对这些评论数据进行分析,可以获取用户所观察到的这些应用在运行中的安全问题。
鉴于应用的用户评论数据是一类非结构化、非标准化的数据,为了对其进行分类,使用自然语言处理工具和分类器对其进行处理(如图1所示),最终获取用户对应用安全方面的评价。为实现准确的恶意应用检测模型对数据集进行预处理,提取特征向量,使用机器学习技术建立准确的恶意应用检测模型。
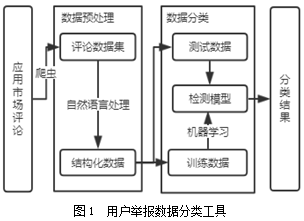
1 系统概述
为对用户评论数据分类,发现恶意应用,设计系统对用户评论数据进行评价。系统包括评论数据获取、评论数据预处理和评论数据分类三个模块。评论数据获取模块通过爬虫获取各类原始样本。预处理模块使用自然语言处理工具,对评论数据进行分词、停用词去除、词频分析等工作,最终形成结构化数据用来构建模型。
2 过程实现
2.1 评论数据获取
为获取用户评论数据,分析移动应用市场评论数据接口,实时抓取评论数据。考虑到这些市场中的正例样本数量有限,从移动病毒分析报告、贴吧等渠道获取更多的正例样本用来训练模型。为对评论数据进行监控、分析,设计针对GooglePlay、百度应用市场等在内的11个移动应用市场的评论数据爬取工具。
2.2 评论数据预处理
评论数据预处理即对评论数据进行过滤筛选,如限定语言、对文本分词、去掉停用词等,然后将文本用模型表示进行特征提取,获取最终的数据集。
2.2.1 定义标签
为了标注这些评论数据,首先参照移动互联网恶意代码描述规范[15]中的定义,将标签分为恶意扣费、隐私窃取、恶意传播、诱骗欺诈、流氓行为五类,如表1所示。

为了实现对数据的分类与验证,需要提前(手动)获得训练的语料库,为此将数据分配给两个组分别进行标签标记,应用Cohen’s kappa[16]系数对标签进行评估,初步确立数据集。
2.2.2 语言限定
由于数据的来源不仅仅是国内的应用市场,因此数据集中还存在非中文文本,所以需要对数据集进行语言检测。
从自然语言处理的角度分析,进行语言检测实际上是对文本从语言角度进行分类,为此选择采用langdetect[17]工具。langdetect基于N-Gram模型,通过设置有关语言概率的先验信息,初始化语言概率图,再从目标文本中提取相关的N-grams,使用N-grams字符串 更新语言概率,对概率进行归一化处理,返回最大概率的语言名称。
2.2.3 文本分词
由于中文文本没有像英文单词空格那样隔开,因此不能直接像英文一样直接用最简单的空格和标点符号完成分词。于是,本文采用jieba[18]分词算法来实现分词。
jieba分词工具实现文本分词的过程分为三步。(1)通过自带的词典生成trie树。字典在生成树的同时,把每个词的出现次数转换成频率,根据trie树对中文文本根据给定的词典进行查词操作,生成几种可能的句子切分。(2)查找带划分句子中已经切分好的词语,对该词语查找出现的频率,根据动态规划查找最大概率路径的方法,对句子从右往左反向计算最大概率(由于中文文本的主干在后面,因此从右往左的正确率较高)得到最大概率的切分组合。(3)使用HMM模型对未在词典中的词语进行识别,如进行地名、人名等未登录名词的识别,重新计算最佳切分路径。
在使用jieba分词精确模式后,能获得较理想的分词结果。
2.2.4 去除停用词
文本中会存在诸如“啊”“这”等停用词,这类停用词对文本分析没有任何贡献度,因此通过引入停用词表将它们从文本中删除。
2.2.5 词频分析
使用的模型是Gerard Salton和McGill[19]提出的向量空间模型。向量空间模型的基本思想是把文档简化为以特征项的权重为分量的向量表示(W1,W2,W3,…,Wn) ,其中Wi 为第i 个特征项的权重,选取词作为特征项。
这里采用TF-IDF算法[20]。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率高,且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF算法如下:
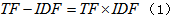
式中TF 表示词频,IDF 表示逆文档频率。将数据集构建一个词向量空间,在这个空间中储存每个词的权重数据,确立文本与标签的映射关系,获得最终实验数据集。
2.3 分类方法
评论数据预处理后得到的数据集,用来构造并训练检测模型,最后用检测模型对新数据进行分类和检测。测试不同机器学习分类器的性能,包括朴素贝叶斯、逻辑回归、支持向量机和决策树。
在机器学习中,朴素贝叶斯分类器是一类简单的概率分类器。它基于贝叶斯定理,在特征之间具有很强的独立性假设。逻辑回归对于训练集,利用回归分析研究文本特征和其所属类别之间的关联,预测文本的所属类别。SVM是具有相关学习算法的监督学习模型,将训练数据集生成推断函数,该函数可用于对新实例进行分类。决策树基于特征属性分类,算法包括ID3与C4.5。
在比较四种模型的性能后,选择最优分类器作为恶意应用检测模型。
3 实验环境
本文设计的检测方法全部使用Python语言能实现,涉及到的工具有jieba和scikit-learn,共搜集到20万条评论数据存储在MongoDB数据库中。物理主机为8 GB内存,处理器为i7-7700,开发环境为64位Win10系统。
4 实验结果
为了保证实验的可靠性和准确性,共计20万条评论数据来源于Google Play市场中各种不同类别的应用。其中,使用80%的样本进行训练,20%的样本作为测试集。
样本基于人工分析和数据处理后,通过四种模型进行训练与测试。实验结果如表2所示,可看出五种类别在每个模型中检测的精确度和四种模型的精确度。
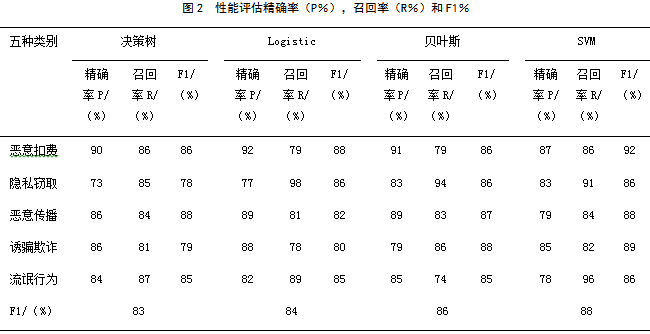
本文提出的恶意应用检测方法从检测指标来看,具有很好的表现,SVM模型相比于其他三种有较好的分类效果。之后的工作中,将选择SVM模型作为恶意应用检测模型。
5 案例分析
为了验证基于评论数据的恶意移动应用检测方法的有效性,对其有效性进行测试。通过从百度手机助手和贴吧等渠道爬取用户评论,发现了11款恶意应用。图2为用户对一款名为温控拜拜的应用(表3为该应用的基本信息)提出安全方面的讨论。
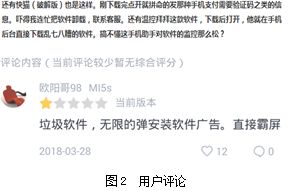

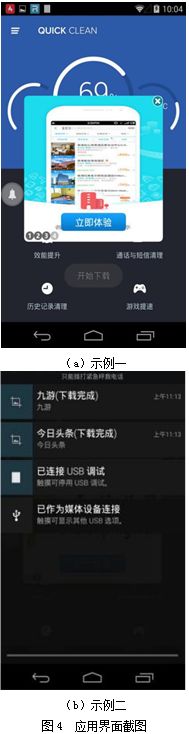
评论数据检测模型将该评论判定为“流氓行为”,对应的应用存在恶意行为。实际测试表明,该应用运行后会自动弹出广告,并且自动下载应用,随后通过virustotal[21]和Janus[22]对该病毒进行了确认,如图4所示。
6 结 语
本文介绍了一种基于自然语言处理的通过用户评论发现恶意应用行为的方法,通过对应用评论进行文本分类,从而确定应用是否存在恶意行为。对获取到的数据按照移动互联网恶意代码描述规范的标准进行类别划分,尝试使用四种分类模型训练数据,获取较高精准度的检测模型,进而实现从用户评论层面检测包含恶意行为的移动应用。
参考文献:
[1] Sebastian P,Yanick F,Antonio B,et al.Analyzing Unsafe and Malicious Dynamic Code Loading in Android Applications[Z].NDSS,2014.
[2] Dong-uk K,Jeongtae K,Sehun K.A Malicious Application Detection Framework using Automatic Feature Extraction Tool on Android Market[C].3rd International Conference on Computer Science and Information Technology,2013.
[3] Sen C,Minhui X,Zhushou T,et al.StormDroid:A Streaminglized Machine Learning-Based System for Detecting Android Malware[C].AsiaCCS,2016:377-388.
[4] 熊皓,陈杰,江坤航.一种基于行为分析的Android系统恶意程序检测模型[J].湖北理工学院学报,2015,31(03):42-46.
[5] 张金鑫,杨晓辉.基于权限分析的Android应用程序检测系统[J].技术研究,2014,7(06):30-34.
[6] 吴敬征,武延军,武志飞等.基于有向信息流的Android隐私泄漏类恶意应用检测方法[J].中国科学院大学学报,2015,32(06):807-815.
[7] 杨欢,张玉清,胡予濮等.基于多类特征的Android应用恶意行为检测系统[J].计算机学报,2014,37(01):15-27.
[8] Gorla A,Tavecchia I,Gross F,et al.Checking APP Behavior against APP Descriptions[C].Proceedings of the 36th International Conference on Software Engineering,2014:1025-1035.
[9] 张家旺,李燕伟.基于机器学习算法的Android恶意程序1774-检测系统[J].计算机应用研究,2017,34(06):1774-1782.
[10]Pandita R,XIAO Xu-sheng,YANG Wei,et al.WHYPER:Towards Automating Risk Assessment of Mobile Applications[C].Proceedings of the 22nd USENIX Security Symposium,2013:527-542.
[11]QU Zheng-yang,Rastogi V,ZHANG Xin-yi,et al.AutoCog:Measuring the Description-to-Permission Fidelity in Android Applications[C].Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security,2014:1354-1365.
[12]Gorla A,Tavecchia I,Gross F,et al.Checking APP Behavior against App Descriptions[C].Proceedings of the 36th International Conference on Software Engineering,2014:1025-1035.
[13]张贤贤,王浩宇,郭耀等.基于众包和机器学习的移动应用隐私评级研究[J].计算机科学与探索,2018,12(08):1238-1251.
[14]LIN Jia-liu,Amini S,Hong J I,et al.Expectation and Purpose:Understanding Users Mental Models of Mobile APP Privacy Through Crowdsourcing[C].Proceedings of the 2012 ACM Conference on Ubiquitous Computing,2012:501-510.
[15]中华人民共和国工业和信息化部.移动互联网恶意代码描述规范[EB/OL].(2011-05-14)[2018-09-01].https://wenku.baidu.com/view/2978e18ccc22bcd126ff0c90.html.
[16]Wikipedia contributors.Cohen"s kappa.[EB/OL].(2005-04-06)[2018-09-15]https://en.wikipedia.org/wiki/Cohen%27s_kappa.
[17]Michal Mimino Danilak.langdetect.[EB/OL].(2014-05-14)[2018-09-15].https://github.com/Mimino666/langdetect.
[18]SUN Jun-yi.Jieba[EB/OL].(2012-11-06)[2018-09-15].https://github.com/fxsjy/jieba.
[19]Gerard S,Mcgill M J.Introduction to Modern Information Retrieval[Z].1986.
[20]Wikipedia Contributors.Tf-idf[EB/OL].(2005-06-16)[2018-09-15].https://en.wikipedia.org/wiki/Tf%E2%80%93idf.
[21]Hispasec Sistemas.VirusTotal[EB/OL].(2004-06-10)[2018-09-15].https://www.virustotal.com/#/home/upload.
[22]犇众信息.Janus[EB/OL].(2017-05-26)[2018-09-15].https://appscan.io.
Benzhong Information.Janus[EB/OL].(2017-05-26)[2018-09-15].https://appscan.io.
作者简介:
朱璋颖,上海犇众信息技术有限公司,上海电机学院,学士,主要研究方向为软件工程;
马 永,上海犇众信息技术有限公司,学士,主要研究方向为软件工程;
燕锦华,华东计算技术研究所,硕士,主要研究方向为软件工程、测试验证;
吴振宇,华东计算技术研究所,硕士,主要研究方向为软件工程、功能安全;
徐文博,上海犇众信息技术有限公司,学士,主要研究方向为移动安全数据分析。
(本文选自《通信技术》2019年第二期)
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
