英伟达又出 GAN 新研究了。小编拿出珍藏猫片试了试,于是好好的一篇新研究报道变成了大型吸猫现场……快来吸猫!
借助图像数据集,无监督图像到图像转换方法可以将给定类的图像映射到另一类的模拟图像,例如 CycleGAN 将马转换为斑马。虽然这种模型非常成功,但在训练时需要大量源类和目标类的图像,也就是说需要大量马和斑马的图像。而这样训练出来的模型只能转换斑马与马,作者认为这极大限制了这些方法的应用。
因为人类能够从少量样本中抓住新事物的本质,并「想象」出它们在不同情况下的状态。作者从中获得启发,探索一种 few-shot 无监督的图像到图像迁移算法,这种算法适用于测试时仅由少量样本图像指定的以前没见过的目标类。
通过对抗训练方案和新网络设计的结合,该模型能够实现 few-shot 图像生成。此外,在经过大量实验验证以及与基准数据集上的几种基线方法比较后,作者证实了所提出框架的有效性。
试用效果
既然效果这么棒,小编忍不住拿出了家崽的百天照试试效果。
Demo 试用地址:https://nvlabs.github.io/FUNIT/petswap.html
下面这张照片展示了我家小溪溪的日常——丧。(微笑脸)

我把这张照片上传到 demo 页面,经过后台系统的一系列神操作之后,嗯,我看到了一堆丧丧的动物。(苦笑脸)

第 2 张的小狗狗是溪溪的犬版吗?表情一毛一样!我的天呐~
再试一下,下面这张照片也是溪溪的经典表情——严肃脸,严肃中带着一点惊讶,惊讶中还有一点彷徨……(此处省略表情描述 500 字)。

嗯哼,系统生成的图如下,一堆目瞪口呆.jpg。宝宝们为啥不开心呀?

突然想起来,溪溪还有一张 wink 照呢,老母亲私以为神似刘昊然(请迷妹们不要打我)……

不知道是不是因为背景太复杂(溪溪害羞钻进了被子里),生成的图效果似乎不太好。看第 15 张,小猫有一只眼完全闭上了,但是溪溪可没有闭眼哦。不过溪溪小警长的小白爪在生成的每张图中都有体现,虽然看不太出是爪子还是耳朵还是别的什么……

图像到图像的转换到底怎么了?
上面英伟达的 FUNIT 已经非常强了,那么一般的图像转换又有什么问题呢?说到图像到图像的转换(image-to-image translation),我们最熟悉的可能就是 CycleGAN,它可以将某种图像转换为另一种,例如将马转换为斑马。

这样看起来非常有意思,但却有一个很大的限制。如果我们希望完成马和斑马之间的转换,那么要弄一堆马的照片和一堆斑马的照片,再训练 CycleGAN 模型就能获得两类图像之间的转换关系。虽然马和斑马之间的图像不需要成对匹配,但这样是不是还有一些复杂?感觉不能像人那样自由「想象」?
其实人类拥有出色的泛化能力,当看到从未见过的动物照片时,我们可以轻易想象出该动物不同姿态的样子,尤其是当我们还记得该姿态下的其它动物长什么样子。这是一种很强的泛化能力,那么机器学习也能做到这一点吗?
虽然当前无监督图像到图像转换算法在很多方面都非常成功,尤其是跨图像类别的复杂外观转换,但根据先验知识从新一类少量样本中进行泛化的能力依然无法做到。具体来说,如果模型需要在某些类别上执行图像转换,那么这些算法需要所有类别的大量图像作为训练集。也就是说,它们不支持 few-shot 泛化。
虽然无监督图像到图像方法取得了显著成功,但总体而言有以下两方面的限制:
其一,这些方法通常需要在训练时看到目标类的大量图像;
其二,用于一个转换任务的训练模型在测试时无法应用于另一个转换任务。
为了解决这些限制,作为缩小人类和机器想象能力之间差距的一种尝试,英伟达的研究者提出一种 Few-shot 无监督图像到图像转换(FUNIT)框架。该框架旨在学习一种新颖的图像到图像转换模型,从而利用目标类的少量图像将源类图像映射到目标类图像。也就是说,该模型在训练阶段从未看过目标类图像,却被要求在测试时生成一些目标类图像。
为了更好地理解这种新颖的图像转换,作者在下图展示了动物面部的 few-shot 转换结果:

如上所示,其中 y_1 和 y_2 是测试阶段可用的目标类 few-shot 样本图像、x 是源类输入图像,而 x bar 就是源类到目标类的转换结果了。我们可以看出来,x 和 x bar 之间的「神态」都非常相似。
英伟达的 Few-Shot 解决方案
接着,研究者假设人们的 few-shot 生成能力是由过去的视觉体验发展而来—如果一个人过去看过很多不同对象类的图像,则能够更好地想象出新对象类的图像。基于此假设,他们使用包含众多不同对象类图像的数据集来训练 FUNIT 数据集,以模拟过去的视觉体验。具体来说,他们训练该模型,从而将其中一类的图像转换为另一类(利用该类的少量样本图像)。
他们假设通过学习提取用于转换任务的少量样本图像的外观模式,该模型得到了一个可泛化的外观模式提取器,在测试时,该提取器可以在 few-shot 图像到图像转换任务中应用于未见过类别的图像。
在实验部分,他们给出了实验性证据,即 few-shot 转换性能会随着训练集中类的增加而提升。
研究者提出的框架基于生成对抗网络(GAN)。通过对抗训练方案和新网络设计的结合,他们实现了预期的 few-shot 图像到图像转换能力。
此外,在经过三个数据集的实验验证以及与其他基线方法在一些不同的性能指标上进行比较之后,他们证实了所提框架的有效性,并且该框架可应用于 few-shot 图像分类任务。通过在 few-shot 类图像模型生成的图像上训练分类器,FUNIT 框架性能优于当前基于特征错觉(feature hallucination)的最佳 few-shot 分类方法。
FUNIT 框架
为了训练 FUNIT,研究者使用一组对象类图像(如不同动物的图像)并将其称为源类。他们不假设任何两类之间都存在可以配对的图像(也就是说没有两种不同物种的动物是完全相同的姿态)。他们使用源类图像训练多类无监督图像到图像转换模型。在测试阶段,他们为模型提供少量新对象类(称为目标类)图像。该模型利用非常少的新目标类图像将任何源类图像转换成目标类的模拟图像。当他们为同一模型提供少量新的不同目标类图像时,该模型必须将任何源类图像转换成这一新的不同目标类的模拟图像。
FUNIT 框架包含一个条件式图像生成器 G 和一个多任务对抗判别器 D。与现有无监督图像到图像转换框架中输入一个图像的条件式图像生成器不同,研究者提出的生成器 G 能够同时输入内容图像 x 和一组 K 个类别的图像 {y_1, ..., y_K},并通过
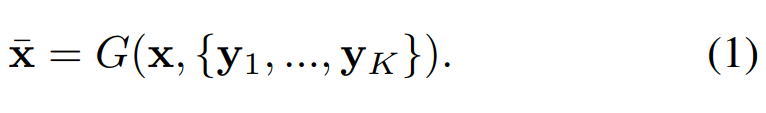
输出图像 x bar。
研究者假设内容图像属于对象类 c_x,而每一个 K 类图像属于对象类 c_y。一般来说,K 值很小,对象类 c_x 区别于 c_y。他们将 G 称为 few-shot 图像转换器。
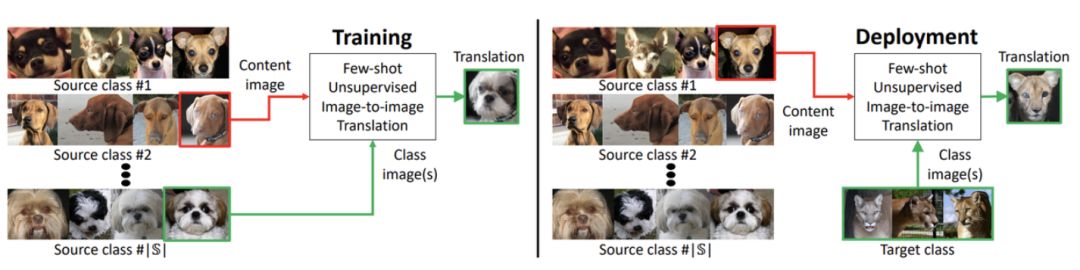
图 1:训练。训练集包含来自几种对象类别(源类别)的图像。研究者训练一个模型在这些源对象类别图像之间进行转换。
部署。研究者向训练得到的模型展示极少的目标类别图像,尽管模型在训练期间从未见过来自目标类别的任何图像,但这已经足够使其将源类别图像转换为目标类别的类似图像。注意,FUNIT 生成器接收两个输入:1)一幅内容图像和 2)一组目标类别图像。它的目标是生成与目标类别图像类似的输入图像的转换。
如图 1 所示,G 将一个输入内容图像 x 映射到一个输出图像 x bar,这样一来,x bar 看起来就会像是一幅属于源类别 c_y 的图像,x bar 和 x 结构相似。让 S 和 T 分别表示源类集和目标类集。在训练期间,G 学习在两个任意采样的源类别 c_x, c_y∈ S(c_x ≠ c_y)之间进行图像转换。测试期间,G 从一个未见过的目标类别 c ∈ T 中提取几幅图像作为类别图像,并将从任何一个源类采样的图像映射到目标类别 c 的类似图像。
FUNIT 的学习过程
如果想要了解 FUNIT 的学习过程,那么了解它的目标函数及组成模块是最好不过了。如前所述,整个 FUNIT 框架主要包含 Few-shot 图像转换器和多任务对抗判别器。其中 Few-shot 图像转换器 G 又包含内容编码器 E_x、类别编码器 E_y 和解码器 F_x,通过这些模块,前面方程 (1) 就可以改写为:
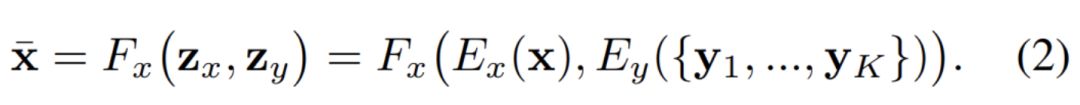
其中 X bar 就是我们希望生成的图像。如果构建了转换器 G 和判别器 D,那么整个 FUNIT 框架就能通过类似 GAN 的方法得到训练,即解极小极大最优化问题:
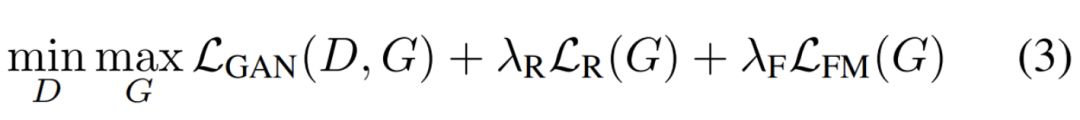
其中 L_GAN、L_R 和 L_F 分别是 GAN 的损失函数、图像内容重构损失和特征匹配损失,它们共同构建了整个模型的目标函数。下面简要地展示了这三种损失函数的计算公式,当然在原论文中,这三个损失函数都有详细的解释,读者可参考原论文理解。
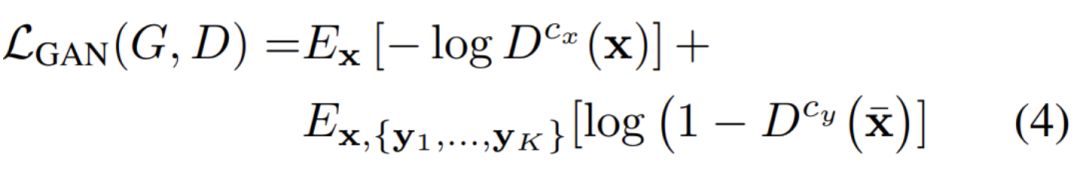
如上在 GAN 的损失函数中,D 的上标表示不同的目标类别。整个损失函数仅使用对应类别的二元预测分进行计算。
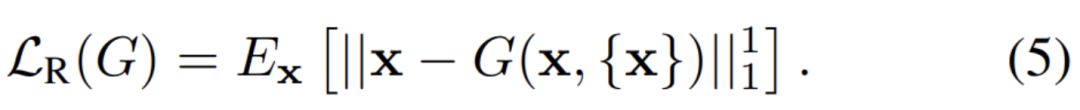
如上很容易看出来,重构损失 L_R 主要会帮助 G 学习转换模型,原始图像要和转换的图像相近一点比较好。
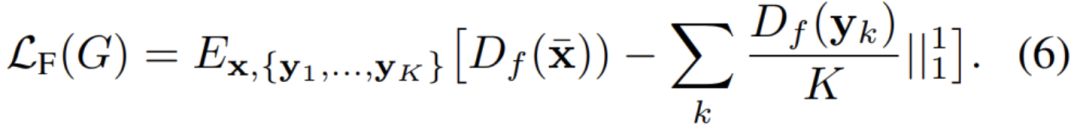
最后是特征匹配损失,它会为整个训练提供正则化效果。其中 D_f 为特征抽取器,它会从输出图像与图像类别中抽取特征。
实验
根据目标类别中的图像在训练过程中是否可用,研究者将基线模型分为两类:公平(不可用)和不公平(可用)。
如表 1 所示,本文中提出的 FUNIT 框架在 Animal Faces 和 North American Birds 数据集上的所有性能指标上都优于 few-shot 无监督图像到图像转换任务基线。
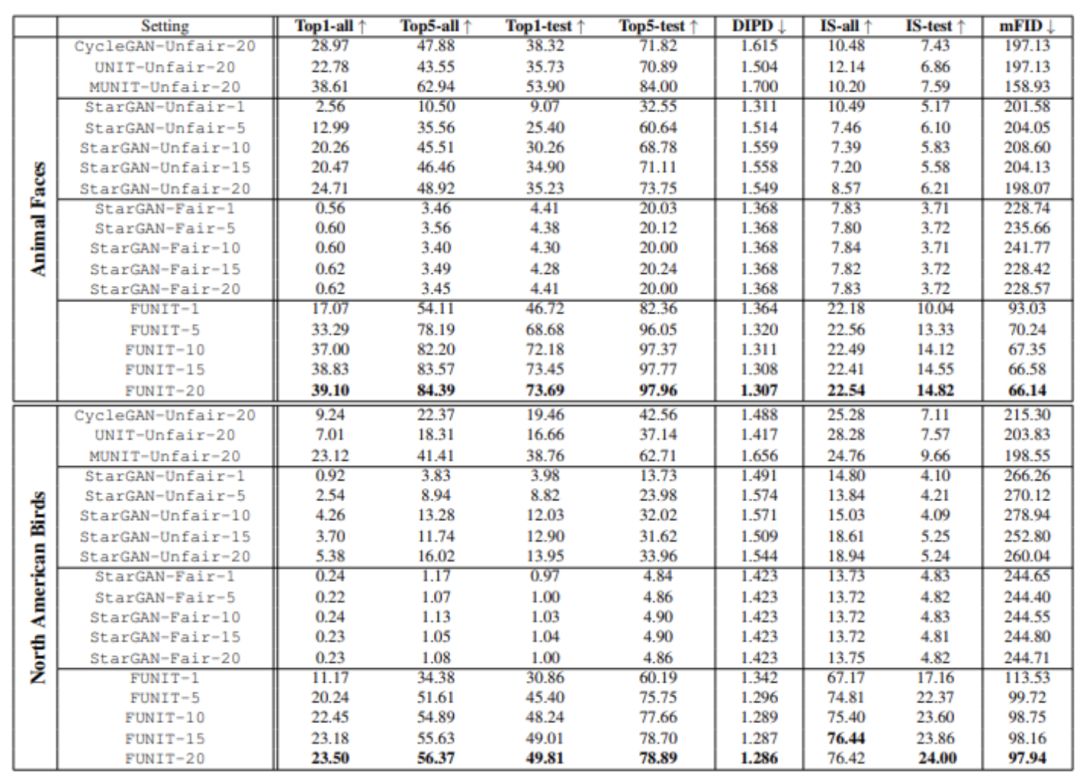
表 1:与「公平」和「非公平」基线的性能比较结果。↑表示值越大越好,↓表示值越小越好。
从表中还可以看出,FUNIT 模型的性能与测试时可用目标图像 K 的数量呈正相关。
研究人员可视化了 FUNIT-5 few-shot 无监督图像到图像转换方法得到的结果(如下图 2 所示)。结果显示,FUNIT 模型可以成功地将源类图像转换为新类的类似图像,输出的图像非常逼真。

图 2:利用本文中的 few-shot 无监督图像到图像转换方法得到的结果。
该结果利用 FUNIT-5 模型计算得到的。从上到下依次是动物面部、鸟、花和食物数据集得到的结果。研究者为每个数据集训练一个模型。y_1、y_2 是 5 个随机采样类别图像中的两个,x 是输入内容图像,x¯表示转换输出。结果显示,尽管在训练过程中没有见过任何来自目标类的图像,但 FUNIT 能够在困难的 few-shot 设置下生成可信的转换输出。从图中可以看出,输出图像中的对象与输入中的对象姿态类似。
下图 3 提供了几种基线模型与 FUNIT 在 few-shot 图像到图像转换任务中的性能比较。由于基线模型不是为 few-shot 图像转换任务设计的,它们在如此具有挑战性的任务中表现无法令人满意。

图 3:Few-shot 图像到图像转换性能的可视化比较。上图中的 6 列图像从左到右依次是输入内容图像 x、两个输入目标类图像 y_1、y_2、从「不公平」及「公平」StarGAN 基线得到的转换结果及本文中的框架得到的结果。
研究人员还让人类受试者参与了生成图像的评价,受试者偏好得分如下图所示(表中数字为喜欢 FUNIT 生成结果的用户所占百分比)。

表 2:受试者用户偏好得分。
结果表明,无论是与「公平」还是「不公平」的基线相比,受试者都认为 FUNIT-5 生成的结果更加可信。
研究人员还分析了在训练时见到的对象类别数发生变化时模型性能的变化(设定为一个样本,即 FUNIT-1)。如图所示,在转换准确率方面,性能与对象类别数呈正相关。这表明,在训练中看到的对象类别数越多,FUNIT 模型在测试中表现越好。
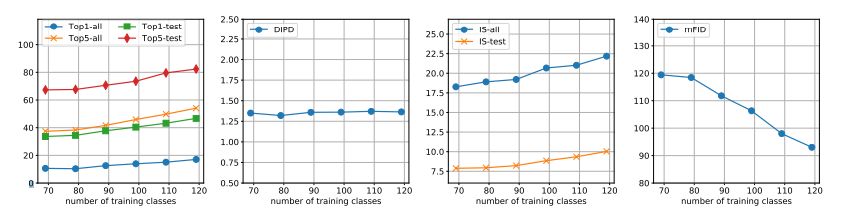
图 4:Few-shot 图像转换性能 vs. 在动物面部数据集上训练时见到的对象类别数。性能与训练期间见到的源对象类别数成正比。
研究者使用动物和鸟类数据集对 FUNIT 的 few-shot 分类性能进行了评估(结果如下图)。更确切地说,他们利用训练得到的 FUNIT 模型为每个 few-shot 类别生成 N 个图像,然后利用生成的图像训练分类器。
他们发现,与 Hariharan 等人提出的 few-shot 分类方法相比,利用 FUNIT 所生成图像训练得到的分类器性能更好。
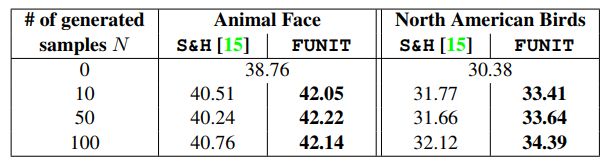
表 3:在 5 种类别上的 few-shot 分类平均准确率。
最后,想要搞点事情的小伙伴们可以看看论文与实现呀。
论文:Few-Shot Unsupervised Image-to-Image Translation

论文地址:https://arxiv.org/pdf/1905.01723.pdf
实现地址:https://github.com/NVlabs/FUNIT
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
