不再是动画,也不再是科幻想象,AI再次带来梦想成真一刻。
在动画片《名侦探柯南》中,阿笠博士送给柯南的变声领结是柯南破案的重要道具,得益于它,柯南可以将声音伪装成其他人,在不暴露身份的情况下巧妙破案。

但或许你未曾想过,有一天,这个变声领结会真的出现在现实世界中,并且只需要在手机上轻轻一点就可以实现完美变声。
没错,现在通过搜狗输入法就OK。
现实版“柯南变声领结”
今天(5月21日),搜狗输入法就化身为了现实版的“阿笠博士”,正式推出“变声”功能。
该功能由搜狗知音团队支持,可以将任意说话人的声音实时变换到指定说话人的音色。
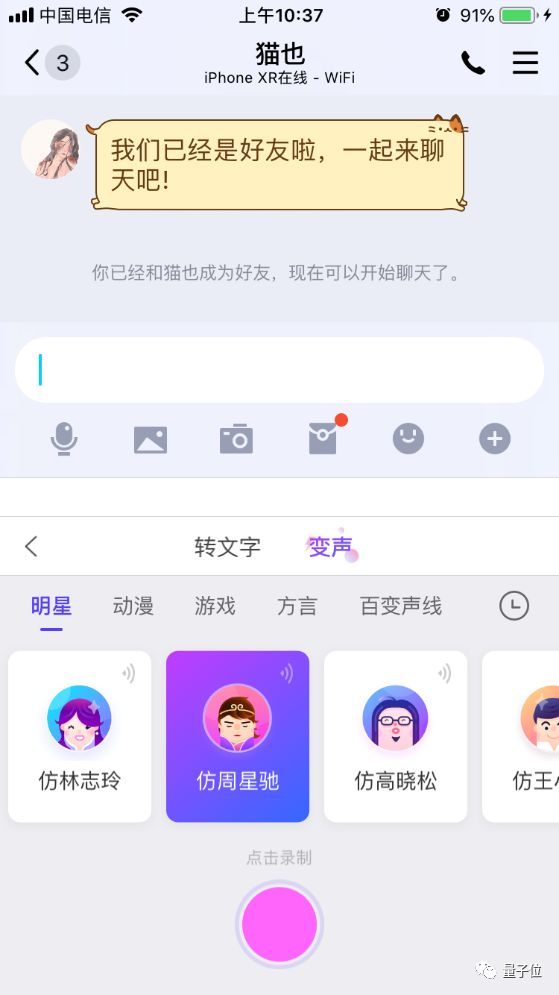
简而言之,只要用户在语音输入中输入想说的话,再选择一个喜爱的角色,就会瞬间把声音转化成该角色的声音,效果直逼柯南的“变声领结”。
虽然效果实现起来一步到位,但背后技术实现并不简单。
搜狗知音的语音技术团队,克服了诸多难以想象的现实困难。
其中最核心的问题是,每一个人的音调、音色和语言节奏都不尽相同,正如同世上没有两片相同的树叶一样,世上也没有两个完全相同的说话人。
如何将“千人千声”通过技术处理,变为同一种指定声音,同时还不丢失原说话人的语言习惯?
这不仅搜狗面临的挑战,也是国际上承认的技术难题。
技术剖析
搜狗知音主要从语音表征学习、语音合成等领域的展开突破。
首先,搜狗知音团队使用表征学习技术,先学习到源端说话人语音的音色、内容和韵律三大特征。
其次,将学习到的源端说话人音色特征替换成目标说话人。
最后,基于搜狗知音的端到端语音合成技术,使用内容(源端)、韵律(源端)、音色(目标端)三类特征合成最终变声音频,达到各个方位的相似和自然。

在表征学习上,对目标音色语料进行声纹特征编码,提取说话人的音色embedding,再分别从输入音频中学习内容和韵律embedding。
把“说话人归一化”模块对内容embedding进行统一规整,去除音色信息。
通过对音频特征的压缩编码及特征抽取,学习表征韵律的风格特征。
然后基于表征学习得到的特征,通过Attention和Decoder模块进行加权特征编码,并利用WaveRNN神经网络声码器恢复成波形,最终得到带有目标音色的音频。
这样一来,由源端音色到指定音色的转化就变得轻易而精密了。
在以上技术原理的支持下,搜狗知音的“变声”功能拥有三大功能亮点:
首先,还原度极高,变声到指定角色的音色与该角色的原始音色十分相似,几乎可以做到以假乱真。
其次,自由空间大,搜狗这一“变声”功能对用户本身的音色没有任何限制,每个人均可变声到预先指定的音色,真正具有“任意人变声到同一人”的能力。
最后,搜狗知音打破了音色转换的局限,将用户输入的语音内容、语速、停顿、情感等均转化为超高逼真度的指定角色声音,因此可以达到更自然的变声沟通。
目前,在搜狗知音“变声”功能中可供选择的角色横跨互联网、明星类、动漫类等多个类别,有近20种声音,包含周星驰、蜡笔小新、小猪佩奇等多个经典的角色,甚至还收录了搜狗CEO王小川的声音。

在聊天过程中,用户可以使用他们的声音完成“变装”,增添聊天过程中的趣味程度。
当然,用户一键使用最新技术的背后,也离不开工程师们的付出。
而且在类似的国际前沿的技术突破领域,中国AI公司正在用研究和论文打响名气。
在搜狗知音团队此次最新技术发布前,搜狗还联合清华天工研究院在5月17日的语音顶级峰会ICASSP 2019上,发布了关于“基于模态注意力的端到端音视觉语音识别”的学术论文。
全球AI华山论剑,中国创新正在 making different~
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
