模仿各路名人的推特行文,现在可以分分钟做到。
MIT的研究科学家、深度学习课老师Lex Fridman做了一个新应用:
DeepTweets,能通过一个人以往的推特内容进行内容模仿,自动生成新的伪推特。
发布10小时,500多人在网友Lex Fridman的研究下点赞,网友@ArthDubey表示,从某种程度上来说,你搜索、查询和发推的时候很容易推断出你的倾向,基于大量数据形成了预测。
效果展示
来看看DeepTweets的假推特实际生成效果。
就拿常年活跃在推特的“网红”马斯克来举例,此前马斯克曾发过一条的关于多层隧道的推特:
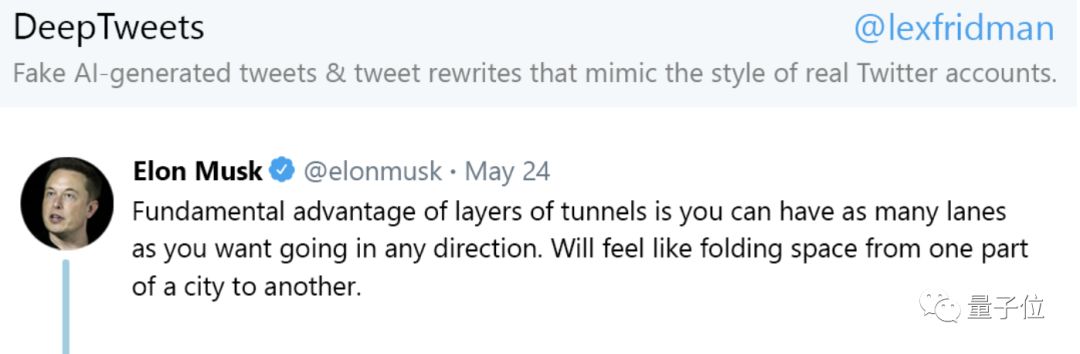
多层隧道的根本优势在于,你可以在任何方向上任意选择车道,就像折叠空间一样从城市的一部分连接到另一部分。
OK,现在该DeepTweets发挥了,它模仿歌星Justin Bieber的口吻,发了假回复推特:

多层隧道的根本优势在于,你不必担心交通或者路面积水,多层隧道让我们很安全。
没错呀,无论是语言连贯度还是内容上的逻辑,这条假推特有点天衣无缝了。
再看一条,来自美国饶舌歌手Kanye West:

多层隧道的优势在于,机器人不惧怕不可知的因素,伊隆加速啊。
可以,这一条连与楼主的互动都用上了。
继续往楼下看,美国女歌手Kate Perry也来凑热闹了:

多层隧道的优势在于……一分钱一分货,宝宝你说呢?
DeepTweets可真是掌握了每个人的用词习惯啊……
这样的例子还有很多,比如让它以“生命的意义是”开头,模仿名人的推特:
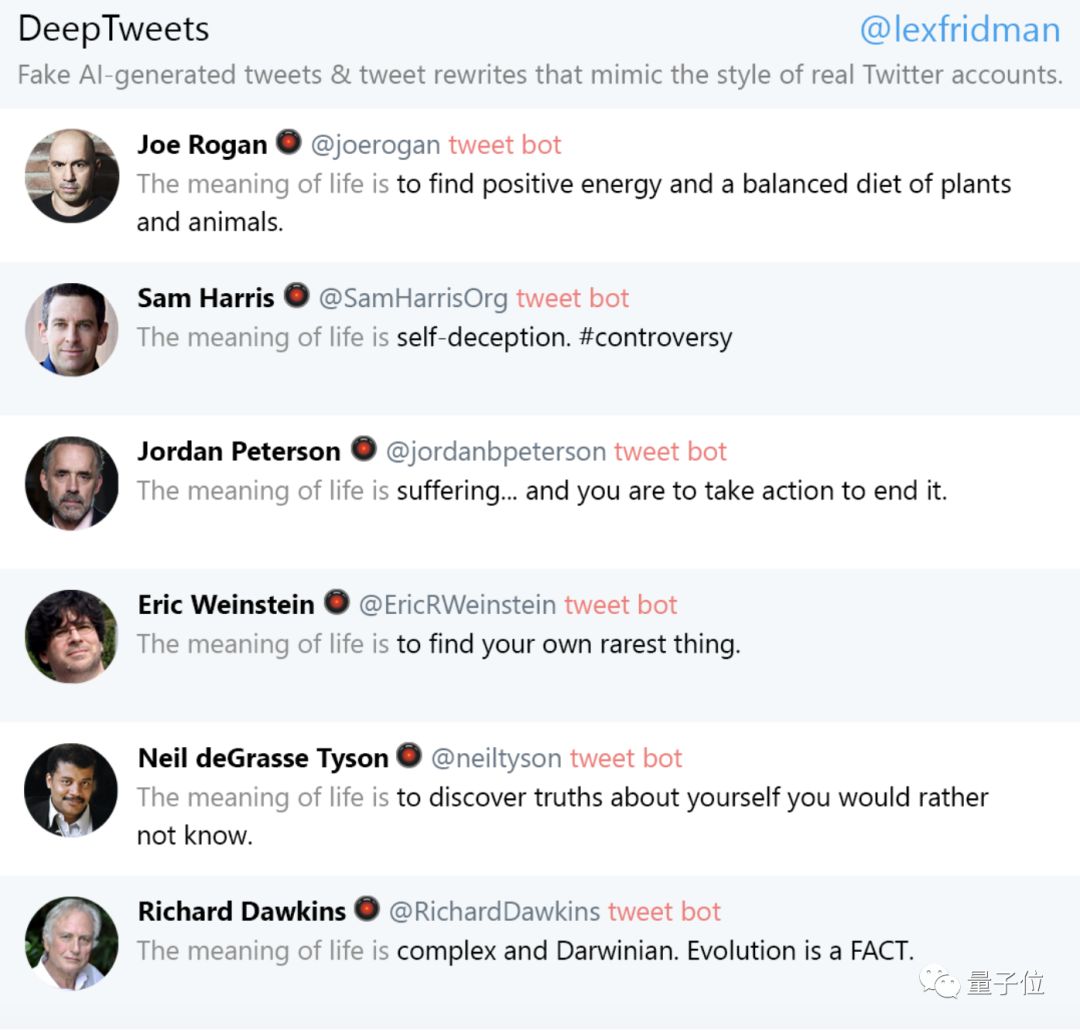
小哥Lex Fridman表示,目前已经训练了不少名人的推特回复模型,比如特朗普、奥巴马、马斯克(Lex Fridman经常与其互动),脱口秀主持人柯南·奥布莱恩,艾伦·德杰尼勒斯等,这些模型将会陆续发布。
GPT-2又立功
作者小哥表示,DeepTweets是在已经开源的语言模型GPT-2上训练的。GPT-2在语言建模任务中,简直是逆天般的存在。

作为一个没有经过任何领域数据专门训练的模型,它的表现比那些专为特定领域打造的模型还要好,横扫各大语言建模任务。
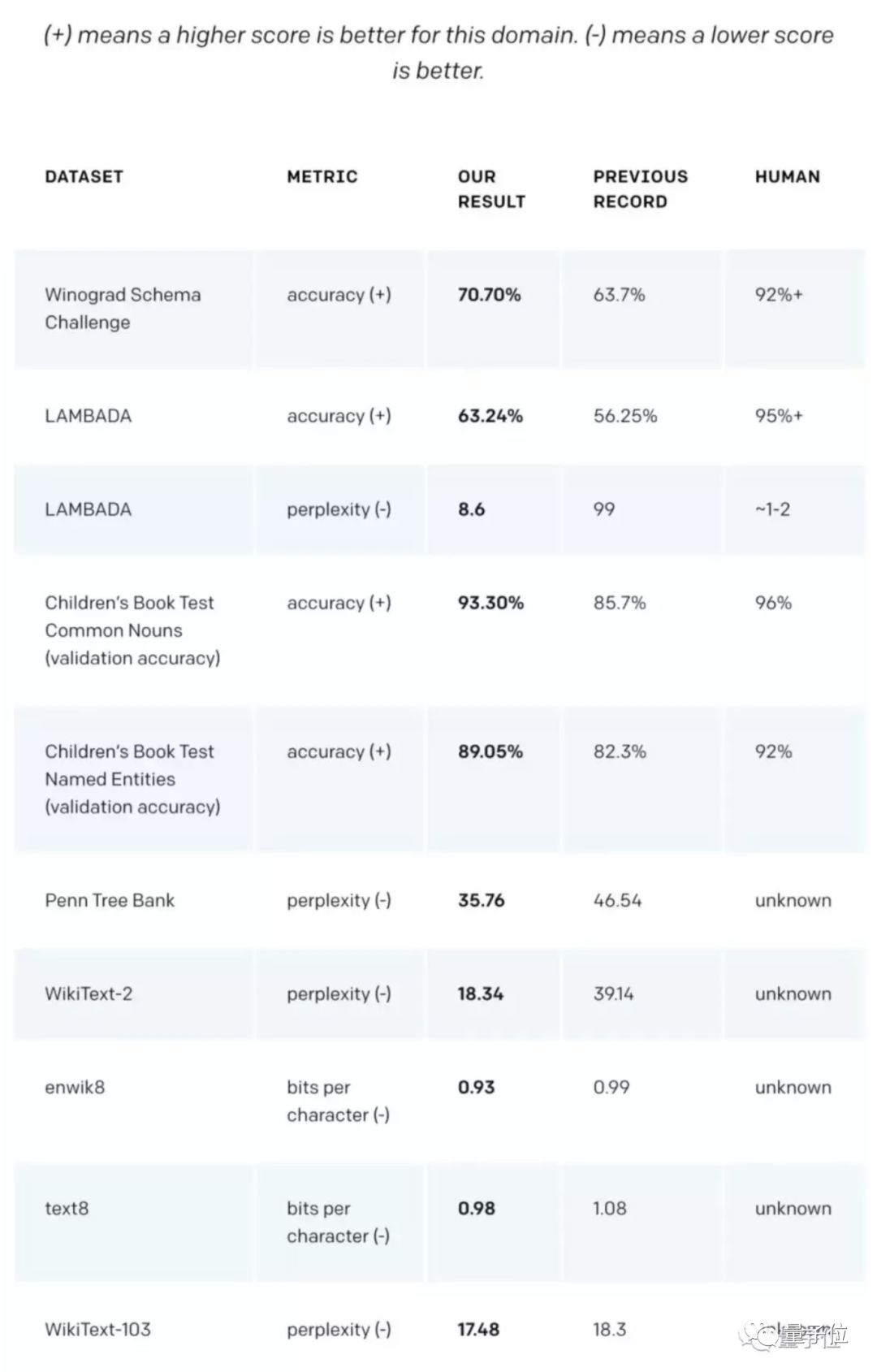
△ GPT-2在不同语言建模任务上的测试结果(从左到右:数据集名称、指标类型、GPT-2测试结果、此前最好结果、人类水平)
简单来说,GPT-2就是基于Transformer架构的大规模模型。
GPT-2是GPT算法“进化版”,比GPT参数扩大10倍,达到了15亿个,数据量扩大10倍,使用了包含800万个网页的数据集,共有40GB。
这个庞大的算法使用语言建模作为训练信号,以无监督的方式在大型数据集上训练一个Transformer,然后在更小的监督数据集上微调这个模型,以帮助它解决特定任务。
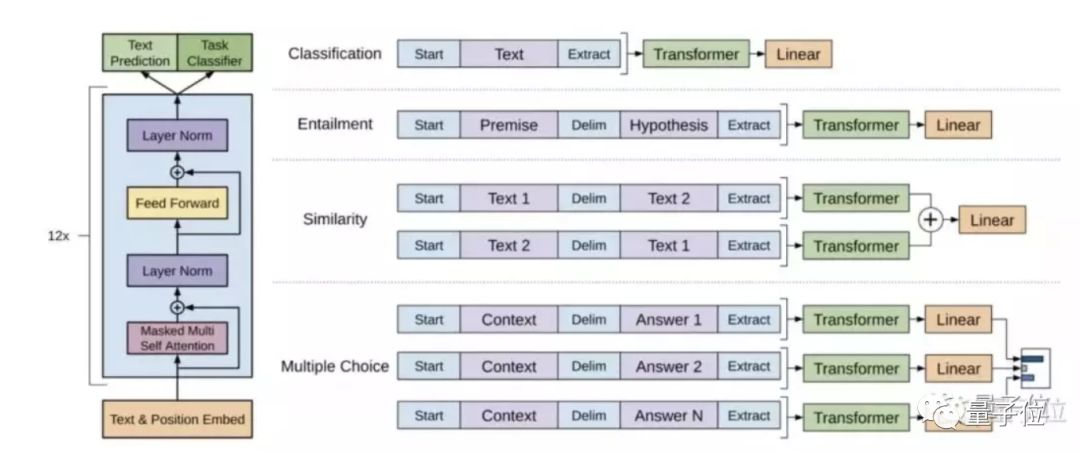
上图左部分,是研究中使用的Transformer架构以及训练目标。右边部分,是针对特定任务进行微调。将所有结构化输入转换为token序列,由预训练模型处理,然后经过线性+softmax层处理。
就GPT-2而言,它的训练目标很简单:根据所有给定文本中前面的单词,预测下一个单词。
一开始,OpenAI只放出了117M的小型预训练模型,被网友调侃为“ClosedAI”。OpenAI表示,不是不开源,而是时候未到。
上个月,OpenAI宣布将其345M的预训练模型开源,外加其Transformer的1.5B参数。
传送门
最后,附上GPT-2相关学习资料。
GitHub代码地址:https://github.com/openai/gpt-2
GPT-2数据集地址:https://github.com/openai/gpt-2-output-dataset
OpenAI介绍主页:https://openai.com/blog/better-language-models/#update
Lex Fridman的GPT-2讲解视频(需要科学前往):https://youtu.be/O5xeyoRL95U
声明:本文来自量子位,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
