
项目地址:https://github.com/imcaspar/gpt2-ml
Colab 演示地址:https://colab.research.google.com/github/imcaspar/gpt2-ml/blob/master/pretrained_model_demo.ipynb
既然昨天才过完双十一,那么我们先看看这个预训练模型能生成什么样的故事。如下是我们给定前提「双十一」,中文 GPT-2 生成的第一个样本:
Sample, 1 of 10
双十一,不只是剁手的节日,更是买买买的狂欢节!10 月 13 日,中国小象开启的全新一年的跨境爆款系列商品双十一的正式来袭,围绕电商双十一的购物理念及战略重点,阿里巴巴、天猫联合打造的潮流趋势支付,正式登陆双十一狂欢夜。潮流界、时尚界盛事的参与者,统统化身成为电商促销的传播者和领导者,时尚界的人们以身作则,走在时尚前线,年轻时尚女性,正用最新的鲜美,向消费者传递快乐与创意。不止双十一,很多行业的大事件会在这个季节火热登场,不只是女性用户,还有男性用户。那么,在这些品牌高调露面的时刻,我们又该如何大玩不同的新玩法?如何抓住双十一的流量红利和品牌曝光点?
首先,形式是核心。网购、预售、快递都是消费者在双十一这个大战场上所接触最多的环节,而品牌商们喜欢的是大玩点创新、玩点新意。其次,先有用户的需求,才能够靠作品的特色获得市场的重视。小象电商的用户就是普通人,所以他们的需求就是需要一个包包,一条围巾,要么想各种创意。
于是,除了颜值,就是线下,大玩奇思妙想!不限于明星、时尚青年的价值需求,一个玩法就是无限加价,为了让所有用户都有收获。潮流的故事往往是颠覆性的,为了引起用户的兴趣,新玩法的推出,要给用户充满惊喜的体验,提供最奇妙的玩法。就算是普通人购物体验也会选择最少的购物过程,这就是品牌持续+创新的理念。来源:综合自阿里巴巴官方微博、阿里妈妈官方微博、中国经济网的特点。对阿里和时尚感兴趣的朋友,可以关注微信号:hzcyhg
这个生成样本说得头头是道,很难看出来它完全是由模型生成的,甚至样本给出了一个微信号,我们查了后估计该微信号与文本是没什么关系的。
既然样本效果这么好,它肯定需要很多中文语料。项目表明,该 15 亿参数量的 GPT-2 中文预训练模型在 15GB 的纯文本上进行训练,一共迭代了 10 万步。这 15GB 的纯文本主要选自 THUCNews 与 nlp_chinese_corpus,它们会做一系列的数据清理。
THUCNews:http://thuctc.thunlp.org/#中文文本分类数据集THUCNews
nlp_chinese_corpus:https://github.com/brightmart/nlp_chinese_corpus
此外,项目作者还简化整理了 GPT-2 训练代码,移植了 Bert Tokenizer 以添加多语言支持。因为移植了 Bert Tokenizer,所以模型输出结果很容易与基于 BERT 的模型进行整合。
项目作者开放的预训练模型是在 TPU Pod v3-256 上复现的 15 亿参数 GPT2,这也是 GitHub 上第一个支持大规模 TPU 训练的中文 GPT-2 项目。
本项目的训练脚本:https://github.com/imcaspar/gpt2-ml/tree/master/train
极简易用的 Colab 演示
非常吸引人的是,该项目提供了一个非常容易使用的 Colab 项目,只需简单地单击三次,我们就能使用 Colab 体验 GPT-2 续写整段文本的能力。演示地址在文章前面已经提供了,这里主要展示机器之心尝试的效果。
下图是我们尝试使用的结果,简单而言分可以为三步:首先从 GitHub 下载源代码;其次从 Google Drive 下载预训练模型,这里需要获得授权,也非常简单;最后,调用 Colab 的硬件进行推断就行了。
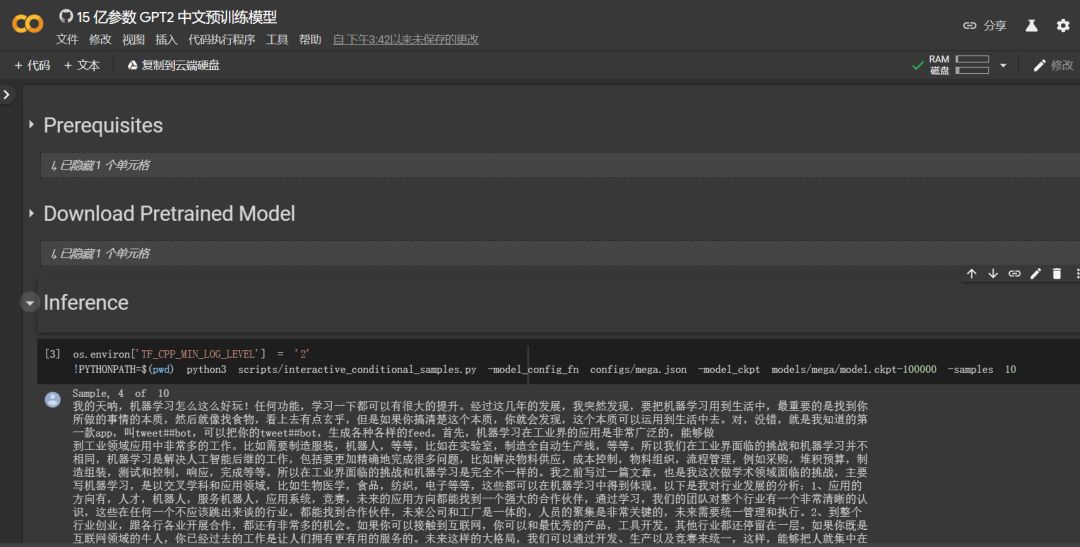
我们可以看到,中文 GPT-2 大部分生成结果,上下文还是非常合理的。如果你也想试一试效果,那就快来试一试吧,没有任何 ML 基础也能看到模型的真实效果。
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
