
2019年11月16日, 智源论坛:虚假新闻检测暨2019虚假新闻检测挑战赛颁奖仪式召开。本次挑战赛由北京智源人工智能研究院和中国科学院计算技术研究所共同举办,旨在促进互联网虚假新闻检测技术的发展,营造清朗的网络空间。
为应对当前虚假新闻泛滥的现状,将虚假新闻带来的危害最小化,我们设立此赛题以促进对虚假新闻自动化监测方法的研究。针对虚假新闻的特点,本次大赛设立了三个子任务:虚假新闻文本检测、虚假新闻图片检测和虚假新闻多模态检测。
它们的具体任务分别是:
给定一个新闻事件的文本,要求参赛者判定该事件属于真实新闻还是虚假新闻;
给定一张图片,要求参赛者判断该图片属于虚假新闻图片还是真实新闻图片;
给定一条新闻的多模态内容(包括文本、配图、用户特征等),要求参赛者判断该新闻属于虚假新闻还是真实新闻。
三个赛道相互独立进行。 整个比赛的数据集包括4万多条文本信息,4万多张微博图片,以及4万多条多元的辟谣信息。 这些数据创造了两个记录:一是目前公开的最大规模的中文虚假新闻数据集,二是全世界第一个虚假图片数据集。
在互联网环境中,各类假新闻以令人眼花缭乱的速度,不断变化发展,干扰人们的认知,削弱媒体机构的公信力。很多时候,光凭肉眼,我们很难分辨一条新闻的真伪。

面对这个棘手的问题,本次新闻检测挑战赛的参赛选手们纷纷给出了自己的答案。他们都采用了什么样的思路、选择了哪种方法来解决呢?我们一起来看一下。
赛道一:虚假新闻文本检测

赛道一的竞争非常激烈,三支获奖队伍都使用了BERT预训练模型加强特征校正。这符合目前虚假新闻识别领域中“数据驱动加知识驱动”的主流研究方向。
获得了第一名的“JayPath”团队,将这个任务抽象为NLP领域的文本二分类任务,采用BERT-Finetune、BERT-CNN-Pooling、BERT-RCNPooling多种结构进行融合,在输入上引入字词结合的形式,充分利用假新闻的关键词特征进行优化。
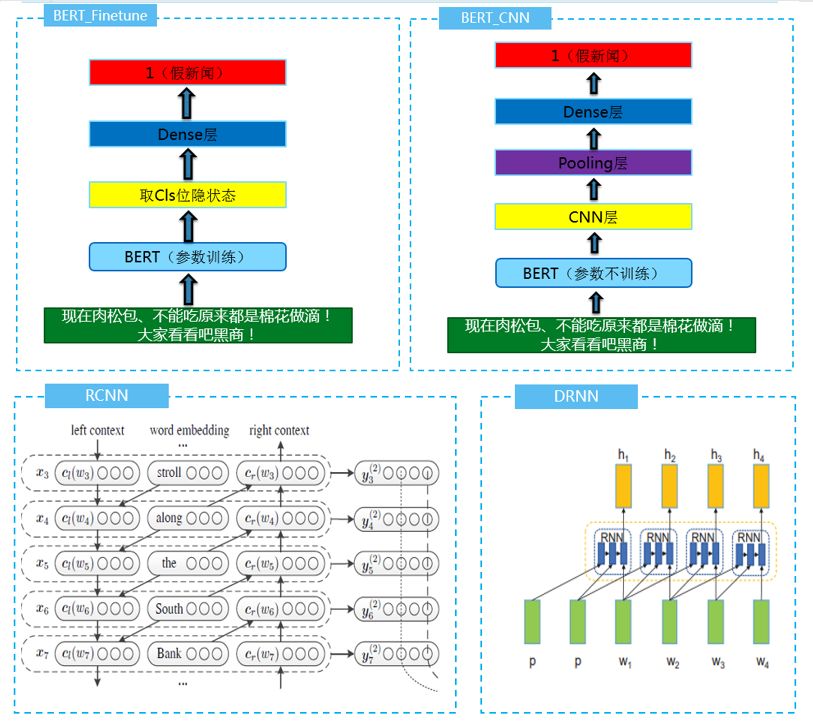
思路:多模型融合
他们在每一个模型的基础上,进行10折交叉验证,然后利用假新闻的关键词特征进行优化:
对于训练集中的所有假新闻,利用 textrank4zh 对每条新闻文本取10个关键词,汇集所有的关键词,得到前100个出现最多的关键词。通过观察这些关键词,发现假新闻喜欢对部分人名、地名、名词、动词进行造谣。
同样对测试集中的每条新闻文本取10个关键词,汇集所有的关键词,得到前100个出现最多的关键词。对这些关键词先去除在训练集中出现较多的,然后按照人名、地名、名词、动词的方式获得以下几类词:
人名:小泽征尔、翁帆、崔永元;地名:中国、美国、南京、上海、杭州、福建、晋江;名词:洪水、新闻、遗产、同学、校车、大学、国家;动词:视察、证实。
因此,某一新闻的前10个关键词含有以上这些词时,它有为假新闻的倾向,因此,在模型融合时可以降低真假新闻的分界线。利用这个关键词特征可以发现更多的假新闻,使假新闻评判效果更好。

实验结果
赛道二:虚假新闻图片检测

在赛道二虚假图片检测中,获得第一名的“流星雨”团队通过特征工程的方法,研究了图片的基本特征、图片中的文字特征、PCA和SVD降维特征,以及DTC特征等。
基本统计特征:
图片尺寸
图片后缀类型
图片模式(RGB、灰度等)
清晰度、亮度
直方图分布特征
各通道的均值方差等统计特征
特征意义:
关键特征包括图片尺寸和清晰度特征
图片尺寸可以识别图片的来源,比如手机截图的尺寸和相机照片尺寸截然不同
一般认为图像越清晰越是真的,因为图像经过ps篡改之后清晰度会下降,还有一种可能性是谣言往往传播得更快,传播过程中的每一次保存和发送都可能会降低清晰度。
原始数据降维特征:
PCA特征
SVD特征
特征意义:
原始数据其实是三维的数组,但不同图片数组尺寸大小不统一,并且直接作为特征会导致维度爆炸
将图片resize成统一尺寸,并利用PCA与SVD抽取主要成分作为特征
降维特征可以在保证维度正常,提取出表征该图片的关键信息。
在比赛初期他们一直使用LightGBM模型,在线下继续5折交叉验证,并且线下线上保持同增减。比赛后期,由于特征瓶颈,又尝试了Xgboost模型,发现效果有了提升。
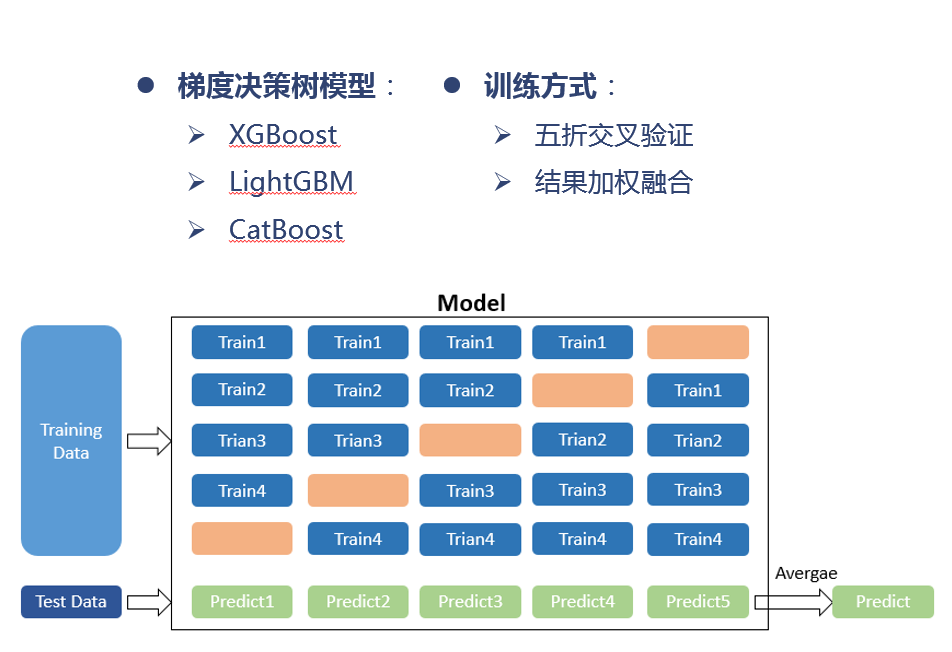
模型构建
下面是最终的效果对比:
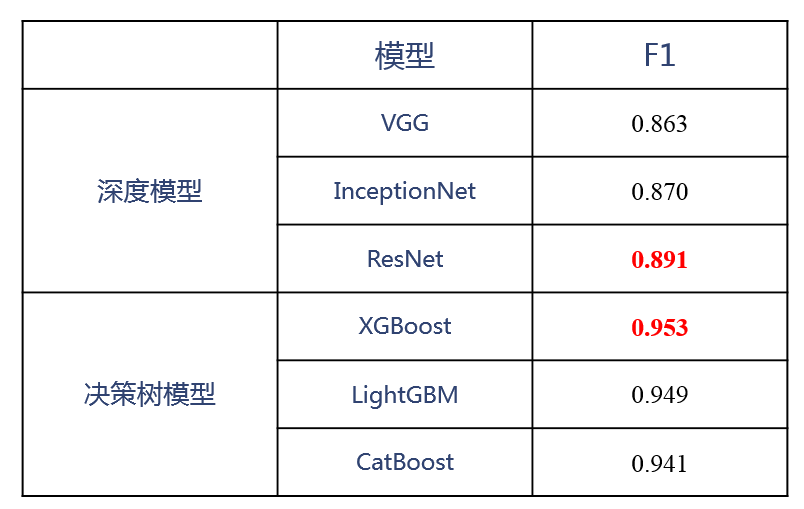
赛道三:虚假新闻多模态检测

在赛道三多模态虚假新闻检测中,获奖选手的方法多种多样,百花齐放。冠军团队“Qingbo&bird”通过提出了一个基于Gdbts-DenseNet-Bert联合抽取特征的识别模型,实现了准确全面的多模态识别。
面对38471条训练样本,他们通过Python对原始特征数据以及构造的特征进行了数据分析。
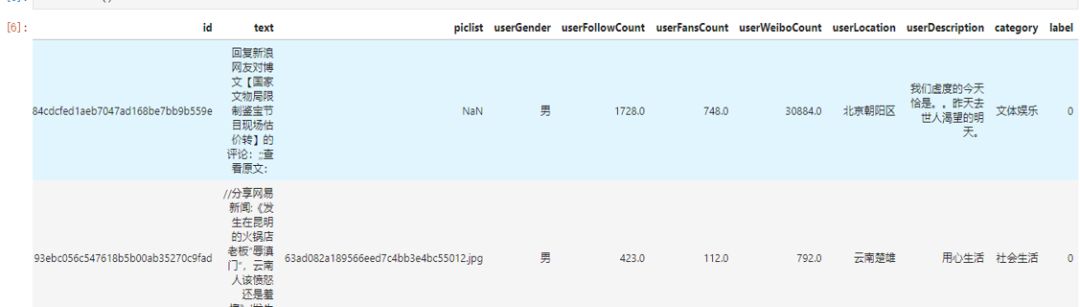
字段分析
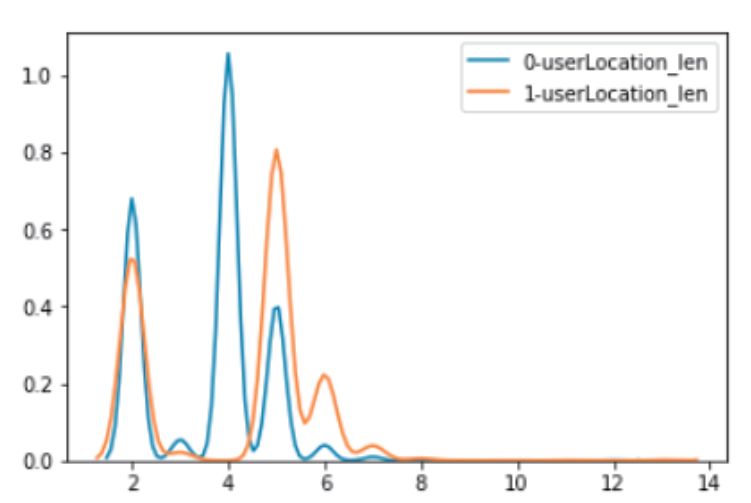
正负样本在地域字符长度上面的分布差异
他们还对其余的字段进行了数据分布上面的探索和分析。
数据预处理
针对非结构化数据的text文本数据字段,他们使用jieba分词库对text进行了分词。
模型部分
多媒体新闻主要包含三类特征,一个方面是图像特征,训练数据中含有图片的样本占80%以上,一个方面是文本特征,还有一个方面是多媒体新闻的发布或者转发者的用户信息特征,比如粉丝数目、关注数、用户简介等用户画像特征。
“Qingbo&bird”团队使用了GDBT-based的模型,针对图像特征,将densent121预训练模型的最后一个全连接层的输出作为图像的语义特征。针对text文本字段,他们利用tfidf提取ngram特征。
最后,他们把图像、N-Gram和Bert提取的文本特征、用户画像特征拼接到一起,输入GDBT-based模型,训练了一个虚假分类的虚假新闻判断模型。
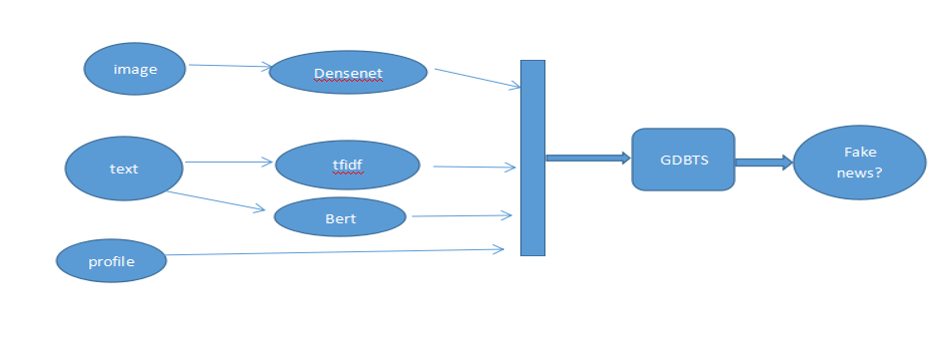
Gbdt-cnn-Bert多模态模型
通过GDBT抽取统计特征,CNN模型抽取图像特征,Bert抽取文本特征,然后将三个特征拼接到一起给模型训练。通过多角度抽取特征,使得模型更加稳定。最终线上效果到达了99%的f1值。

模型框架
本次论坛总结了“智源&计算所-互联网虚假新闻检测挑战赛”的比赛情况和获奖方法、为获奖团队颁奖,又重点讨论了互联网虚假新闻识别这一日益紧迫的研究方向。
智源研究院首席科学家文继荣,北京智源人工智能研究院常务副院长曹岗,中科院计算所党委书记李锦涛,中科院计算所研究员曹娟,纽约州立大学奥尔巴尼分校计算机视觉与机器学习实验室主任吕思伟,以及新华社技术局技术研发中心处长成鹏等出席了本次论坛。
声明:本文来自北京智源人工智能研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
