编者按:个性化新闻推荐是新闻行业必然的发展方向,在其实现过程中面临着三个关键问题,即分析用户兴趣、根据新闻内容建模和新闻排序。本文将这三个问题划归为新闻信息与用户兴趣的多样性问题,并由此出发,提出了基于多视角学习和个性化注意力机制的解决方案,相关论文发表在 IJCAI 2019和 KDD 2019。
引言
如今,在线的新闻服务平台成为了热门的电子新闻阅读渠道,但海量的新闻为用户带来了严重的信息过载。因此,个性化的新闻推荐技术对于在线新闻平台来说非常重要,它一方面可以帮助用户发现感兴趣的新闻,提高新闻的阅读体验;另一方面可以帮助新闻平台提高用户的参与度和平台的收入。本文介绍我们关于新闻推荐的研究工作:基于多视角学习和个性化注意力机制的新闻推荐。
新闻推荐中有三个关键问题需要解决:
1)如何利用用户的新闻阅读历史来对用户进行建模,捕捉他们的潜在兴趣。
2)如何根据新闻的内容对新闻进行建模。
3)如何根据新闻和用户的建模结果,来对候选新闻进行有效地排序。
新闻推荐作为一个推荐系统的一个子任务,自然可以使用例如协同过滤等传统的推荐方法,进行新闻用户表示的学习以及候选新闻的排序。但是,与传统的推荐任务不同,新闻推荐有其特有的挑战。在新闻平台上,旧的新闻会很快消失,大量新的新闻会快速地出现,这就带来了严重的冷启动问题。这也使得基于协同过滤的方法难以直接应用于新闻推荐的场景。目前也有一些基于人工设计的特征来进行新闻推荐的方法。但是,这些方法需要大量领域知识进行特征工程,同时也通常难以建模新闻中的语义信息。
新闻信息和用户兴趣的多样性
近年来,随着深度学习的发展,一些基于深度学习的新闻推荐方法被提出。通常这些方法先从单一的新闻内容(如新闻标题)中学习新闻的表示,再从用户的浏览历史中学习用户的表示。这就带来了两个挑战:一是信息不足,新闻标题可能不足以概括整个新闻的内容,二是缺乏个性化的问题。在这些方法中,相同的新闻对建模不同用户使用了相同的表示,而假设不同用户点击了相同的新闻,也被认为有相同的兴趣。这实际上违背了用户兴趣的多样性。
新闻信息的多样性。如图1所示,一个新闻中通常会包含多种不同类型的信息,例如标题、正文、类别等等。而不同类型的信息特性差异很大。例如,标题通常是简短的句子,正文是很长的文档,而类别是由数个词语组成的类别 ID。因此,如何利用异构的新闻信息来学习信息更加丰富的新闻表示是需要解决的问题。

图1:两个示例新闻。红色代表标题和正文中重要的词语
用户兴趣的多样性。如图2所示,不同的用户通常对新闻阅读有不同的兴趣,并且不同的用户可能会关注同一篇新闻文章的不同重点。这导致了他们可能会因为不同的兴趣而点击相同的新闻。因此,如何学习个性化的新闻和用户表示是需要研究的问题。
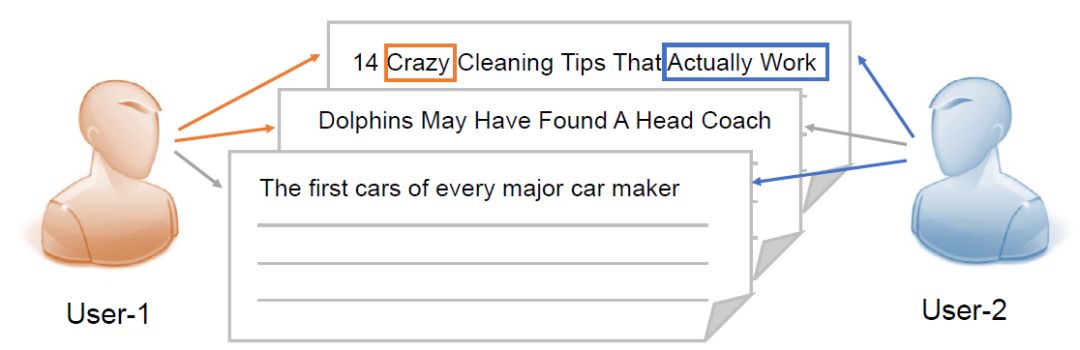
图2:两个示例用户及其点击新闻
多视角学习
为了解决新闻信息的多样性问题,我们在 IJCAI 2019 发表了一种基于多视角学习的方法 NAML,其框架如图3所示。该模型包含两个核心模块,分别是一个新闻编码器和一个用户编码器。在新闻编码器中,我们从新闻的标题、正文、类别和子类别中学习新闻表示。我们将这些不同类型的新闻数据视作不同的新闻视角,并且使用词语和视角级的注意力网络来选择重要的词语和视角。在用户编码器中,我们使用新闻级的注意力机制来选取高信息量的新闻。而在最后的点击预测模块中,我们根据候选新闻和用户表示的内积来计算点击分数。
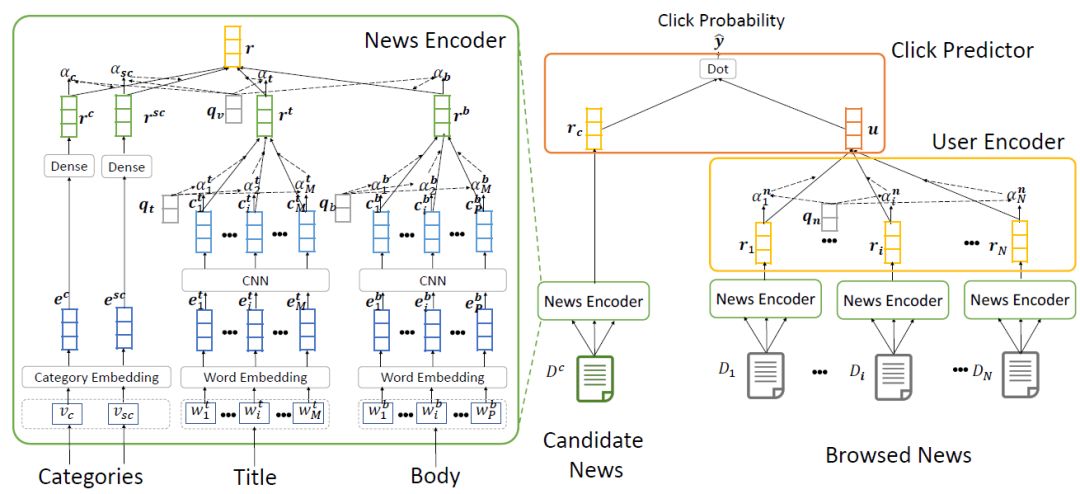
图3:NAML 方法的框架
实验评估
我们的实验在真实新闻推荐数据集上开展,数据集从 MSN 新闻一个月的记录中采样得到。我们使用最后一周的日志作为测试,其余用作训练和验证。结果如表1所示。

表1:数据集的统计数据
首先,我们将我们的方法与一系列基线方法对比,表2中的结果显示我们的方法显著优于基线方法。
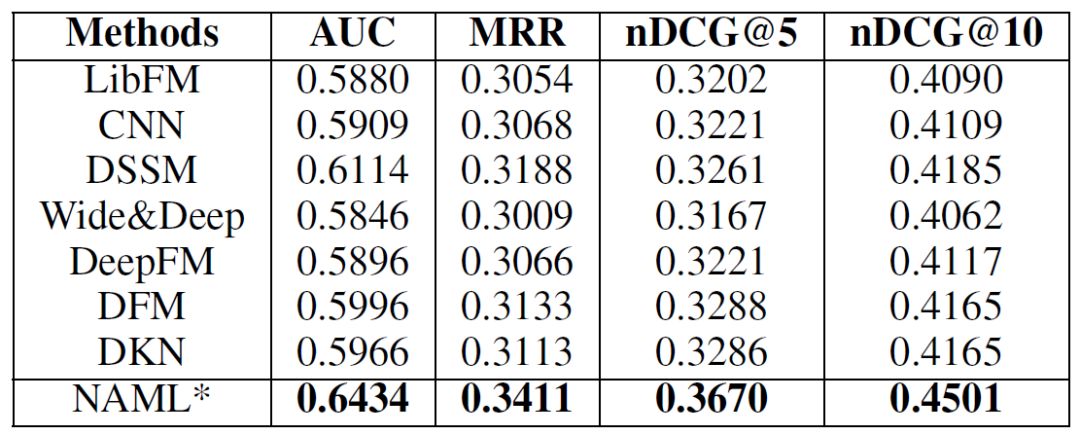
表2:不同方法的结果。*性能的改进在p < 0.001的水平上显著
接下来,我们进行了实验来验证基于注意力机制的多视角学习的有效性。首先,图4(a)显示了我们模型及其仅使用一种视角的变体的性能。根据结果,我们发现正文比标题更为重要,而通过多视角学习将三种不同的信息结合能够进一步提升模型效果。而图4(b)显示了不同注意力机制的有效性。我们通过分别移除某一种注意力机制来探究每种注意力网络的贡献。根据实验结果,词语级别的注意力机制最为重要。这可能是因为词语是承载新闻语义信息的基本单位。新闻和视角级别的注意力同样对于模型性能有用,并且将三者结合可以进一步提升模型性能。这也验证了我们模型中基于注意力机制的多视角学习方法的有效性。
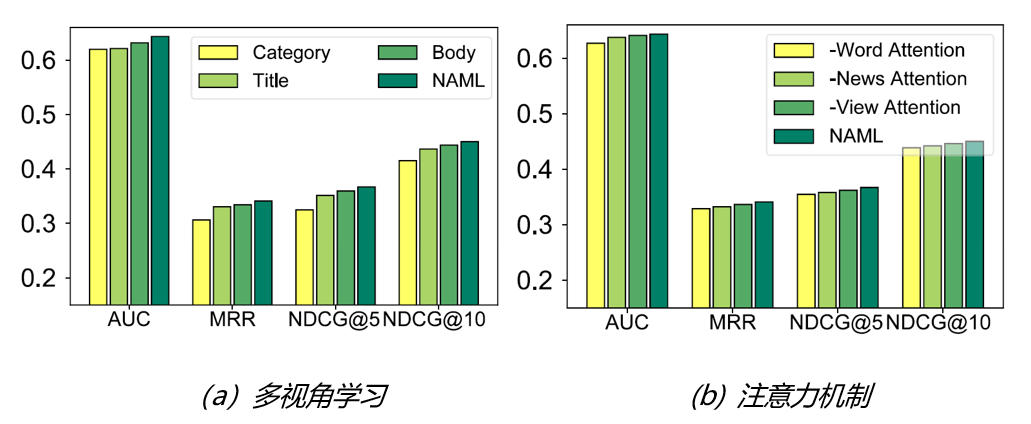
图4:多视角学习框架和注意力网络的有效性
可视化探究
我们进行了一些可视化探究。首先将视角级的注意力权重可视化,如图5所示。左图显示了不同视角注意力的均值和标准差,而右图显示了他们的分布。根据结果,我们发现正文比标题获得了更高的注意力权重,这也与前述的结果对应。有趣的是类别和子类别获得了最高的注意力权重,这可能说明二者有着很高的信息密度。

图5:视角注意权重的可视化
我们也对词语和新闻级别的注意力进行可视化。从图6中可以发现,我们的模型能识别和选择重要的词语和新闻。例如,Bowl、Coach 这样的词语对于推测新闻的主题很有帮助,因此被高亮,而像 weekend 这样的词语则信息量较低。对于新闻而言,例如第4条新闻被高亮,因为它能够很好地反映用户的兴趣,而如第3和第5条新闻则可能被各种类型的用户浏览,没有兴趣区分度,因此获得了较低的权重。

图6:单词和新闻级别注意力权重的可视化。越深的颜色代表越高的注意力权重
了解更多技术细节,请查看论文:
Neural News Recommendation with Attentive Multi-View Learning
链接:https://arxiv.org/abs/1907.05576
个性化注意力机制
我们的第二个工作——基于个性化注意力机制的新闻推荐发表在 KDD 2019上。为了解决用户和新闻表示的个性化问题,我们提出了一种名为 NPA 的模型,其结构如图7所示。它的结构同样包含两个主要模块:新闻编码器和用户编码器。
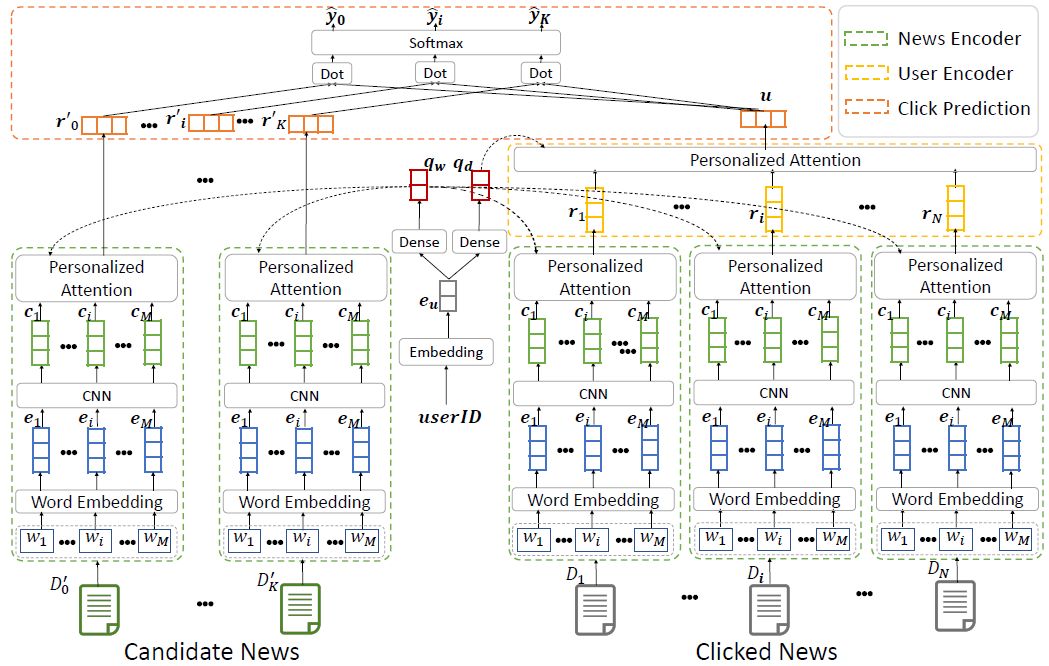
图7:NPA 方法的框架
新闻编码器包括三层:一个将词语序列转化为语义向量序列的词嵌入层,一个用于建模局部上下文的 CNN 层,和一个词语级的个性化注意网络。在个性化注意力网络中,我们使用一个偏好查询向量和一系列输入表示计算相似度,构建个性化的输出表示。在词语级别,用户的偏好向量是由用户的 ID 嵌入向量经过一个非线性变换生成的。而在用户编码器内,我们使用一个新闻级别的个性化注意力网络。我们通过另一个非线性变换来得到用户的新闻偏好向量。最终在点击预测模块,候选新闻的点击分数由用户和候选新闻表示向量的内积计算。在这里我们提出使用负采样方法,将每个用户点击的新闻(视为正样本)搭配 K 个在同一个会话内展示而没有被用户点击的新闻视为负样本。我们联合预测 K+1 个新闻的点击预测分数,而将任务重构为一个 K+1 路的分类任务,最终通过优化正样本的负对数似然来训练模型。
实验评估
我们的实验同样在一个 MSN 新闻推荐数据集上进行。从表3可以看到,数据集内正负样本的比例非常不平衡。
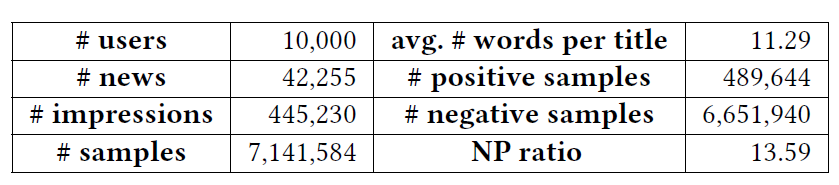
表3:数据集的统计信息
与一系列基线方法对比,我们的方法一致地优于对比的基线方法,并且效果的提升是统计显著的。我们也对比了各种方法的计算复杂度。可以看出,我们的方法可以很好地平衡效果和计算效率。
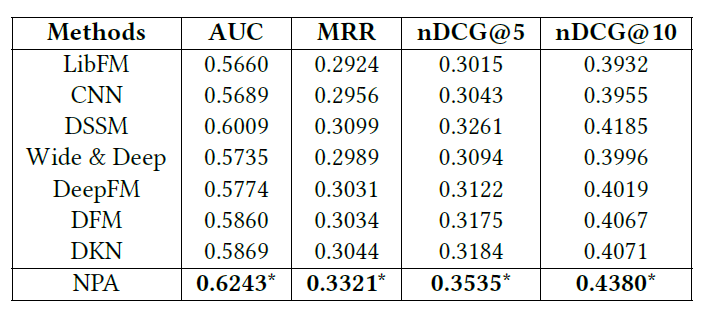
表4:不同新闻推荐方法的结果。*改进的显著性水平为 p < 0.001
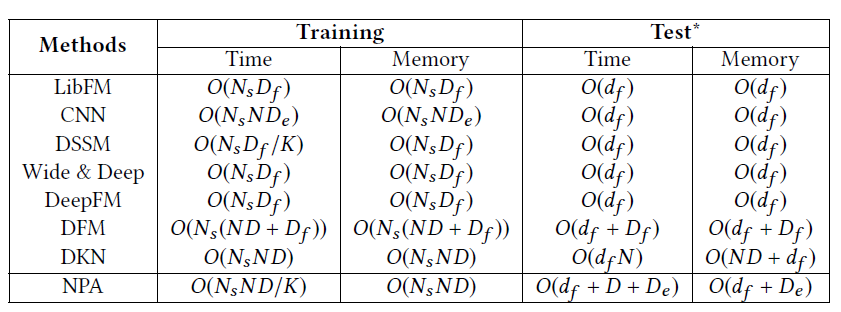
表5:不同方法的计算复杂度
接下来,我们也进行了实验来探究负采样的作用。图8(a)显示的是使用负采样与否的结果对比,可以看出负采样对于模型性能非常重要;同时图8(b)显示了负采样比率对模型性能的影响,可以看出一个适中的负采样比例效果最佳。
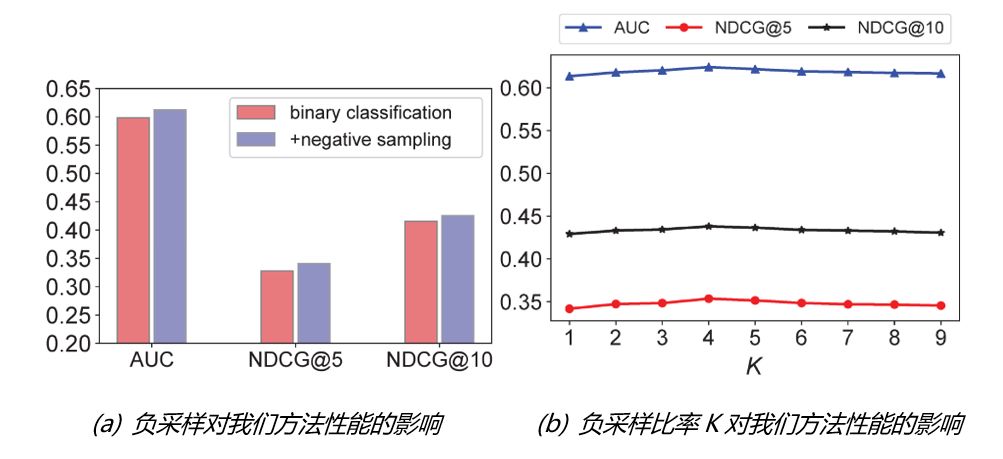
图8:负采样对模型性能的影响
我们同样进行了实验来探究个性化注意力机制的作用。图9(a)的结果显示了使用注意力机制的方法优于不使用注意力的方法,而使用个性化注意力机制则进一步优于普通的注意力机制。而图9(b)则显示了词语和新闻级别个性化注意力机制的作用。可以看到二者均对模型的性能非常重要,同时将二者结合可以进一步提升模型效果。

图9: 个性化注意力机制对模型性能的影响
可视化探究
我们也对个性化的新闻和词语注意力进行了可视化。我们根据点击历史发现,例如图10(a)中,用户1可能对体育感兴趣,而用户2对电影更感兴趣。因此对于用户1,候选新闻中体育关键词则被高亮,而对于用户2,电影关键词被高亮。同时在图10(b)中,对于同一个点击过的新闻,体育新闻对用户1被赋予了较高的注意力权重,而对用户2则不然。这也说明了我们的方法可以根据用户的偏好选取重要的词语和新闻。

图10:词语和新闻个性化注意力权重的可视化
了解更多技术细节,请查看论文:
NPA: Neural News Recommendation with Personalized Attention
链接:https://arxiv.org/abs/1907.05559
结语
综上,我们提出了两种有效的新闻推荐方法,分别是利用多视角学习来从异构的新闻信息中学习更好的新闻表示,以及利用个性化注意力来建模用户兴趣的差异,做到千人千面的新闻推荐。
本文作者:武楚涵、吴方照、谢幸
声明:本文来自微软研究院AI头条,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
