胡望洋 1,2,邵安 2,3,舒洪水 1
(1.西北政法大学反恐怖法学院,陕西 西安 710063;2.浙江警察学院公共安全与危机管理研究所,浙 江 杭州 310053;3.基于大数据架构的公安信息化应用公安部重点实验室,浙江 杭州 310053)
摘要
[目的/意义]开源情报分析是情报工作的重要内容。在大数据时代,事件信息能够短时间内在互联网上呈指数性增长,以人力为主的传统情报分析技术的局限性越来越明显。因而自动化的文本挖掘技术愈发举足轻重。
[方法/过程]本研究通过前置处理、特征淬取、数据分群、标记处理与情报挖掘等阶段,运用自组织映射算法进行数据关联分析,使用主题侦测和特定事件侦测两种技术进行情报挖掘,以期建立基于文本挖掘技术的自动化开源情报分析方法。
[结果/结论]遵循上述程序与技术,借助标准数据集Reuters-21578进行事件侦测实验,运算结果满足了特定事件情报分析的需求。注意的是数据集文件数量的均匀程度会显著影响类别准确度。
关键词:开源情报;文本挖掘;事件侦测;自组织映射
自古以来,情报的搜集与分析就备受重视。无论是商家还是兵家,情报搜集大都通过秘密、隐蔽渠道及不合法方式获得,造成情报搜集过程面临极大风险,加上搜集渠道的特殊性、稀少性与反情报机制的制约,情报可靠性通常无法保障。相对于此,通过新闻网站、政府报告、企业财报、组织网页等公开来源获取的情报,则称之为公开来源情报(简称开源情报),这是一个风险较小的情报渠道,但其分析结果对情报工作贡献巨大[1]。开源情报的搜集与分析需要仰赖专业化程度高、信息分析能力强的行业专家,因此,实战中时常会面临人手不足与实时性不够等瓶颈。
开源情报处理常常面临两方面问题。
一是大量数据快速撷取与处理。开源数据数量巨大且格式不一,无论是在线处理或脱机处理都十分困难,尤其是新闻等实时数据。
二是开源情报分析。开源情报来源不虞匮乏,从大量数据中过滤、侦测、摘录出重要情报是十分艰巨的任务,如果仅仅依靠人力显然无法满足分析工作的需求。
因此,一套能够满足大量数据快速撷取与处理需求的情报分析方法,是开源情报自动化处理的关键。
1、相关研究
1.1 情报搜集与处理
Johnston[2]认为情报是了解某些实体秘密信息的国家或团体活动。情报的目标是获取实体秘密信息,大多由政府专业机构进行,如搜集特定情报以了解恐怖组织动向。另一方面,Johnston认为情报分析是运用个人或群体认知的方法,在特定情境下所进行的数据分析与假设验证,如情报来源显示恐怖份子近期入境,则情报专家应当分析该情报的可信度,并预测其是否会造成危害。情报管理是一个循环过程,包含规划与指引(Planningand Direction)、搜集(Collection)、处理(Processing)、分析与产出(Analysisand Production)、发布(Dissemination)5个步骤,其中搜集、处理、分析与产出是数据处理过程[2]。
开源情报具有成本低、信息实时、信息量充足等优势,是一个新兴且具吸引力的情报渠道[3]。当获得情报后需要及时分析,情报分析师依据相关准则与流程[4]对情报进行分析,期间需要运用大量技巧、经验及智慧,这些技巧与经验的积累需要耗费的时间与心力极大,故无法大量为之。因此,各国政府莫不把高水平的情报分析师视为国家重要资产。
1.2 开源情报及处理
开源情报并非是新的情报渠道,第二次世界大战期间,美国中央情报局依据公开信息巴黎柳橙价格波动来判断法国铁路桥是否被炸毁。近代开源情报始于1988年,美国 Alfred M.Gray Jr 将军建议政府把大部分情报搜集汇集在开源渠道[5],2005年美国国家情报总监下设开源中心(Open Source Center),同时也着手训练开源情报分析师。
在开源情报研究上,早期研究大多局限于情报管理与操作规范,例如,北大西洋公约组织(North Atlantic Treaty Organization,NATO)出版的开源情报操作手册[6]。随着互联网发展,北约针对网络开源情报处理也发表了相关著作[7],为该领域研究奠定了基础,然而,以上著作对开源情报自动化处理模式几无着墨。
近年来,开源情报自动化处理吸引了计算机领域学者关注,与情报界不同的是,这些学者关注的焦点是:如何设计程序取代人力进行开源情报处理。情报分析是从海量数据中挖掘有价值信息,与数据挖掘相近,因此衍生出数据挖掘技术与开源情报处理的交汇融合。目前,该领域相关的国际会议仅仅有 International Symposium on Open Source Intelligence and Web Mining(OSINT-WM),会议主题探讨基于网络挖掘与社交网络分析进行的开源情报分析技术,此外,少量欧洲学者论文散见于其他国际会议中。
1.3 情报分析
情报分析是从大量杂乱无章的资料中进行搜集、整理、分析,得到有价值并且能够提供辅助决策信息的过程。情报分析范畴较为广泛,包含不同的情报挖掘方法,常见的有事件侦测、事件关联挖掘、 关键事物侦测、情报可信度评估等[5]。事件侦测指针对特定、新奇、异常事件进行情报挖掘;事物关联 挖掘则是发掘事物间关联,例如恐怖份子间是否有关联(人与人关联)、两件爆炸案间是否有关联(事与事关联)、恐怖分子与爆炸案间是否有关联(人与事关联)等。
事件侦测是指在连续新闻串流中发现新的或之前未发现事件[8-9]的过程,与其相关研究较多,以美国国防部基于多语言文本与语音数据情报挖掘技术的“主题侦测与追踪”计划为最为典型,该计划包 括 5 个方向(见表 1),与事件侦测最为相关的有主题侦测与主题追踪 (Topic Detection and Tracking, TDT),通常使用 k-means、k-nearest neighbors 等算法来进行数据关联分析。
表 1 美国国防部主题侦测与追踪计划
N | 方向 | 功能 |
1 | 报道切割 | 原始资料切割单独的新闻报道 |
2 | 主题追踪 | 找到新进文件是否与先前的主题相关 |
3 | 主题侦测 | 侦测并组织相同主题文件 |
4 | 第一新闻侦测 | 判断新进文件是否为新主题或未讨论过主题 |
5 | 关联检测 | 判断两份文件是否讨论相同主题 |
1.4 数据关联分析
数据关联分析是通过数据分群与标记找出文件数据之间关联的过程,目前有 k-means、k-nearest neighbors、self-organizing map 等算法。Baldini 等在开源情报处理平台 SPY Watch[10-11]中使用 K-means 算法对数据分群以处理不同语言数据,Pfeiffer 等 [12]开发的MPEG-7 系统适用于卫星影像、 电视影像、网页与 RSS 输入等开源数据处理,已应用于早期预警、信息分享与风险评估上;Vincen 等[13]则提出集中式架构融合不同渠道开源信息为应急管理提供服务[14],Badia 等[14]通过文本语句分析获得文件时空信息提供给开源情报分析使用,Palmer[15]通过语意比较与度量,使用 Lavalette 分布取代了语料库分析[16]侦测事件间关联;欧盟委员会联合研究中心(European Commission Joint Research Centre,ECJRC )以二阶段事件淬取系统[17]从主题群组中淬取信息,Wiil 等[18-19]以图论法分析恐怖组织 网络,Bartik[19]使用 tf-idf 加权法来描述数据内容并以视觉特征即文字位置进行数据分类;Dawoud 等 人[20]则通过多个社交网络分析来度量恐怖组织的组织强度,Neri 等[10]以意大利总理的性丑闻为例,通过对新闻文件数据分群挖掘其隐含的关联。k-means、k-nearest neighbors 算法虽然应用较多,但是存在一定局限性,易受离群值影响,需要精确的训练数据集与高强度计算量。
自组织映射 (Self- Organizing Map,SOM)算法是 Kohonen[21]提出的一种对数据进行无监督学习聚类的神经网络模型,具有分群效能好且能够将高维度数据拓朴关系呈现于二维平面,该算法是模仿人 类大脑结构(相似功能脑细胞会聚集一起)与特征映像特性所发展出来的方法。SOM 主要由输入层、 输出层组成(见图 1),
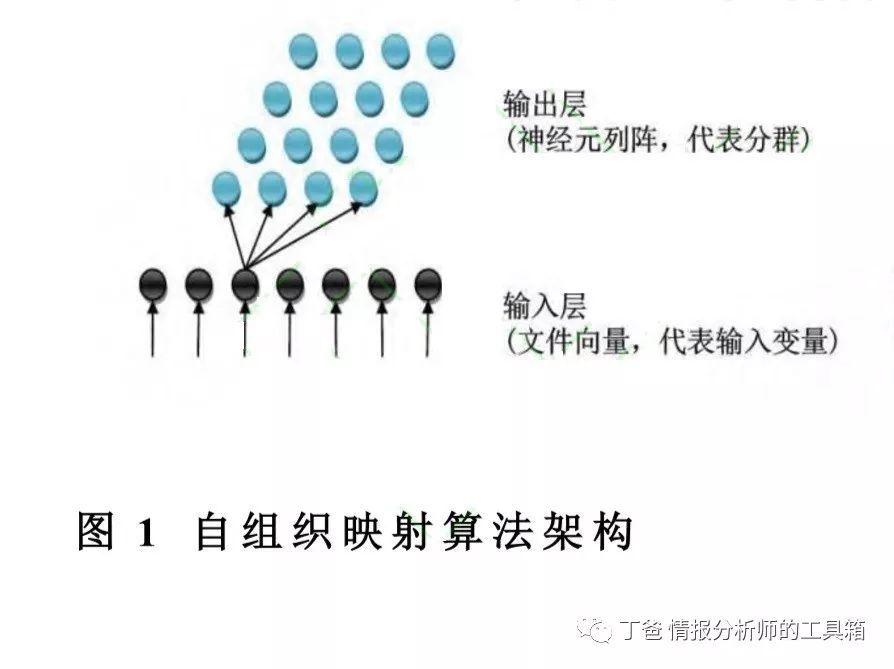
其强度以权重向量表示,全部神经元之间均有链结关系。通过计算文件向量与神经元突触权重向量的距离,来映射文件至神经元上,根据文件相似程度,训练出一个能表现整体的特征图(见图 2)。

2、研究架构
开源情报的来源与种类繁多,本研究将以事件侦测为主,通过文本挖掘技术建立情报挖掘方法,使用自组织映射(SOM)进行数据关联分析。研究仅针对电子格式且以文本格式数据,整体架构包括前置处理、特征淬取、数据分群、标记处理与情报挖掘等阶段。
2.1 前置处理
情报搜集所得文件具有不同格式,包含许多无效文件,前置处理包括文件正规化与无效文件筛选。文件正规化是将不同格式网页标记、多媒体对象、无效字元去除,淬取文字部分,将不同来源文件转换成相同格式的过程,无效文件筛选是删除文件正规化后容量小于20字的无效文件。
2.2 特征淬取
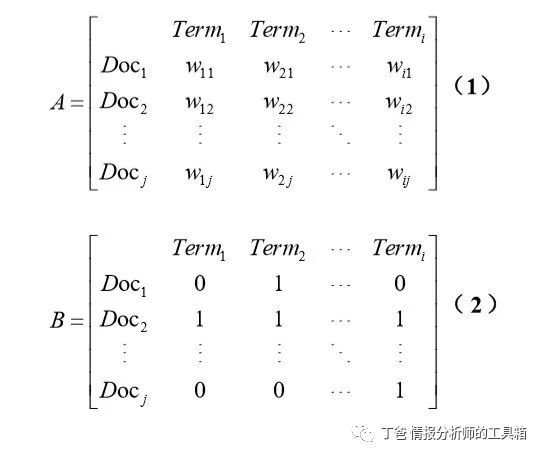
从文件内容中淬取出重要特征集合来代替原始文件,并将其转换为向量格式,该阶段包括断词、 字词处理及其文件向量化。本研究是使用 Part-Of-Speech Tagger[22]软件进行断词及字词处理。在词性标记上选择名词为关键词,采用 Porter 字根还原算法[23]进行字根还原。采用由 Salton 等[24]提出的向量空间模型(Vector Space Model,VSM)转化为向量。向量空间模型是通过关键词与文件组合成了“关键词 —文件”矩阵,便于机器阅读并加快系统执行效能,公式(1)为一个具有 i 个关键词与 j 份文件矩阵, 其中 wij为关键词 i 在文件 j 中的权重值。
在权重计算方面采用二元化权重的向量空间模型,若关键词出现在该文件中,则在该文件向量中相对应元素值为 1,反之则为 0(见公式 2)。
2.3 数据分群
运用 SOM 进行数据关联分析,该算法是一个迭代过程,训练过程如下。
步骤 1:设定训练参数:包含输入层神经元数、输出层神经元数、输入文件向量数、学习速率 (t)、 学习次数 T,并以随机数设定链结权重向量𝑊 𝑖;
步骤 2:执行学习流程:
1)文件向量中随机挑选一个文件向量𝑑𝑗,进行训练;
2)计算𝑑𝑗与输出神经元距离,找出距离最小的神经元 c 为优胜神经元,满足公式(3)。其中𝑤𝑖为第 i 个神经元的权重向量,M 为输出神经元总数。

3)链结权重向量调整法是将优胜神经元 c 与其邻近区域神经元进行调整,更新链 结权重向量满足公式(4)。其中𝑁𝑐为优胜神经元 c 的邻近区域内神经元集合,此邻近 区域将随着训练周期增加而递减,𝛼(𝑡)为训练时间为 t 时的学习速率参数。
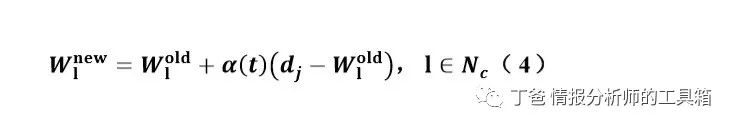
4)重复 1)〜3), 直到所有文件向量都经过一次训练。
步骤 3:检查停止条件:令 t=t+1,假如 t 达到了预先设定总学习次数 T 时,则训练完成;否则就减少学 习速率𝛼(𝑡), 并缩减邻近区域的范围, 回到步骤 2 继续执行训练 。
2.4 标记处理
经过SOM训练后对神经元进行标记处理,标示出优胜神经元后形成文件分群图(Document Cluster Map,DCM) 。DCM是经过计算文件向量与各神经元突触权重向量的距离而产生,突触权重向量距离 为最小的文件标记于神经元上。文件向量依据各文件所包含的关键词来确定,有大量相同关键词的文件表示其相似度很高,则标记于同一神经元上,以了解文件间关联程度。
2.5 情报挖掘
从大量实时情报中,挖掘出刚发生或即将发生的事件,是开源情报分析中的重要任务,也是早期预警不可缺失的步骤[25]。本研究通过两种情报挖掘技术,尝试自开源情报中侦测出重要事件。
2.5.1 主题侦测
通过挖掘文件群组重要关键字词作为分群主题,经由字词标记获得关键字词分群图(Key Word Cluster Map, KCM)。具体方法:检视第 j 个神经元突触权重向量 Wj,若字词所对应元素临界值超过设定值,则将字词标记在该神经元上。元素临界值是指介于 0~1 之间的数值,越接近于1表示重要性越高,则设定为接近于1的数值。在标记处理之后,一个神经元会被数个字词所标记,形成字词群集,依据两个字词在 KCM 中所对应神经元来判断其关系。
2.5.2 特定事件侦测
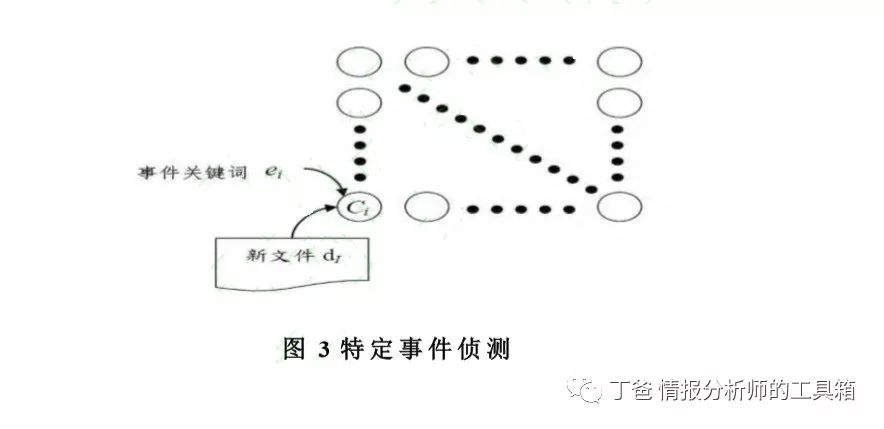
特定事件指使用者关注的事件,如当前中美贸易磋商中关税,设定事件相关关键词后,通过监看新进文件以侦测事件是否发生。假设 E={ei}为关键词集合,在挖掘每个 ei文件集合后, 用下列方式来侦测:对新进文件进行前置处理并转换为文件向量 dI,输入与 DCM 中神经元比较,以找出最近的文件分群 CI。若 CI 与任一事件分群(即 Ci)相同,则 DI 视为使用者有兴趣的特定事件文件 (见图 3)。
3、结果分析
本研究使用标准数据集 Reuters-21578(见图 4)进行文本挖掘,由 D. D. Lewis[23]与路透社工作人 员整理而成,总有 21578 篇新闻文件。该数据分 135 个类别,使用 Modified Apte Split 方法划分为 9603 份训练数据与 3299 份测试数据,经前置处理后各包含 5815 与 2355 份文件,再将这些文件转换为向量, 通过 SOM 建立 DCM。
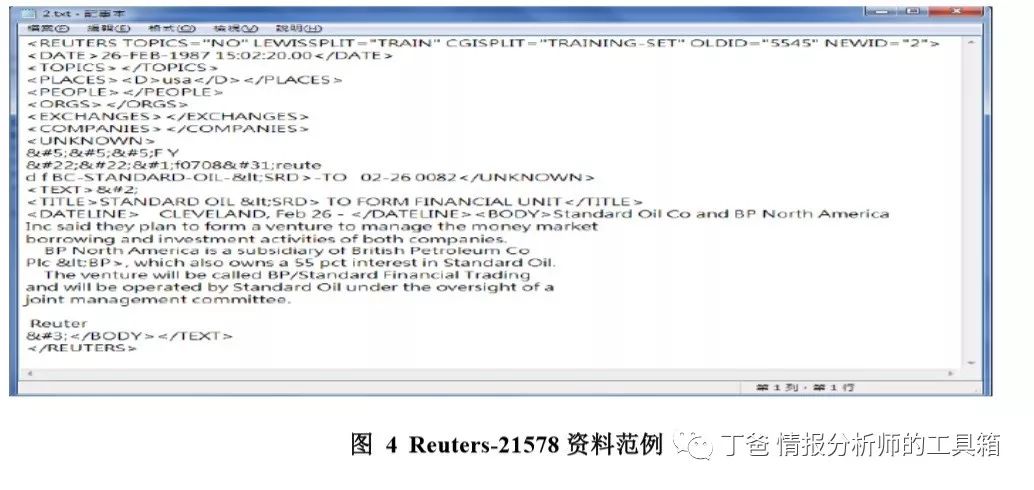
3.1 前置处理
图 5 为前置处理后文件,剔除控制字符与非英文字符,再将字数少于 20 或大于 300 的文件剔除,以降低不良的分群效果 。

3.2 特征萃取
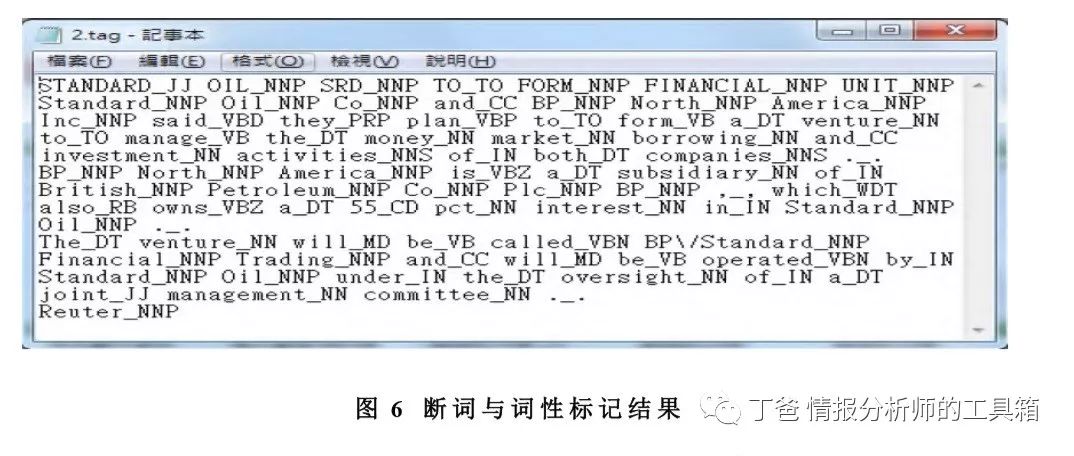
采用 Part-Of-Speech Tagger[14]进行断词与词性标记,过滤标点符号并找出有语意 的词汇(见图 6)。由于使用字词信息进行分群,影响了主题的辨认与学习,过滤了一 些频率较高但无检索价值词汇。此外,英文字词因单复数与时态,通过 Porter 字根还 原算法 [15]进行字根还原,将词汇各种变化格式转换回原来字根,最后筛选出 2740 个关键词。
在完成上述步骤后,接着进行文件向量化。首先从文件集中进行特征选取以形成词汇集,再利用 Salton[26]等的向量空间模型将文件转换后与 SOM 结合,作为 SOM 输入参数,权重部分则是采用二元布尔值作为向量值,即文件中有出现该关键词则设值 为 1 反之为 0。
3.3 数据分群与标记
在 SOM 训练后,将文件标记于 SOM 优胜神经元上,得到 DCM。表 2 为获得最佳 结果的 SOM 统计资料,尝试不同参数范围,神经元数量由100 至225,学习速率由0.2~1,最大训练周 期由 200~1000。
表 2 自组织映射统计资料
参数 | 值 |
自组织映射大小 | 10X10 |
神经元突触数量 | 2740 |
学习速率初始值 | 0.4 |
最大训练周期 | 600 |
3.4 情报挖掘
3.4.1 主题侦测
在进行事件侦测之前,先对文件分群进行主题侦测。由于 DCM 每个群集由词汇特征相似文件组成,文件所采用词汇有很大的重复性且能够反映出文件主题,在训练过程中会得到较高权重值,故可以通过神经元突触向量中关键词权重值的大小来判定该词在分群中的重要程度,而找出每一分群中较为重要的关键词作为分群主题。
门坎值确定方式满足公式(5),其中𝜋1为门坎值,𝑊𝑖𝑗为神经元 i 中关键词 kj对应 的权重值。考虑单一神经元内突触权重,由于权重值越高代表神经元重要性越高,故 将𝜋1值设为 0.9。
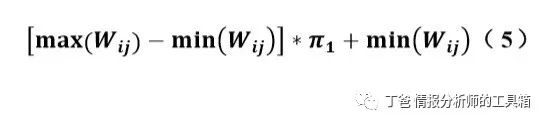
3.4.2 特定事件侦测
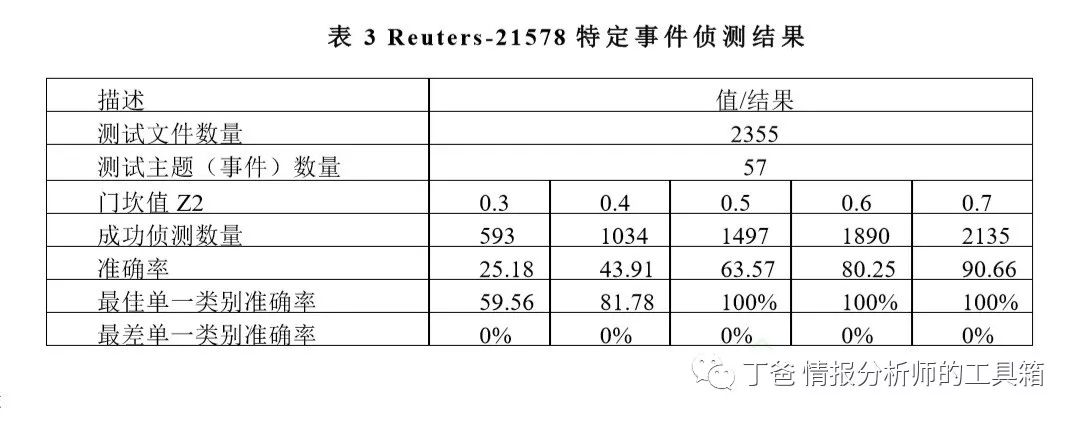
使用 Reuters-21578 类别关键词为事件关键词,超过 20 份文件的类别共 有 57 个,以这些类别的主题作为事件关键词测试,找出关键词所属分群,后从测试数 据集中选取某一类别文件,再将该文件的文件向量与所有神经元相比较,最相近者即为该类别主题所属的文件分群,则将其视为一个成功的侦测。采用准确率(成功侦测 数量/测试文件数量)作为评估侦测效能的指标。实验结果见表 3,在门坎值为 0.3 时, 测试文件数量为 2355 笔,成功侦测数量为 593 笔,准确率=593/2355=25.18%。
2355 份文件分别来自 57 个类别,从一个类别中抽出一份文件来计算与所有文件分 群距离,当这份文件与文件分群距离小于一定范围时,认定文件属于该文件分群 C, 其范围为 DCM 中所有文件与该文件分群距离的一定比例下,满足公式( 6)。其中𝜋2为 门坎值,𝐶𝑖为文件分群𝐶𝑖突触权重向量,𝑑𝑖为该分群中的文件。图 7 为各个类别于不同门坎值下之特定事件侦测准确度。
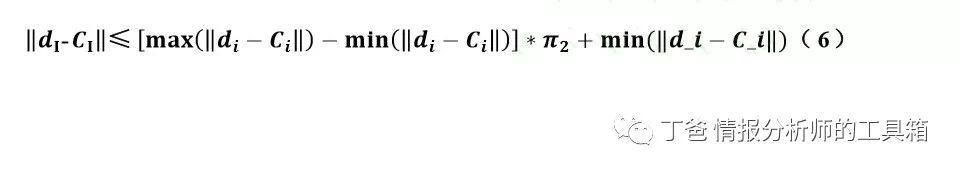

从表 3 发现,当门坎值从 0.3 逐步调整到 0.7 时,其最差准确率仍然为 0%,检查数据后发现,造成该结果的原因在于某些类别文件数量过少,如 retail 与 stg 这两个类别,在测试数据集中仅仅有一 份文件存在,所以其准确率非 0%即 100%,致使最差准确率始终相当低。Reuters-21578 数据集各类别的文件数量极度不均,在进行 SOM 训练时,会导致神经元对某些类别训练不足,致使后续事件侦测上有些类别准确率较低,对这类文件无法有效侦测。今后应用中,如果能够以文件数量均匀的数据集进行训练,相信能提高其准确度。
在中美贸易磋商中,情报能力直接影响着谈判策略甚至最终结局,可以预先设定关注事件,通过特定事件侦测获得事件有价值信息。首先针对关注事件设定关键词,后通过主题侦测找出关键词所属 文件分群,之后监测这些分群,根据侦测结果,如果有文件被标记于受监测分群上,即代表侦测出使用者关注的事件。通过特定事件侦测,可以降低大数据环境海量信息中寻找特定事件所花费的时间, 满足特定事件情报需求。
4 、结束语
大数据时代,信息量急剧增长,信息的复杂度与多样性亦随之成长,开源情报处理已然超过人类处理极限,发展半自动乃至全自动的情报分析方法迫在眉睫。本研究以标准数据集进行实验,运用自组织映射算法进行数据关联分析,发展出自动化情报挖掘技术,以侦测开源情报中有价值信息,得到令人满意的结果。情报循环包含五大步骤,本研究针对开源情报的分析与产出步骤进行探讨,在假设 所有的数据皆为可信且有用前提下进行事件侦测,所得结果满足了特定事件情报需求。本研究针对开源情报的管理与分析方法,降低了情报分析上大量人力的需求,破解了情报搜集危险与不易获取的困境。
参考文献
[1] BEST R A,CUMMING A. Open Source Intelligence (OSINT): issues for congress[EB/OL].[2019-02-14].https://fas.org/sgp/crs/intel/RL34270.pdf.
[2]JOHNSTON R. Analytic culture in the US intelligence community: an ethnographic study[EB/OL].[2019-02-14].https://www.cia.gov/library/center-for-the-study-of-intelligence/csi-publications/books-and-monographs/analytic-culture-in-the-u-s-intelligence-com munity/index.html
[3] 冯静.开源情报在国防技术转移中的应用研究[J].情报理论与实践,2018,40(12):67-69.
[4]HEUER, RICHARDS J. Psychology of intelligence analysis. chapter 2.perception: why can"t we see what is there to be seen? [EB/OL].[2018-12-09]. https://www.mendeley.com/catalogue/perception-cant-we-see-seen/.
[5]GRAYA M. Global intelligence challenges in the 1990"s[J].American Intelligence Journal,1990:37-41.
[6]NATO.NATO open source intelligence hand book [EB/OL]. [2018-12-10].https://en.wikipedia.org/wiki/NATO_Open_Source_Intelligence_Handbook
[7]NATO. Intelligence exploitation of the Internet [EB/OL].[2018-12-10].https://www.yumpu.com/en/document/view/5887778/nato-intellige nce-exploitation-of-the-internet-the-air-university.
[8]ALLAN J. On-line new event detection and tracking[C]. International Conference on Research & Development in Information Retrieval,1998.
[9]YANG Y,PIERCE T,CARBONELL J. A study of retrospective and on line event detection[M]. Special Interest Group on Information Retrieval’98.Australia: Melbourne Press,1998.
[10]NERI F, PRIAMO A. SPY Watch overcoming linguistic barriers in information management[C]. Intelligence and Security Informatics: European Conference on Intelligence and Security Informatics. Denmark: Esbjerg Press,2008.
[11]NERIF,GERACI P. Mining textual data to boost information access in OSINT[C]. the13thinternational Conference on Information Visualization. Spain :Barcelona Press, 2009.
[12]PFRIFFFER M,AVILA M,BACKFRIED G, et al. Next Generation Data Fusion Open source Intelligence (OSINT) System Based on MPEG7[EB/OL].[2018-12-19] http://xueshu.baidu.com/usercenter/paper/show?paperid=f0618f4fb8c5c784a36eb12df456 5800&site=xueshu_se.
[13]VINCEN D,STAMPOULI D,POWELLG. Foundations for system implementation for a centralized intelligence fusion frame work for emergency services[C].the12thInternationalConferenceonInformationFusion.Seattle:WA Press,2009.
[14]BADIA A,RAVISHANKAR J,MUEZZINOGLU T. Text extraction of spatial and temporal information[C].the 2007 International Conference on Intelligence and Security Informatics. San Diego: CA Press,2007.
[15]PALMER J. Textually retrieved event analysis toolset[C]. Military Communications Conference.Atlantic City:NJ Press,2005.
[16]ATKINSON M,BELAYEVA J,ZAVARELLA V, et al. News mining for border security intelligence[C].IEEE International Conference on Intelligence and Security Informatics.Vancouver:BC Press,2010.
[17]JIANG J,CONRATH D.Semantic similarity based on corpus statistics and lexical taxonomy[C].International Conference on Research in Computational Linguistics. Taipei, Taiwan Press,1997.
[18]WIIL U K , MEMON N , KARAMPELAS P. Detecting new trends in terrorist networks[C].the 2010 International Conference on Advances in Social Networks Analysis and Mining. Odense: Denmark University of Southern Denmark Press,2010.
[19]BARTIK V. Text-based web page classification with use of visual information[C].the 2010 International Conference on Advances in Social Networks Analysis and Mining. Odense: Denmark University of Southern Denmark Press,2010.
[20]DAWOUD K,ALHAJJ R, ROKNE J G.A global measure for estimating the degree of organization of terrorist networks[C].the 2010International Conference on Advances in Social Networks Analysis and Mining. Odense: Denmark University of Southern Denmark Press,2010.
[21]KOHONEN T. Self-organized formation of topologically correct feature maps[J]. Biological Cybernetics,1982,43(1):59-69.
[22] Stanford log-linear part-of-speech tagger[EB/OL].[2019-02-10] http://nlp.stanford.edu/software/tagger.shtml.
[23] PORTER M F. An algorithm for suffix stripping[J]. Program,1980,14(3):130-137.
[24]SALTON G, et al. A Vector space model for automatic indexing [EB/OL].[2019-02-10] https://www.researchgate.net/publication/200773081_A_Vector_Space_Model_for_Autom atic_Indexing.
[25] 胡望洋.灾难现场应急管理[M].北京:中共中央党校出版社,2018:9.
[26]SALTON G ,WONG A ,YANG C S. A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
本文为全国教育科学规划课题“总体国家安全观视野下公安院校反恐人才的培养目标、能力评价与培 养模式研究”的成果,项目编号:BIA170221。
文章来源:《情报理论与实践》网络首发论文
网络首发日期:2019-09-02 引用格式:胡望洋,邵安,舒洪水.基于事件侦测方法的自动化开源情报分析研究.情 报理论与实践. http://kns.cnki.net/kcms/detail/11.1762.G3.20190830.1550.002.html
作者简介 :
胡望洋(ORCID:0000-0001-7724-2698),男,1970年生,博士生,教授。研究 方向:公共安全与危机管 理 。
邵安(ORCID:0000-0003-4509-500X), 男, 1981年生 , 博士 , 副教授 , 研究 方 向 :公共安全与应急管 理 。
舒洪水 (ORCID:0000-0001-7855-081X),男,1972年生,教授 ,博士生导师。研究方向 :暴恐犯罪与反恐对策。
声明:本文来自丁爸 情报分析师的工具箱,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
