
分享嘉宾:王学志 贝壳 资深工程师
文章整理:李光明
内容来源:贝壳找房知识图谱技术大会
出品平台:DataFun
导读:
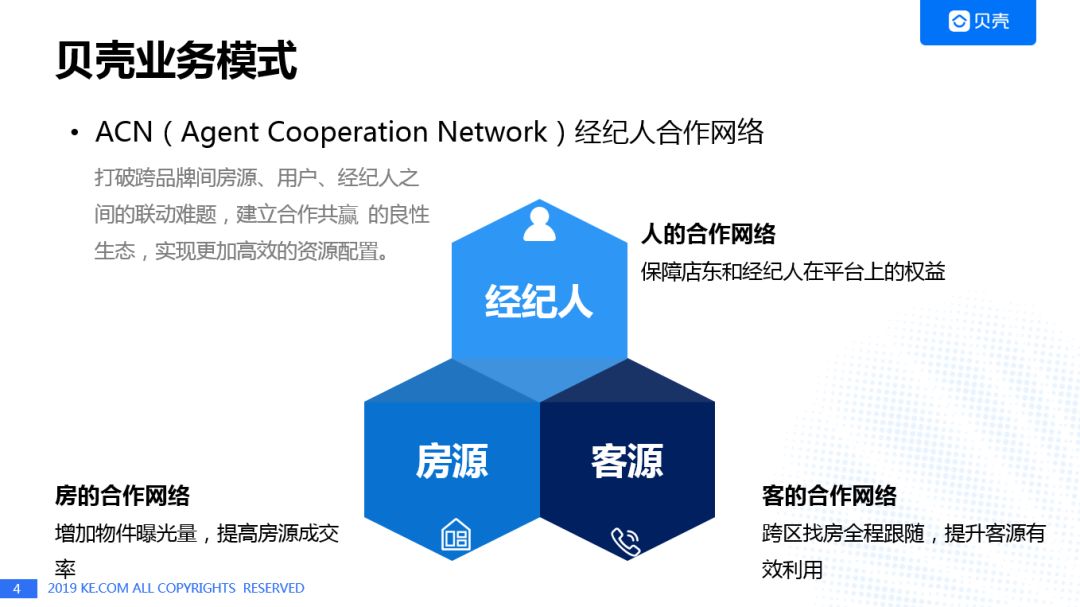
风控是与具体业务强相关的技术领域,贝壳的ACN(Agent Cooperation Network,经纪人合作网络)业务模式旨在打破跨品牌间房源、用户、经纪人之间的联动难题,建立合作共赢的良性生态,实现更加高效的资源配置,并在此业务模式下,逐步建立了经纪人,房源,客源间的利益联盟和信任联盟,以及为经纪人服务的尊严联盟,品质联盟和网络联盟。围绕贝壳的ACN业务模式,从以下三方面介绍贝壳的风控体系:
贝壳风控的业务概况
关系图谱在贝壳风控的应用与实践
关系图谱的规划
贝壳风控的业务概况
首先分别介绍贝壳的风控业务风险,风控特点以及对应的风控体系。
1. 贝壳的业务风险

虚假房源/客源/带看带来的“虚假繁荣”,其短期影响有限,但长此以往,会损害平台的信誉度,严重影响用户体验,从而导致客源及房源的流失,降低平台吸引力;
爬虫导致的资源泄露,以及经纪人违规的体外行为(绕过平台促进成单),都存在损害平台收益的风险;
藏房,藏客以及低费率等经纪人间的恶意竞争有违贝壳的平台规则,给平台健康生态的构建带来了风险。
2. 贝壳的风控特点
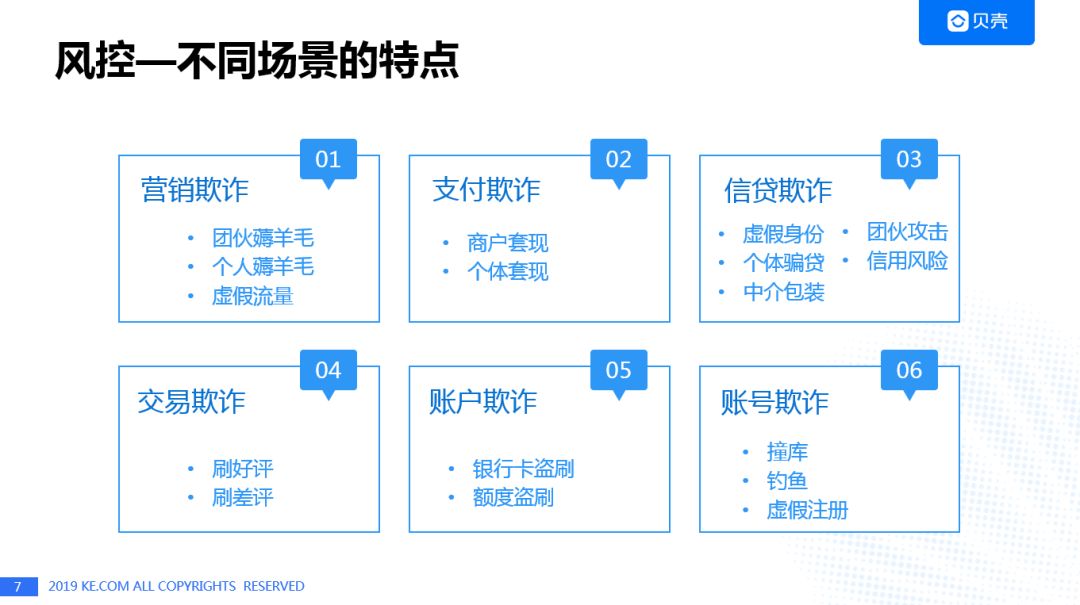
业界的风控大多体现在线上场景,而贝壳多元化的业务场景中:
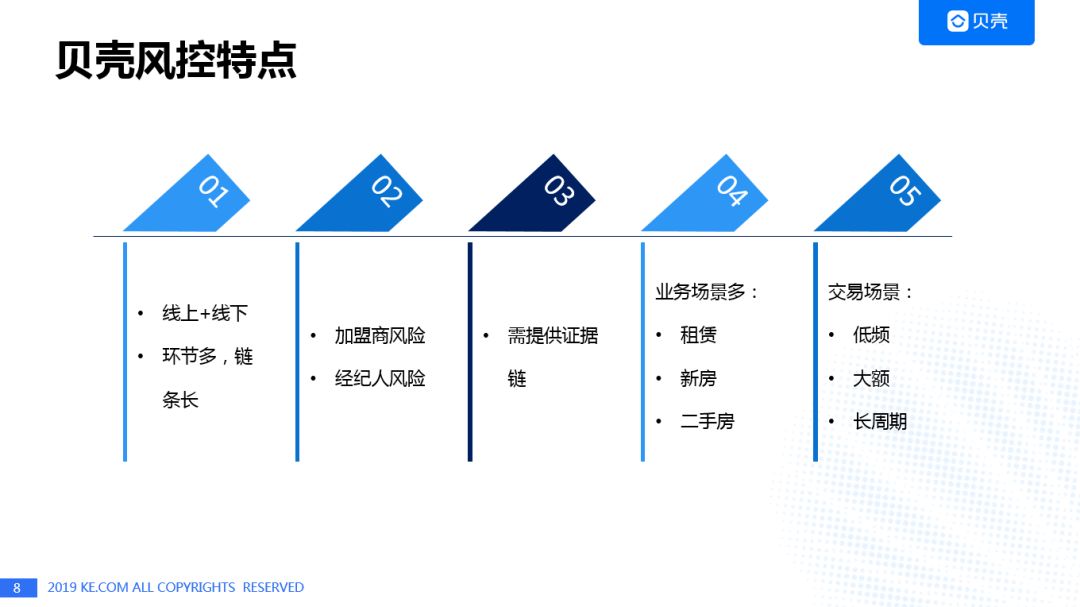
涉及了线上+线下的多个环节,给风控带来了额外的高难度,而在整个环节的长链条中混杂的各种小B(business)/大B的违规行为,更加剧了平台的加盟商风险和经纪人风险,这就要求贝壳的风控体系,不仅能够识别风险,同时还需要提供可解释的,完备的证据链。尤其是贝壳特有的低频、大额、长周期的交易属性,有别于业界普遍存在的高频、小额、短周期的场景,是风控体系的重点与难点。
3. 贝壳的风控体系
结合业务场景和风控特点,贝壳构造了如下图所示的层级风控体系:
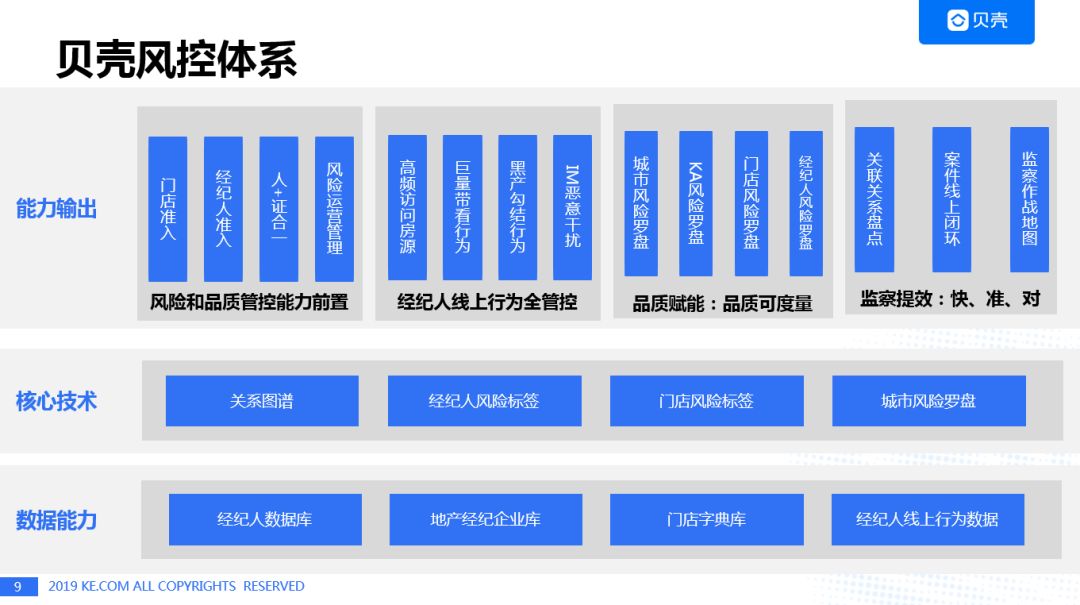
最底层是数据能力层,提供包括经纪人数据,房产/地产数据,门店数据以及经纪人行为数据在内的全量的业务相关数据;其上层为核心技术层,利用关系图谱挖掘风险关系,同时提供经纪人风险标签,门店风险标签以及城市的风险罗盘;最后的能力输出层可分为事前、事中和事后三个环节:事前环节,主要在门店/经纪人准入阶段发挥作用,确保“我是我”的经纪人/门店真实性和有效性;事中环节主要通过管控经纪人的线上实时行为进行风险刻画,同时会构建经纪人的风险罗盘,便于了解风险态势的变化;而事后环节可以通过举报,系统主动识别等方式找到问题门店/经纪人,并通过关联关系提供完备的证据链。
关系图谱在贝壳风控的应用与实践
1. 为什么用关联关系

人力介入程度从高到低的风控手段依次包括黑名单机制,专家规则,有监督的模型,关联图谱以及行为序列分析五个层次,其中黑名单机制,专家规则都需要较高的人力成本,而且从行业现状来看,很难构建一份完整的业界黑名单,从而导致黑名单机制的可实施性较差,而专家规则过度依赖专家经验,存在较高的经验误判风险,主观犯错概率较大,因此通过黑名单或专家规则的方式,很难构建切实可行的风控体系,而监督模型方法的难点在于样本的定义与构造,因此关联图谱和行为序列分析这种自动化识别风险的方法吸引了越来越多的关注。
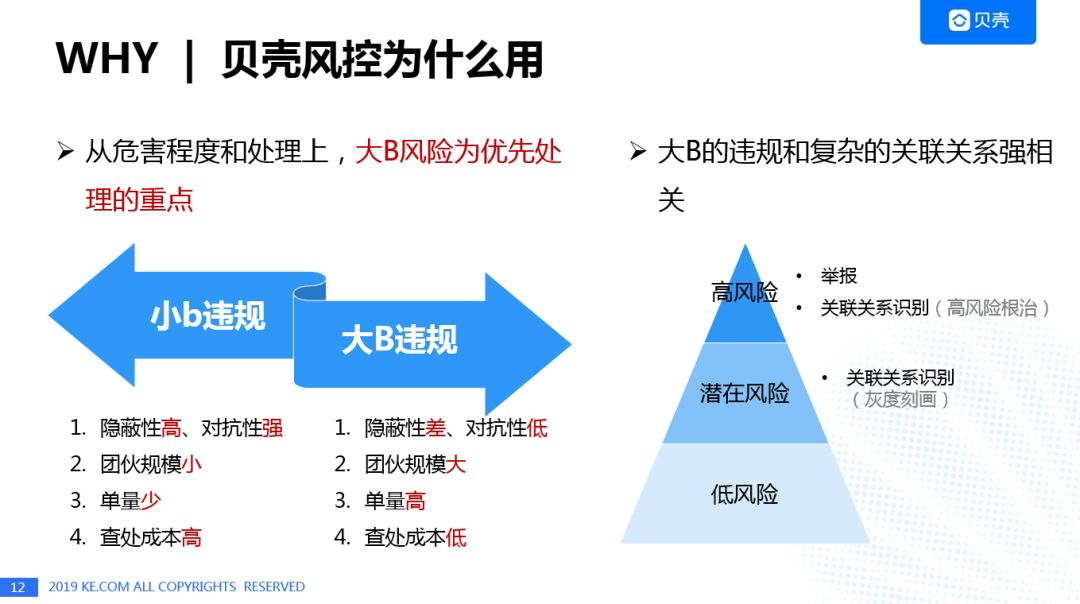
贝壳之所以使用关联图谱的出发点还是出于贝壳业务中常见的小B风险和大B风险的权衡考虑。大B风险具有隐蔽性差,团伙规模大,单量高以及查处成本低等特点,在危害程度上高于小B风险,因此需要重点控制大B风险。另外,从针对大B的违规行为中分析发现,与关联关系强相关的违规行为占比达到29.3%,因此关联关系在贝壳风控体系中的作用,总体上可以表述为先通过关联关系或举报发现高风险的违规行为,而后可利用关联关系识别中低风险的违规行为,进而实现对“黑”,“灰”,“白”三个不同层次违规行为的监控和打击。
2. 贝壳的关系图谱
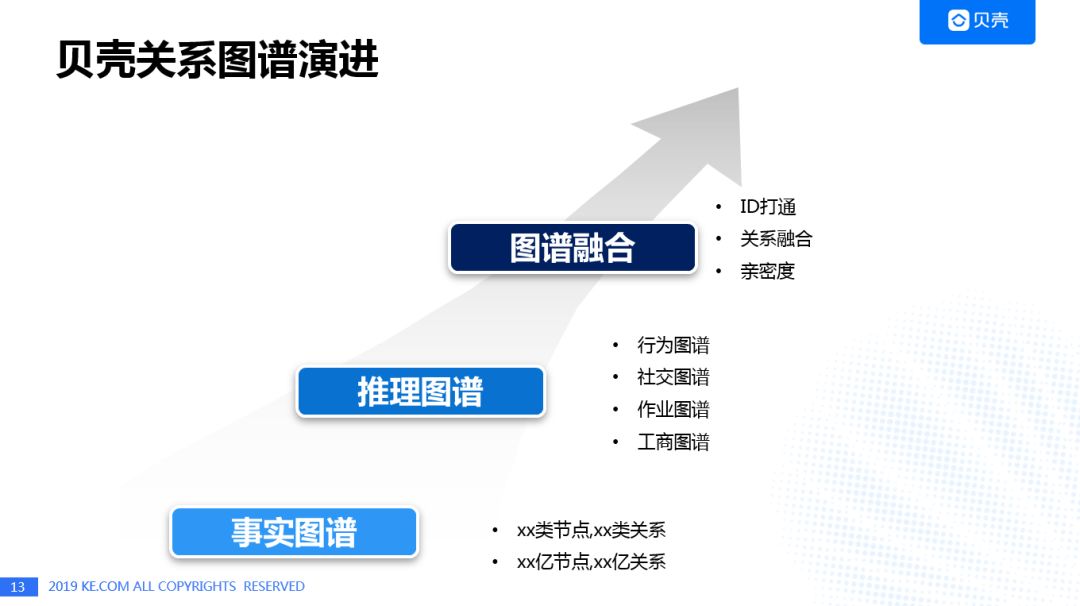
贝壳风控的关系图谱经历了事实图谱 -> 推理图谱 -> 图谱融合三个阶段的演进。事实图谱涵盖了贝壳找房所有线上的动作和行为,形成了10亿级节点,100亿级边的巨大图谱;推理图谱构建在事实图谱基础上,利用不同节点间的关系,分别构建行为图谱,社交图谱,作业图谱和工商图谱,这也是贝壳风控目前所处的阶段;而未来的图谱融合阶段,会利用ID打通,完成多个推理图谱的关系融合,进而完成人与人之间亲密度的定性或定量的表达,从而实现深层次的风险控制。
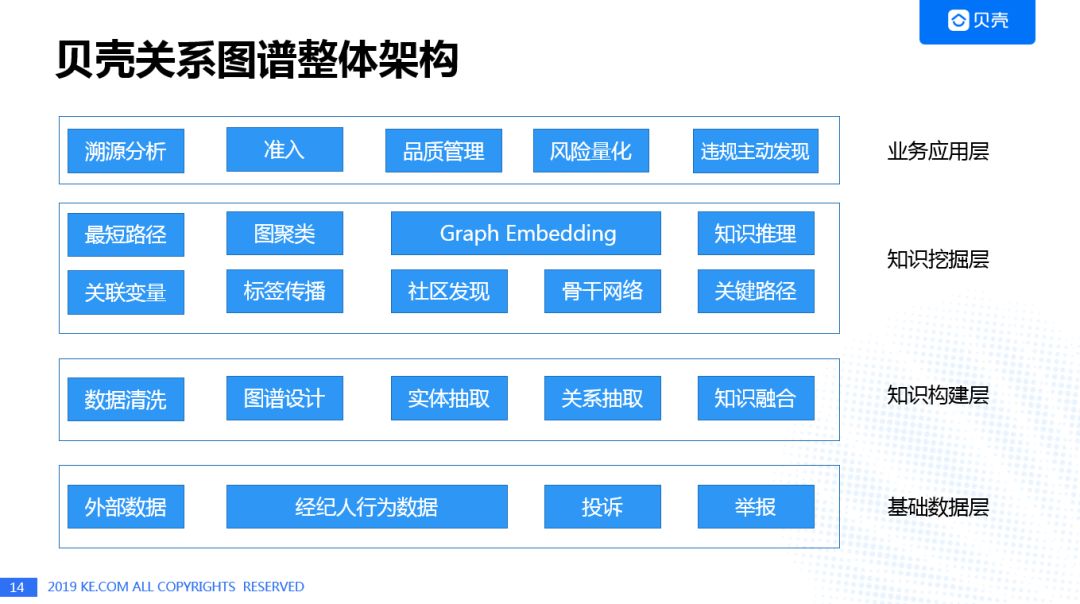
贝壳关系图谱的整体架构主要包括四层:基础数据层负责收集各种来源的行为和属性数据;知识构建层通过多种手段抽取实体和关系,完成构图;知识挖掘层会结合传统的最短路径/关键路径方法,以及社区发现,标签传播和Graph Embedding等机器学习方法,进一步挖掘节点之间的关系;业务应用层基于关联图谱提供了溯源分析,风险量化,违规行为主动发现等业务能力。
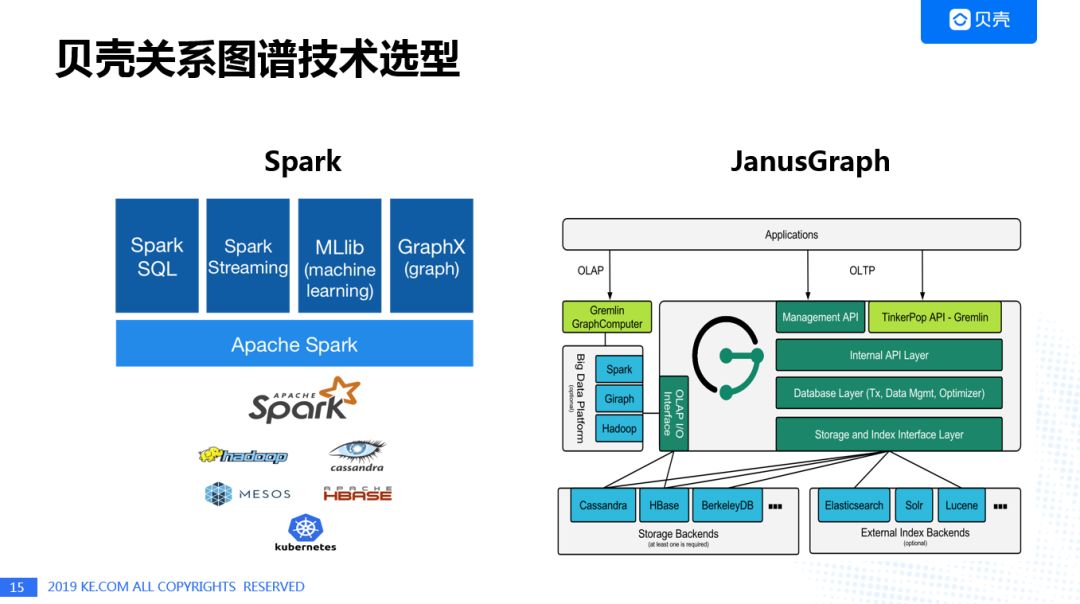
贝壳的关联图谱技术选择了Spark GraphX作为图分析的工具,Janus Graph作为图查询的工具,之所以选择GraphX主要是考虑Spark拥有较完备的社区支持,并且GraphX实现了Gradle在Spark上的重写,具有较高的效率;而选用Janus Graph主要是出于业务场景中较多的图的可视化以及溯源分析的需求考虑。
3. 贝壳关系图谱的应用

从前文的贝壳关系图谱的整体架构可以看出,在应用层,关系图谱提供了准入防控,风险量化,品质管理,风险发现,查案溯源等能力。

准入防控,主要利用path searching,risk path ranking技术,解决风控关系传播中长路径下的风险识别能力,可以进行针对门店的体外公司搜索(包括多种变种),负面信息评估(路径上是否存在失信人员,被投诉人员等),人员历史风险,以及针对经纪人的信息交叉验证,关联关系扫描以及黑灰白的分级。
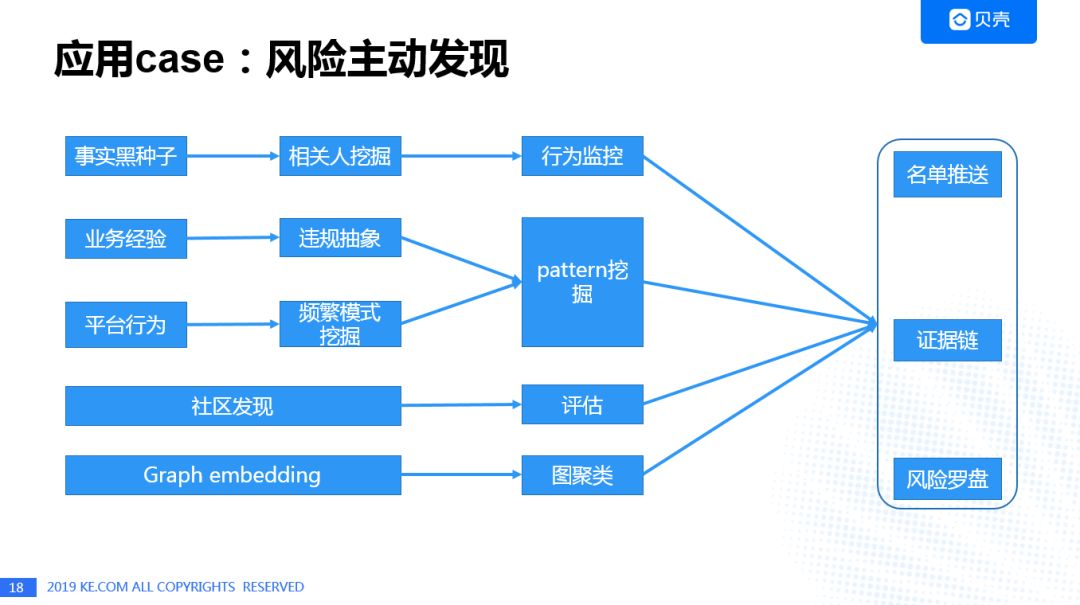
风险主动发现,主要有三种手段:
① 基于举报获得风险种子人群,利用关系图谱监控相关人的行为,发现“白”到“灰”、“黑”的变化;
② 基于用户行为以及行业经验的模式提取与搜索;
③ 社区发现的Louvain算法以及Graph Embedding的自动化机器学习挖掘风险方法(下面有进一步介绍)。
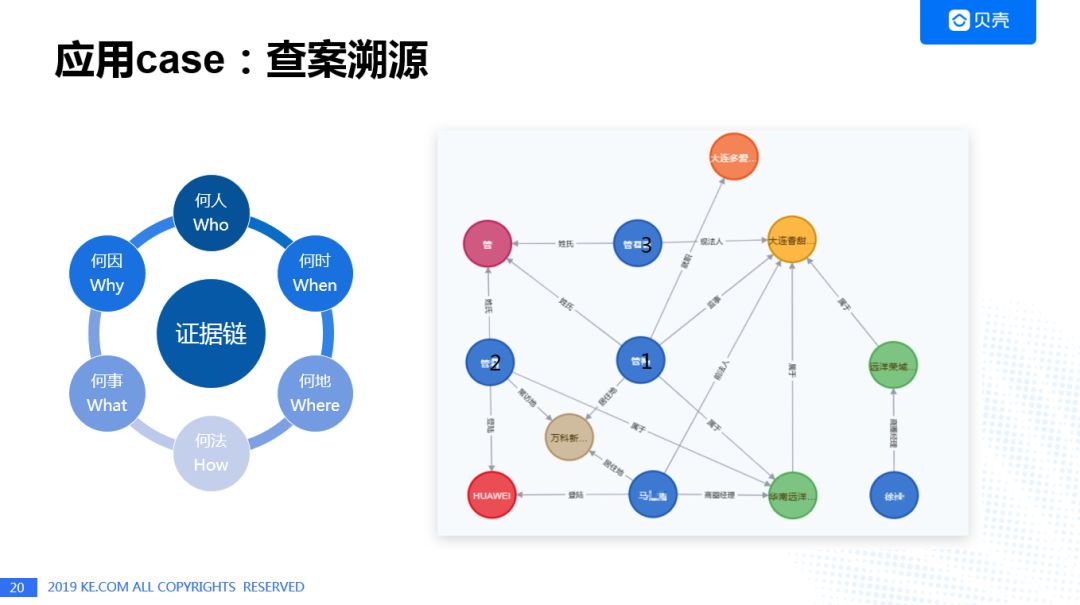
查案溯源,根据种子风险节点的多维属性,探索多条关系路径,找到相关人,进而判断亲密度,发现潜在的风险团伙。
4. 社区发现和自动化机器学习

Louvain是一种经典的基于图的社区发现算法,其优化目标为尽可能提升图的模块度(衡量社区紧密度的标准),模块度提升的定义如下:
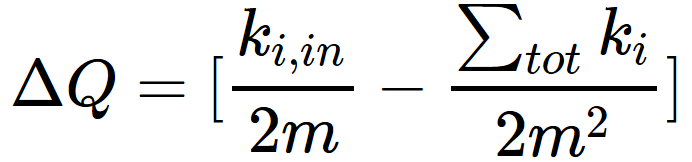
其中前面一项为节点加入邻居社区后,社区内的所有边,后一项代表节点加入邻居社区后,社区所有边(包括内部边,以及连接外部的边),目的是希望变化后的子社区内边多,外边少,即社区更聚集。
Louvain是一种迭代式算法,每一轮迭代可以分成两个步骤:
① 算法扫描图中的所有节点,针对每个节点遍历该节点的所有邻居节点,衡量把该节点加入其邻居节点所在的社区所带来的模块度的提升,并选择对应最大收益的邻居节点,加入其所在的社区,这一过程化重复进行直到每一个节点的社区归属都不再发生变化;
② 对 ① 中形成的社区进行折叠,把每个社区折叠成一个单点,此时新生成的节点之间的边的权重为两个结点内所有原始节点的边权重之和。重复以上两步,多轮迭代直至算法收敛,则可以发现图上的多个社区。
Graph Embedding是图表达的一种方法,其大概思想是将图数据转化为序列数据,进而利用word2vec等处理序列数据的方法得到图中结点的向量化表示,而这样的转化通常可以通过图上的随机游走来完成,Node2Vec就是结合了深度优先和广度优先的图游走方法。
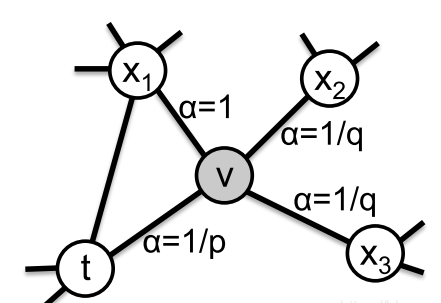
如上图所示,当从结点t走到节点v时,面临的选择可以分为三种:
① 返回节点t;
② 走到与节点t具有一度关系的节点x1;
③ 与节点t有二度关系的节点x2或x3。利用p和q控制着路径返回和继续探索的关系,如果倾向于深度探索,可以将q设置小一点,p设置大一点。
关系图谱的规划
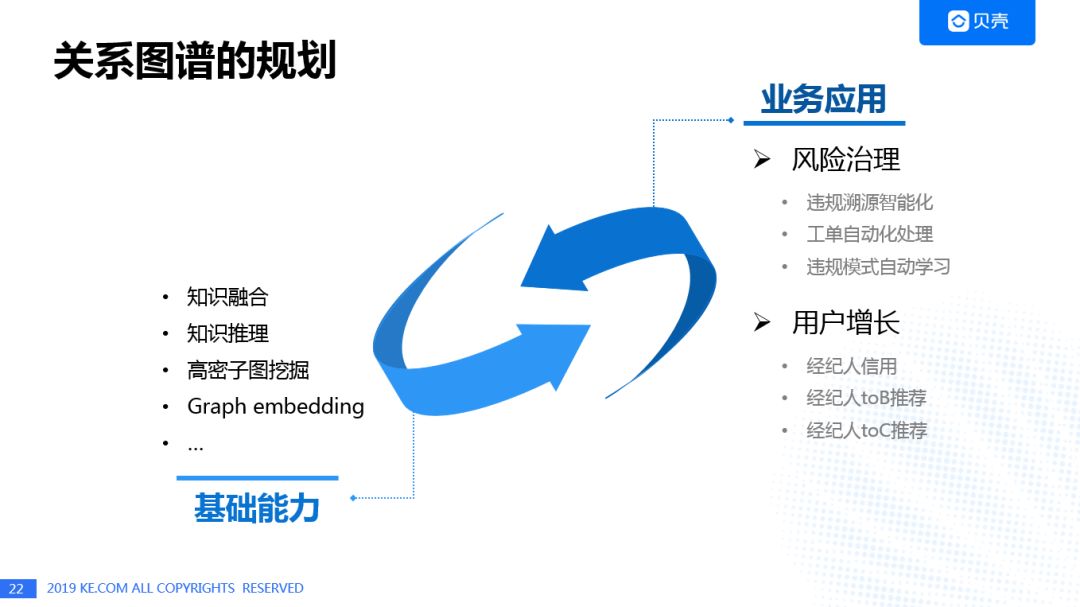
高密子图的挖掘是社区发现的升级,可以更好地发现团伙,结合关系融合,以及Graph Embedding算法,共同提升关系图谱的基础能力。在此基础上的业务应用,可以推广到风险治理和用户增长等场景。
本次分享就到这里,谢谢大家。
分享嘉宾

王学志
贝壳 | 资深工程师
声明:本文来自DataFunTalk,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
