
作者 | 蔡芳芳
近两年,联邦学习发展迅速,开始从理论研究迈向批量应用的落地阶段,越来越多企业尝试引入联邦学习,用它来解决人工智能大规模落地过程中遭遇的数据瓶颈问题。但现成的联邦学习工具和框架并非拿来即用的“灵丹妙药”,联邦学习要真正在企业实际业务场景中发挥作用,仍有许多问题需要摸索,比如如何匹配业务的实际需求、如何兼容现有业务流程、如何尽可能减少对已有训练系统的改动等。为此,InfoQ 采访了腾讯 TEG 数据平台部的智能学习团队,深入了解联邦学习在腾讯的实践情况,以及他们对联邦学习技术难点的解决思路。
联邦学习技术发展历程
早在 2016 年,谷歌就在论文 《Federated Learning: Strategies for Improving Communication Efficiency》 中率先提出了 Federated Learning(联邦学习)的概念,主要用来解决联合存在于多个终端(例如移动手机)中的数据进行中心化模型训练的问题,并应用在输入法改进等场景。
但此后相当一段时间里,联邦学习一直处于理论研究的阶段,并没有太多落地的案例。这其中可能有几方面的原因:首先是缺少需求,最近两三年人工智能飞速发展,已经到达落地的阶段,必然面临着数据从哪里来、如何打通等问题,但在这之前没有数据打通的问题,自然也就不会有联邦学习的需求;其次是技术成熟度不够,谷歌提出的 Federated Learning 模型中,需要有一个中心服务器,负责收集各方训练好的本地模型进行聚合,那么问题就在于这个中心服务器是否可信可靠?另外,这个模型要求不同参与方的数据属性是相同的,例如张三和李四的数据都要求是年龄、身高、性别,虽然他们的具体数值不同,但属性必须一致。
在 2019 年初发表的论文 《Federated Machine Learning: Concept and Applications》 中,香港科技大学的杨强教授进一步发展了 Federated Learning,提出了 Horizontal(横向)和 Vertical(纵向)Federated Learning 两种 框架,如下图 1 所示,其中,谷歌提出的模型可以算作横向联邦的一种。
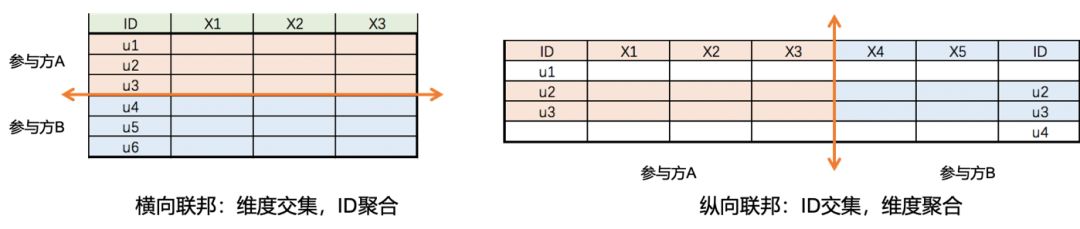
图 1. 联邦学习两种形态:横向、纵向
随着技术不断发展成熟,以及人工智能落地过程中数据痛点愈发凸显,联邦学习得到了更多的关注,学术界和工业界开始联合起来系统化地研究整个 技术体系,也有越来越多企业开始尝试引入联邦学习并将其作为打通多方数据的一种解决方案。
腾讯联邦学习实践
基于 2016 年推出的自研分布式机器学习平台 Angel(2017 年在 GitHub 上开源),腾讯 TEG 数据平台部的 Angel 智能学习团队正在进行联邦学习项目的攻坚工作。据介绍,Angel 联邦学习的发展,主要来自业务需求的驱动。
在机器学习,尤其是深度学习中,模型的获得需要大量的训练数据作为前提。自 2016 年年初在腾讯内部上线以来,Angel 已应用于微信支付、QQ、腾讯视频、腾讯社交广告及用户画像挖掘等业务。随着 Angel 在公司内部和合作伙伴中应用越来越广泛,在很多业务场景中,模型的训练数据往往分散在各个不同的业务团队、部门,甚至是不同的公司内。例如,广告推荐的模型要想获得针对每个用户的精准推荐效果,除了用户的基本自然属性之外,还需要这个用户的行为数据,比如网页浏览行为、上下文信息、购买支付行为等等,但这些行为数据通常在浏览器、新闻站点、游戏或内容等其他产品中,无法直接用来训练广告模型。如何在保护用户隐私的前提下,联合多个数据源进行模型训练,成为 Angel 智能学习团队的一项新挑战。
2019 年 10 月初,团队内部成立专项组,着手研发联邦学习平台。首先梳理整合业务需求,找到共性的关键问题;然后调研学术界和业界是否有成熟的解决方案,能满足业务场景;最后重点解决落地问题,即安全、易用、高效和稳定。
其中业务需求方面主要有以下几个特点:
90% 的场景是纵向联邦学习的问题,即 ID 相同、在数据维度上联合建模。以广告为例,一方有用户的基本画像,主要是静态标签,而另一方则有其购买行为、兴趣等信息,需求是如何安全有效地联合两方的数据。
用户普遍关心安全问题,即学习过程是否安全。除了最终产出的模型参数,过程中不应该泄露任何一方的数据信息,也不可以反推数据信息的中间结果。
效率和稳定问题,平台的训练速度不能太慢,而且要稳定,降低问题调查、任务重跑等代价。
要能兼容现有的业务流程,不要对现有训练系统改动太大。另外要容易部署,系统不能太复杂。
基于对业务和现有技术方案的调研,团队重新设计了一种“去中心化”的联邦学习框架,无需依赖可信第三方。整个系统以 Angel 的高维稀疏训练平台作为底层,抽象出“算法协议”层,供实现各种常见机器学习算法。
Angel 联邦学习系统架构
从技术层面看,分布式机器学习平台 Angel 的架构如图 2 所示,其核心组件是 Angel PS 参数服务器。在机器学习领域,当模型的参数规模达到高维例如千亿时,单台机器内存已经无法容纳下这样大规模的数据,必须借助于分布式的方式,利用多台机器一起才能完成训练任务,而参数服务器就是其中比较好的解决方案。Angel PS 针对高维稀疏场景做了大量优化,比如对参数更新做批量处理,将很多在 worker 上的计算提升到 PS 端计算,提升了计算效率和一致性,加快算法收敛速度。Angel PS 目前支持万亿级模型。同时,整个 Angel 平台底层基于 Spark 搭建,利用 Spark RDD 的高效和灵活性,很容易与大数据系统如 HDFS 等数据打通,兼容性高;后端可以接入 TensorFlow、PyTorch 等作为运行时算子。
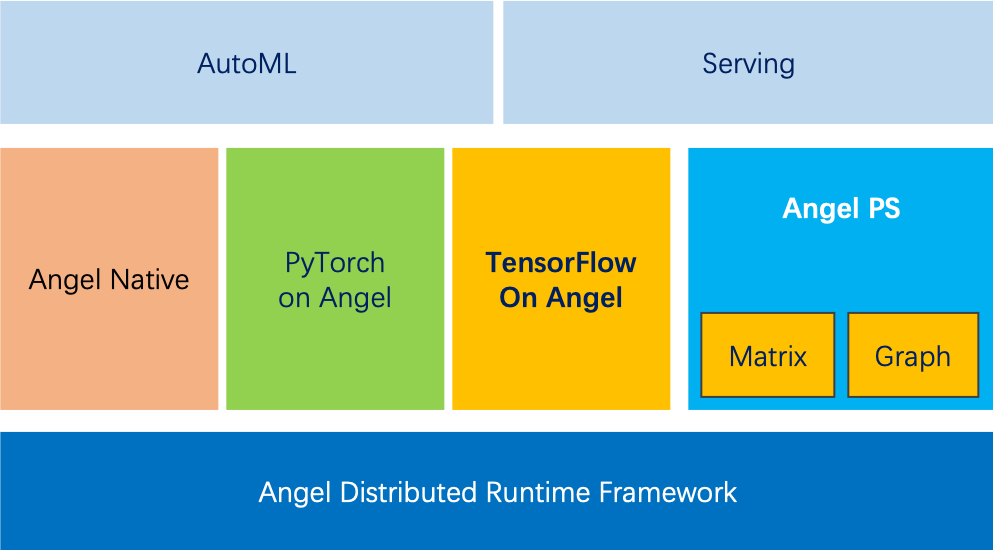
图 2. Angel 机器学习平台架构
腾讯目前整个联邦学习框架构建在 Angel 之上,以两个业务方 A 和 B 为例,Angel 联邦学习系统架构如图 3 所示(也可以扩展到多个参与方的场景)。
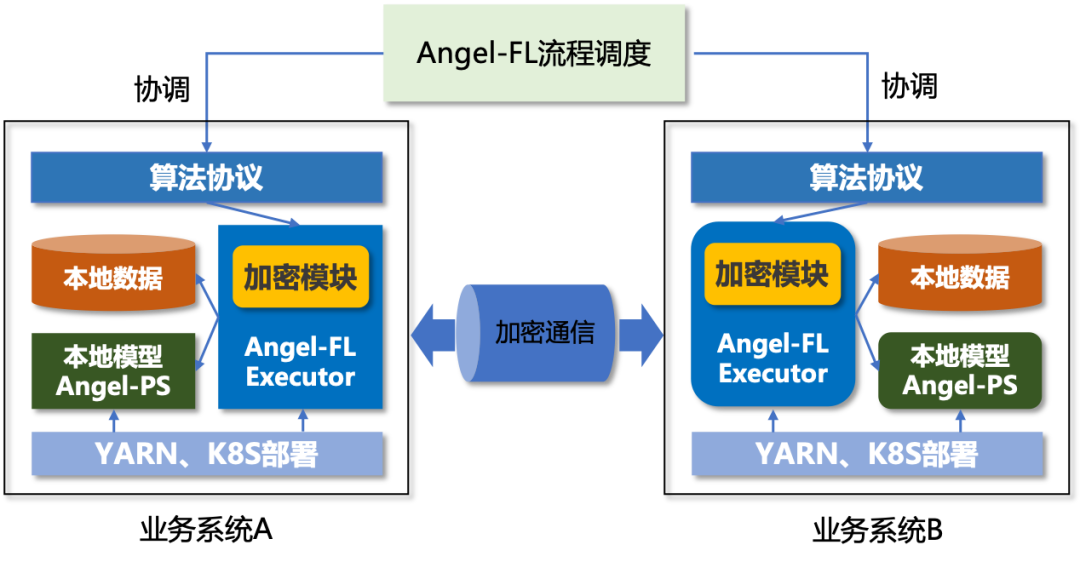
图 3. Angel 联邦学习系统架构
A、B 双方分别拥有各自的与用户相关的数据,存储在本地集群,在整个联合建模的训练过程中,A 和 B 双方的原始数据均不出本地。可以看到,架构具有以下特点:
A、B 两方独立部署 Angel 联邦学习的本地框架,支持 YARN、K8S 多种资源申请方式,与业务现有系统完全兼容,灵活易用;
本地训练框架 Angel-FL Executor 的计算采用 Spark,充分利用其内存优先和分布式并行的优点,效率高且易于和现有大数据生态(如 HDFS 等)打通;
本地模型保存在 Angel-PS 参数服务器中,支持大规模数据量训练;同时,PS 写有 checkpoint,意外失败的任务可以从上次保存的进度继续执行,具有很好的容错性;
模型训练相关的数据经过加密模块加密后,在 A、B 两方之间直接通信而不依赖第三方参与“转发”,实现了“去中心化“,整个训练流程仅需要协调双方的进度即可,能够增强实际应用中的安全性。
在上述系统框架的基础上,再抽象出一层算法协议层,利用平台提供的计算、加密、存储、状态同步等基本操作接口,实现各种联邦机器学习算法。在训练任务执行时,通常拥有标签的一方作为训练的驱动方,算法协议层会控制本地训练步骤,例如梯度计算、残差计算、模型更新、消息发送等,同时与 Angel-FL 流程调度模块交互同步执行状态,并按照协议触发对方进行下一步动作。
一个典型的算法过程如下图 4 所示:
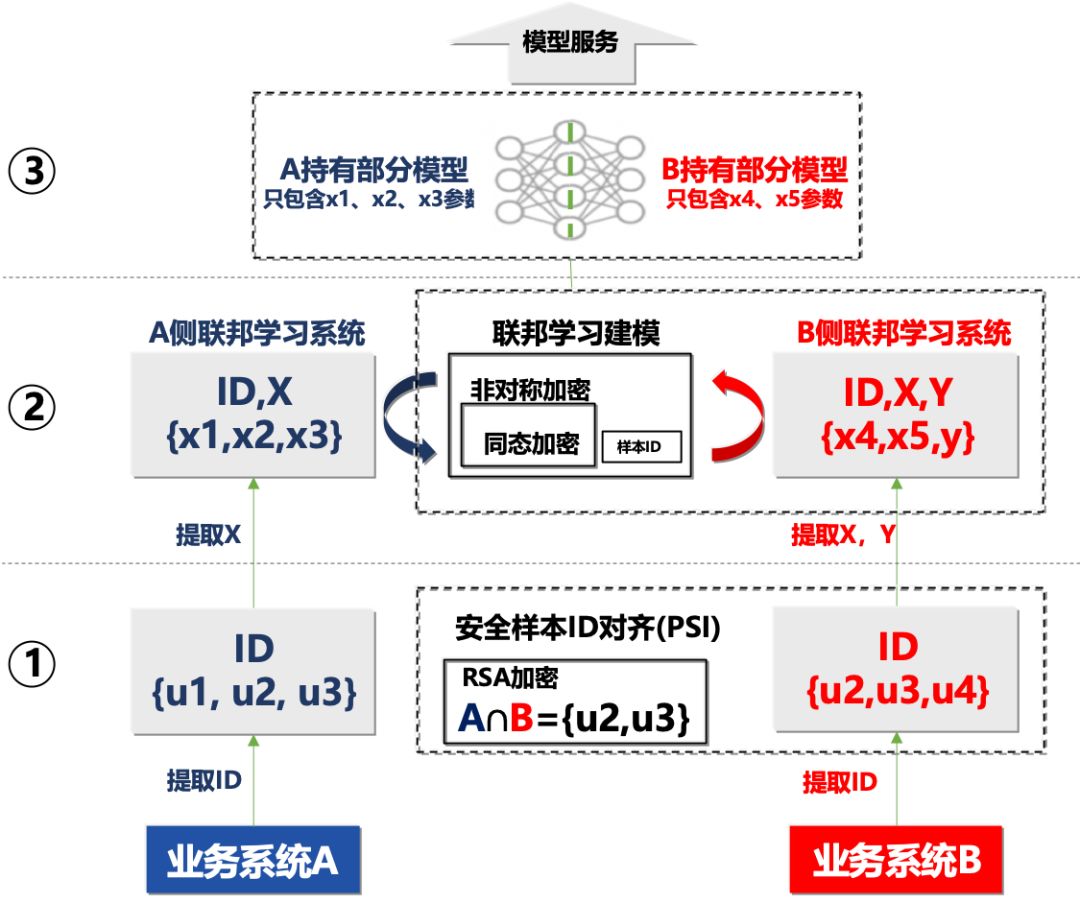
图 4. 联邦学习训练过程
假设还是两个业务系统 A 和 B,其中 ID 表示样本 id 的集合,X 表示维度数据,Y 表示 ID 样本标签,联邦学习的目的是联合 A 和 B 的 X 来训练得到能预测 Y 的最优模型。B 拥有标签,将作为训练的发起方,过程如下:
1)A、B 双方提取样本 ID,通过加密算法加密后,在 B 方进行安全样本 ID 对齐(PSI),得到双方共同的 ID 集合的交集 A^B = {u2, u3}; A,B 均不知对方除了交集外的部分;
2)根据交集 ID,双方提取相应样本的维度数据 X,先在计算本地模型数据如梯度,然后 A 通过加密方式,将中间数据发送给 B,B 根据标签计算预测误差,并将模型更新信息加密后传回 A;
3)模型收敛后训练结束,A、B 分别持有模型中与自己维度 X 相关部分的参数,并共同提供模型服务。
2019 年年底,Angel 智能学习团队已经完成了上图中 Angel 联邦学习框架的 Demo 原型验证,证明了系统可以满足业务场景的需求,并开始产品系统的开发。
技术难点
在技术层面,Angel 联邦学习系统存在几个主要的难点:
“去中心化”。Angel 联邦学习系统主要采用了密码学中的同态加密算法,该加密算法有一个特点是:对经过同态加密后的密文数据进行运算,将运算结果解密,与未加密的原始明文数据进行同样运算的结果是一样的。利用这种特点,研发团队对需要双方交互的模型相关数据采用同态加密,直接发送给对方,对方在密文上完成训练所需的计算,然后将结果返回,接收方解密后,能得到计算后的结果,而无法获知其原始数据。
消息通信膨胀,这个问题也与同态加密有关。采用高强度加密算法,例如如果采用 2048 位 Paillier 加密,一个浮点数的体积将膨胀到 4096 位。研发团队采用 bit-packing 的方法压缩了密文的体积,从而较少网络传输量。
跨网传输消息拥塞。算法在训练过程中通常有大量的数据需要交换,这导致网络传输量巨大,而联邦的双方一般处于不同网络域中,如果采用简单的 RPC 点对点通信,容易引起交换机 in-cast 现象而导致消息拥塞。为了解决这一问题,研发团队采用 MessageQueue 作为消息管道,控制拥塞并提供消息持久化功能,增强系统稳定性。
加密解密加速。联邦学习涉及大量的数字加密和解密操作,属于计算密集型任务,可以采用硬件如 GPU 加速来解决,这方面研发团队正在探索中。
早期应用
目前,整个 Angel 联邦学习框架已初步成型,并逐渐在实际场景中落地。在腾讯内部,Angel 联邦学习已经在金融私有云、广告联合建模等业务中开始尝试落地应用。
以广告场景为例,广告用户画像数据库中有用户的基础属性标签,如性别、年龄等,而其他业务上则有更丰富的行为数据,如何综合这些数据维度给用户更好的广告推荐?针对这个场景,Angel 智能学习团队用多分类问题建模,以候选广告为分类标签,采用联邦 GBDT 算法来训练分类器。在 500 百万训练样本、100 万测试样本、500 维数据特征的数据集上,联邦 GBDT 算法的训练和测试 ACC 准确率均达到 80% 以上,具体提升指标还在业务放量收集中。
另外,Angel 智能学习团队还在腾讯内部筹建了联合项目组,由多个团队参与共建,接下来将对联邦学习框架做进一步的性能优化,并开发更多联邦学习算法,例如 FM、神经网络等。
未来展望
虽然联邦学习技术正在快速演进,但从国内企业的整体落地情况来看,联邦学习在业界还处于早期阶段。在安全标准上,还没有一套完善且业界都认可的安全认定标准出台;加密和解密带来的计算量剧增也需要性能优化;深度学习等复杂算法如何改造成联邦学习模式也是面临的挑战。
目前,不同企业和研究团队在上述这些技术发展的细节上还存在分歧,但 Angel 智能学习团队认为这并不妨碍联邦学习在各个实际场景的应用,分歧反而可能成为促进发展的催化剂,过多纠结于这些分歧,不如去应用场景中寻找答案。
和大多数技术的发展一样,联邦学习技术也会经历概念萌芽,到低谷期,再到逐渐被重视的过程。在 Angel 智能学习团队看来,联邦学习技术有其独特的价值,如果说常规机器学习解决的是一个部门自有数据的模型训练问题,那么联邦学习则是解决不同部门的数据如何训练模型的问题,扩展了机器学习能触达的边界。随着人工智能技术的不断落地,联邦学习在跨部门合作、数据隐私保护等方面将会发挥越来越重要的作用,有着广阔的应用前景。
本文由 InfoQ 粤港澳大湾区内容中心采访报道,我们重点关注大湾区 AI、金融科技、智能硬件、物联网、5G 等前沿技术动态及相关产业、公司报道,寻求报道请联系邮箱:natalie.cai@geekbang.com。
声明:本文来自AI前线,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
