Cortex-M架构被广泛应用于IoT产品,医疗电子产品,工业控制产品和基带系统,但是由于cortex-m固件十分精简提供的额外信息较少,固件逻辑非线性,使得安全分析难度很高。本议题以nRF52为例,较为系统的介绍cortex-m的逆向方法,可能存在的攻击面以及安全防御手段。

演讲嘉宾:李海粟
小米AIoT安全实验室高级研究员,ID:backahasten 研究方向为嵌入式系统安全和通信协议安全。
Cortex-M逆向分析与安全
以下为速记全文:
今天将给大家介绍一下Cortex—M的逆向分析,包括一些安全分析方法和可能会遭受的安全风险,内容涉及逆向的意义、逆向的困难、逆向的技巧,并且还会搭建一个简单的堆栈溢出示例,最后再介绍一下目前的厂商有怎样的防御手段。
Cortex—M是ARM的物联网主力产品,比如我手上的翻页器就使用了Cortex—M,以下我列举了几个用到Cortex-m的产品。

第一张图泛指所有手机,对于手机我们经常关心的是主核心,多少大核,多少小核,性能怎么样,但是除此之外,手机里面还有很多的子系统,比如说WiFi等等,这些子系统很多也使用了Cortex-M,电脑产品中也是同样的情况。
PPT中的第二个图是我们的心电运动衬衫,我用它泛指所有的可穿戴设备,包括现在我手腕上戴的手环,这一类的小东西,由于它对功耗的要求比较高,所以大部分都是Cortex—M的。
第三张图是平衡车,我用它来代指一些控制类型的产品,不仅仅是民用级别的控制,还有工业级别的控制,包括汽车电子产品等。之前的汽车电子更多使用了自定义架构,但是今年我们开始看到越来越多的Cortex—M的产品进入到汽车里。第四张图是比较特殊的,充电宝。现在的充电宝里面都会有一套"类计算机"系统,它有自己的CPU、硬盘和缓存,它的作用主要是给手机充电的时候,协商电压和电流,保证更安全的充电。
大家会发现Cortex-M大多在一些特殊领域和大家不太注意到的地方,但是它有没有安全问题呢?Cortex-M设备还是有很大几率出现安全问题的。原因主要是由于算力比较小,软件上的安全功能不好做,只能依赖硬件,如果开发者的安全意识比较淡,就会催生很多安全问题。
列举几种比较常见的安全问题,第一个就是协议加密或者加密太弱,可以被伪造,这是非常常见的。比如说今年我就通过逆向的方式分析了某款产品的协议,发现了安全问题。
第二个是硬编码密钥获取,部分开发人员有一定的安全意识,但是他的安全意识可能不太够,他会做一些防御,但是这个防御是不够的,如果密钥被人拿到,就可以破解整个系列的固件加密或者通信协议,这也是有风险的。
第三个是堆栈溢出,我后面会着重讲一下。第四个就是知识产权保护与窃取,这是非常有意思的一个点,我们之前所有的攻击好像都是针对用户的,但是随着未来的发展,针对厂商的攻击可能也会出现。
我之前自学过一段时间的深度学习,业内把深度学习训练网络模型的过程戏称为炼丹,一是因为它特别费电,第二是训练集素材特别贵,第三结果不确定性很高,我费了很大的代价去炼出来的丹,被别人这么轻易的从我的芯片里抠出来拿走的,这个肯定是不行的。这些都是一些潜在的或者已经存在的Cortex-M产生的问题。

Cortex-M逆向有哪些困难呢?我们来简单总结一下。
第一它没有加载基址,里面的函数位置反编译器就恢复不出来。另外,Cortex-M有大量的硬件跳转,地址是写死的,如果你没有加载基址,跳转关系就是错的,找不到函数在哪,引用关系也是错乱的。
第二是没有符号表,一个固件我们大概分析一下,它有80%的代码是框架代码,20%或者更多一些是逻辑代码,我们把它叫APP部分。越复杂的系统,框架所占比例越高,在逆向分析的时候,我可能只看APP部分就可以了,如果都没有函数名的话,我不知道哪一个是框架函数,哪一个是应用函数,我需要把所有的都看一遍,时间成本会非常高。
第三个是大量使用全局变量,他会把框架代码和APP打包在一起,有别于我们比较熟悉的安卓的框架代码是分层的,这种全局变量作为两个问题,第一个就是需要装载在内存里,所以我需要找到内存装载的代码,第二是全局变量带来一个非线性的思维,在逆向的时候,整个思维是非线性的,特别跳跃,有时候看着看着就懵了。
最后,有一些垂直领域的专用芯片,它的开发资料、文档、SDK都是不公开的,我们拿不到,对于逆向来说,就是很痛苦的一件事情,没有任何资料的话,逆向工作很难开展。
这次议题后面的例子会以nRF52为例,因为它应用比较广泛,大量的门锁和蓝牙鼠标,还有还有智能医疗的产品都会选择这款芯片,其次它有一个SDK,说明框架代码所占比例非常高,我们可以测试一下我们开发的自动化分析插件能否有效识别它。它还有中间层,API比较丰富,这样如果框架代码识别出来,APP部分的逆向很容易,开发资料也是很丰富的,所以有比较好的研究意义和参考价值。|
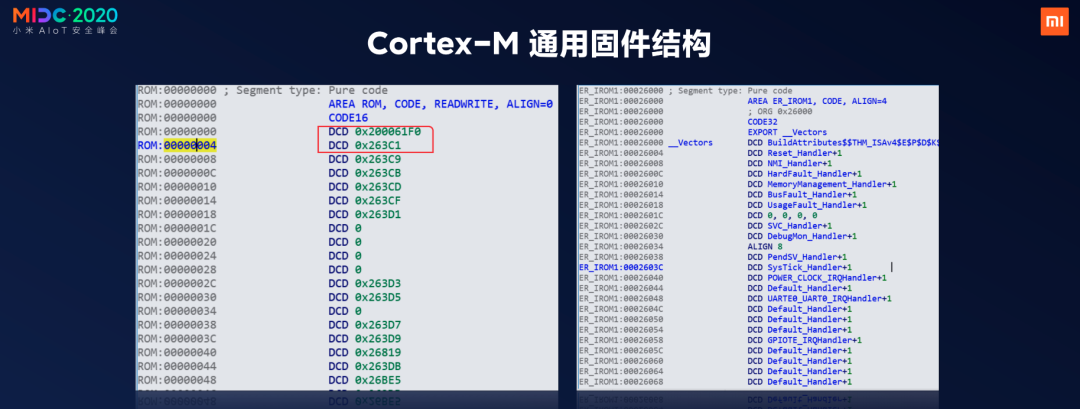
我们来看一下这张图,左边是没有符号表的,右边是有符号表的,左侧这张图就是固件头的结构,如果熟悉Cortex-M架构的话,很容易从这里面发现一些关键的东西。比如红框里这两个地址,上面的那个是SP指针的初始位置,下面这个是加载基址,CPU从这个位置开始运行。然后看一下差异,左边的基址是0x0,右边是0x26000,这个表示右边是有加载基址的,右边是没有加载基址的,这个PC指针如果直接点击是跳不到这个位置的,所以我们第一件要做的事就是恢复加载基址。

这里简单介绍一个小的窍门方法,对于我们的这个固件来说,它有一个特别有意思的结构,0xFE 0xE7,汇编指令的含义就是不停的自己跳自己,芯片在这个时候的表现就是它在那里不动了。为什么有这个东西呢?中断向量表存在的意义当芯片有错误的时候,它会把PC指针指向那个位置,芯片就不动了,这样避免整个PC指针在芯片里面乱飞,如果芯片的PC指针乱飞的话,对于工业控制产品是十分可怕的一件事。
我简单的自己写了一个小插件,可以迅速在固件里面搜索位置,确定了终端向量表的位置之后简单看一看就可以找到Reset handler,结合固件头结构中的地址位置,就可以迅速非常快速的定位出加载基址。这个方法对于某些固件是不适用的,这个和芯片的SDK有关,我们也设计了通过计算方法,利用Cortex-M架构特性计算的插件。

我们为什么要恢复全局变量呢?全局变量是在编译的时候已经定义好了,在芯片上电之后加载到内存去执行,全局变量里面一般会有固件非常非常重要的信息。举个例子,比方说定义完成的回调函数的地址,还有之前说过的神经网络模型,都会在这个位置进行加载,然后以一个全局变量的方式进行调度。
左边这张图就是BW加载的函数。恢复完每段代码之后,我们经过简单的分析就可以看到,这段代码实际含义就是从一个flash开始加载到内存的一个位置,然后下面是一样的,它是分两个步骤来加载的,上面这一段是RW段,而下面那段加载的是零。RW段的恢复会帮助我们后续在交叉引用时快速找到回到函数。

接下来就是函数意义的识别,给大家简单举了几个小方法,我依次介绍一下这些方法的优劣。第一个是日志的字符串,芯片在开发时为了防止哪个地方有错误,会留出调试的信息,这些调试的字符串会帮助我们快速定位到这个函数是干什么用的。但是字符串的缺点就是有些固件是没有字符串的,因为有些公司的安全基线要求就是正式发布版不允许留字符串。第二个就是它的粒度比较粗,你只能定义到这个函数具体在哪一个文件里面,而拿不到文件名。
第二个方法就是bindiff,这是谷歌开源的二进制比较软件,如果你有一个库的话,可以快速进行比对。bindiff也是我经常用的方法,好处是特别准,很不容易错,对一些关键函数识别特别好。bindiff的缺点就是需要维护一个比较大的库,我们针对小米常用的芯片也是建立了一个bindiff常用库,可以对我们的框架代码进行快速识别。
第三个是SVD的内存影射,SVD是一个文件的扩展名,它标注着我这个芯片用来进行硬件设置的内存是在什么位置,如果我在函数里面看见了SVD的地址了,就可以确定函数的大概功能,随着工具的成熟,SVD的内存影射和bindiff的组合可能是一个比较好的方法。
第四个就是中断向量表,方便快速定位关键函数和关键功能。逆向分析是实在没有办法的办法。对于NRF52的专用方法就是SVC的中断识别,找到对应逻辑的SVC中断编号我也可以快速定位逻辑。
另外部分逆向工具也会提供一些识别功能,比如IDA Pro的Lumina虽然只是一个实验性功能,不完善,但是十分令人期待。
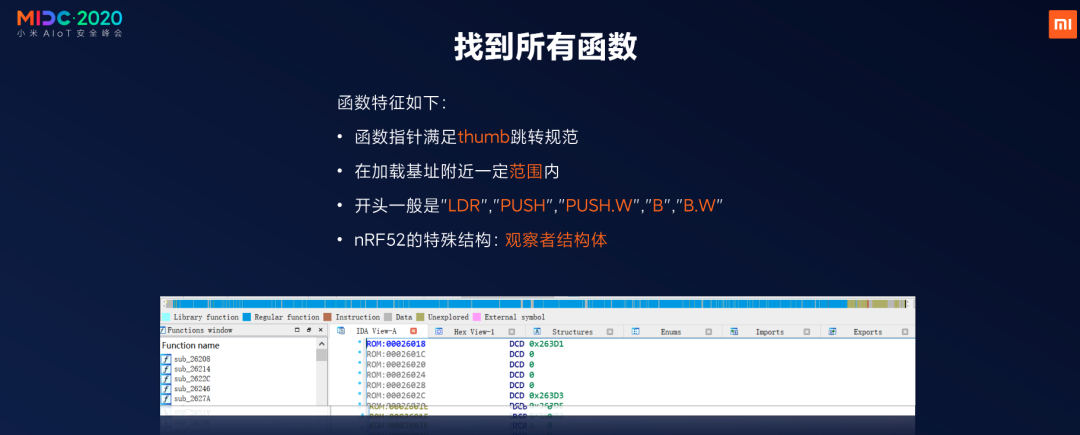
恢复了函数意义之后,首先我们需要找到所有函数,大家可以看一下这张图,如果你把一个bin固件拖入系统就是这样一个状态,上面棕色的条不是代码,它没有识别出来,因为它没有一个正常的文件结构。
我们基于这四条方法,开发出来了一些自动化的工具,可以快速把整个逻辑恢复出来,我们可以看一下效果是什么样的。大概需要三四秒的时间就恢复成这个样子,左边可以看到函数已经恢复出来了,上面蓝色代表代码段,蓝色段很连续表示交叉引用良好,这个效果是非常不错的,我们后续的逆向、后续的安全研究和安全审计都是非常便利的。
简单说一下这四个规则,第一个函数指针满足thumb跳转规范,它在加载基址附近一定的范围内,我们从最开始的截图已经知道加载基址的位置了,所以说它的函数不能跟加载基址跑得太远。第三个就是开头一般是LDR、PUSH等五个指令,可以快速匹配。第四个是就是nRF52的特殊结构是观察者结构体。
说一下SVC中断如何帮助我们识别函数,我们可以先找一下0xA8和0xAA,第一个是对应的UUID加到对应的服务里,第二个是把服务里的特征值和对应的应用UUID绑定在一起,并进行回调函数的注册。通过找这两个SVC中断的调用,我们可以通过判断出回到函数的位置。
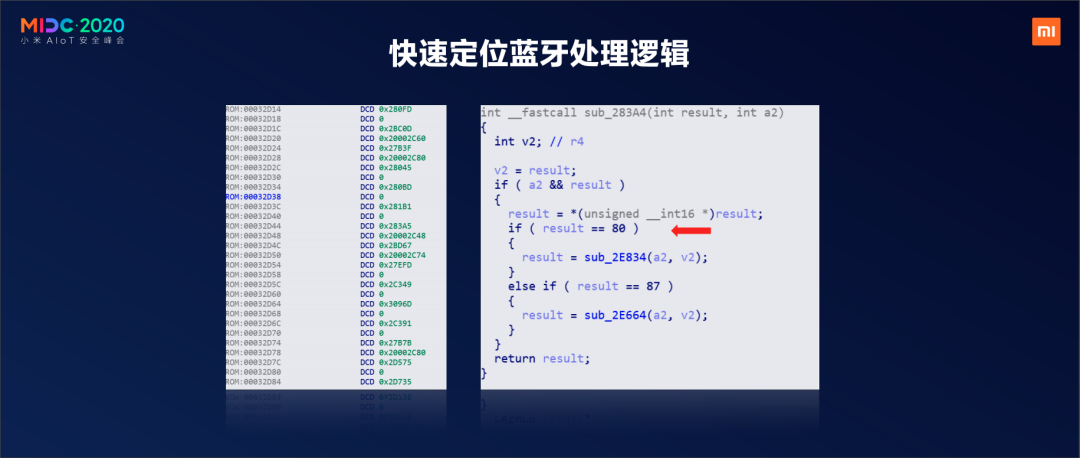
这个就是我刚才所说的观察者结构体,大家可以看一下它的特征是什么。一个指针地址加一个0,或者一个代码的指针地址加一个内存的指针地址,可以看到它特别长,这就涉及到nRF52会把所有的依次调用一遍,如果不是我的,我会返回一个数,让下一个数继续处理。
再看一下右边,result等于80,如果说我们再翻看左边这些函数指针的时候,找到了等于80,那么它选中的这个下面的函数就是对应的就是这个函数。这样就可以帮助我们非常快速的找到一个nRF52芯片的蓝牙处理数据的位置,而一般的通信处理位置是最容易产生安全问题的,也是最值得分析和研究的。
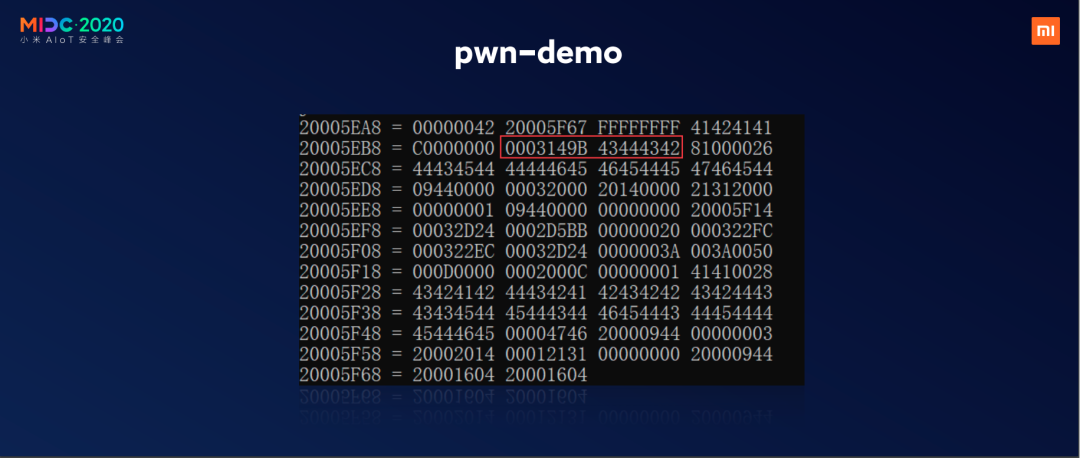
下面简单讲一个堆栈溢出的小demo,自己写了一个bug,就是memcpy,它的长度和输入都是外部可控的,我给它乱发了一个包它就崩了,我打印出了它的一个崩溃的情况。
它停在了这个位置,说明它内部已经检测到了芯片PC指针位置不太对,CPU把整个芯片运行停下来了,根据规定,在芯片崩溃时候,它会把崩溃前的情况原原本本保留到堆栈空间里进行回溯。
我们重点观察一下第六和第七个,通过逆向可以找到这个位置,然后往上一看,好像就是一个memcpy,我们快速定位到这个崩溃的位置,以便于后面进行一些其他的攻击,或者给业务提出来这个位置是有问题的。
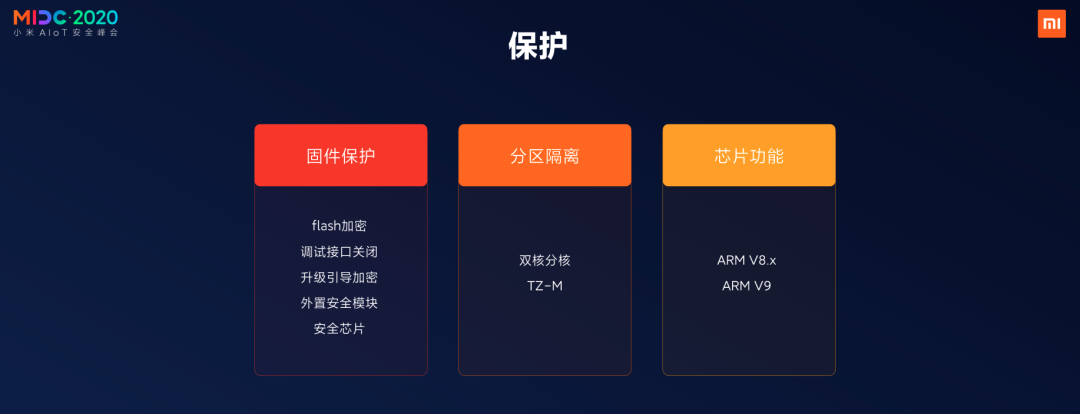
说了这么多攻击和逆向,我们也要讲讲保护,保护大概就这三个思路,第一个是固件保护,第二个是分区隔离,第三个是芯片功能。
固件保护根本的含义是我把我的固件加密了,你拿都拿不到。这也是一种很主流的防御方法。比如flash加密、调试接口关闭,更新流程加密,用外置安全模块对内部的功能进行抽离,这些都是可以的。
这里要重点讲一下flash加密,很多厂商以为用了flash加密以后就彻底安全了,实际上并不是这样的。芯片在进行固件保护的时候有一个悖论,无论你怎么做,你的密钥就在这块芯片里,所以攻击者只要竭尽全力去搞,他始终是有办法搞到的。
最近开始大面积应用的一个技术让我看到了希望,就是PUF,使用芯片在进行流片时的物理特性,生成密钥,实时加密flash,根据我所学的芯片知识,这个东西就没法搞了,因为一旦你对芯片进行剖片或者其他操作,密钥就会不一样,最后解出来的东西跟真实的就不一样了。
第二个是分区隔离,我之前介绍的nRF52是把蓝牙部分协议栈和应用部分进行隔离。因为协议栈一般是很容易出问题的,分区隔离之后,哪怕你已经把协议栈打崩了,或者控制它了,你还需要把应用核再打崩一次,这已经很大程度的提高了安全的门槛。
如果说之前的协议栈分核是把危险的部分单独隔出来,那么Trustzone-M就是把需要安全保护的部分单独隔离开,对于门锁来说就是电机的控制引脚,哪怕PC指针已经被劫持,还是需要经过鉴权之后才能控制电机引脚,这就比单独隔离协议栈更加安全了。
最后一个是芯片功能,我们可以很高兴的看到在ARM的8.x之后陆续提供了硬件上的缓解措施,但是具体可以起到什么样的缓解作用,有什么样新的攻击出现,让我们拭目以待。
隐私保护这条路上任重而道远,只有小米一家还不够,但是我们愿意走在最前面,小米和MIUI永远会做用户的光明守卫,永不懈怠!
声明:本文来自小米安全中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
