
来源:thenextweb
编辑:肖琴
论文:http://niessnerlab.org/papers/2018/7headon/headon_preprint.pdf
来自德国慕尼黑工业大学、斯坦福大学等的一组研究人员最近开发了一个AI,它可以将你的实时的面部表情、眼球运动和姿势转换成肖像,使得图像中的人看起来像是真的在说话和移动。这种技术创造的肖像非常逼真,甚至逼真得令人不安。
这个AI被称为HeadOn,创造它的人正是去年研发了令人瞠目结舌、引发很大争议的“变脸AI”Face2Face的团队。事实上,HeadOn可以说是Face2Face系统的升级版。
HeadOn的视频演示:
研究人员在论文里将这个系统称为“首个人体肖像视频的实时的源到目标(source-to-target)重演方法,实现了躯干运动、头部运动、面部表情和视线注视的迁移”。
根据研究人员的说法,没有其他系统能做到这样。它结合了多种技术——其中大部分是由这个研究团队首创或完善的。
为了解决视线注视的问题,该团队之前开发了FaceVR:
研究团队去年在Face2Face上所做的工作为HeadOn的大部分能力提供了框架,但Face2Face只能实现面部表情的转换,HeadOn增加了身体运动和头部运动的迁移。

在论文中,作者进一步介绍了HeadOn,这是一个用普通RGB-D相机录制的人像视频的重演(reenactment)系统。该系统通过不仅控制面部表情的变化,而且重演了头部、上身的摆动和眼睛注视的方向,克服了当前的面部重演方法的局限性。也就是说,重演了视频中的整个人体。

HeadOn技术的图示
这个方法的核心是将对变形代理的精确跟踪与基于视图的纹理相结合,进行基于视频的重新渲染。
为了实现这一目标,研究人员提出了一种新方法,可以快速、自动地从一个简短的RGB-D初始化序列中构建人的头部和躯干的几何代理(proxy)。这个虚拟形象具有完整头部的参数化3D模型,使用混合形状进行表情控制,并与个性化的上身模型集成。
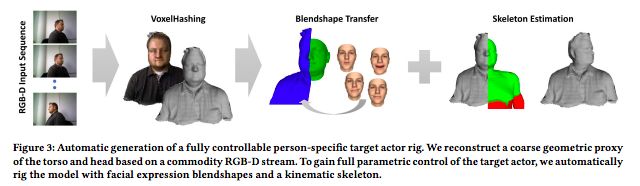
自动合成一个上半身模型
一种新的实时重现算法利用这个代理来真实地映射面部表情和眼睛注视,以及捕获的源参与者对目标参与者的头部动作和身体动作。
为此,研究人员提出一种新的基于视频的渲染方法,合成重新映射的目标人像视频。
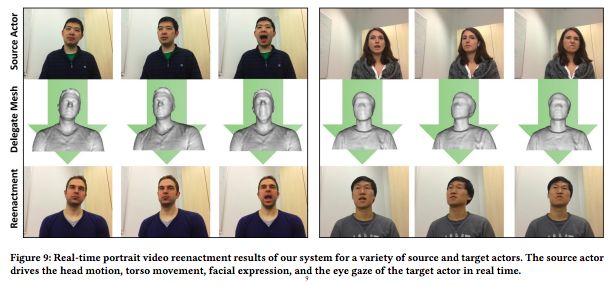
部分结果
总结而言,这个研究的贡献如下:
快速自动构建个性化的几何代理,嵌入参数化的人脸、眼睛、整个头部和上半身模型;
提出一种逼真的、基于视图的、与姿势相关的纹理和合成方法;
对source actor的稳健的跟踪方法;
以及实时source-to-target 重演的完整人像视频。
争议、改进和局限性
视频演示甚至有些令人毛骨悚然,你几乎立即可以想到坏人会利用这种技术做出什么可怕的事情。试想一下,视频通话中的人有可能是假冒的,这太可怕了!
但是,任何技术都有可能用于邪恶目的,只要开发者能以某种方式使输出可以检测,那么至少可以防止AI被滥用。值得一提的是,这个AI的积极应用有很多。正如研究人员所说:
尽管当前的面部重现技术效果令人印象深刻,但它们在操控类型上仍然存在着根本性的限制。例如,这些方法只能修改面部表情,但头部的姿态很僵硬,例如头的方向一直是保持不变的,不会随着输入视频而变。因此,这样的技术能实现的只是细微的变化,例如张开嘴,或皱皱眉。
如果你曾使用Animoji或Bitmoji来聊天,你可能已经注意到这些表情看起来是多么不自然——至少对我们这些看动画片长大的人来说很不自然——说话时不会动脑袋和脖子,面部表情也只有那几种。例如,当一个人皱眉时,通常会伴随着低头和耷拉肩。这些微妙的动作是我们身体语言的一部分,没有身体动作,只有一个会说话的脑袋就显得很奇怪。HeadOn修复了这个不和谐的问题,并通过将几个先进的神经网络结合在一起,产生了更为自然的结果。

局限:对长头发的人处理不怎么好
这个系统当然还不是完美的;在高清分辨率下进行测试,除了最迟钝的观众之外,所有人都觉察到图像被操纵了。而且,根据研究人员的说法,这个AI不怎么会处理长头发的人,产生的输出较为粗糙。但这些小问题未来可以解决。
这个“变脸”项目已经持续多年,未来,HeadOn这样的AI欺骗人类的概率很可能会达到99%。
声明:本文来自新智元,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
