一、密码技术在《个人信息保护法》中的基石地位
《个人信息保护法》是个人信息领域的基本法律。其承继和细化了《民法典》和《网络安全法》中关于个人信息保护的规定,从个人主体的权利、个人信息处理者的义务和监管者职责等多方面塑造了中国个人信息保护规则的全貌。整体上,《个人信息保护法》是一部保护法,其对个人信息处理技术的规范是“内向”性的,而对于包括个人信息在内的数据开发、利用和资源化,则更多的是《数据安全法》的平衡考虑和立法目的。
从上述出发,便不难理解为何密码技术在《个人信息保护法》中具有基石性的重要地位。
密码对于《网络安全法》和《数据安全法》等所界定的网络数据“属性”保密性、完整性和可用性的保障和实现具有重要作用。密码对个人信息和数据的保密性维护自不待言,通过“特定变换的方法对信息等进行加密保护”,是《密码法》定义的基本表述,属于密码“基因”上的功能要求。密码对完整性的维护,是密码对保密性、可用性保障功能的自然推导,SM3、SHA-3等哈希算法和ZUC的完整性算法都是为此而生。至于可用性,一方面指向信息和数据的普遍可获得性,另一方面,什么人访问什么信息,知情同意、因需知晓又有赖于访问控制,可利用密码的身份鉴别、密钥管理等安全认证机制和功能实现。欧盟的GDPR中,也有使用加密技术措施保护个人数据不被未经授权访问的明确规定(第32条、第34条等)。
二、密码技术在《个人信息保护法》中的体现——以第51条为例
1、《个人信息保护法》对加密等去标识化的要求
对个人信息进行安全技术措施保护,是《个人信息保护法》规定的企业个人信息安全保护义务的基本要求,这一要求需要对存储的静态数据,传输中的动态数据,以及随时处于流动的无论其状态的各种数据采取符合法律要求、行业实践和保护惯例的技术措施。其中,被《个人信息保护法》“点名”的加密,则成为了安全技术措施的基线要求。通过部署加密进行数据保护也是企业具有性价比的较优实践选择。同时,密码技术也通过各种组合方式,体现在第51条规定的其他主流“去标识化”安全技术措施之中。
在当前各种隐私计算技术风起云涌的背景下,对这些涉及个人信息的计算模式、方法进行准确的法律定性,应该是开展相关技术措施活动的重要前提,否则,认知偏差会导致对技术的负面法律评价,从而引入新的法律风险。
在之前的公众号文章:“隐私计算工具的《个人信息保护法》评价(二)——密码家族(beta)”中,我们已经探讨并得出结论,将各类隐私计算技术归入去标识化,而非匿名化技术措施。
按照《个人信息保护法》的定义,去标识化是指个人信息经过处理,使其在不借助额外信息的情况下无法识别特定自然人的过程。匿名化,是指个人信息经过处理无法识别特定自然人且不能复原的过程。
由此可以看出,去标识化之后的信息,本质上仍然属于一种“个人信息”,只是这种“个人信息”对自然人的识别,有待于额外信息的引入和触发——换言之,只是增加了识别这些自然人身份和状态的困难。比如加密后的个人信息,呈现的可能是一种“乱码”的状态,但这些密文个人信息在借助额外信息(比如密钥)解密后,就“泥板上的字迹依然清晰可见”。因此,去标识化是一种可逆或近似可逆的过程,即通过去标识化处理后的信息本身无法指向特定个人,但只要结合额外信息并通过计算,就能够指向特定个人。去标识化的技术价值在于通过对额外信息的权限控制使得个人信息可以有条件的流转,其法律价值在于通过现有技术的动态评价,逐渐逼近“匿名化”的法律状态,从而对特定场景、特定技术的个人信息安全状态和保护义务履行程度形成法律评价。
而匿名化后的信息,法律定性为不属于个人信息。因为按照匿名化的定义本意,已经无法识别自然人,且不能复原。当然读者可能会问,是否存在真实可用的匿名化技术?这个问题的法律答案是,法律可以对某种技术在实际个案中是否保护或导致个人信息识别做出判定,因此在具体个案中,存在使用某一技术是否做到了匿名化的法律评价。
因此,匿名化不仅是一种理想化的技术目标,目前所有的隐私计算工具(隐私和个人信息的差别,见《民法典》1032-1034条)都朝着这个方向努力,同时也可以是法律对个人信息保护的裁判标尺。尽管两者并不等价,尽管随着技术的发展,当前认为无法识别自然人的技术,在可预见不久就或许能够与其他技术结合识别出具体的个人。
2、密码技术在去标识化技术中的作用体现
按照公开信息和相关标准总结,目前常见的去标识化技术主要有以下这些种类(受限于认知水平,只选取了部分而非全部的去标识化技术。为本文目的,不讨论这些技术的脆弱性),读者可以看出,密码技术在去标识化,从而也是在个人信息保护技术措施中的基础地位。需要指出的是,去标识化的这些技术并无严格的非此即彼的区分,在工程实现上往往是基于去标识化模型的多种技术组合。而《个人信息保护法》对处理者义务的精细化规定,未来必然也将会对去标识化技术的发展和调整产生深刻影响。
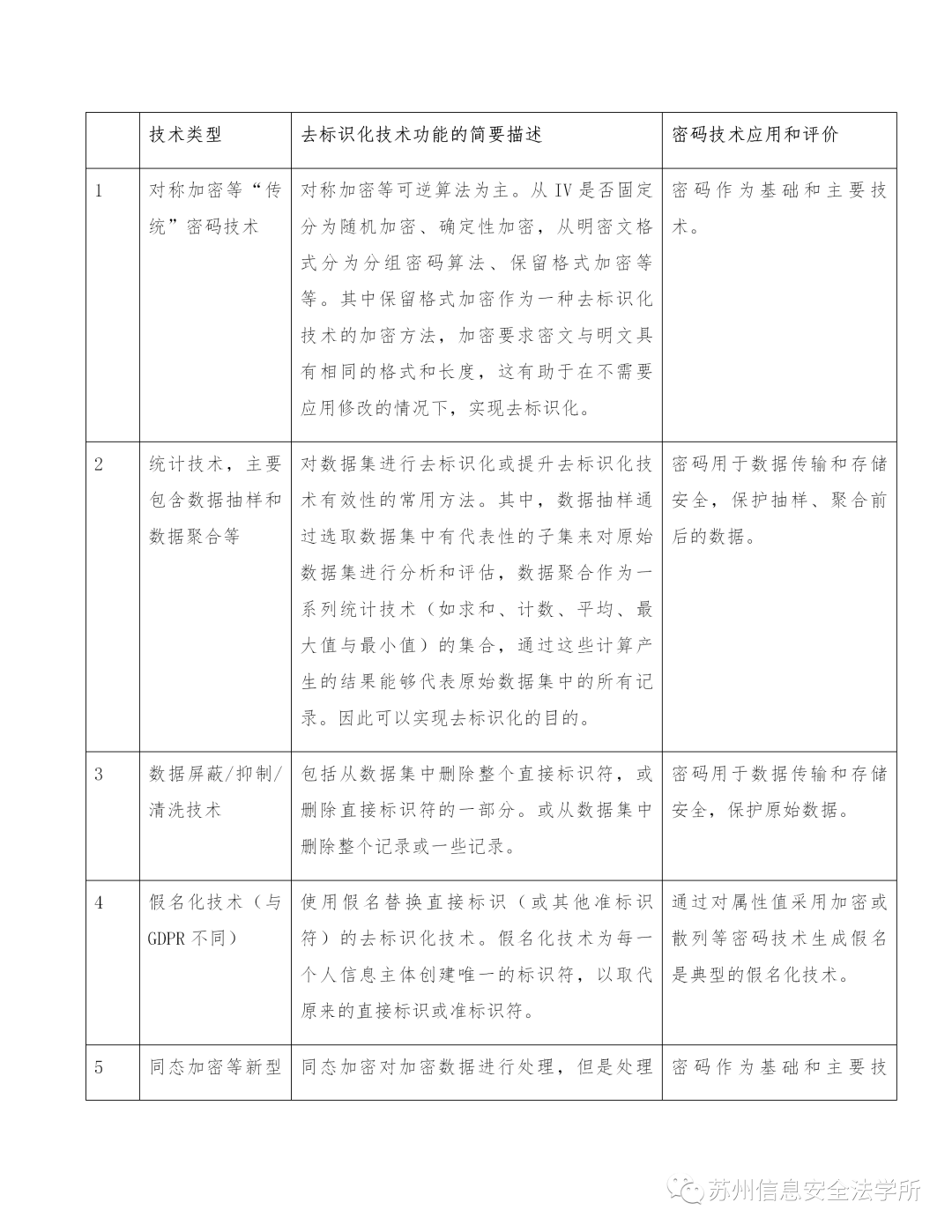
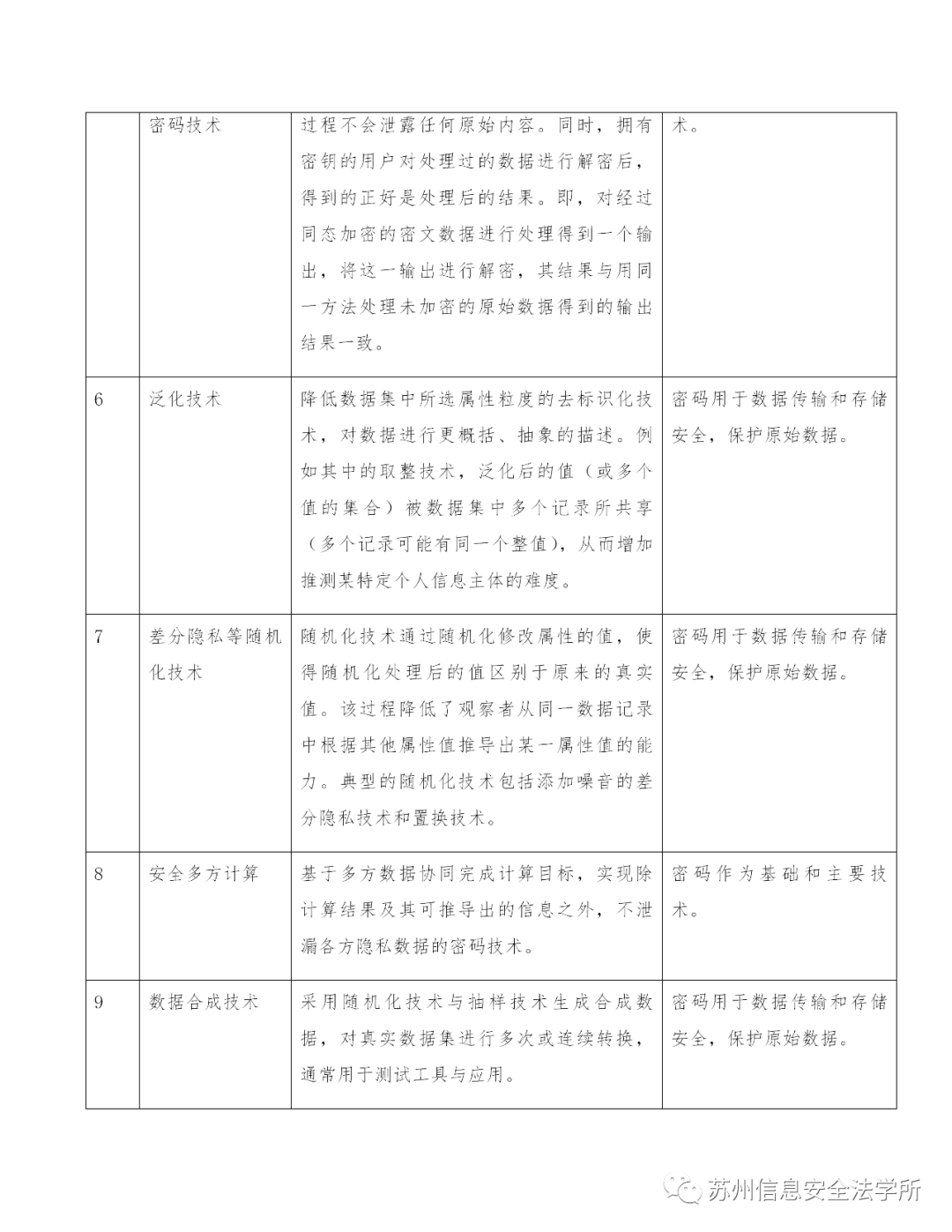
因此,如果说“隐私设计”等概念要求在个人信息处理的启动阶段(甚至之前)就在产品、服务中植入个人信息保护的理念,“基于密码技术的隐私设计”则意味着在进行任何的产品、服务设计之时,也应当将密码技术作为默认的基本配置,保障个人信息有序处理和安全合规二者兼得。
三、结论评价
整体评价上,首先应明确对去标识化技术的使用,是作为《个人信息保护法》第51条的义务合规进行,而不是作为第24条“自动化决策”的目标。否则就会涉及到《个人信息保护法》对自动化决策的规制和启动第55条规定的个人信息保护影响评估——当然技术应用本身的多向性可能无法避免。
其次,这些常用的去标识化技术的使用,至少从理论上降低了个人信息的敏感程度——从而也弱化了企业可能面临的合规风险,可以满足《个人信息保护法》第51条规定的要求,但在具体的实现和个案中,仍然需要接受司法的放大镜审视,因为算法本身的安全性和算法实现的安全性之间存在着不小的差距。
再次,正如去标识化的法律定义,去标识化可能通过借助额外信息实现对个人信息的“重新标识”,因此实务中不同的去标识化技术会通过综合算法模型、需要消耗的资源、可能引入的风险等因素进行评价和使用,以在增加重新识别的难度的同时,确保资源的消耗在可接受的成本范围之内。
最后,《个人信息保护法》的施行,已成为未来企业个人信息合规的重要法律来源。当技术风险对个人信息产生风险和危害时,法律通过义务和责任的方式对技术进行规范和约束,设定了保护个人信息的屏障。但这个屏障的控制实现,却又需要通过技术措施的方法实现。这大概就是技术和法律的“互博”与“共进”吧。
(本文同时作为寰球密码简报第26期内容发布,特别感谢林璟锵老师给出技术指导意见和待决场景问题)
本文作者:
江苏竹辉律师事务所 合伙人律师 原浩
北京炼石网络技术有限公司 创始人/CEO 白小勇
声明:本文来自苏州信息安全法学所,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
