2021年12月,欧盟网络与信息安全局(ENISA)发布了题为《安全机器学习算法》(Securing Machine Learning Algorithms)的报告,这是ENISA在2020年发布《人工智能网络安全威胁图谱》之后又一人工智能安全领域报告。
报告详细分析了当前机器学习算法的分类,针对机器学习系统的攻击和威胁,具体的威胁包括数据投毒、对抗攻击、数据窃取。报告给出了安全框架、标准等方面的具体和可操作性的安全控制。

ENISA发布安全机器学习算法报告
编译:学术plus观察员 张涛
本文主要内容及关键词
1.背景:机器学习AI在工业和政府基础设施应用上极具前景,应用广泛,但需要大量数据进行学习
2.机器学习算法分类:数据类型;算法分类(有监督学习、无监督学习和增强学习);端到端机器学习全生命周期图谱
3.机器学习算法威胁(绕过、Oracle、投毒、模型或数据泄露、针对机器学习应用组件的攻击、机器学习应用的失效或功能错误)及其相应漏洞类型清单
4.安全控制方法:组织/技术/算法三个层面,提出:将机器学习的特性及应用融入到现有安全政策,尤其是网络安全弹性战略中

内容主要整理自外文网站相关资料
仅供学习参考,欢迎交流指正!
文章观点不代表本机构立场
*****
1.背景
机器学习是人工智能在工业和政府基础设施应用研究的发展最好和最有前景的子领域。通过自动和智能地解决决策问题,人工智能广泛应用于经济社会的各个方面。机器学习算法可以从数据中学习,实现无需复杂编程就可以解决问题。但这类算法需要大量的数据来学习。
2.分类
机器学习算法分类

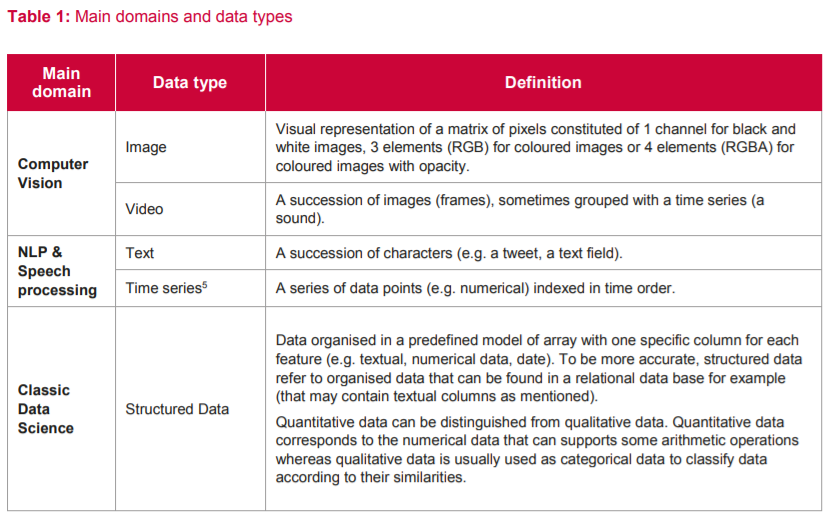
2.1 主要领域和数据类型
不同的算法可以应用于机器学习的不同领域,主要的应用领域有计算机视觉、自然语言处理和经典数据科学。
计算机视觉领域,常用的数据类型有图像和视频,
自然语言处理领域,数据类型有文本和时序数据,
经典数据科学领域,数据类型为结构化数据。
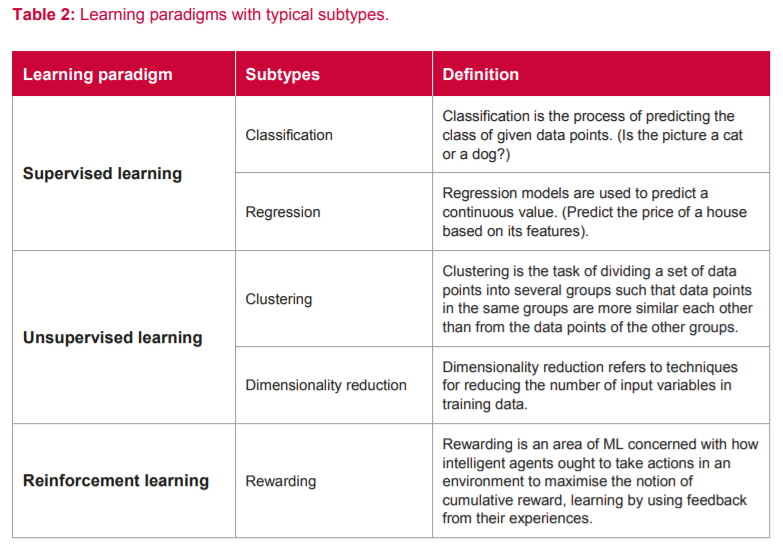
2.2 机器学习算法分类
从学习方式来看,机器学习算法可以分为有监督学习、无监督学习和增强学习。
有监督学习根据样本的输入-输出对数据来映射输入和输出。可以从包含训练样本的有标记的训练数据中进行推断。
无监督学习可以从无标记的数据中去学习模式和特征。可以在没有人工干预的情况下发现隐藏的模式和数据组。
增强学习是使智能代理通过试错和自己的动作和经验的反馈来在交互式环境中学习。
2.3 端到端机器学习全生命周期
人工智能系统的生命周期包括几个相互依赖的阶段,从设计和开发(包括需求分析、数据收集、培训、测试、集成等子阶段)、安装、部署、操作、维护和处置。
人工智能生命周期通用参考模型,如图所示:
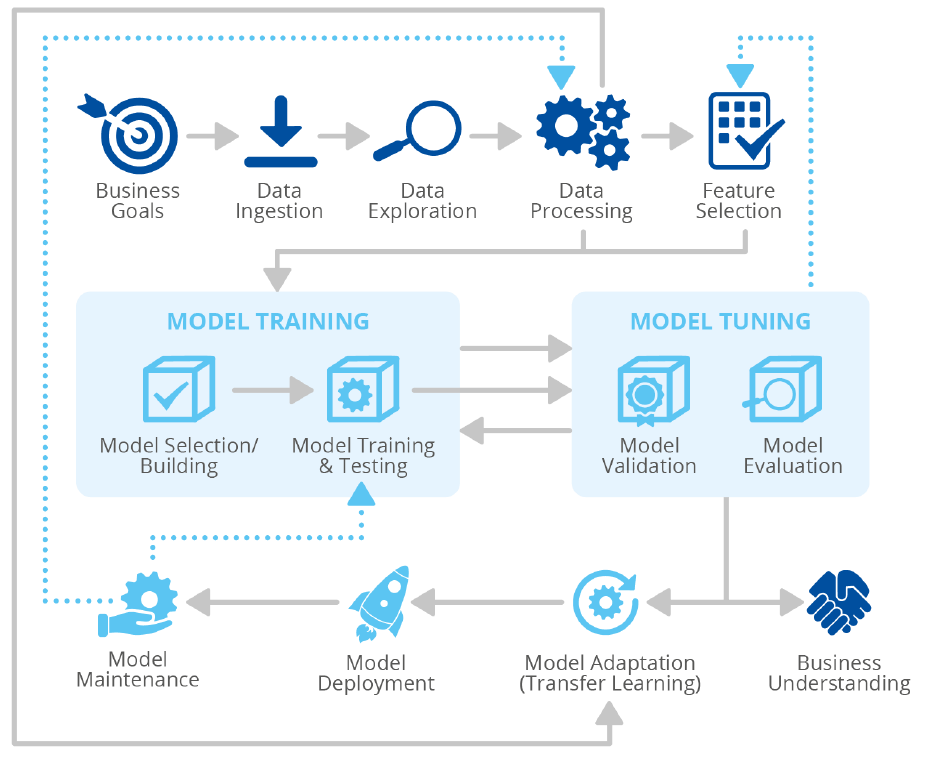
一个典型的机器学习算法全生命周期:
数据收集:从客户端的外部存储或内部存储来提取数据;
数据清洗:识别和纠正可能对算法有影响的错误值;
数据预处理:提高数据质量,具体的方法有降维处理、聚类、特征工程、数据增强等;
模型设计和实现:选择一个预定义的模型或设计新的模型,并定义模型参数;
模型训练:训练一个或多个算法来完成特定的行为,可以采取的方法有正则化处理、分类、聚类、奖励方法;
模型测试:在未知的数据上对模型进行测试;
优化:使用超参数调整等方式来改善模型性能;
模型评估:定义评估模型性能的技术和商业指标;
模型部署:将模型在生产环境的服务器或云平台上数据,并进行用户交互;
监控和推断:对模型的使用和性能进行监控。

3.威胁和漏洞
机器学习算法威胁和漏洞
3.1 机器学习算法威胁
机器学习算法的威胁包括:绕过、Oracle、投毒、模型或数据泄露、针对机器学习应用组件的攻击、机器学习应用的失效或功能错误。
绕过:攻击者利用机器学习算法的输入的小的抖动来引发输出发生比较大的变化,比如决策错误。此类修改的输入就是所谓的对抗样本。
Oracle:攻击者通过利用精心伪造的输入来观察输出以分析模型。这类攻击是绕过或投毒攻击的前一步。比如,攻击者可以研究输入和输出对的关系,并使用这些结果来提取训练数据。
投毒:攻击者可以通过修改的数据或模型来修改机器学习算法的行为。此类攻击也叫做因果推断攻击。
模型或数据泄露:此类威胁是指模型的全部或部分信息泄露的可能性。可以分为数据泄露和模型泄露两类。
针对机器学习应用组件的攻击:此类威胁是指机器学习应用的组件或开发工具被黑。比如,机器学习应用开发者使用的开源库被黑。
机器学习应用的失效或功能错误:此类威胁是指机器学习应用失效,比如由于恶意输入导致的DoS、处理错误导致的不可用。但其中不包括商业用例的失效。
3.2 机器学习算法漏洞
机器学习算法威胁与漏洞的对应关系如下:
绕过对应的安全漏洞有:
缺乏对异常输入的检测;
模型设计实现过程中对绕过攻击的考虑不足;
缺乏对基于对抗攻击的训练;
使用广泛应用的模型,攻击者可以利用模型来研究输入,并生成攻击者控制的输入输出对;
Oracle对应的安全漏洞有:
访问权限管理不合理;
模型允许隐私信息被提取;
输出中包含过多的信息;
模型信息暴露过多;
缺乏对可能攻击的考虑;
缺乏维护机器学习应用组件高安全等级的安全过程;
机器学习模型组件的访问保护机制不足。
投毒对应的安全漏洞有:
模型易被投毒;
缺乏增强对抗投毒鲁棒性的数据;
访问权限管理不足;
数据管理不足;
缺乏对机器学习应用可能暴露的攻击的考虑;
使用不受控的数据;
使用不安全的数据或模型;
缺乏对投毒的控制;
在训练数据集中缺乏对投毒样本的检测;
机器学习模型组件的访问保护机制不足。
模型或数据泄露对应的安全漏洞有:
访问权限控制不足;
存在未定义的泄露场景;
机器学习模型组件访问保护机制不足;
缺乏维护机器学习应用组件高安全等级的安全过程;
测试环境中敏感数据未保护。
针对机器学习应用组件的攻击对应的安全漏洞有:
访问权限管理不足;
暴露过多模型信息;
由于项目中未融合安全导致机器学习应用中存在安全漏洞;
输出中暴露过多模型信息;
存在未定义的攻击场景;
缺乏网络安全意识的不安全实践;
缺乏维护机器学习应用组件高安全等级的安全过程;
由于机器学习应用未遵循安全策略导致的安全漏洞;
存在低安全等级第三方的合约。
机器学习应用的失效或功能错误对应的安全漏洞有:
机器学习模型或数据应用中存在偏见;
存在未定义的失效场景;
决策缺乏可解释性或可追溯性;
缺乏维护机器学习应用组件高安全等级的安全过程;
由于机器学习应用未遵循安全策略导致的安全漏洞;
存在低安全等级第三方的合约。
4.安全措施
4.1 组织层面
应用基于角色的访问控制模型,使用最小权限模型;
在人工智能项目中应用文档设计;
评估机器学习应用需要合规的法律、法规等;
确保机器学习应用的数据安全合规要求;
确保机器学习应用在身份管理、认证和访问控制策略方面的合规;
确保机器学习应用融入到安全操作过程中;
确保机器学习应用遵从安全策略;
将机器学习应用包含在安全应急响应过程的检测和响应中;
将资产管理过程包含在机器学习应用中;
将机器学习应用融合在整个网络安全弹性战略中;
将机器学习特性融入到现有的安全策略中。
4.2 技术层面
评估使用的模型的暴露等级;
检查使用的组件的安全性,确保不同的组件有适当的安全等级;
对机器学习应用进行风险分析;
控制机器学习模型使用的所有数据;
部署测试环境时确保有适当的保护;
确保机器学习应用遵循第三方的安全需求;
确保机器学习项目在将安全融合在项目中时遵循全局过程。
4.3 特定机器学习算法
在训练数据集中增加对抗样本;
在输入中应用修改;
构造可解释的模型;
选择和定义更加弹性的模型设计;
扩大训练数据集;
确保模型是没有偏见的;
确保模型遵循一定程度的差分隐私;
确保模型对应用的环境有充分的弹性;
实现过程来维护机器学习组件的安全等级;
实现工具来检测数据点是否是对抗样本;
将机器学习特性融合到感知战略中,确保所有的机器学习利益相关者能被接收到;
在模型评估过程之后加入投毒控制;
减少关于模型的信息暴露;
减少模型的给定信息;
使用联邦学习来最小化数据泄露的风险;
使用不易迁移的模型。
下载报告:https://www.enisa.europa.eu/publications/securing-machine-learning-algorithms/@@download/fullReport
声明:本文来自学术plus,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
