重要位置发现是轨迹数据挖掘的重要内容,可以基于多种轨迹数据进行分析,如:
使用社交媒体中用户的签到数据,来挖掘用户的重要位置。签到数据的位置精度高,但是覆盖用户规模较小、人群窄,而且还存在数据稀疏性问题,即签到位置仅集中于少数几个地点。
使用市民刷卡记录数据来分析居住地和工作地,其覆盖人群仍不够广泛,所获得的结果精度不够高。
而鉴于手机已得到极大的普及,目前许多工作集中于使用手机大数据来分析用户的重要位置。
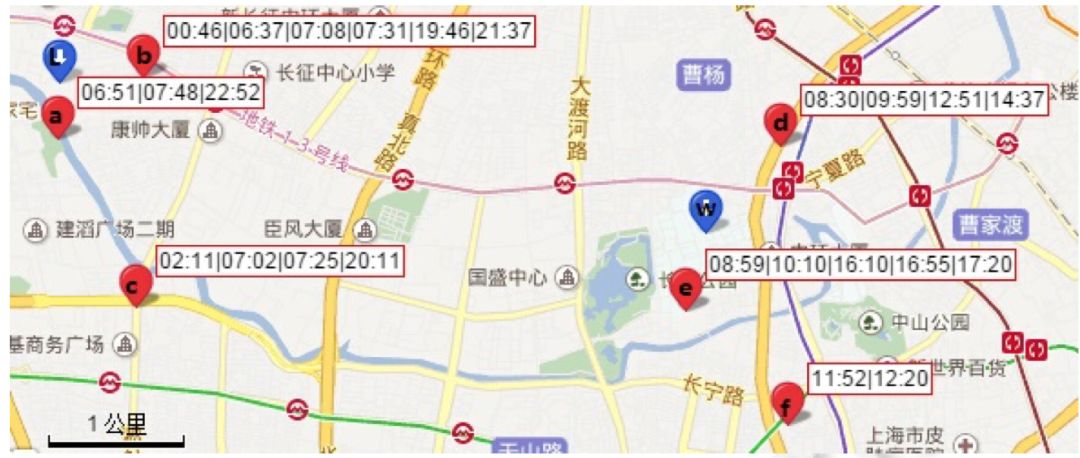
图 1 某用户一天的基站连接日志
基于移动轨迹数据进行重要位置挖掘的方法主要分为两类:
1、基于网格统计的方法,是较早提出的方法:先将研究区域栅格化,再将基站位置与栅格相对应,接着统计用户在每个栅格的出现次数,并将次数最多的栅格看作是包含重要位置的栅格。使用栅格的中心点,或在该栅格出现位置的平均值作为用户的重要位置所在地。
2、基于聚类分析的方法,是目前较常用方法。直接对用户连接过的基站位置点进行聚类,并将聚类中心作为用户重要位置。
先聚类再过滤的改进方案:考虑用户在各簇中的停留时间和次数,从而筛选出潜在合理的簇。
如图1所示, 由于c基站的覆盖范围较广,聚类算法在不同的参数下会将a, b, c这3点聚为一簇,或者将a, b聚为一簇, c点单独成为一簇。当a, b, c聚成一簇时,现有方法会使得结果偏向c点,影响结果的精度,当c点单独聚成一簇时,又会使用户多出一个“居住地”, 降低了结果的准确度。
同时,对于第2个簇中f基站虽然满足聚类阈值,但由于在其有效停留时间段为11:52到12:20,相对于用户在其他基站的停留时间则较短。显然,该基站的重要性对于分析工作地来说没有d, e两个高。
基于网格统计的方法简单、易行,但所求结果准确度和精度不高。基于聚类的分析方法虽然考虑了用户在各个簇中的停留持续时间和次数,但未考虑簇中各基站的连接时间和持续时间,所以结果的精度仍有待提高。
进一步地,以上方法未考虑用户的多样性等问题,所求得的结果还存在较大偏差。为此,针对低质手机轨迹数据,需要一个处理框架和挖掘算法,来有效地找出用户的多个重要位置、解释用户的重要位置的变化情况。
这个处理框架的主要思路是:首先,针对轨迹记录中大量与重要位置无关的噪声数据,通过状态生成和状态过滤两个步骤消除噪声数据以及基站跳变对分析造成的影响,提高数据的可用性,接着对剩下的位置通过聚类分析,找出用户的重要位置。
详细内容,请听下回分解。
声明:本文来自LBS,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
