距离计算机先驱们在达特茅斯创立 AI 学科已过去 60 多年,目前属于它的时代正逐步到来,资本市场上更是竞相推崇,一代代 AI 人的坚守终于迎来了春暖花开。但回望 AI 早前的这段曲折历史,相信每个人都不免慨叹,好在现今计算性能的大幅提升以及海量数据都为 AI 的发展提供了绝佳契机,虽然接下去要走的路还很漫长。而作为支撑 AI 的机器学习所扮演的重要角色自然不言而喻,针对其中各种训练模型、算法的攻击已是屡见不鲜了,随之而来的安全问题也日益凸显。这让很多人开始思考 AI 的安全性,本次议题是由吴鹤意为我们带来的有关此方面的探讨,并以 NLP 在实际业务中的应用为例进行了详细阐述,相信大家在看完文章后都会有所收获。
—— 看雪『Pwn』版主 BDomne

吴鹤意,网络安全爱好者,拥有大型政企单位安全应急与运维经验,多次参与中央部委安全事件解析工作,研究领域现集中于AI+SDN。
以下内容为吴鹤意在看雪2018安全开发者峰会上的演讲实录:
大家上午好!非常感谢看雪给我这个机会,和大家交流有关AI安全方面的问题。
我今天这个议题主要来自于一个聊天机器人在工程实践中遇到的一些问题。
我自己是一个安全研究爱好者,平时更多聚焦在AI、在工程方面的落地内容。
现在机器学习的安全问题在国内安全会议上已经讨论得不少了,其中主要集中在三类:一类是对抗性输入,专门设计的输入,往往是主要用来让AI的分类器进行误分类以躲避检测,比如恶意软件的检测和恶意流量的检测。第二类是数据中毒攻击,攻击者主要是用来污染训练数据,因为很多机器学习模型需要在训练数据的基础上进行训练,一旦污染了数据之后,训练出来的模型也会产生很大的影响。第三类是模型窃取技术,通过探测把一些看不到具体代码的模型,可以把模型分类曲线、分类决策面复现出来。

现在机器学习已经有很多落地的攻击方法,比如:
第一,图片类机器学习的攻击。这是我自己分类的,第一类是代码级的攻击,它主要用的是代码方面的漏洞,第二类是算法级的攻击,它更多是基于图像扰动方面的原理:
第一类是代码攻击,我参考的是这个文章,这类攻击主要利用的是代码方面,比如依赖的包上面代码问题,比如内存访问越界、除零异常、空指针引用、整数溢出等等。可以达到什么效果?可以运行机器学习的进程挂掉,导致应用无法去应用了。像这类攻击主要基于的是开源代码,对代码进行漏洞分析,它比较底层,所以适用性很好。要去修复它的话,主要依赖于打补丁。影响的是可用性,它会让这个模型的进程直接挂掉,让运行机器学习的进程直接挂掉。
第二类是算法攻击。这是我引用的一篇文章,它的原理是对图片样本加上轻微的扰动,可能是一个很小的扰动,人眼是看不出来的,但机器学习算法的原理是基于对每一个像素的检测,每一个像素产生微小的变化,人看不出来,但机器学习模型会产生很大的变化。如果大家参加过这两年安全会议,只要有类似的会议都会放上面这张图,因为这张图是对机器学习攻击论文上最经典的图。一张熊猫的照片加上微小的扰动,就可以让它识别长臂猿。它攻击的是算法原理,对模型原理和算法进行研究。但这种方式对机器学习、图像分类或识别算法是各不相同的,因为攻击方式必须根据模型进行改变。修复一直属于螺旋式上升过程当中,这篇文章是今年3月份总结了类似的攻击方式,比较知名的有12种,防御方式达到了15种,这类攻击是通过首先影响机器学习分类模型的准确性,造成模型分类准确性迅速降低,最后导致它不可用,影响的是它的可用性问题。
第二,针对音频类的。也大体分为两类:
一类是频率攻击,比较知名的是海豚音那个攻击,利用手机上麦克风和人耳对于声音接受频率不同,除了海豚音攻击以外,手机上也存在类似的攻击,例如智能助手会利用语音进行操作,但手机麦克风对于声音识别的范围频率和人耳不一样,比如人耳听不见,但手机麦克风却能识别为声音,然后进行操作。跟刚才的图片类似,人眼看不出,人耳听不出,但机器却可以识别出来。这类攻击是基于声音,它的适用性也非常好,因为它攻击的是麦克风硬件的模组,以及它上面很底层的比如用软件或者硬件实现的滤波器,所以它的修复需要从底层硬件方面,或者很底层的滤波器的软件代码进行修复。它的影响也是影响可用性,会造成让手机进行误操作、个人助理进行误操作。
从算法方面,这里引用了一篇文章,在你音频样本之上进行一个叠加,让你关于音频方面的机器学习模型造成误判或者准确率降低,这个原理是一样的。像这一类的特性和刚才图片的扰动一样,依赖于具体音频AI识别的算法,根据不同的算法,很多攻击方式并不能做到很好的共用性。像它的修复方式,只能对你的算法来进行升级,除了升级以外,还有一些其他的,比如数据增强的方式来进行,在这个文章里也有提到。它最后通过影响你模型的准确性,来影响应用的可用性。
我之前有一个工程应用上遇到的问题,今天借此机会与大家交流一下。NLP的应用有很多,这是我从百度AI平台上截下来的图,就是NLP现在的应用有非常多场合,其中一个场合是问答机器人。大家对于问答机器人的分类不一定那么清楚,它大体分为两类,一类是问答机器人,一类是聊天机器人,聊天机器人是你可以跟它一直聊天聊下去,但问答机器人的目标是在3-4个与你的交互环节之内给你一个你满意的答案。问答机器人在国内的落地方案中采用的方式大概可以分成几类:

一开始是对于用户的输入做字符分割,然后把分割出来的字符提取关键词,把提取出来的关键词转变成一个向量,然后和问答库当中原来已经存的答案进行匹配,比如4000个问题和4000个答案的关键词进行相似度匹配,把匹配出来的前3个或者前5个问题返给用户,然后让用户自己来选择哪个问题是你想问的问题,点击进去可以看到这个问题的答案。topK的匹配度很低,比如当低于30%的时候,有些厂商提供的方案是采用知识图谱的方式,或者把这个问题直接输到搜索引擎里去,把搜索引擎top3的答案返还给你,或者它觉得你的问题问得不太清楚时,它会引导你更加精确的描述你的问题。可能具体实现的细节有所不同,但大概的方案就是这两几类。
在我们实际测试过程中,发现很多问答机器人是存在词槽设置不完善、敏感词没有过滤、搜索引擎答案直接相互返回以及匹配度阈值的设定。我主要跟大家讨论敏感词的过滤问题,大家能够在网上看到真实案例的新闻,比如亚马逊的音箱去年年底说出一些不恰当的话,最后被迫下线一个月。可能这些问题不是那么传统意义上的安全问题,但它可以直接导致我们的AI系统达到被下线的程度。
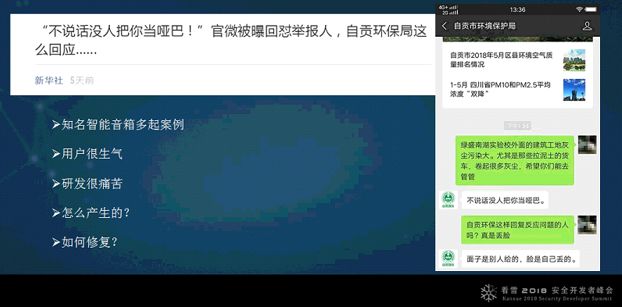
最近某地政府官方微信引用了智能机器人,因为有一些不恰当的回复,把新华社点名了。大家看看这个截图,很明显这个机器人是一个聊天机器人,并不是问答机器人,把用户的输入变成闲聊对话,匹配度又不是很高,导致它产生了这样的回答。发生这样的问题,国内很多公司都在做智能音箱,这个问题和智能音箱背后的问题是一样的,因为智能音箱从原理技术上也是这样实现的。遇到这样的问题,用户是非常生气的,研发却很痛苦。从技术角度来说,现在并没有很好的解决方案来解决这样的问题,比如这个应用直接就下线了,导致比较严重的后果。
这是我实际测试的案例,这是一个云端的智能客服,它对用户的输入和自己的输出根本没有做任何过滤,用户有很多输入,这种话完全不应该输出,但它直接输出了。
这是一个政务方面的应用,也嵌入了聊天机器人,但是对于用户的输入也没有做完全的过滤,通过聊天的方式把不太恰当的话直接输出了。这种问题是普遍性存在的。
这个例子是跟刚才同样的应用,我提出问题之后,厂商说“该公众号提供的服务出现故障,请稍后再试。”直接把这个应用关掉了,大家觉得这种修复方式很粗暴,其实这种问题修复起来是很难的。前不久大家在安全方面看到了,在一个操作系统,它通过语音直接激活智能助手,然后进行代码的执行,那个厂商提出的安全就是直接把这个功能禁掉了,它也没有做什么修复。
这都是国内大厂智能客服的问题,像这个大厂已经做了过滤,对用户输入的中文已经做了过滤,但我可以用英文、韩文、日文。
有些案例对敏感词没有过滤好,有的是阈值设置有问题,有的是答非所问,直接影响客户的满意度以及这个产品会不会在线上应用。导致这些问题的原因是机器学习的模型具有不可解释性,它在可解释性上很差,比如刚才我举的被新华社点名的那个例子,为什么模型会做出那个回复?即使是研发工程师,他也是很难解释的,因为AI模型特别是深度学习模型有几百层,很难解释怎么产生了这个回复。用户很生气,研发又不知道该怎么进行修复。
我们也尝试考虑做规则过滤、敏感词过滤等等,但绕过的方式太多,因为汉语博大精深。我们也考虑过Fuzz,第一,它效率低,第二,又是文字游戏,效果不理想。刚才我举的例子和大厂AI安全实验室的工程师进行了探讨,他们没有好的解决方案,我自己也没有好的解决方案,大家有好的解决方案可以告诉我。
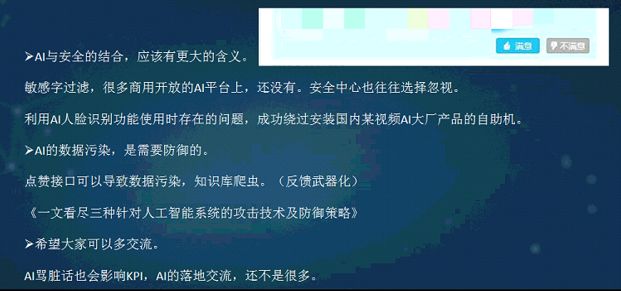
我原来是做AI的,现在安全会议上也有关于AI的问题,安全和AI的结合有更大的含义。比如敏感词过滤的功能在国内很多平台根本没有,如果把这个问题提交给安全中心,它不认为这是传统意义上的安全问题。这个觉得这跟安全不是很紧密,但是类似的原理如果利用在人脸识别,可以绕过很多厂商人脸识别。攻击不一定从代码层面,也可以从AI的应用层面,应用逻辑和程序中的问题都可以拿来作为攻击点。
AI的数据污染也需要防御,在第一个案例的截图,它会把top3的问题返还给用户,用户觉得好可以点赞,觉得不好可以不点赞。但也可以恶意给你不停的点赞,让你这个模型慢慢畸变,变到最后让模型觉得应该推送错误的答案。像问题在国内有一些专家已经意识到了,这里也引用了一个网上的文章,它里面提到了类似的问题,像这个问题不一定针对的是代码层面,也不一定针对的是算法层面,但AI可以说脏话和不恰当的话,它最后会直接影响到AI的落地问题。但国内在AI应用过程中的这个安全点讨论得并不是很多,希望大家以后有计划可以加强沟通和交流。
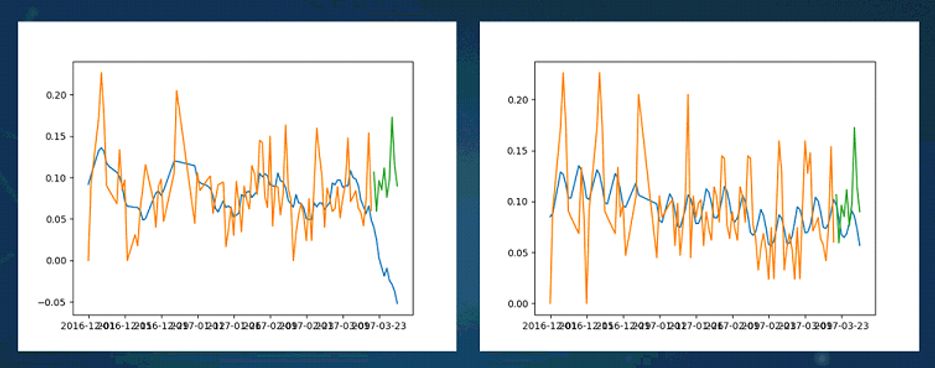
像数据污染问题,这是我们自己做的一个实验,左边这张图是被污染过的图,右边这张图是没有被污染过的图,橘黄色的曲线是训练过的曲线,蓝色曲线是预测曲线,预测数据应该是应该跟真实数据进行对比的。同样一个模型,对一些数据点进行污染之后,可以让它的预测产生不一样的效果,右边这个模型大概能够预测出后面的峰值,左边的模型已经和真实的点千差万别。
对于AI模型在应用中的有些安全点,苹果自己也写过文章,比如苹果因为Siri总是发出“笨拙”、“尴尬”的词,直接放弃了音箱产品。Uber在3月发生了安全问题,AI的安全有时不一定是算法、代码,可能是在应用方面。
着眼于国内的政企应用,聊天机器人的不恰当回复,会给单位带来很大的压力和困扰,也会影响AI在这个领域的发展。但可喜的是,经过我跟厂商的交流和沟通,发现有些厂商已经开始着手解决这个问题,但这个问题的确不是那么容易来解决。
很多国内外大牛们也在往这方面进行思考,摆脱传统代码级别、算法级别的问题,来研究AI在其他领域的安全问题,比如Google工程师提到了,还有阿里的大牛提到了数据中毒,腾讯大牛也提到了AI非传统安全方面的问题。
声明:本文来自看雪学院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
