议题概要
现代操作系统基本都已经在硬件级别(MMU)支持了用户态只读内存,只读内存映射在保证了跨进程间通信、用户态与内核间通信高效性的同时,也保证了其安全性。直到DirtyCOW漏洞的出现,这种信任边界被彻底打破。
在iOS中,这样的可信边界似乎是安全的,然而随着苹果设备的快速更新和发展,引入了越来越多的酷炫功能。许多酷炫功能依赖iOS与一些独立芯片的共同协作。其中,DMA(直接内存访问)技术让iOS与这些独立芯片之间的数据通信变得更加高效。
然而,很少有人意识到,这些新功能的引入,悄然使得建立已久的可信边界被打破。科恩实验室经过长时间的研究,发现了一些间接暴露给用户应用的DMA接口。虽然DMA的通信机制设计的比较完美,但是在软件实现层出现了问题。将一系列的问题串联起来后,将会形成了一个危害巨大的攻击链,甚至可导致iOS手机被远程越狱。部分技术曾在去年的MOSEC大会上进行演示,但核心细节与技术从未被公开。该议题将首次对这些技术细节、漏洞及利用过程进行分享,揭示如何串联多个模块中暴露的“不相关”问题,最终获取iOS内核最高权限的新型攻击模式。

作者简介
陈良,腾讯安全科恩实验室安全研究专家,专注于浏览器高级利用技术、Apple系操作系统(macOS/iOS)的漏洞挖掘与利用技术研究。他曾多次带领团队获得Pwn2Own 、Mobile Pwn2Own的冠军,并多次实现针对iOS系统的越狱。

议题解析
现代操作系统都会实现内存保护机制,让攻击变得更困难。iOS在不同级别实现了这样的内存保护,例如,MMU的TBE属性实现NX、PXN、AP等,以及更底层的KPP、AMCC等:

其中,用户态只读内存机制,在iOS上有很多应用,比如可执行页只读、进程间只读以及内核到用户态内存的只读:

如果一旦这些只读内存的保护被破坏,那么最初的可信边界就会被彻底破坏,在多进程通信的模式下,这可以导致沙盒绕过。而对于内核和用户态内存共享模式下,这可能可以导致内核代码执行:

然而突破这样的限制并不容易,在iOS中,内核代码会阻止这样的情况发生:每个内存页都有一个max_prot属性,如果这个属性设置为不能大于只读,那么所有设置成writable的重映射请求都会被阻止:

随着手机新技术的发展,DMA技术也被应用于手机上,DMA是一种让内存可以不通过CPU进行处理的技术,也就是说,所有CPU级别的内存保护,对于DMA全部无效。
那么,是不是说,DMA没有内存保护呢?事实并非如此,这是因为两个原因:第一,对于64位手机设备,许多手机的周边设备(例如WIFI设备)还是32位的,这使得有必要进行64位和32位地址间转换;第二是因为DMA技术本身需要必要的内存保护。

正因为如此,IOMMU的概念被提出了。在iOS设备中,DART模块用来实现这样的地址转换。
事实上DMA有两种:Host-to-device DMA以及device-to-host DMA,前者用于将系统内存映射到设备,而后者用户将设备内存映射于系统虚拟内存。在2017年中,Google Project Zero的研究员Gal Beniamini先将WIFI芯片攻破,然后通过修改Host-to-device DMA的一块内存,由于内核充分信任这块内存,忽略了一些必要的边界检查,导致成功通过WIFI来攻破整个iOS系统:

然而Gal的攻击方式存在一定局限,因为必须在短距离模式下才能完成:攻击WIFI芯片需要攻击者和受害者在同一个WIFI环境中。
我们有没有办法通过DMA的问题实现远距离攻破,这听上去并不可行,因为DMA接口本身并不会暴露于iOS用户态。
然而通过科恩实验室的研究发现,可能存在一些间接接口,可以用来做DMA相关的操作,例如iOS中的JPEG引擎以及IOSurface transform等模块。我们选择研究IOSurface transform模块的工作机制。以下是IOSurface transform模块的工作机制:

IOSurfaceAccelerator接口通过用户态提供的两个IOSurface地址作为用户参数,通过操作Scaler设备,将IOSurface对应的地址转换成Scaler设备可见的设备地址,然后启动scaler设备进行transform,整个过程如下:

另一方面,在这个Host-to-device DMA过程中,用户态内存的只读属性是否被考虑在内,是一个比较疑惑的问题。我们经过研究,发现在IOMMU中是支持内存属性的:

在TTE的第8和第9位,是用于执行内存页的读写属性的:

因此我们得到这样的页表属性定义:

我们之后介绍了苹果图形组件的工作模式:

在iPhone7设备中,一共有128个Channel,这些Channel被分成三类:CL、GL和TA,内核将来自用户态的绘图指令包装并塞入这128个channel,然后等待GPU的处理。由于GPU处理是高并发的,因此需要很健全的通知机制:
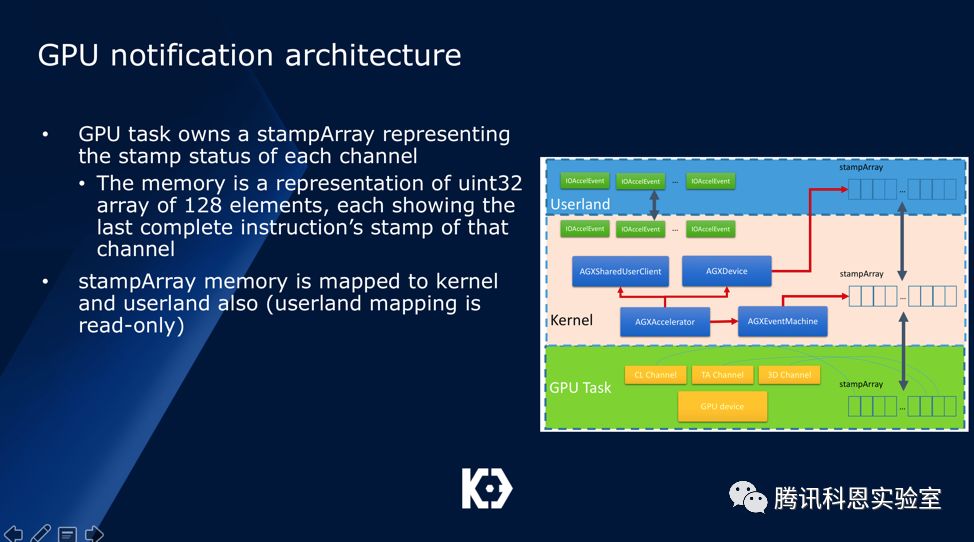
首先GPU会映射一个128个元素的stampArray给kernel,kernel也会把这块内存映射到用户态。与此同时,内核也维护了一个stamp address array,用于保存每个channel的stamp地址:

值得注意的是,GPU每处理完一个绘图指令后,都会将对应channel的stamp值加1。另一方面,对于每个绘图指令,都会有一个期望stamp值,这个值被封装于IOAccelEvent对象中:

系统通过简单的比较expectStamp于当前channel的stamp值就可以确定这个绘图指令是否已经完成。为了提高处理效率,部分IOAccelEvent对象会被映射到用户态,属性只读。
在介绍完了所有这些机制性的问题后,我们来介绍两个用于Jailbreak的关键漏洞。漏洞1存在于DMA映射模块,先前提到,系统的内存属性mapOption会被传入底层DART的代码中,然而在iOS 10以及早期的iOS 11版本中,这个mapOption参数被下层的DART转换所忽略:

所有操作系统中的虚拟地址,都会被映射成IOSpace中允许读写的内存:

之后我们介绍第二个漏洞,这个漏洞存在于苹果图形模块中。在IOAccelResource对象创建过程中,一个IOAccelClientShareRO对象会被映射到用户态作为只读内存,这个对象包含4个IOAccelEvent对象:

在IOAccelResource对象销毁过程中,testEvent函数会被执行,用于测试IOAccelResource对应的绘图指令是否已经被GPU处理完成:

在这个代码逻辑中,由于内核充分信任这块IOAccelEvent内存不会被用户态程序篡改(因为是只读映射),因此并没有对channelIndex做边界检查。这虽然在绝大多数情况下是安全的,但如果我们配合漏洞1,在用户态直接修改这块只读内存,就会导致可信边界被彻底破坏,从而造成m_stampAddressArray的越界读以及m_inlineArray的越界写:

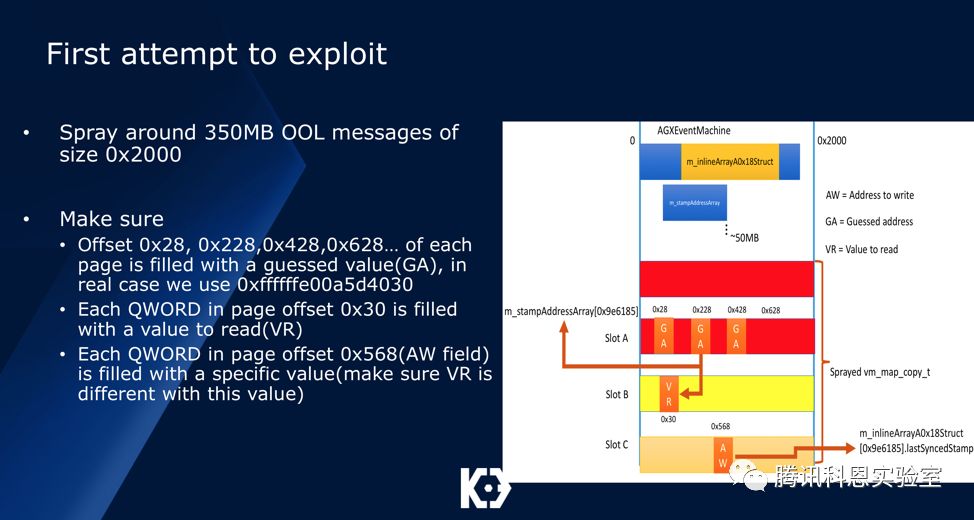
最后,我们讨论两个漏洞的利用。要利用这两个漏洞并不容易,因为我们需要找到一种内存布局方法,让m_stampAddressArray以及m_inlineArray这两个数组的越界值都可控。但因为这两个数组在系统启动初期就已经分配,而且这两个数组的元素大小并不相同,因此布局并不容易。

经过研究,我们发现,只有通过指定大index以及合理的内核对喷,才能实现这样的布局。因为在iPhone7设备中,用户态应用可以喷射大概350MB的内存,并且在m_stampAddressArray以及m_inlineArray初始化后,会有额外50MB的内存消耗,因此我们需要使得index满足以下两个条件:
index ∗ 24 < 350MB + 50MB
index ∗ 8 > 50MB
也就是说index的值需要在[0x640000, 0x10AAAAA]这个范围内,可以使得两个数组的越界值极大概率在我们可控的喷射内存内:

然后,下一个问题就是,我们是否能够任意地址读以及任意地址写。对于任意地址读似乎不是什么问题,因为m_stampAddressArray的元素大小是8字节,可以通过指定任意index到达任意内存地址。但任意地址写需要研究,因为m_inlineArray的元素大小是24字节,只有一个field可以用于越界写,所以不是每个内存地址都可以被写到:

在这种情况下,我们退求其次,如果能实现对于一个页中的任意偏移值进行写操作,那么也可以基本达到我们的要求。在这里,我们需要通过同余定理来实现:

因为:
0xc000 ≡ 0(mod0x4000)
因此对于任意整数n,满足:
n ∗ 0x800 ∗ 24 ≡ 0(mod0x4000)
由于0x4000 / 24 * 0xF0 / 16 = 0x27f6,我们得到:
0xF0 + 0x27f6 ∗ 24 + n ∗ 0x800 ∗ 24 ≡ 0(mod0x4000)
最后我们得出结论,如果需要通过越界m_inlineArray写到一个页的前8字节,需要满足:
index = 0x27f6 + n ∗ 0x800
而如果需要到达任意页内偏移,假设要到达偏移m,则index需要满足条件:
index = 0x27f6 + 0x2ab ∗ m/8 + n ∗ 0x800

与之前得出的index范围结论相结合,我们最终选择了index值0x9e6185:

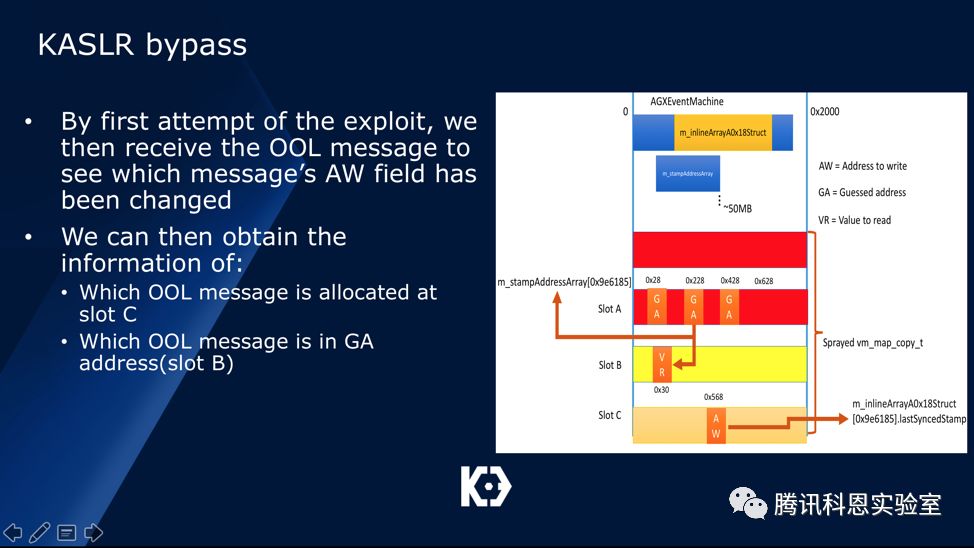
然后我们通过以下几个步骤进行漏洞利用,在第一个布局中,我们得出Slot B与Slot C的index值:
随之我们将slot B填入相同大小的AGXGLContext对象,然后再次利用漏洞泄露出其vtable的第四位:
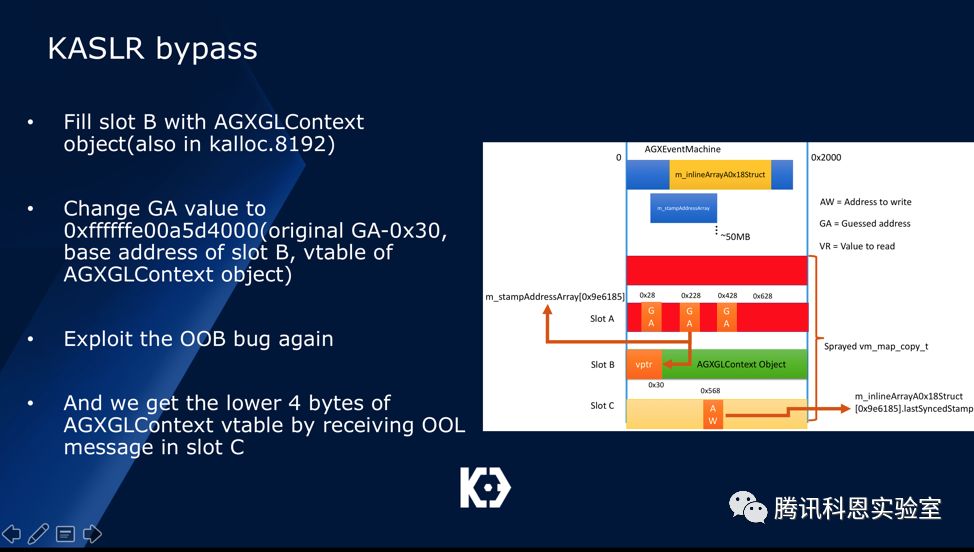
最后我们通过将Slot C释放并填入AGXGLContext对象,将其原本0x568偏移的AGXAccelerator对象改为我们可控的内存值,实现代码执行:

最后,整个利用流程总结如下:
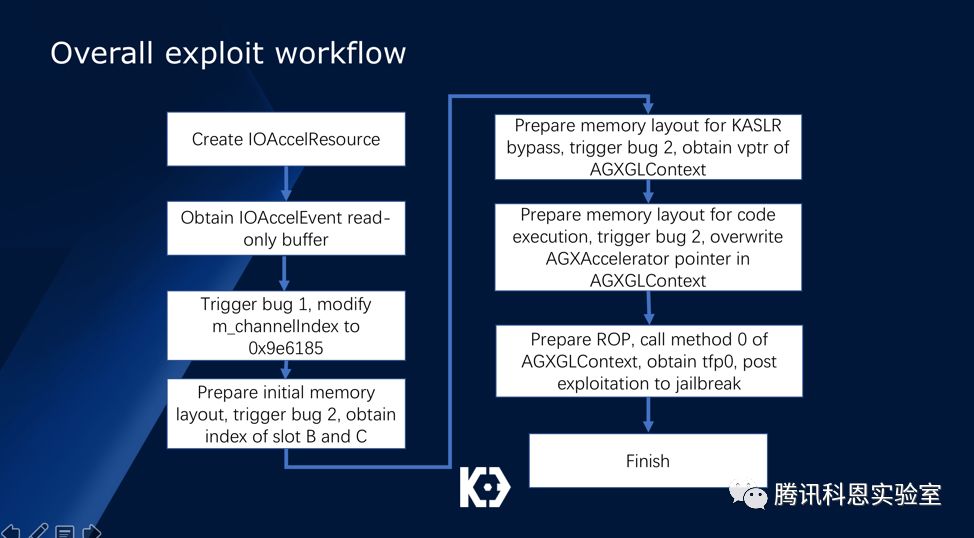

在通过一系列ROP后,我们最终拿到了TFP0,但这离越狱还有一段距离:绕过AMFI,rootfs的读写挂载、AMCC/KPP绕过工作都需要做,由于这些绕过技术都有公开资料可以查询,我们这里不作详细讨论:


最后,我们对整条攻击链作了总结:
在iOS 11的第一个版本发布后,我们的DMA映射漏洞被修复;
但是苹果图形组件中的越界写漏洞并没有被修复;
这是一个”设计安全,但实现并不安全”的典型案例,通过这一系列问题,我们将这些问题串联起来实现了复杂的攻击;
也许目前即便越界写漏洞不修复,我们也无法破坏重新建立起来的只读内存可信边界;
但是至少,我们通过这篇文章,证明了可信边界是可以被打破的,因为用户态只读映射是”危险”的;
也许在未来的某一天,另一个漏洞的发现又彻底破坏了这样的可信边界,配合这个越界写漏洞将整个攻击链再次复活。这是完全有可能的。


对iOS安全研究感兴趣的朋友可以查看此次议题发布的白皮书《KeenLab iOS越狱细节揭秘:危险的用户态只读内存》获取更多信息。
声明:本文来自腾讯科恩实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
