
近些年来,人们越来越多地关注神经网络后门攻击的研究。相比于对抗样本和毒化攻击来讲,后门攻击更加灵活,几乎可以发生在深度学习过程的每个阶段。然而,大多数现有的后门攻击方法很容易被一些简单的数据预处理(如旋转、放缩、裁剪等)所防御,而且用于后门攻击的触发模式也不够隐蔽,极易被人眼察觉。为了解决隐蔽性和鲁棒性的局限,我们提出了一种称为“毒墨水”后门攻击方法。
我们的最终目标是设计一种鲁棒且不可见的后门攻击方法,为此,将该目标细化为以下几点要求:1)后门攻击的触发模式应易于被目标模型学习,不会混淆目标模型学习以影响原始任务的性能;2)触发模式在常见的数据预处理之后应保持一致性,从而确保其对数据预处理的鲁棒性;3)触发图像需要在视觉上与对应的干净图像不可区分。
为此,我们提出了一种全新的触发模式,即基于图像结构(边缘)的触发模式。该设计来源于以下几点分析:1)一方面,DNN的浅层往往捕获低级结构信息,这意味着DNN可以轻松捕获结构,另一方面,DNN的最终输出通常取决于对象纹理而不是结构信息,这间接表明了基于结构的触发模式不会破坏原始任务的性能,因此它满足上述第一个要求;2) 图像结构分布在整个图像中,在常见的数据预处理下可以保持其语义不变(如图像边缘经过旋转之后还是图像边缘),这间接满足第二个要求;3)边缘结构属于图像的高频分量,因此隐藏在其中的触发信息更难被发现,这满足了第三个要求。
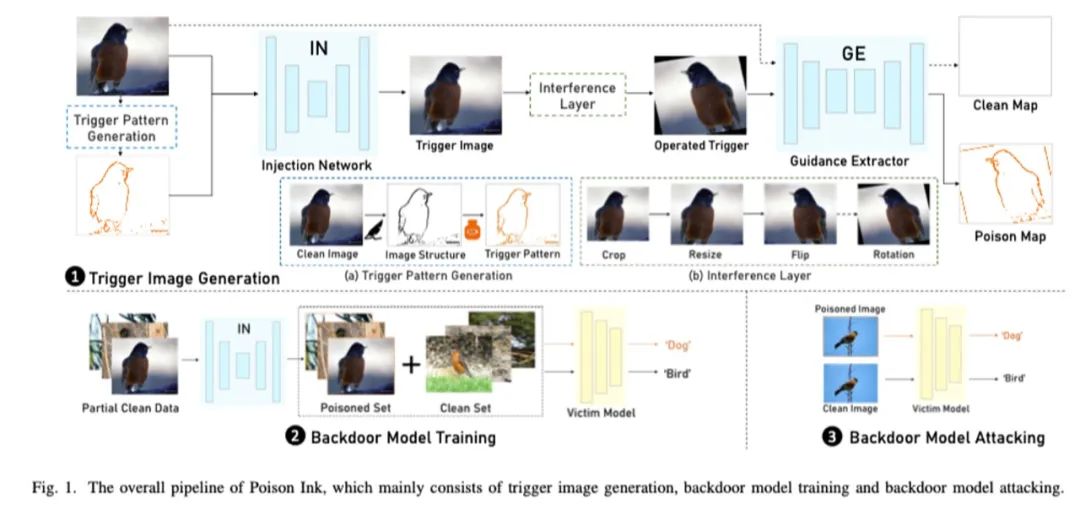
如图1,我们展示了毒墨水的整体流程图。具体来说,我们首先利用图像结构作为触发模式的嵌入区域,并将毒墨水(即颜色信息)填充在该区域以生成最终后门攻击的触发模式。我们使用一个注入网络来隐蔽地将触发模式注入原始干净图片。为了使有毒信息按照我们事先假设的方式嵌入结构区域,我们引入了一个提取器来指导注入网络的训练。此外,我们又引入了一个噪声层来进一步增加嵌入触发模式后的触发图片对不同数据处理的鲁棒性。在后门模型的训练过程中,我们利用上述训练好的注入网络,将相应的触发模式注入干净图片从而获得触发图片,并遵循上述步骤按照一定比例污染原始训练集,进而对模型进行后门训练。在攻击阶段,我们只需出示同样方式生成的触发图片,就可以使模型功能发生异常。
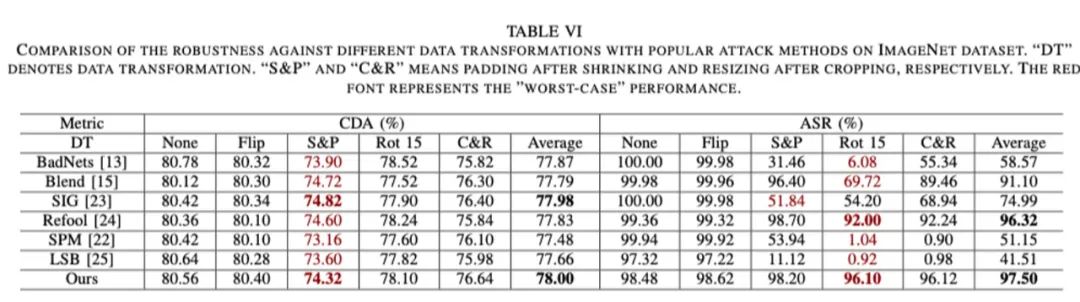
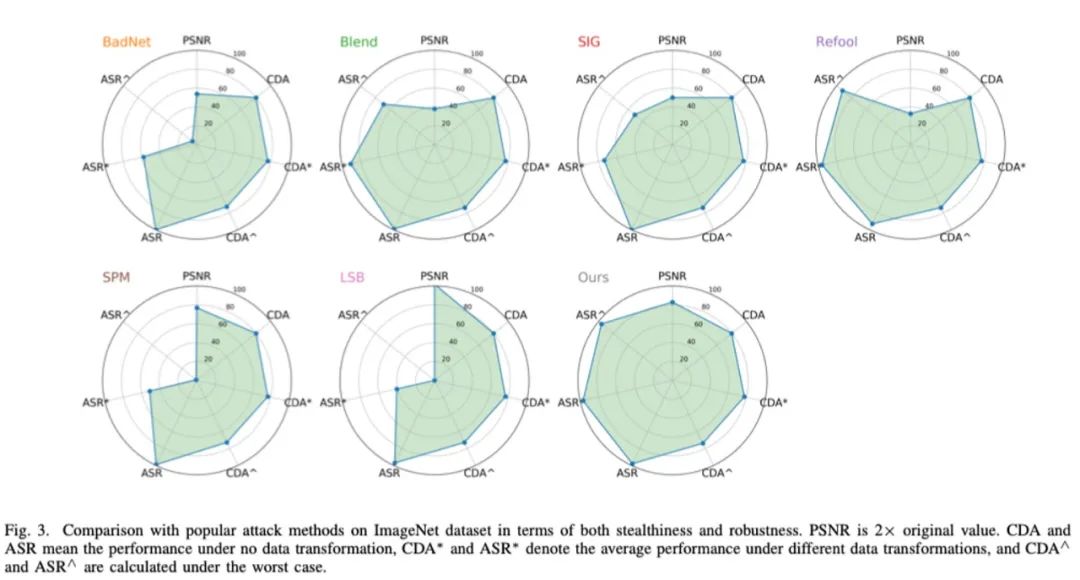
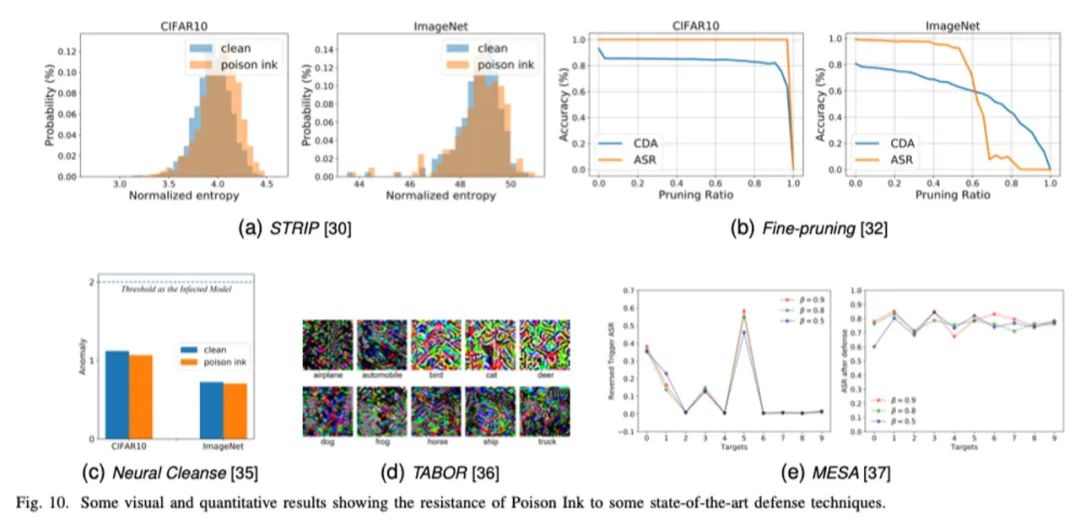
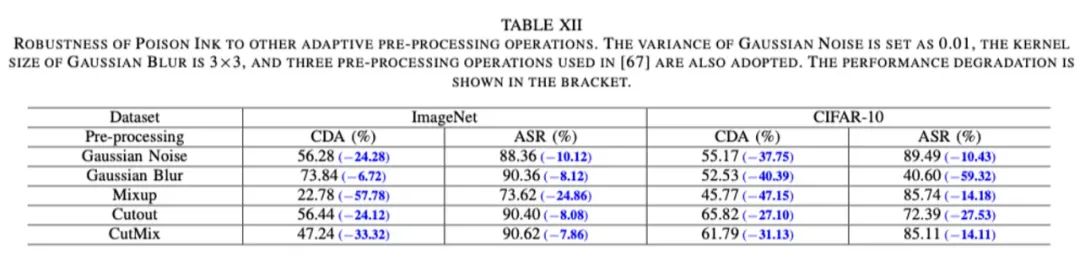
通过大量的实验,我们验证了所提毒墨水在隐蔽性和鲁棒性方面可以实现更好的平衡,并对一些自适应防御仍具有攻击性。部分实验结果展示如下:

论文信息:
相关论文已被 IEEE Trans. on Image Processing 2022 (TIP) 录用,作者为中国科学技术大学网络空间安全学院的张杰、黄启栋、张卫明、俞能海;微软雷德蒙德研究院的陈冬冬;香港城市大学的廖菁;便利蜂研究院的华刚;北京电子科技学院的封化民。
Jie Zhang, Dongdong Chen, Qidong Huang, Jing Liao, Weiming Zhang, Huamin Feng, Gang Hua, Nenghai Yu, “Poison Ink: Robust and Invisible Backdoor Attack”, IEEE Transactions on Image Processing, 2022, Accepted.
张卫明,中国科学技术大学
邮箱:zhangwm@ustc.edu.cn
个人主页:http://staff.ustc.edu.cn/~zhangwm/
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
