摘要
近年来,人工智能技术在开源情报领域的应用不断加深,尤其是机器学习、网络爬虫、智能图像分析、自然语言处理等技术的广泛应用,大规模、高质量、多样化且极具情报价值的信息被高效能挖掘出来,为开源情报注入了新的发展动力。面向未来人工智能与开源情报的融合发展,分析了人工智能技术在开源情报周期中的数据采集、数据处理、数据分析和情报分发等核心阶段中的应用,介绍了美国在该领域的重点举措,并提出了融合发展的相关建议。
内容目录:
1 开源情报周期及发展趋势
1.1 开源情报周期
1.2 开源情报面临的瓶颈问题
1.3 开源情报发展趋势
2 人工智能在开源情报周期中的应用
2.1 数据采集阶段
2.1.1 自主精确搜集和筛选
2.1.2 个性化预处理
2.1.3 信息优先级排序
2.2 数据处理阶段
2.2.1 大规模数据集的自动化处理
2.2.2 自动分类和智能推荐
2.2.3 早期预警
2.3 数据分析阶段
2.3.1 自主分析
2.3.2 模式识别和语义分析
2.3.3 增强监测和风险识别
2.4 情报分发阶段
2.4.1 定制化服务
2.4.2 可视化呈现
2.4.3 按需安全分发
3 美国人工智能与开源情报融合发展情况
3.1 顶层战略明确发展纲领
3.2 防务智库聚焦新兴应用
3.3 公私合作促进领域协同
4 结论与展望
随着智能世界的加速到来,人工智能作为一种通用目的技术(General Purpose Technology,GPT)正与社会经济产生更多的碰撞。世界主要国家不断加大在人工智能领域的战略布局,美国颁布了《美国人工智能倡议》《国防部人工智能战略》等 AI 技术创新和发展战略;俄罗斯将人工智能发展战略纳入“俄罗斯联邦数字经济”国家发展计划。与此同时,我国国家政策亦持续为人工智能层层加码,早在《2019 年政府工作报告》中就特别指出“深化大数据、人工智能的研发应用”,以加快 AI 与各领域的融合发展。
当前,人工智能技术在军事、经济、社会的渗透力和推动力越来越强,开源情报也成为其主要应用领域之一。机器学习、网络爬虫、智能图像分析、自然语言处理等人工智能技术在开源情报中的广泛应用,使得大规模、高质量、多样化且极具情报价值的信息被高效能挖掘出来,开源情报数据量呈指数级增长,给开源情报带来了颠覆性变革。未来,人工智能技术在开源情报领域的发展与应用,将会显著提升开源情报在数据规模呈爆炸式增长的网络空间时代的适应性,使其以更快的速度、更大的规模分析聚合,成为更具价值的情报产品。
1开源情报周期及发展趋势
随着互联网在全球范围内的迅速发展,可供人们利用的网络信息飞速膨胀,互联网已成为取之不尽、用之不竭的公开来源信息资源宝库。美国中央情报中心曾指出,高达 80% 的情报可以从公开信息源获得 ,开源渠道的情报价值与日俱增,在情报体系中发挥的作用越来越大。
1.1 开源情报周期
开源情报(Open Source Intelligence,OSINT)作为军事情报的重要组成部分,自 20 世纪中叶开始便活跃于情报体系。关于开源情报的定义,目前暂未形成统一描述,根据美国 2006 年《国防授权法案》,“开源情报是为了响应特定的情报需求,通过搜集和利用公开可得信息而进行情报生产,并及时地分发给适当的受众群体”。
开源情报周期遵循情报生成的基本规律,国内外研究学者提出过不同的开源情报周期模型,其侧重点各不相同,但大致均包含从情报需求、数据收集直至反馈评估的一系列过程。从流程、技术及循环视角出发,能够对开源情报周期形成较全面的认识。
从流程视角来看,田仲等人 认为开源情报周期可分为需求确定、计划指导、数据采集、数据预处理、数据分析和数据分发 6 个环节。该模型侧重呈现了开源情报分析的步骤和过程,从确定需求出发,根据开源情报需求进行开源数据的采集工作,继而对搜集得到的数据进行加工、处理和分析,最后将形成的开源情报产品分发给用户。
从技术视角来看,由 Pastor-Galindo 等人组成的西班牙研究团队将开源情报工作周期分为搜集、分析和知识抽取 3 个步骤 。面向网络数据集,将搜集阶段获得的数据碎片视为从原料输入到分析阶段,侧重于借助人工智能技术,经过诸如语义分析、回归分析、关联技术等,按照需求输入形成开源情报产品。
从循环视角来看,兰德公司(Rand)提出开源情报循环周期由搜集、处理、利用、生产 4个环节组成(如图 1 所示),主要强调各组成部分的循环和反馈 。搜集阶段是在明确的计划或指导下对互联网开源信息的获取和留存;处理阶段包括对海量数据进行进一步的分类、处理,将原始数据转换为可用的情报信息;开发阶段包含对信息源的验证和信息内容可信度的评估;展示阶段包括分类和分发,将有价值的开源情报产品提供给用户。
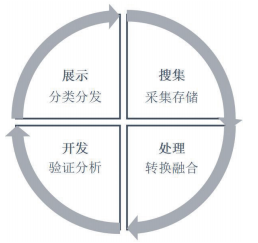
图 1 开源情报循环周期模型
1.2 开源情报面临的瓶颈问题
当前,开源情报在海量数据条件下,可以及时、高效、智能地完成情报分析,但同时也面临着一些瓶颈问题。一是从量来看,开源情报的信息获取渠道多元化,包括政府公共文件和报告、在线多媒体内容、社交网络、报纸,甚至是“深网”“暗网”的数据和信息等,采集到的数据格式各异,难以处理。二是从质来看,开源情报信息来源不断向互联网转移,而互联网上采集到的原始数据约 80% 都是非结构化数据,且虚假信息层出不穷,各类数据资源鱼龙混杂、真伪莫辨。三是从时效性来看,社交媒体等互联网平台的舆论信息,往往成为把握事态发展、推理事件范围、预测事件态势的第一窗口,而舆论信息是瞬时更新的,且开源情报信息容易失效。为此,探索将人工智能等新兴技术应用到开源情报工作中,可以提升开源情报搜索能力,为决策者提供有效的战略情报,对在日益复杂的外部环境中保持情报竞争优势、维护国家安全利益具有重要意义。
1.3 开源情报发展趋势
一是未来开源情报渠道的价值属性持续提升。凭借网络时代社交媒体平台的蓬勃发展,在互联网上可挖掘到大规模、高质量、多样化且极具情报价值的信息。因此,相比其他情报渠道,开源情报兼具信息面广、时效性高、可用性强等优势,在情报体系中的价值和地位将会大幅提升。
二是人工智能的应用持续为开源情报赋能。数据处理和人工智能系统的计算和处理能力的巨幅增长,计算机视觉、自然语言处理等技术的广泛应用,以及商用人工智能应用程序与情报数据和系统的有效结合,将显著提升开源情报收集、处理数据和从数据中提取情报信息的能力。
三是开源情报推动人工智能领域的深化发展。随着新的全球威胁快速演变和出现,以及政策制定者决策周期的加快,情报分析过程及范式面临变革。一些国际利益集团采取非正常途径,从开源和闭源情报中挖掘敏感信息,对其他国家的重要行业、金融秩序、社会安全等构成了较大威胁。须在提升智能融合、重塑、拓展和强化开源情报研究的可用性和时效性的同时,确保人工智能在开源情报中使用的合规性。
2 人工智能在开源情报周期中的应用
综合国内外学者提出的开源情报周期模型,以基于流程视角的开源情报周期模型为参考,同时结合人工智能技术在开源情报周期中的具体应用,因此对“需求确定”“计划指导”两个阶段不做重点分析,主要聚焦开源情报的“数据采集”“数据处理”“数据分析”“情报分发”4 个核心阶段(如图 2 所示),并分别阐述人工智能技术对上述 4 个核心阶段的关键性驱动作用。
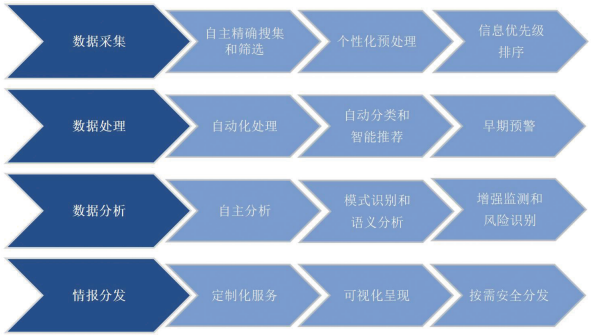
图 2 人工智能技术优化开源情报周期
2.1 数据采集阶段
开源情报数据被隐藏在广阔的虚拟空间原始数据中,普通的自动化检索难以满足海量数据的处理和分析需求。将基于人工智能的数据采集模型运用到开源情报提取中,显著提升了开源情报在数据规模呈现爆炸式增长的网络空间时代的适应性。
2.1.1 自主精确搜集和筛选
开源情报数据采集阶段利用人工智能驱动的自主传感器和网络爬虫程序,实现持续自动抓取大量数据,形成针对目标的自主和半自主数据采集,爬虫获取数据的效率和覆盖率都得到了显著提升。同时,利用基于机器学习的分析平台筛选社交媒体等数据源,构建基于知识库的主动式专题搜索引擎系统模型,实现自动化检测,提高抓取和筛选数据的效率,并自动生成包含任务、地点和时间等要素的规范化材料。
2.1.2 个性化预处理
利用人工智能工具在采集阶段进行初筛、分类等预处理,使采集到的数据更加易于后续的处理和分析,依靠深度学习模型,对海量开源情报进行多维度的学习,形成高效可用的情报分类器,利用分类器进行预处理,完成采集的同时进行分类派发、存储、管理,为后续的处理和分析环节提供结构化的数据支撑。
2.1.3 信息优先级排序
开源情报借助人工智能技术,通过预先标记等功能确定数据的重要性等级和优先级排序。如利用强化学习模型,根据多维度可信特征对模型进行激励,加强爬虫获取情报的可信度和相关性,同时利用情报数据类型库对数据进行全局融合、研判与标注,提取优先级最高的信息。
2.2 数据处理阶段
在数据处理阶段,由于开源情报数据的无序性、异构性和庞杂性,信息量和价值点难以被界定。相比之下,人工智能技术则能突破人脑的计算速度和耐力限制,情报人员利用人工智能图像处理等技术,对采集到的数据进行清洗、甄别、比对及分类,可使格式多样的、结构不规则或不完整的数据转化为“可读性”数据,极大提升数据处理的效率和稳定性,满足开源情报的数据处理需求。
2.2.1 大规模数据集的自动化处理
网络信息时代的大规模数据集给数据处理的实时性带来巨大的挑战,采用人工智能技术可实现以较快的速度和较大的规模执行诸如图像识别和分类等关键、耗时的任务。如计算机视觉可用于协助处理大量图像和视频数据流,机器学习算法可用来处理大型数据集,这些人工智能工具的发展,将使数据处理的后端以更加易于理解和可操作的形式交付至开源情报的分析阶段。
2.2.2 自动分类和智能推荐
数据处理阶段面临数据格式标准化、异常数据识别、错误纠正、重复数据清除等环节。机器学习技术的进步,使得算法能够对大量的开源信息进行归类,远超传统的开源情报分析人员手工完成的任务量。人工智能工具除了可以帮助处理日益增长的开源情报数据,还可以显示与开源情报任务需求最相关和最有用的信息。如推荐算法可根据开源情报人员的任务需求,发现模式、趋势和相互关系,查找和标记相关度较高的内容。
2.2.3 早期预警
人工智能技术能够辅助情报人员对特定分析需求保持持续的态势感知,识别原始情报中的细微变化、隐含趋势、潜在威胁及相关联系,提升开源情报的精准性。此外,对人工智能工具进行训练,识别和标记关键信息,如机器学习可以帮助建立正常行为活动的基线准则,识别目标环境中不可察觉的变化,并感知异常或高风险行为,为分析人员提供“早期预警”。
2.3 数据分析阶段
在数据分析阶段,针对完成预处理的数据进行进一步的特征提取,并在此基础上对数据进行整合和分析,最终形成可被利用的、有价值的情报。大数据时代,将庞大、多样、无关联的数据转化为诸如趋势走向、关键数据点、态势分析等直观可用的信息,是开源情报面临的一大难题。人工智能技术中基于特定规则生成的算法和模型可以对所收集和处理的信息做出进一步判别,提炼出看似无用的海量信息之间的关联,挖掘出大量信息背后所蕴含的知识。
2.3.1 自主分析
人工智能工具自动化执行某些特定类型的分析工作,使开源情报人员能够将更多的时间密集型任务交给计算机完成。如地缘政治事件、冲突地区的政治和军事发展等常规开源情报产品,人工智能工具可以完成相关信息的整合,并生成摘要报告,情报分析人员只需对其进行更新、微调或补充即可。美国国防情报局的机器辅助分析快速存储系统(Machine-assisted Analytic Rapid-repository System,MARS)可连接不同来源的情报数据,并自动分析原始情报,极大地提升了开源情报的收集、融合及分析能力。
2.3.2 模式识别和语义分析
通过对数据进行筛选和简化,人工智能技术可以帮助开源情报人员进行语义分析和理解。例如,采用深度学习算法可识别数据流中的模式和趋势,推断目标之间的关系;自然语言处理技术可以进行由语音到文本的转录、语音识别、文本摘要、语言翻译等;先进的自然语义分析和模式识别技术还能够提高复杂背景和环境下的语言、图像及视频识别的准确性。
2.3.3 增强监测和风险识别
人工智能可以监测日常情报信息变动中的增量变化,避免错过情报信息的最佳时间窗口。通过非结构化数据处理、动态情报分析和多源情报融合,构建统一的现实场景,识别重要目标和事件,发现规律并推断其发展动向,察觉潜在威胁与风险。此外,分析人员还可以利用基于人工智能的数据挖掘、情绪分析、地理定位等工具,帮助监测和预测大规模抗议等破坏性事件,对社会潜在危机和不稳定性做出预警。美国国防部高级研究计划局于 2019 年开展“知识导向型人工智能推理模式”项目,旨在用一种“基于模式的人工智能”技术感知世界各地的事件,尤其可用于发掘多媒体信息中的复杂事件,并对其进行上下文理解和时间推理,预测其发展趋势。
2.4 情报分发阶段
在情报分发阶段,开源情报也面临着两大难题:一是面对不同类型的开源情报需求,如何针对性提供具有实时性、完整性、准确性的情报产品;二是情报信息的共享,如何利用公共的或可访问的数据架构来共享数据集,并促使情报界实现更容易、更安全、不同密级的信息共享。
2.4.1 定制化服务
类似于人工智能可以帮助分析人员处理和确定相关数据的优先级,也可以帮助开源情报人员根据任务需求,为不同群体定制情报服务。人工智能工具可以帮助不同群体确定其情报产品的优先级,针对性推送情报读物;机器学习模型可以智能推荐关联度高的内容,并随着时间的推移采用新的数据进行自动更新。
2.4.2 可视化呈现
开源情报人员需将复杂的信息或规律以图形符号的形式表达出来,实现对情报获取目标的直观展示。利用交互式图形、动画和其他增强现实或沉浸式技术可以改变情报产品的呈现形式,可视化展示情报目标之间的关系和网络,进而辅助决策人员推断其中的关键影响因素。
2.4.3 按需安全分发
依靠新兴技术,开源情报系统通过提供身份认证、访问授权、分级管理、密码管理、容灾备份、数据校验等安全功能,保障数据传输和访问安全以及数据存储安全。如人工智能和云计算能够根据用户的属性(如等级、角色和地点),自动化、针对性地向“需要知道”的用户提供关键的、具有时间敏感性的情报。
综上,人工智能技术在开源情报领域的发展与应用,重塑了开源情报周期中的重点环节,为开源情报的发展带来了新机遇,推动开源情报工作朝着数据采集智能化、异构数据整合化、信息识别自动化、情报知识关联化的趋势加速发展,对开源情报周期中的核心阶段起到了巨大的赋能增效作用。
3 美国人工智能与开源情报融合发展情况
美国高度重视开源情报领域的创新与发展,早在 2005 年就创建了国家独立的开源情报机构,即情报总监开源中心(Open Source Center,OSC),隶属于美国国家情报总监。近年来,美国情报界(Intelligence Community,IC)早已把人工智能技术融入到开源情报周期的核心环节,从顶层战略、防务智库、公私合作等方面积极推动开源情报的发展。
3.1 顶层战略明确发展纲领
2019 年,美国国家情报总监办公室(Office of the Director of National Intelligence,ODNI) 发布《国家情报战略》,重点关注了人工智能、自动化和高性能计算等新兴技术给情报界带来的机遇和挑战 [8];同年,ODNI 还发布了《AIM倡议:利用机器增强情报战略》,强调 AIM 倡议的目标之一即是情报界整合利用现有联邦政府和私营部门对人工智能在开源情报领域的研究成果,从根本上改变情报界的情报产出方式。次年,ODNI 颁布《2020—2022 年美国国家反情报战略》,提出了反情报威胁的主要趋势,重点阐述了越来越先进的情报功能和技术,包括网络工具、增强的技术监视设备和大数据分析等带来的威胁。
3.2 防务智库聚焦新兴应用
在防务智库方面,2018 年 5 月,Rand 发布研究报告《为防务机构定义第二代开源情报》,指出得益于机器学习、自然语言处理、智能图像分析等人工智能技术的发展与应用,第三代开源情报能以更快的速度、更大的规模分析聚合成更具价值的情报产品;2020 年 4 月,战略与国际研究中心(Center for Strategic and International Studies,CSIS)成立技术与情报工作组,研究发布了《分析优势:利用新兴技术来转变情报分析》等 4 份报告,重点探讨新兴技术对美国情报界的影响和应用。总体而言,美国情报界致力于利用新兴技术优化整个开源情报流程,强化美国相对于战略竞争对手的情报优势。
3.3 公私合作促进领域协同
在过去十几年中,私营部门已逐步发展成为美国情报界技术和咨询服务的主要供应商,按照性质和分工可以将这类私营部门分为 4 类:一是防务巨头,负责提供情报分析、风险评估等服务,如洛克希德·马丁公司、诺斯罗普·格鲁门公司、雷神公司等;二是网络威胁情报公司,负责提供情报搜集、预测性情报以及威胁信息共享等,如 Recorded Future 和 Palantir 等;三是信息科技公司,负责提供搜索引擎技术、开源记录软件、自动化数据库系统等技术支持,如谷歌、IBM、微软等;四是管理咨询公司,负责提供情报咨询规划、战略运营及情报对策研究等,如埃森哲、博思艾伦咨询公司、德勤咨询公司等。因此,得益于联邦政府的战略支持和私营部门的技术优势,开源情报领域的协同发展基本满足了美国情报界日益增长的开源情报需求。
4 结论与展望
未来,人工智能、机器学习、云计算、高级传感器技术与开源情报的融合将更加紧密,开源情报的价值和决策辅助方面的作用将会更加显著。值得注意的是,人工智能等新兴技术在改变和增强开源情报潜力的同时,还可能被用来渗透、操纵和削弱开源情报能力,给开源情报人员带来了前所未有的挑战。可以预见的是,欺骗技术可以通过欺骗算法对数据错误进行分类;基于人工智能的虚假信息行动可以使对手以前所未有的规模传播虚假信息;外国情报机构可以利用反人工智能技术将“中毒”或虚假数据插入训练集,以破坏机器学习模型。当前,世界主要国家还将继续按下开源情报发展的快进键,我国如何提升人工智能技术和开源情报服务的融合发展值得深思,基于此提出如下建议。
一是在开源情报体系方面,建议加快建立和完善科学合理的开源情报体系,从总体上明确开源情报工作的战略部署、体制机制以及发展方向。欧美等地区和国家已在短短十几年间建立了较为完善且层次分明的开源情报体系,尤其是美国,建立了涵盖战略指导、机构设置、任务管理、运行机制、教育培训等方面的开源情报体系,如机构设置方面,美国国家开源委员会(National Open Source Center,NOSC)对情报界 17 个机构的开源情报行动进行统一协调。相比而言,我国亟待加强开源情报体系的建设及应用,聚合政府、军队和业内地方力量,共同探讨采用先进技术为决策者提供战略情报的方式。
二是在人工智能技术方面,建议高度重视基础算法的研究和数据的深度分析,加强人工智能的数据分析和算法能力。国外情报领域主要围绕机器学习、深度学习算法的优化和应用开展研究,如深度神经网络、卷积神经网络在图像识别、情感分析、自然语言处理等方面的应用。相比而言,在深度学习、卷积神经网络研究方面我们已取得进展,未来还应不断加强自然语言处理、计算机视觉、语音识别、机器学习等技术在开源情报各流程中的发展与应用,促进情报的获取、存储、推理和应用。
三是在情报分析人才方面,建议加大开展计算机和网络操作技能、情报软件利用、情报研究和分析、重大情报敏感意识、多语种等方面的能力培养。重视开源情报人才多层次供给,开展多维度的能力培养和技能培训,是跨越当前开源情报人才现状与日益提升的开源情报工作需求鸿沟的关键所在。例如,美国开源中心下属的开源学院定期开展专业的、成体系的开源技能培训;澳大利亚国家开源情报中心十分重视计算机和网络操作技能、情报软件利用、情报研究和分析、重大情报敏感意识、报告写作能力、多语种等方面的能力培养。我国应加强开源情报人才多维度、多方面能力的培养,不断提升利用开源信息服务决策的能力。
四是在社会科技力量方面,建议加强国家情报力量与高科技企业间的紧密联系,在保障国家安全的前提下,充分发挥地方科技资源优势,提升情报智能化速度。人脸识别、语音识别和自然语言处理等技术在商业领域已取得良好的应用效果。美国国家情报力量与高科技企业间建立了紧密的关系,许多重大项目通过市场化运作高效执行。我国在智能语音、图像识别翻译等应用方面已取得不少成果,未来开源情报的发展应进一步吸纳商业创新力量和成果,加快融合发展。
引用格式:罗仙 . 人工智能技术在开源情报周期中的应用 [J]. 信息安全与通信保密 ,2022(7):33-41.
作者简介
罗 仙(1991—),女,硕士,工程师,主要研究方向为网络安全战略研究。
选自《信息安全与通信保密》2022年第7期(为便于排版,已省去原文参考文献)
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
