
分享嘉宾:李林峰博士 医渡云 技术创新副总裁
编辑整理:田育珍 搜狗
出品平台:DataFunTalk
导读:今天介绍的主题是真实世界医疗知识图谱及临床事件图谱的构建。数据源主要来自于医院的EMR、HIS、LIS、RIS等系统,以及医学文献、临床指南、书籍和药品说明书这类已经沉淀好的知识。
首先简单介绍一下医渡云和几个医疗数据相关的概念。
医渡云成立于2014年,公司以自主研发的数据智能基础设施“YiduCore”对获得授权的大规模多源异构医疗数据进行深度处理和分析,建立真实世界疾病领域模型,助力医学研究、医疗管理、政府公共决策、创新药物研发、帮助患者实现智能化疾病管理,通过技术提高医疗效率、降低成本,加速行业数字化转型,努力推动实现数据智能绿色医疗新生态。公司已于2021年1月15日在香港联交所上市。
几个医疗数据相关的概念:
EMR是电子病历系统,会记录患者主诉、现病史、体格检查等;如果是住院患者,也会记录手术记录、病程记录、出院记录等大量自然语言描述。
HIS基本是结构化数据,主要是开检查、检验、用药、医嘱的信息。
LIS是做检验结果记录的,比如:血常规中检验的数据项和结果。
PACS及RIS分别是做影像和影像报告管理的。
01 医疗知识图谱构建
传统的医疗知识图谱一般是基于医学书籍、指南、文献等知识库进行构建,今天我们介绍的工作是如何通过真实世界电子病历数据构建真实世界医疗知识图谱及临床事件图谱。
由于历史原因,医疗信息化各个厂家的特点不同,患者信息存储在不同院内系统。截至目前,国内大多医院的信息系统是由不同厂家的多个系统共同建设的。要使用分散在各处系统中的数据时,需要先对数据进行聚合。将同一个患者、同一次就诊的数据从不同的系统中抽取出来,组合成患者维度及就诊维度的全景数据。
将临床数据用于数据挖掘、管理等场景时,需要先对数据进行脱敏。医院数据存在数据质量差、表之间的关联不合理等问题,因此需要对数据质量进行控制。此外,之前提到会有大量非结构化的文本描述,需要进行结构化和标准化(归一)。以上这些处理都属于数据治理的范畴。
基于患者全景数据和现有的医学知识构建疾病知识图谱后,可以将其应用在CDSS临床决策支持、医院病例搜索排序、智能问诊和深度学习结合的知识融合等场景。结合该知识图谱,对每个患者的全景数据进行进一步加工,抽取出临床诊疗事件,形成患者维度、面向专科疾病的事件图谱。事件图谱可以用于专科诊疗视图、自动生成病历、事件搜索以及因果关系分析等。

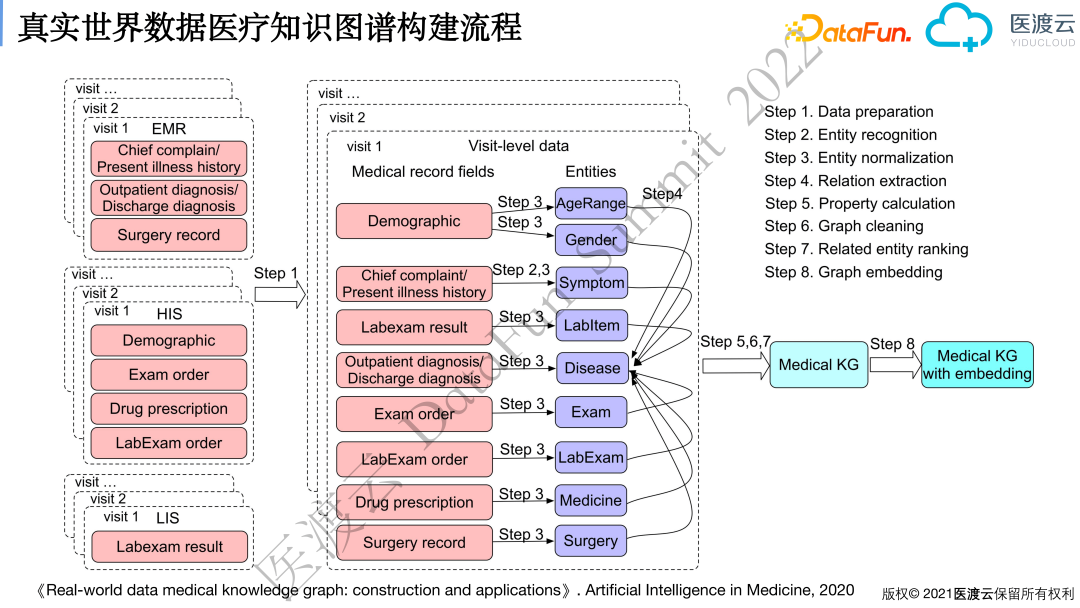
下图是疾病维度知识图谱构建的pipeline。
先将不同系统、不同次就诊的信息,按照同一个患者、同一次就诊、同一次发病等维度进行融合。一开始数据挖掘是基于就诊维度的数据,后来发现有些数据分析和挖掘的需求需要基于患者和发病的维度。比如,一个肿瘤患者患病后会多次去医院就诊,其整体治疗方案需要将患者连续多次就诊的信息融合在一起才能计算出来,称之为一次发病。
一次发病的数据包含患者的基本信息、初次就诊时的主诉、现病史、当时的检查检验结果、医生诊断、药品医嘱、手术记录等。基于这些原始信息,经过实体抽取、实体标准化流程,形成标准的实体(entity)。对实体(entity)进行关联关系构建,形成图(graph)。在实体间链接(link)创建好之后,进行属性(property)的计算。考虑到图谱是基于大量病例实现的,会存在数据质量的问题,因此需要进行图清洗(graph cleaning),最后再进行一些实体的排序。如果需要将实体应用到深度学习中去,还需要进行图嵌入(graph embedding)。
为了完成上面的pipeline,医渡云开发了数据ETL平台、医学词典管理平台、结构化抽取平台、标注平台、质控平台以及机器学习平台。
我们为很多家医院提供大数据平台和知识图谱技术,由于每家医院的原始信息系统来自于不同的厂家,数据表字段也不一样,需要先定义统一的数据模型。该数据模型可以覆盖通用疾病诊疗过程记录,每个患者的数据都会进行标准化。我们会先将各医院的原始库表结构映射为该通用模型,后续的数据质控、结构化归一、数据挖掘等都是统一流程。
下图是实体识别和标准化的过程。图中的大段文本是住院患者的现病史,一般会描述患者多少年前有什么诊断、当时的临床表现、后续的治疗过程,以及本次就诊的原因等。
以识别阳性症状和阴性症状为例,模型用词典识别、LSTM-CRF实体识别(NER , Named Entity Recognize)模型识别症状实体,之后使用正则表达式进行匹配,最终生成需要的实体或关系。

归一化主要是将医院信息系统中的原始术语转化为标准描述。比如,医生在系统中书写诊断和手术的写法非常多,过多的取值会导致无法进行质控或统计分析,也无法进行不同医疗机构之间的统一管理。目前我们采用了基于医学语义变换的符号相似度排序,并与深度学习模型进行hyper融合。
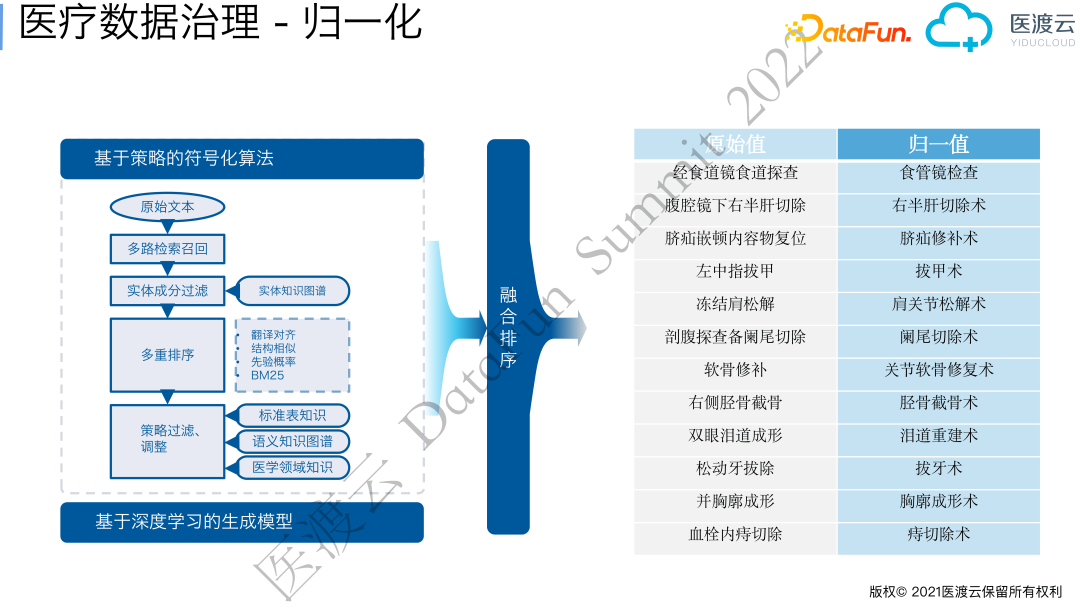
对大型医疗机构的诊断、手术、检查、检验、药品等实体进行标准化的效果非常明显。例如:诊断名称的原始词数量为1458万,经过归一化之后数量为2.36万,下降99.8%。手术和操作原始描述原始词数量为85万,归一化后剩0.54万,下降99.4%。
实体构建好之后,会进行关系抽取(relation extraction)和属性计算(property calculation)。下图是我们将知识图谱经典三元组升级为四元组的过程。三元组部分表达的信息是2型糖尿病相关的症状有多饮,但并非所有患者都会有多饮的症状,那发生的概率有多高,这个信息就会记录在第四元(称为属性元)。除此之外,多饮症状在多少疾病会出现、该条知识是通过多少原始病历观察得到的,这些数据挖掘的信息都会记录在第四元中。图谱与文献中的经典医学知识进行融合时,第四元也会存放关于该三元组的知识限定。
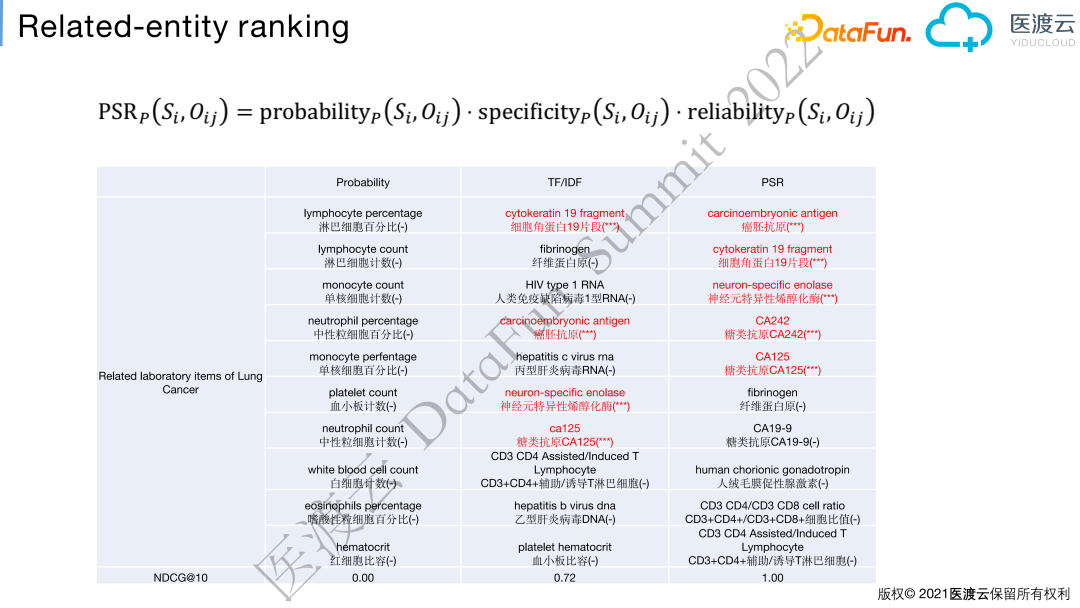
为了更好地发现与疾病的特异性较高的实体,我们提出了实体的特异度(Specificity)指标,例如帕金森相关症状从数据按照概率排序时排名前五症状为:头晕、震颤、失眠、动作缓慢、翻身困难。但是头晕并不是帕金森的典型症状,这是由于帕金森基本发生在老人身上,这样老人常见的失眠、头晕的症状也会被统计出来。因此,我们使用了类似IDF(Inverse Document Frequency)的算法来挖掘疾病真实的典型症状。
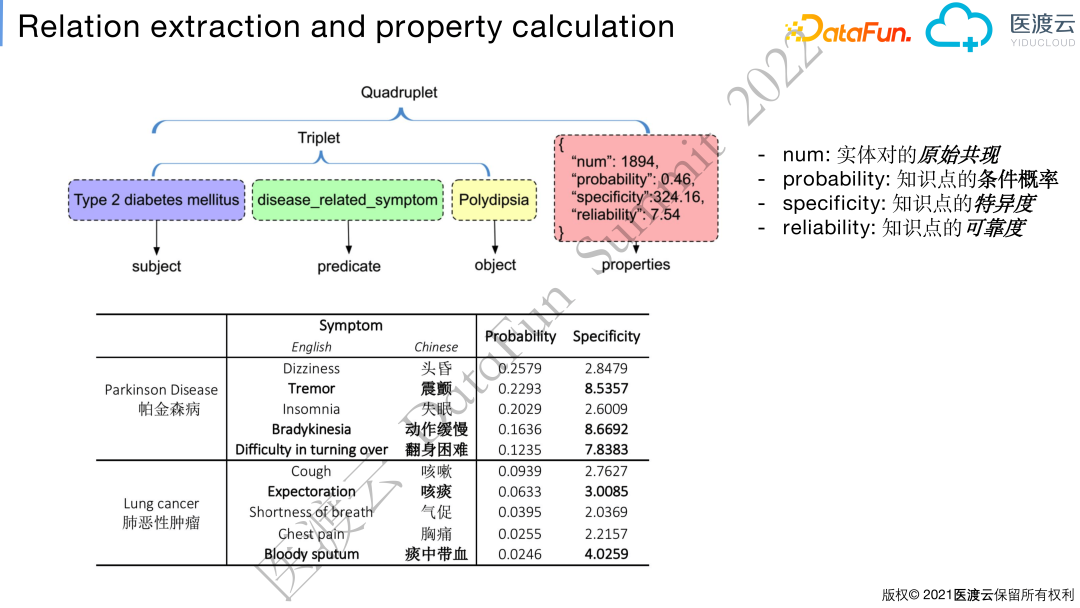
我们将疾病三元组SPO的条件概率(probability)、特异度(specificity)、可靠度(reliability)进行融合,形成PSR指标。该指标可对于给定主语实体(subject)和属性(predicate)的多个对象(object)做排序。比如,挖掘肺癌相关的检验指标,PSR指标可以将肺癌的典型肿瘤标志物排在前面。
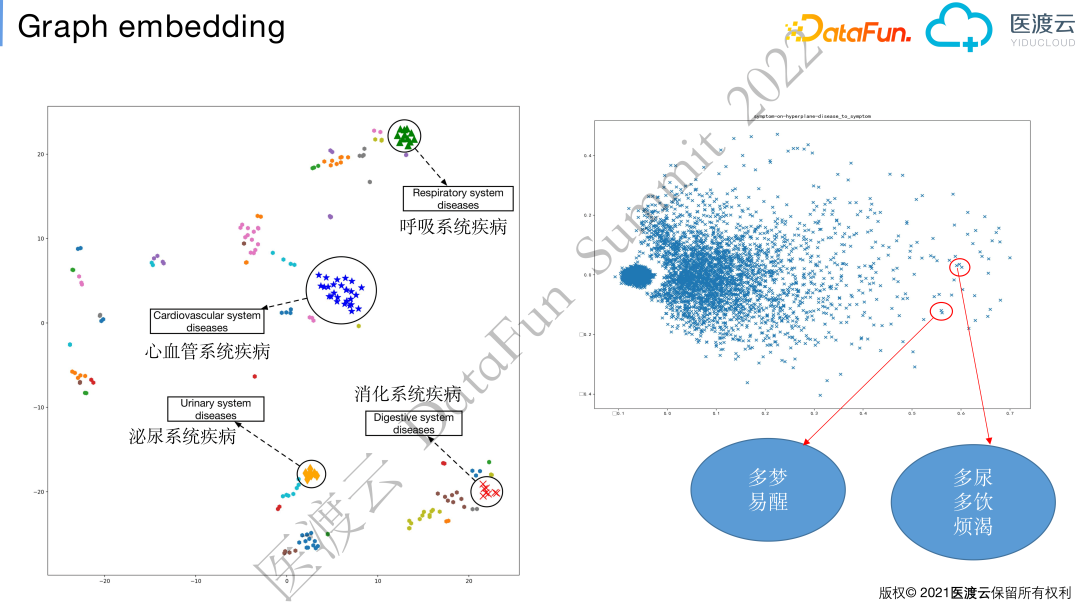
图嵌入的工作,目的是为图谱中的主语实体(subject)、属性(predicate)和对象(object)分别学习到一个向量表示,方便进行语义计算。图嵌入算法的基本原理是求解一个损失函数,使得主语实体和属性的向量求和后与对象的向量表示尽量接近。由于构建的医疗知识图谱是个概率图谱,我们提出了一种优化的图嵌入方法,在原来优化目标的基础上,要求预测的条件概率(probability)也和原始概率尽量一致。实验证明,在所有Trans系列算法的基础上,引入该方法后图谱的预测效果更好。

如图,我们对图嵌入学习到的疾病和症状进行可视化。将不同疾病和症状的向量分别投影到二维空间,会发现同一个系统的疾病会聚集在一起。这和临床认知是一致的,因为同一系统疾病的临床表现、检验结果、用药和手术治疗都有很大的相似度,即它们related entity相似,所以学到的向量也是相似的。
右侧的症状也有类似的效果,像多梦、易醒这两个字面完全不相关的症状,因为经常同时出现在相似的疾病病例中,治疗方式也类似,所以症状的embedding也很相似。
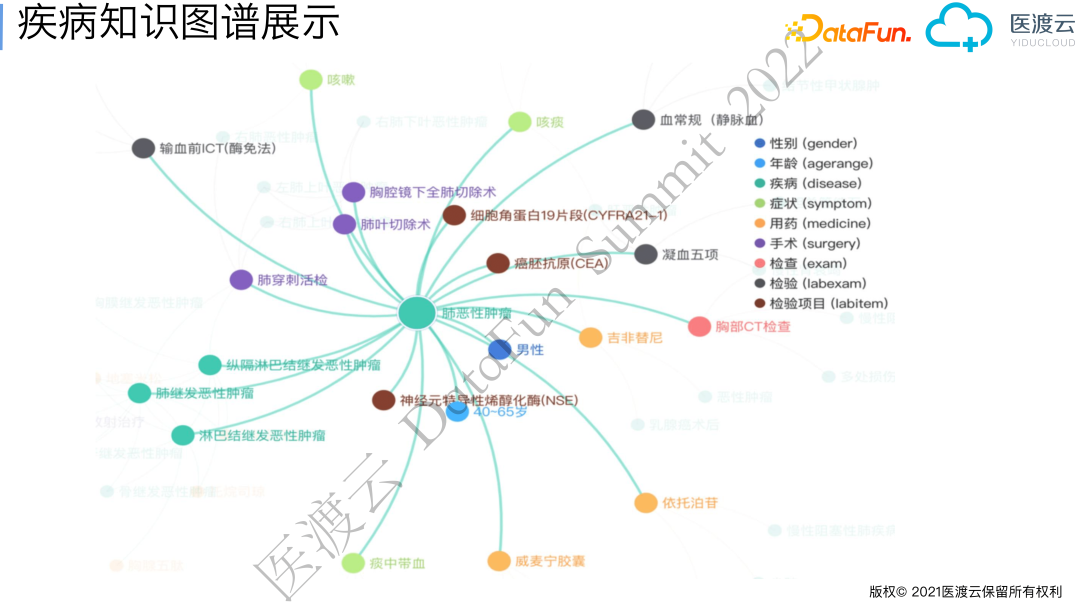
下图是构建的真实世界知识图谱的展示,以疾病为核心,疾病相关的症状、检验、人群都是与实体相连的节点,每条边对应实体之间的关系。鼠标移动到节点上会展示该实体以多大概率、在什么人群发生,移动到边上会展示该关系发生的概率值以及其他属性。
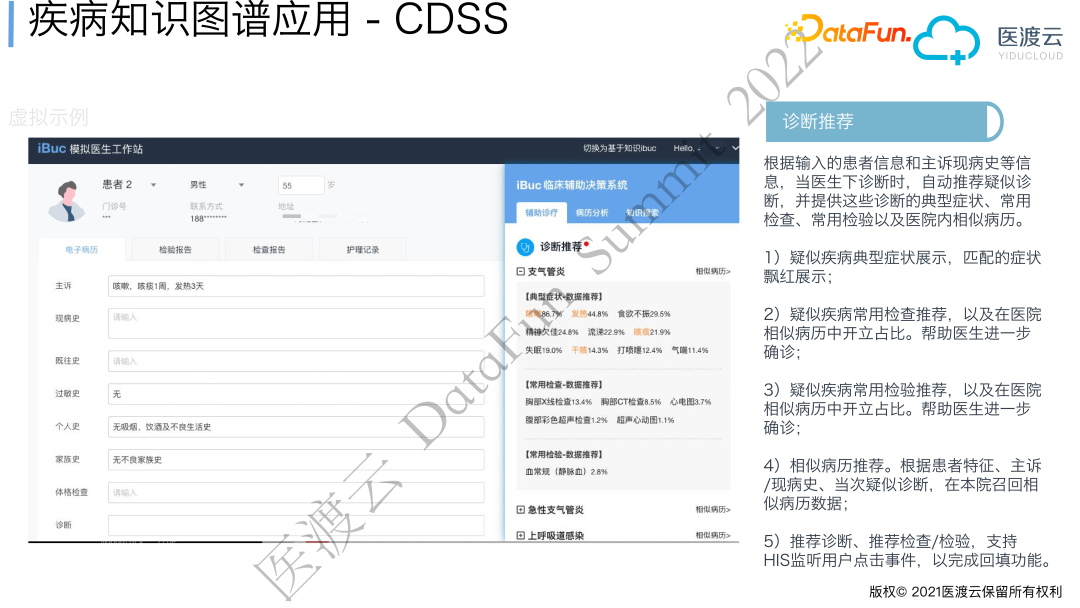
1. 智能诊断
基于疾病概率知识图谱,做疾病智能诊断的应用会更便捷。我们将其应用在临床辅助决策场景中。当患者初次在医院进行就诊时,医生会在病例中写主诉、现病史等信息。通过NLP技术抽取患者主诉和现病史的症状、症状的发病特点,将其输入到改进的贝叶斯模型,推理出目前患者最有可能的疾病列表。当医生选择了诊断之后,系统会基于医生所选的诊断自动推荐检查检验项目,推荐的内容都来自于构建的医疗知识图谱。
2. 信息检索排序
住院期间患者的用药非常多,例如:一个糖尿病患者住院期间会使用数十种药物。在住院期间或者出院后,当医生想要查看患者的主要用药时,传统的做法是从前往后翻阅药物医嘱。基于上述知识图谱,我们使用患者本次的主要诊断查询知识图谱中与其最相关的药物和患者住院期间用药进行匹配,使用PSR指标对药物进行排序。如图可以看到该2型糖尿病患者主要用药是瑞格列奈片、伏格列波糖片、门冬胰岛素注射液。大大节省了医生的时间,提高工作效率。

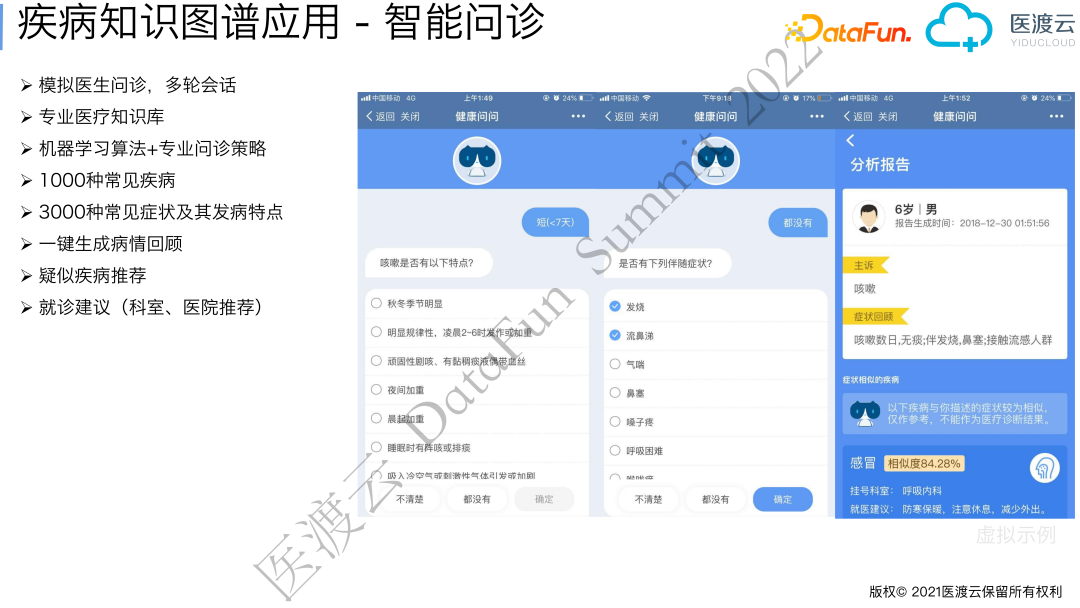
3. 智能问诊
当患者身体不适时,可以通过智能问诊进行症状自查,通过与机器的多轮交互,系统给出最有可能的疾病与建议就诊科室。相对于前述的临床辅助决策系统,智能问诊加入了医生问诊的逻辑。比如患者症状为咳嗽,系统会模拟医生问诊思路,先询问咳嗽的特点,即:是否咳痰,咳嗽多长时间,之后基于可能的几种疾病收集更多的信息进行确认或排除,如致病因素、检查检验结果等。基于构建的疾病概率知识图谱,系统可以生成最有用的候选题目与答案选项。
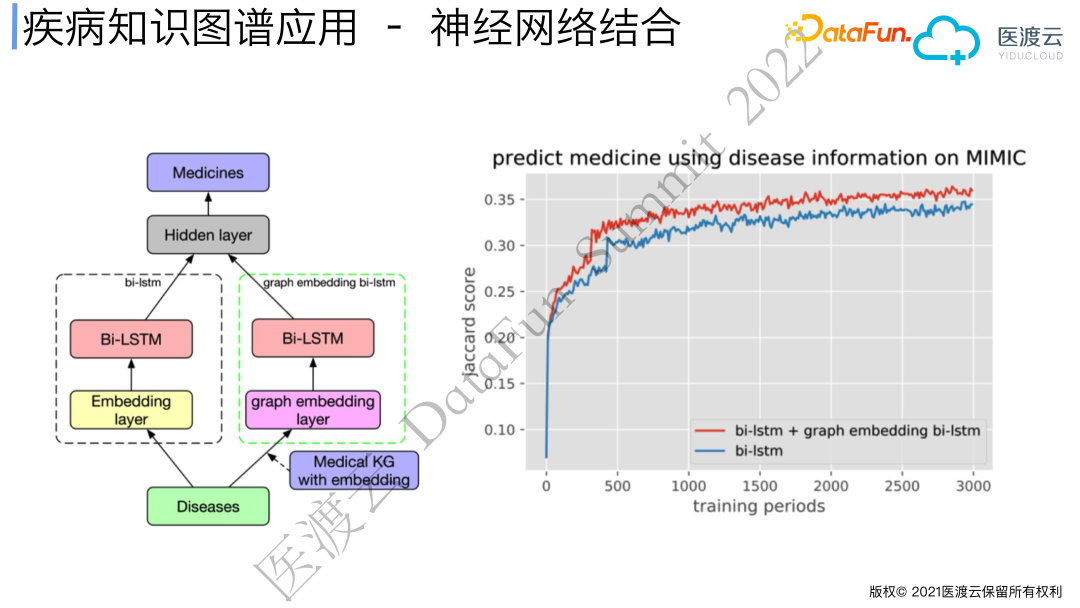
4. 神经网络结合
医学信息学领域经常会基于公开数据库MIMIC进行患者下一步用药的预测,由于是ICU的时序数据,以Bi-LSTM为基本模型的深度学习算法取得了不错的效果。我们在Bi-LSTM模型的基础上加入了graph embedding层,预测患者下一步用药,实验结果显示模型的收敛速度和准确度都有提高。这说明graph embedding和深度学习联合场景对模型优化很有帮助。然而,基于向量表示的预测模型因其解释性较差,在药物推荐等严肃医疗场景下还是经常被挑战,比较适合应用于医疗文本NLP及智能导诊等场景。
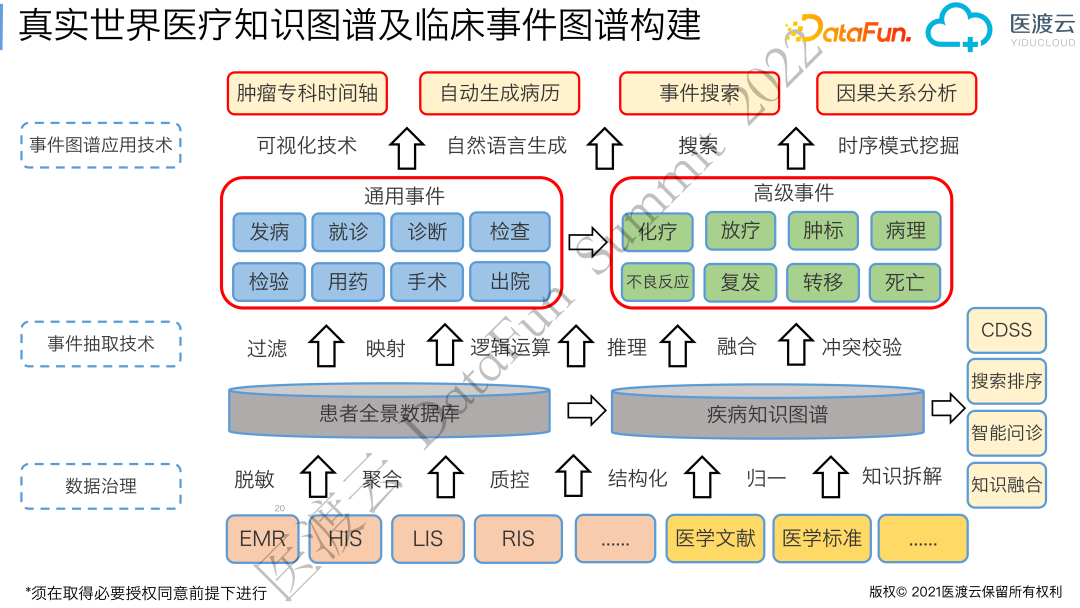
02 临床事件图谱构建
患者的发病及诊疗过程由一系列的事件组成,如:发病、就诊、诊断、检查、用药以及手术、死亡等,这些是适用于全部疾病的通用临床事件。除了通用临床事件,专科医生对某些疾病的特定事件关注比较多,比如对于肿瘤患者,会有化疗、放疗、肿瘤标记物检测、病理报告、复发、转移等事件。基于疾病通用临床事件和专科高级事件,可以构建面向临床诊疗过程的应用,如:肿瘤专科时间轴、自动生成病历、事件搜索、因果关系分析等。
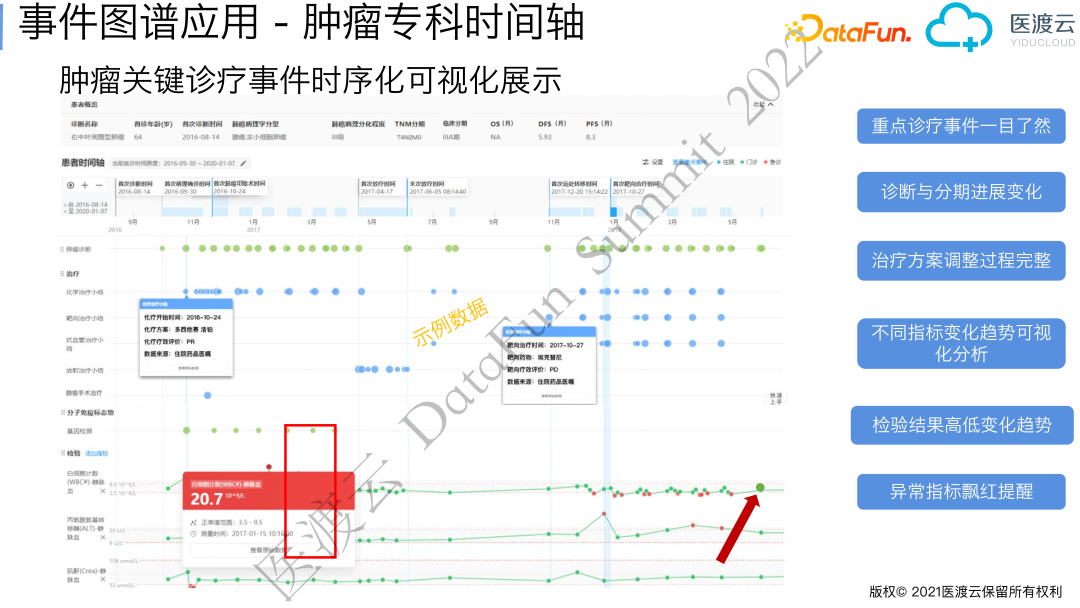
1. 肿瘤专科视图
接下来通过肿瘤专科时间轴介绍一下事件图谱的应用。
从下图的时间轴中可以看到该患者于64岁确诊为右中叶周围型肺癌,首次诊断时间为2016年8月14日。沿着时间线可以看到患者先后进行了化疗、手术切除以及放射治疗,在治疗过程中可以通过检验指标趋势和影像轴观察其病情的变化。患者于2017.12月发生远处转移再次来医院就医,医生采用了化疗+靶向治疗+抗血管治疗的治疗方案。基于临床诊疗事件构建的肿瘤专科时间轴,可以将患者从发病到死亡或者末次就诊之间的重点诊疗事件及病情发展进行展示,方便医生快速了解和分析患者病情,准确做出下一步临床决策。
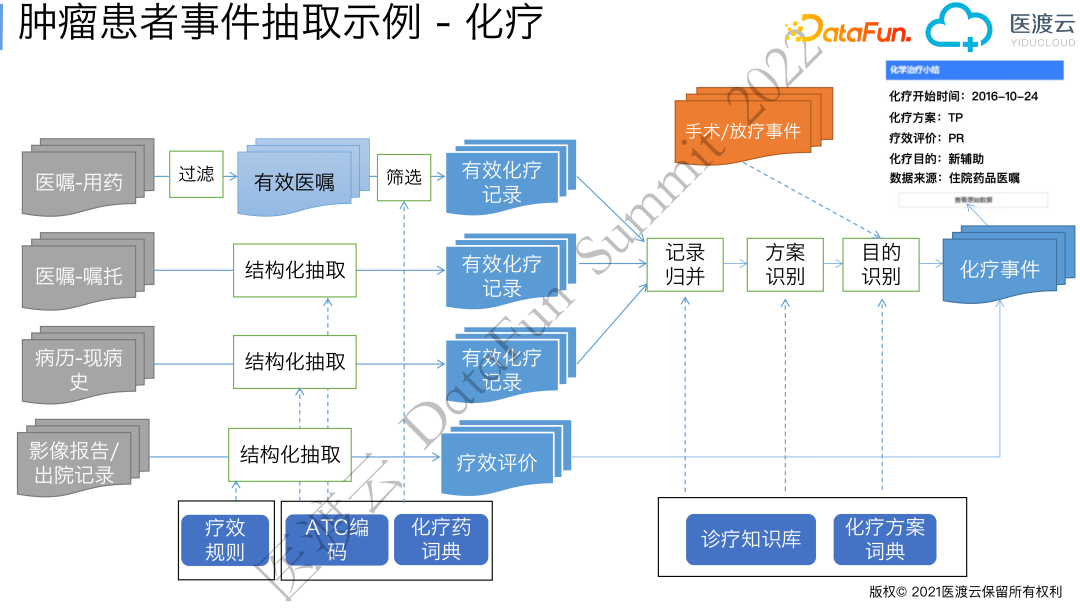
接下来,我们以上述时间轴中提到的化疗事件为例阐述高级事件抽取过程,化疗事件包括化疗开始时间、化疗方案、化疗目的、疗效评价等。
化疗方案
化疗方案是若干个化疗药品的组合。最开始我们通过对药品进行ATC分类,过滤出ATC分类为化疗的药品,组合起来形成化疗方案。在应用过程中发现,有很多新上市的化疗药未被识别,原因是ATC编码是每年更新的,很多新药未纳入ATC编码中。因此,我们在ATC编码的基础上补充了最新的化疗药品词典。此外,还有一些患者自带药或者赠药,这些药物的使用会记录在嘱托医嘱的文本中,需要从嘱托医嘱中进行结构化抽取。我们还发现,很多患者在大医院手术后会回到当地的医院进行化疗,这些用药信息就需要从现病史中进行结构化抽取,或者随访信息中补充。通过不断的查漏补缺,对几个来源的数据进行合并,得到最终化疗药物组合,推导出患者的化疗方案名称。
化疗目的
一般情况下,肿瘤治疗以手术切除为主。但一些患者不适合直接手术,会采用先化疗缩小肿瘤再手术的方式,这种化疗的目的称为新辅助化疗。手术后为了清除残留的病灶而进行的化疗称为辅助化疗。通过计算机实现这些医学逻辑,最终确定化疗目的。
疗效评价
疗效评价是用来表示患者经过治疗后病情的变化,如:完全缓解(CR)、部分缓解(PR)、疾病稳定(SD)及疾病进展(PD)等。我们可以从出院记录中抽取到这个信息,但有时候医生没有写或者写的很模糊,这时就需要先抽取影像学中靶病灶的大小,然后根据病灶大小的变化来计算疗效。
上述事件抽取过程中最重要的技术是医学文本结构化抽取技术和基于医学知识的逻辑推理。
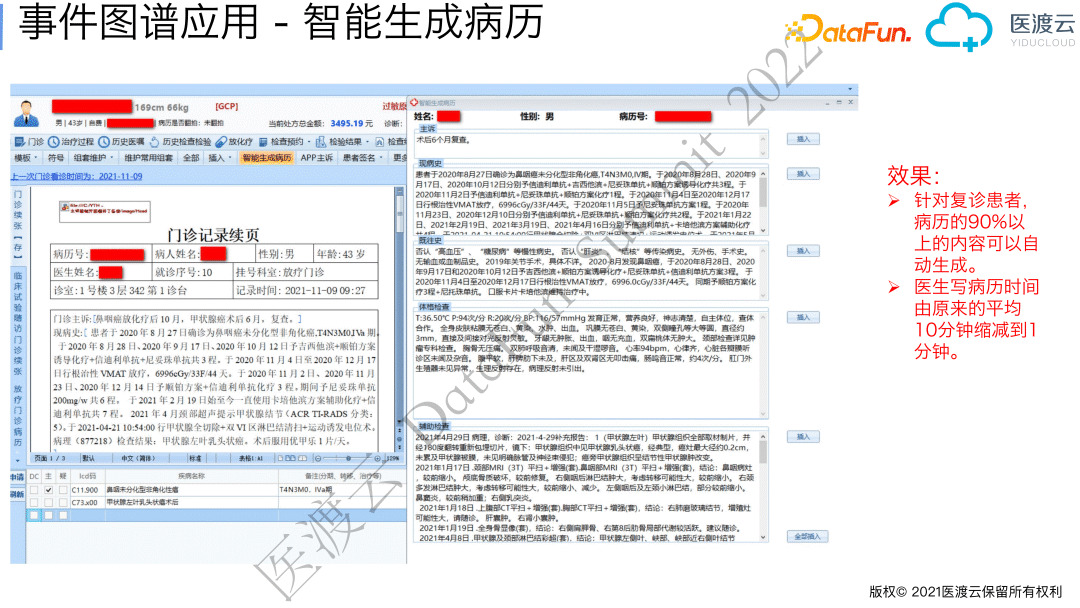
2. 智能病历生成
前面主要讲的是把很多非结构化的内容变成结构化的数据,即:将人能看懂的内容转化为机器能看懂的内容,这个过程叫自然语言理解(NLU , Natural Language Understanding)。接下来我们介绍一个将机器能看懂的内容自动转换为人能看懂的内容·,这个过程叫自然语言生成(NLG , Natural Language Generation)。
医生在临床工作中经常需要撰写大量电子病历,比如:肿瘤患者每次就诊时需要将患者之前的诊疗概况写到病历系统中,便于后续的使用和防范医疗纠纷。我们基于患者诊疗事件图谱,通过NLG技术将临床事件转换为规范化的病历描述,达到自动生成病历的目的。
当医生点击“智能生成病历”按钮时,系统自动从后台抽取出患者的诊疗事件,并进行事件的聚合、选择、排序后套入病历模版自动生成病历。目前针对复诊患者,90%以上的病历内容可以自动生成。医生写病历的时间由原来的10分钟压缩到1分钟,让医生从繁重的病历书写中解放出来。
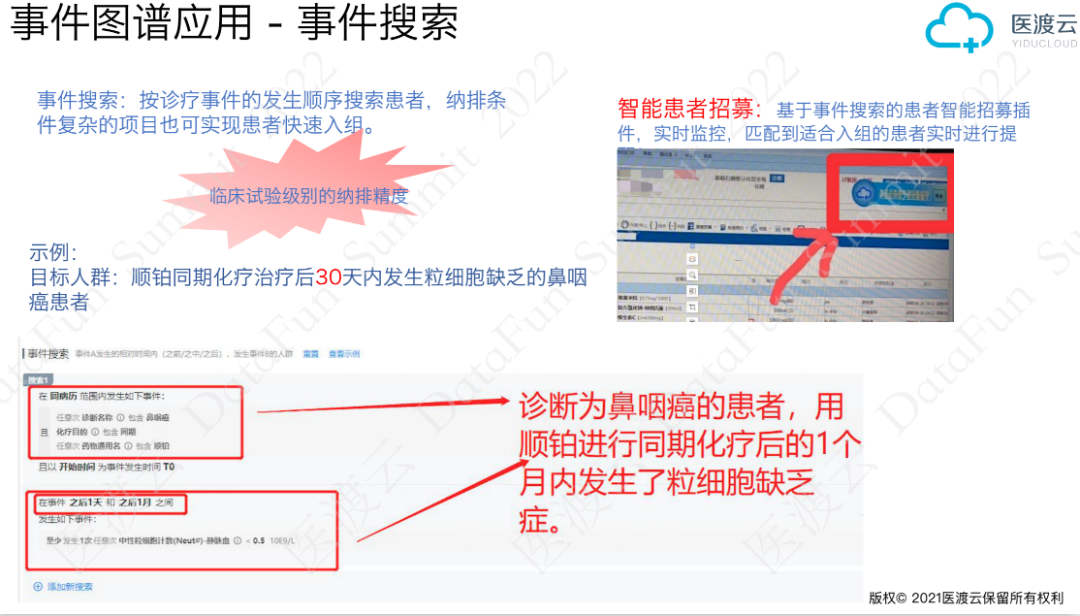
3. 事件搜索
新药上市前需要招募患者进行临床试验,准确高效地招募到符合条件的费时费力。基于临床事件图谱的病例搜索可以精确定位满足条件的患者,快速完成患者入组。例如,某药需要招募经过顺铂同期化疗治疗后30天内发生粒细胞缺乏的鼻咽癌患者,左下图是我们将纳排条件转化为事件搜索的可视化的展示。进一步,将患者事件搜索功能嵌入到医生日常工作的流程中,实现了患者智能招募。
(1)当有临床试验要开展时,输入患者招募条件后可以在历史患者中搜索,给满足招募条件的患者推送临床招募的信息。临床试验是免费的,对目前没有有效治疗方式的患者来讲是很有价值的。
(2)新患者就诊时,如果系统发现该患者与临床试验入组条件相匹配,会提醒医生该患者符合临床试验的入组条件,进而提高患者招募的效率。
03 精彩问答
Q1:使用贝叶斯模型预测的出发点是什么?是为了提升模型的可解释性吗?
A1:是为了提升模型可解释性。即使诊断因素之间并非独立,贝叶斯模型仍然具有不错的效果。也尝试使用包括深度学习在内的其他方法,准确性略好,但可解释性差一些。
Q2:有些医疗文献中出现“发病概率70%”的概率数据,这部分是怎么处理的?
A2:医渡云主要处理的是医院的原始病历数据,70%的发病概率是从这些医疗文本中统计出来的。医疗文献中有时也会写某疾病的发病概率是70%,这是一个关于疾病的知识,它可能是基于某段时间、某个区域的调查得到的结果。这部分的结论可能没有我们基于真实数据值计算得到的概率准确,但我们的结论也可能会出现某家医院特色疾病科室或发病人群分布偏移带来一些偏差。将全国的数据整体进行计算理论上最准确,但是目前数据都还是保存在各自医疗机构内部,实现起来比较困难。我们是基于特定医院或者区域数据进行分析,在该医院或者该区域做推荐,还是可行的。
Q3:基于书本抽取的知识来自哪些书本?如何保证这些知识是最新的知识?
A3:一般会用人民卫生出版社的内外科和专科书籍、临床指南及论文等参考资料。我们会将病历中挖取的知识和以上3个来源的数据做合并,在某些场景下如果某个关系只在挖掘数据中存在但没有文献支撑时,我们会将其删掉。
Q4:今天分享的疾病知识图谱和事件图谱的工作,有公开的代码吗?
A4:疾病知识图谱有一篇文献《Real-world data medical knowledge graph : construction and applications》。事件图谱的工作目前还没对外发表。
Q5:怎么确定大数据的数据源是可靠数据?
A5:目前确实无法保证。目前有两种思路:
如果是比较严肃的场景,我们会和书本的内容进行融合,基于书本构建图谱的骨架,基于数据补充统计信息。
如果是数据挖掘场景,如:看哪些检验指标对疾病诊断有帮助,可能从数据中可以挖掘新的指标出来;还有分析疾病发病的危险因素或者保护因素时,我们会更愿意相信数据中得到的洞察。
Q6:数据不能如愿的情况下,如何很好地进行模型迭代?
A6:不同场景下的做法不一样。医渡云有纯数据驱动、纯知识驱动模型以及数据和知识融合的模型。我们目前和医院的合作形式是在医院授权的前提下,登录到医院的服务器中进行数据的处理和模型训练。
Q7:医疗事件图谱构建是否有行业标准?
A7:据我所知目前暂无。
Q8:不考虑模型可解释性,哪个模型的疾病预测准确率更高?
A8:与具体问题相关,在我们的经验中,大部分疾病诊断和风险预测问题,在知识指导下选取变量,进行数据驱动的机器学习模型效果更好一些。数据量大的情况下,深度学习模型效果更好些。而在疾病治疗方案推荐方面,知识和数据融合的模型准确率更高,哪怕是简单的规则+逻辑回归,也可能会比神经网络效果要好。这是因为在疾病治疗时,医生往往就是基于知识(理性)和经验(感性)综合判断。
Q9:可以计算疾病实体到症状的概率吗?
A9:可以。
Q10:基于图谱路径、专家规则、机器学习的疾病预测模型,目前哪个更准确?
A10:针对疾病的诊断,如:基层医院来了个患者,想根据症状知道患了哪种疾病。这个往往需要从几千个疾病中筛选,此时使用知识图谱的概率推理就更适合。前两年也有团队使用逻辑回归来进行预测,也取得了不错的效果。
针对单病种的风险预测,如:什么样的患者容易发生哪种疾病、发生某种疾病的人治疗后的效果预测,这类问题基于数据构建机器学习模型比较适合。
治疗方案选择基于专家规则会更主流。纯基于数据学习的知识,医生通常是不敢相信的。治疗方面通常都是根据临床指南和最新文献决定。临床指南是定期更新的手册,将其计算机化就可以得到专家规则。另外,在专家规则的基础上数据做补充的融合模型,目前看效果也不错。
还有一种思路是类似IBM的沃森,自动抓取海量的文献,对文献打各个维度的标签,包括:文献的研究对象是什么人群,研究的疾病、干预方式、治疗效果如何等。之后,将这些标签信息进行融合,确定最适合患者的治疗方案,推荐给医生。
Q11:医疗知识图谱schema的设计有规范吗?
A11:据我所知,中文医疗知识图谱的标准比较少,一些机构有标准,但目前还没广泛的应用。
Q12:DRG是否会对医疗知识图谱带来挑战?
A12:DRG的目的是按病种付费,应该不会对知识图谱带来太大挑战。
Q13:NLP在医疗领域目前最大的困难和挑战是什么?
A13:NLP的挑战有几方面:
(1)缺乏临床实用、完备的中文术语标准;
(2)缺乏大量高质量的标注数据;
(3)算法不能很好地解决实体嵌套、可解释性差和快速修复等问题;
(4)理解医疗文本需要大量的医学专业知识,应用对于错误容忍度低等。
针对这些问题,我们一直在与政府部门、高校、学协会及其他企业一起努力。比如与山西医科大学研究院的老师一起将少量脱敏后的电子病历拿出来,由医生进行标注后,通过中国中文信息学会在CHIP、CCKS等会议上发布并举办评测比赛,共同推动行业技术进步。
今天的分享就到这里,谢谢大家。
01/分享嘉宾
李林峰 博士
医渡云
技术创新副总裁
李林峰,博士,医渡云技术创新副总裁、AI架构师。2017年加入医渡云,研究方向为医疗大数据挖掘技术及和人工智能创新应用,包括医学知识图谱构建,医学知识表示及推理方法,预测模型,以及基于AI技术的临床决策支持系统等。拥有多项医疗人工智能领域专利及论文。曾任百度医疗算法负责人,负责知识图谱构建、智能问诊及百度医学的算法工作。
声明:本文来自DataFunTalk,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
