文 / 深圳证券交易所 许保勋
近年来,迅速发展的大数据、云计算、移动互联技术受到了社会各方的重视。以大数据为支撑的互联网与各领域的深入融合发展具有广阔前景和无限潜力,已成为不可阻挡的时代潮流,将对我国经济社会发展产生着战略性和全局性的深远影响。
基于各类文本等非结构化、结构化数据进行决策将变成各行各业的主要信息应用模式,大数据及其处理技术将成为企业的核心价值和技术领先标志。金融市场尤其是资本市场表现得更为明显。首先,资本市场信息流的主体是文本信息,“互联网+”背景下的文本信息量及传播模式对监管工作形成的挑战凸显,证券价格受信息驱动的影响更为明显,只有在对信息流的运作有相当程度理解的基础上,才能实现风险管理、政策模拟、市场效应等深层次的监管和服务。其次,目前不管是市场主体还是监管当局,近年来,随着大数据和互联网的快速发展,各类网络信息大量聚集并迅速传播,对证券价格的影响程度和频繁度越来越大,尤其是在2015年股市的异常波动中表现得更为明显,对监管工作形成严峻的挑战。面对信息驱动模式下经济、金融风险监测工作的严峻形势。如何对非结构化的文本信息进行分析并用于监管已经成为监管当局必须解决的问题和技术攻关项目。
促进科技监管,加强智能应用
基于文本挖掘技术的证券智能监管项目以推进监管转型、提升服务质量为总体目标,紧紧把握大数据时代下证券市场监察、上市公司监管、网络舆情监控的信息服务需要,侧重于对信息的快速加工、精准反应应用。项目以“文本信息数据库”为基础构建架构,结合监管转型业务需要,推进完成“抢帽子交易操纵网络信息监测系统”“信息披露直通车公告类别整合系统”和“智能资讯服务系统”等创新应用项目。项目正式启动以来,三个创新应用项目有效地提升了大数据市场监察水平和上市公司信息披露智能化水平,在证券监管系统内形成了良好的示范效应,促进系统内文本挖掘智能监管平台的建设。
“文本信息数据库”的目标是打造企业级市场资讯存储和服务平台。构建统一的信息搜集、加工处理和分析、信息服务、评价反馈于一体的资讯管理信息化智能服务平台,通过整合信息搜集渠道和改进信息收集效率,提高对重要信息采集处理的及时性和有效性,实现对多种类型信息源的采集、分类和存储,建立共享性好、安全性好、可扩展的信息资源库。
“文本信息数据库”为市场异常波动期间交易所监控市场风险、分析市场信息传播情况提供了有效的数据支持。在市场异常波动之前,基于项目成果每日快速把握市场热点、公司公告、分析师研报、大V言论、网络舆情等情况,深入分析市场特别是创业板的快速大幅上涨情况,以及各种可能的风险因素。市场异常波动期间,结合微信、微博等新媒体信息传播特点,挖掘引起市场恐慌负面信息线索,为管理层制定救市对策提供了有效的数据支持。
“抢帽子交易操纵”是指证券公司、咨询机构、专业中介机构及其工作人员,买卖或持有相关证券,并对该证券或其发行人、上市公司公开做出评价、预测或者投资建议,以便通过期待的市场波动取得经济利益的行为。“抢帽子交易操纵网络信息监测系统”旨在利用文本挖掘技术进行证券市场监控的尝试,通过对文本挖掘技术(包括证券行业领域知识库的构建、财经类文本特征的筛选、文本分类算法的构建、文本信息抽取方法)研究,构建包含文本信息和市场数据信息的综合市场监控模型,逐步探索积累文本挖掘在金融证券领域的应用经验,为防范和打击证券违法犯罪行为起到重要作用。通过“抢帽子交易操纵网络信息监测系统”推送的荐股信息,同时结合账户交易数据,开展了大量抢帽子交易异常账户识别工作,有效打击了投资者在荐股前买入荐股后卖出、买入推荐股票比重大、买入推荐股票放量等各种异常交易行为,有效遏制了市场操纵等违法违规行为。
“信息披露直通车公告类别整合系统”采用历史公告文本数据构建了公告“自动标注机”过滤获取公告类别训练数据文件,采用改进后的机器学习方法(层次分类算法)构建公告文本分类器(如重大资产重组、股东大会等类别公告)。各类公告分类器测试样本召回率达99%以上,有效地排除了多起上市公司直通披露错误类别标注风险,杜绝了类别标注错误可能造成的巨大社会影响,对交易所公司监管提供了有力支持。
“智能资讯服务系统”以网络新闻、电子报、股吧、博客、微信、微博、互动易、券商研究报告和上市公司公告为收集对象,按照公司监管、市场监察、市场分析、舆情监测的业务需求对相应的文本数据进行分类标识、热度分析和情感分析,帮助监管员事前提示监控重点、事中进行快速监控分析,事后进行违规深度分析,有效提升交易所一线监管效率,全面提高交易所风险监测和预研预判的科技监管能力。
技术创新,从更迭中找突破口
敢做第一个吃螃蟹的人。大数据时代下,证券监管工作中需要处理大量非结构化信息,目前主要以人工处理为主,经常面临监管广度不足、深度不足、效率低下等问题。基于文本挖掘的证券智能监管项目为在证券监管系统内较早引入文本挖掘大数据技术,实现了证券市场交易监察、上市公司监管、信息披露、舆情监控等的智能化处理,拓宽了传统的基于结构化和市场数据的市场监管模式,为我国证券监管提供了全新的市场监管模式,标志着证券监管全面进入大数据时代。
行业自然语言处理技术需要突破。中文自然语言处理技术是中文文本挖掘的难点,中文的复杂是从分词就开始的,断句和语调不同意思会完全不同。海外没有相关经验可借鉴,国内也没有相关的针对证券行业的现成技术,以致文本信息分类、关键信息提取等信息加工处理也无法做好。基于文本挖掘的证券智能监管项目在自然语言处理技术方面有三个突破:一是较早构建了中文较完备的证券金融领域专业词库;二是自主研发“词汇区分度”和“覆盖面”抽取特征指标算法,构建出高质量的荐股特征关键词库;三是结合证券类文本行文特点,构建出具有层次的文本分类算法和非结构化信息抽取策略。上述三个突破融合语言学、金融学、统计学、计算机技术等交叉学科,创造性地实现自然语言处理的突破,并具有良好的通用性,成功地将文本信息等大数据技术应用于市场监管领域。
创造性地利用文本挖掘技术打击证券违法行为。通过抢帽子交易操纵网络信息监测系统、信息披露直通车公告类别整合系统、智能资讯服务系统等文本挖掘应用,一是创造性地从海量网络信息中挖掘对股价有重要影响的信息,提升本单位对股价异动事前预警的自动化水平;二是对信息操纵类案件,利用文本分析和信息抽取在网络上进行违规行为证据的收集;三是结合网络信息挖掘结果与成交量、股价、波动率等市场交易数据,为违规可疑案件进行筛选,能有效提高监管系统预警效率;四是实现了信息披露中信息类别的自动化识别与纠正,降低了市场操作风险,提高了市场监管水平。
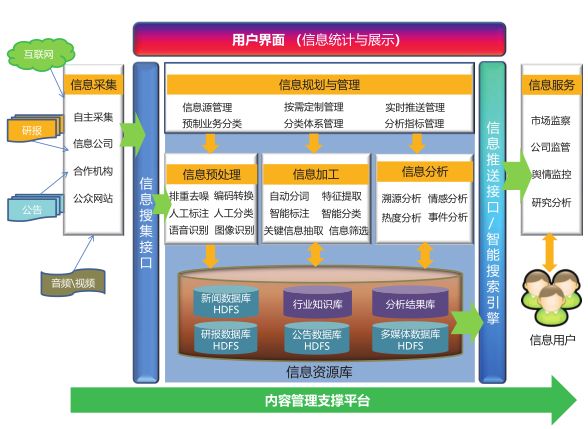
图 文本信息数据库技术架构和运用规划
行业内率先构建了统一的文本信息数据库基于证券监管机构的视角,利用交易所在数据资源的优势以及在证券领域的专业地位,率先构建了集信息搜集、加工处理、智能分析、信息服务于一体的文本信息数据库平台,促进了监管转型,降低了监管成本,全面提高监管工作的智能化水平。
声明:本文来自金融电子化,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
