选自arXiv
作者:Peng Sun、Xinghai Sun、Lei Han、Jiechao Xiong、Qing Wang、Bo Li、Yang Zheng、Ji Liu、Yongsheng Liu、Han Liu、Tong Zhang
机器之心编译
OpenAI 一直致力于用深度强化学习战胜《Dota 2》的人类玩家,目前 OpenAI Five 勉强达到了职业玩家水准。而由于游戏主体数量更多(几十到数百)、观察空间以及动作空间巨大,《星际争霸 II》的游戏难度实际上比 Dota 2(5 个游戏主体)更高,目前 AI 仅在「星际争霸 II 学习环境」的多个小游戏上达到专业水平。近日,腾讯 AI Lab 等利用深度强化学习开发出了能在《星际争霸 II》全场游戏中打败「开挂」内置 AI 的智能体(深海暗礁地图,虫族 1 对 1),这个「开挂」AI 的能力相当于暴雪战网(Battle.net)天梯排名系统中前 30% - 50% 的人类玩家。
最近,深度学习与强化学习的结合为许多棘手问题的决策系统带来了重大突破。深度强化学习从头开始训练(或从预训练的模型开始训练),馈入的(几乎)都是原始的观察特征,在一大批应用中表现出了令人惊艳的性能,包括玩围棋游戏 [6, 7]、玩电子游戏(如 Atari [8]、第一人称射击游戏 Doom/ViZDoom [9, 10] 或 Quake/DeepmindLab [11]、Dota 2 [12])、机器人视觉运动控制 [13] 及机器人巡航 [14, 15] 等。学到的策略/控制器运行效果出人意料,有时甚至超越人类 [8, 7]。
然而,《星际争霸 II》,这一被公认为最具挑战性的 RTS 游戏还一直没有被 AI 攻克。在这款游戏中,人类玩家必须控制数十至数百个单位(unit)来实现各种目的,如收集两种资源、扩展额外资源、更新技术、组建其它单位、派遣队伍进行攻击或防御、对战斗中的每个单位实施微观管理等。这是《星际争霸 II》比 Dota 2 难的关键原因之一,后者的单位总数要控制在 5 个以内(分别由 5 个玩家控制)。图 1 是人类玩家互动的截图。对手对玩家隐藏,除非对手的单位出现在玩家的视野范围内。因此,玩家需要派遣单位侦察对手的策略。所有决策都要实时做出。在设计 AI 智能体方面,《星际争霸 II》包含很大的观察空间、巨大的动作空间、局部观察、多玩家同时游戏、长期决策等。所有这些因素都增加了《星际争霸 II》的难度。为了扩展 AI 能力的边界,Deepmind 和 Blizzard 联合推出了「星际争霸 II 学习环境」(StarCraft II Learning Environment,SC2LE)[16]。Deepmind 的近期研究成果 [16, 17] 显示其 AI 智能体能够在多个小游戏中达到职业选手的水平,但要在全场游戏上达到专业水平还有很长的路要走。
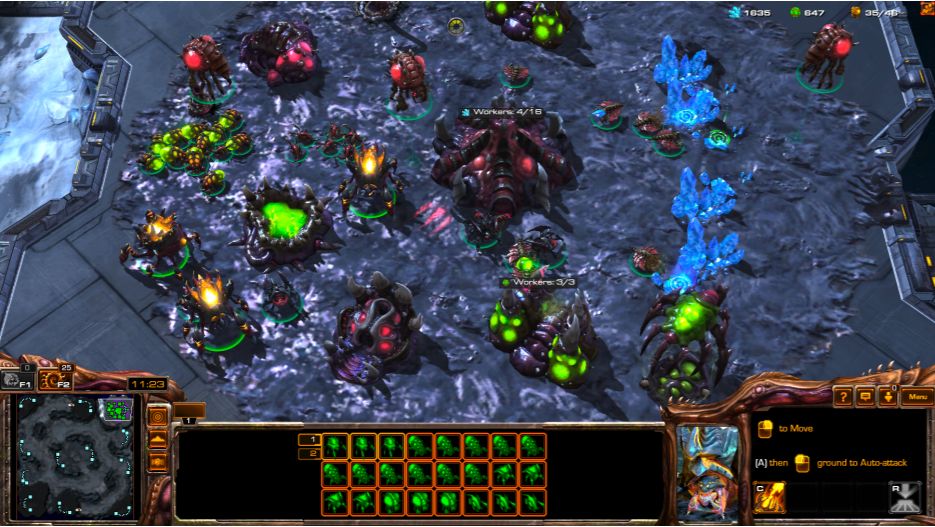
图 1:《星际争霸 II》游戏中人类玩家操控单位的截图。
为了在全场游戏中开展研究,本文作者将研究限制在以下环境中:深海暗礁地图上的 1 对 1,虫族对虫族。他们开发了两个 AI 智能体——智能体 TStarBot1 基于平面动作(flat action)的深度强化学习,智能体 TStarBot2 基于分层动作(hierarchical action)的规则控制器。TStarBot1 和 TStarBot2 都能够在全场游戏中击败水平从 1 级到 10 级的内置 AI 智能体。注意,8、9、10 级内置 AI 都作弊了:8 级拥有对整个地图的完整视角;9 级的资源收获增加,而 10 级则前两者都有。另外,根据《星际争霸 II》论坛里的一些非正式讨论,10 级内置 AI 智能体被估计为白金级至钻石级 [1],相当于暴雪战网(Battle.net)Leagues 排名系统中排名前 30% - 50% 的人类玩家。
具体而言,TStarBot1 基于「平面」动作建模,它会展平动作结构并生成一系列离散的动作。通过这种方式,TStarBot1 能马上为任何现成的 RL 算法做好准备,并将离散动作作为输入。TStarBot2 基于「深度」动作建模,这令我们可以手动指定动作的层级。「深度」建模直观上更好地捕捉了动作依赖关系,并具有倍增的表达能力。然而,由于复杂的分层 RL 可能会参与其中,训练将更具挑战性。请注意这种权衡,在这项初步研究中,研究者为 TStarBot2 采用了基于规则的控制器。
论文:TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game

论文链接:https://arxiv.org/pdf/1809.07193.pdf
摘要:《星际争霸 II》(SCII)被公认为是目前最具挑战性的即时战略(RTS)游戏,因为它具有很大的观察空间、巨大的(连续和无限)动作空间、局部观察、多玩家同时游戏模式、长期决策等。为了扩展 AI 的能力边界,DeepMind 和暴雪联合推出了「星际争霸 II 学习环境」(SC2LE)——一个设计复杂决策系统的测试平台。SC2LE 提供了一些小型游戏,如 MoveToBeacon、CollectMineralShards、DefeatRoaches。虽然在这些游戏中,一些 AI 智能体达到了专业玩家的水平,但它们离在全场游戏中达到专业水平还有很远的距离。为了启动全场游戏中的调研,我们开发了两个 AI 智能体:智能体 TStarBot1 基于平面动作结构上的深度强化学习;智能体 TStarBot2 基于分层动作结构上的规则控制器。TStarBot1 和 TStarBot2 都能在全场游戏中击败水平 1 到 10 级的内置 AI 智能体(在深海暗礁地图里,虫族 1 对 1),注意在全场游戏中,8、9、10 级的智能体作弊了:8 级拥有对整个地图的完整视角;9 级的资源收获增加,而 10 级则前两者都有。具体来说,TStarBot1 采用一组平面宏观动作,在这些动作上,单个控制器通过强化学习进行训练;TStarBot2 采用分级组织的宏微观混合动作,并依赖硬编码专家规则的控制器。
据我们所知,这是第一次公开调查能够在《星际争霸 II》全场游戏中击败内置 AI 的智能体。代码将开源 [3]。我们希望本研究提出的框架在这些方面有益于未来的研究:1)成为混合系统的基线,在该系统中越来越多的学习模块将逐渐被采用,规则仍然被用来表达难以学习的逻辑;2)生成用于模仿学习的轨迹;3)成为自我对抗(self-play)训练的对手。
TStarBot1:基于宏观动作的强化学习智能体
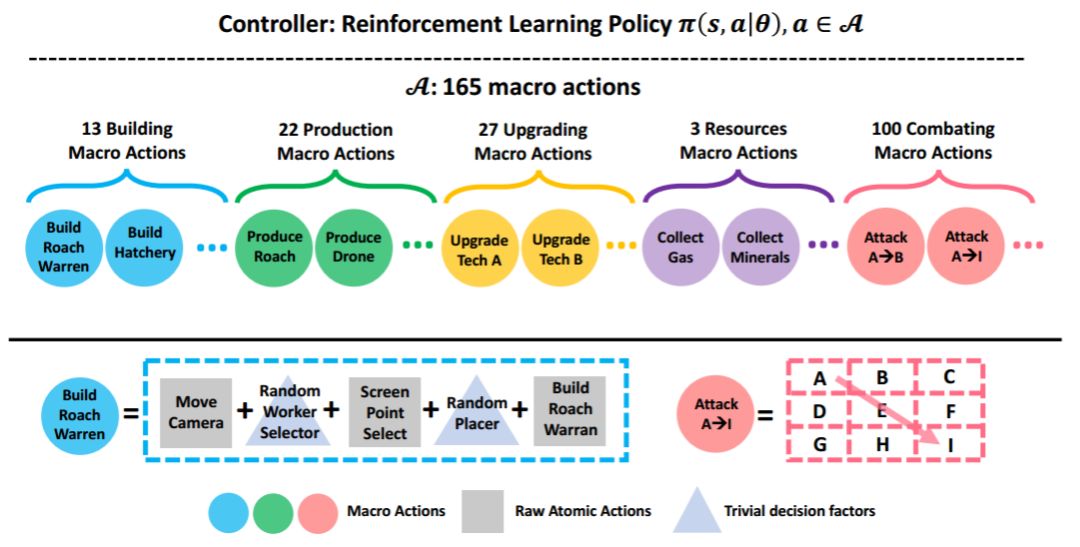
图 2:基于宏观动作和强化学习的智能体架构概览。
如图 2 所示,顶部:基于宏观动作的可学习控制器;底部:165 个可执行宏观动作,硬编码了游戏规则的先验知识(例如,技能树),并对控制器隐藏了琐碎的决定因素(例如,构建布局)和一些执行细节。图中还展示了两个宏观动作的定义作为示例:BuildRoachWarren 和 ZoneAAttackZoneI。

表 1:165 个宏观动作的总结:分类、示例和硬编码规则/知识。在最右列,RandUnit 表示随机选择一个主体单元; RandPlacer 表示随机选择一个有效的放置坐标。
TStarBot2:一个基于分层宏观-微观行动的智能体
基于宏观动作的智能体 TStarBot1 可能存在局限。尽管宏观动作可以按功能分组,单个控制器必须基于整个动作集合来工作,其中这些动作在每个决策步骤是互相排斥的。此外,当预测采取哪个策略时,共同观察(对于动作组是不可知的)被馈送给控制器。这给控制器训练带来了不必要的困难,因为不想要的信息可能会影响观察和动作。另一方面,宏观动作本身并不对微观动作(即,每个单元的控制)控制产生影响,当我们想使用多智能体类型的方法时,这变得很不灵活。因此,我们尝试了一系列不同的行动,如图 3 所示。

图 3:宏观-微观分层动作总览
写代码的时候,我们将每个控制器封装为一个模块。模块以类似于 UAlbertaBot 的方式组织,如图 4 所示。
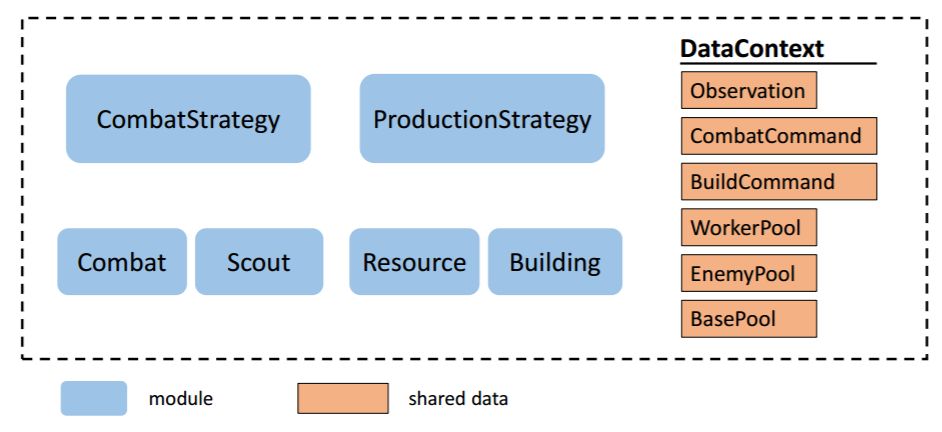
图 4:基于宏观-微观分层行动的智能体模块图。
实验
我们在 1v1 虫族对虫族的全场比赛中分别测试 TStarBot1 和 TStarBot2 智能体。具体来说,智能体需要和等级 1(最简单)到等级 10(最困难)的内置 AI 进行比赛。我们使用的地图是深海暗礁模式,据报道在该地图中,在原始 PySC2 观察/动作上,一般 A3C 智能体与内置 AI 进行人族 vs 人族全场比赛时表现不佳。
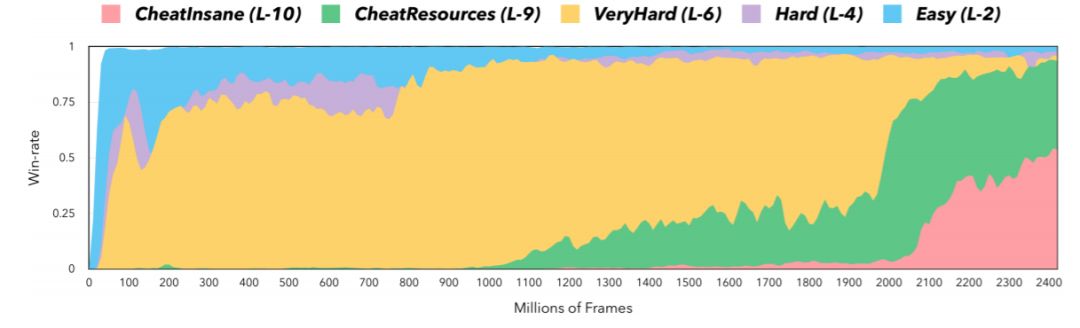
图 5:TStarBot1 使用 PPO 算法的学习曲线。注意 TStarBot1 - PPO 在大约 30M 帧后开始打败等级 2(简单)的内置 AI(至少 75% 的胜率),打败等级 4(困难)、等级 6(非常困难)、等级 9(资源作弊)、等级 10(疯狂作弊)则分别是在大约 250M 帧、800M 帧、2000M 帧、3500M 帧的时候。

表 2:TStarBot1 和 TStarBot2 智能体在不同难度等级下和内置 AI 比赛的胜率(%)。对于 TStarBot1,我们报告了使用 DDQN、PPO 和随机策略的比赛结果。每个胜率通过对使用不同的随机种子在 200 场比赛的结果取平均值得到,其中允许使用战争迷雾。

表 3:TStarBot vs 人类玩家。每个项表示 TStarBot1/TStarBot2 的胜利/失败场数。
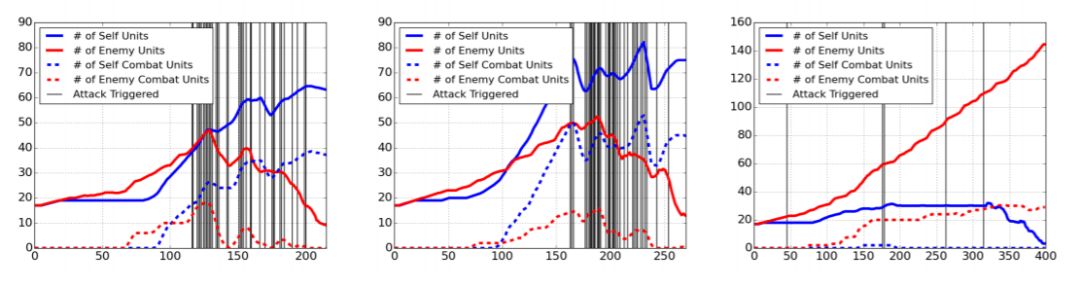
图 6:关于 TStarBot1 战争时机的学习策略:Rush 和经济优先。
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
