
作者 | 张海涛 编辑 | Vincent
一. 概述
随着物联网 IOT 时代的来临,IOT 设备感知和报警存储的数据越来越大,有用的价值数据需要数据分析师去分析。大数据分析成了非常重要的环节。当然近两年开启的开源大潮,为大数据分析工程师提供了十分富余的工具。但这同时也增加了开发者选择合适的工具的难度,尤其对于新入行的开发者来说。学习成本,框架的多样化和复杂度成了很大的难题。例如 Kafka,Hdfs,Spark,Hive 等等组合才能产生最后的分析结果。把各种开源框架、工具、库、平台人工整合到一起所需工作之复杂,是大数据领域开发和数据分析师常有的抱怨之一,也是他们支持大数据分析平台简单化和统一化的首要原因。
二.ClickHouse 发展历史
Yandex 在 2016 年 6 月 15 日开源了一个数据分析的数据库,名字叫做 ClickHouse,这对保守俄罗斯人来说是个特大事。更让人惊讶的是,这个列式存储数据库的跑分要超过很多流行的商业 MPP 数据库软件,例如 Vertica。如果你没有听过 Vertica,那你一定听过 Michael Stonebraker,2014 年图灵奖的获得者,PostgreSQL 和 Ingres 发明者(Sybase 和 SQL Server 都是继承 Ingres 而来的), Paradigm4 和 SciDB 的创办者。Michael Stonebraker 于 2005 年创办 Vertica 公司,后来该公司被 HP 收购,HP Vertica 成为 MPP 列式存储商业数据库的高性能代表,Facebook 就购买了 Vertica 数据用于用户行为分析。
三.ClickHouse 支持特性剖析
在看 ClickHouse 运行场景之前,架构师或开发人员必须要了解技术的功能特性以及弊端。只有”知己知彼”才可以”百战不殆”,接下来我们看一下 ClickHouse 的具体特点。我们来看看其中的一些功能:
1. 真正的面向列的 DBMS
在一个真正的面向列的 DBMS 中,没有任何“垃圾”存储在值中。例如,必须支持定长数值,以避免在数值旁边存储长度“数字”。例如,十亿个 UInt8 类型的值实际上应该消耗大约 1 GB 的未压缩磁盘空间,否则这将强烈影响 CPU 的使用。由于解压缩的速度(CPU 使用率)主要取决于未压缩的数据量,所以即使在未压缩的情况下,紧凑地存储数据(没有任何“垃圾”)也是非常重要的。
因为有些系统可以单独存储单独列的值,但由于其他场景的优化,无法有效处理分析查询。例如 HBase,BigTable,Cassandra 和 HyperTable。在这些系统中,每秒钟可以获得大约十万行的吞吐量,但是每秒不会达到数亿行。
另外,ClickHouse 是一个 DBMS,而不是一个单一的数据库。ClickHouse 允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器。
2. 数据压缩
一些面向列的 DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
3. 磁盘存储的数据
许多面向列的 DBMS(SAP HANA 和 GooglePowerDrill)只能在内存中工作。但即使在数千台服务器上,内存也太小,无法在 Yandex.Metrica 中存储所有浏览量和会话。
4. 多核并行处理
多核多节点并行化大型查询。
5. 在多个服务器上分布式处理
上面列出的列式 DBMS 几乎都不支持分布式处理。在 ClickHouse 中,数据可以驻留在不同的分片上。每个分片可以是用于容错的一组副本。查询在所有分片上并行处理。这对用户来说是透明的。
6.SQL 支持
如果你熟悉标准的 SQL 语法,那么大家在谈论 ClickHouse SQL 语法的支持层面上,就不能算真正全面的支持 SQL 语法了。ClickHouse SQL 有跟真正 SQL 不一样的函数名称。不过语法基本跟 SQL 语法兼容,支持 JOIN、FROM、IN 和 JOIN 子句以及标量子查询支持子查询。不支持关联子查询。ClickHouse 支持基于 SQL 的声明性的查询语言,并且在许多情况下符合 SQL 标准。支持 FROM BY、IN 和 JOIN 子句中的 GROUP BY、ORDER BY,标量子查询和子查询。不支持特殊的子查询和窗口函数。
7. 向量化引擎
数据不仅按列存储,而且由矢量 - 列的部分进行处理。这使我们能够实现高 CPU 性能。
8. 实时数据更新
ClickHouse 支持主键表。为了快速执行对主键范围的查询,数据使用合并树 (MergeTree) 进行递增排序。由于这个原因,数据可以不断地添加到表中。添加数据时无锁处理。
9. 索引
例如,带有主键可以在特定的时间范围内为特定客户端(Metrica 计数器)抽取数据,并且延迟时间小于几十毫秒。
10. 支持在线查询
这让我们使用该系统作为 Web 界面的后端。低延迟意味着可以无延迟实时地处理查询,而 Yandex.Metrica 界面页面正在加载(在线模式)。
11. 支持近似计算
系统包含用于近似计算各种值,中位数和分位数的集合函数。
支持基于部分(样本)数据运行查询并获得近似结果。在这种情况下,从磁盘检索比例较少的数据。
支持为有限数量的随机密钥(而不是所有密钥)运行聚合。在数据中密钥分发的特定条件下,这提供了相对准确的结果,同时使用较少的资源。
12. 数据复制和对数据完整性的支持。
使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复
ClickHouse 不完美之处:
不支持事物。
不支持 Update/Delete 操作。
支持有限操作系统。
现在支持 ubuntu,CentOS 需要自己编译,不过有热心人已经编译好了,拿来用就行。对于 Windows 不支持。
ClickHouse 与已有大数据分析技术有何不同
知道了 ClickHouse 的特性和不完美,下面我们可以对比一下之前的大数据分析跟现在的有啥区别?
代替复杂的多样大数据技术组合架构
之前的大数据分析,例如 Hadoop 家族由很多技术和框架组合而成,犹如一头大象被拆分后其实所剩下的价值也就是 HDFS、Kafka、Spark ,其他的几乎都没有任何价值。
这些可以用 ClickHouse 一项技术代替。

典型的大数据分析架构 =>ClickHouse
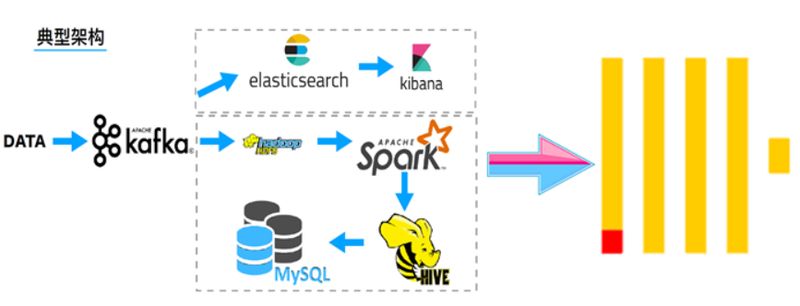
查询速度快快快
以下为新浪公司实战得出的测试结果:
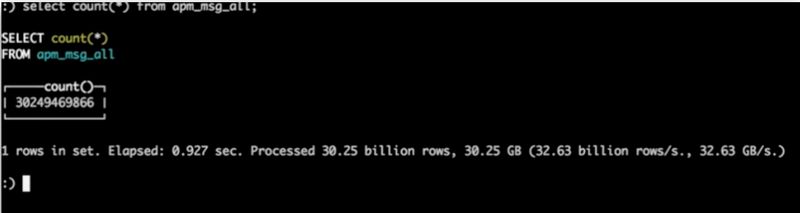
集群部署 4 台机器,每台机器配置 :CPU E5-2620@2.00GHz ,开启超线程后 24core ,48g 内存,3T × 12 Raid5Select count(*) 300 亿 数据 0.9 秒
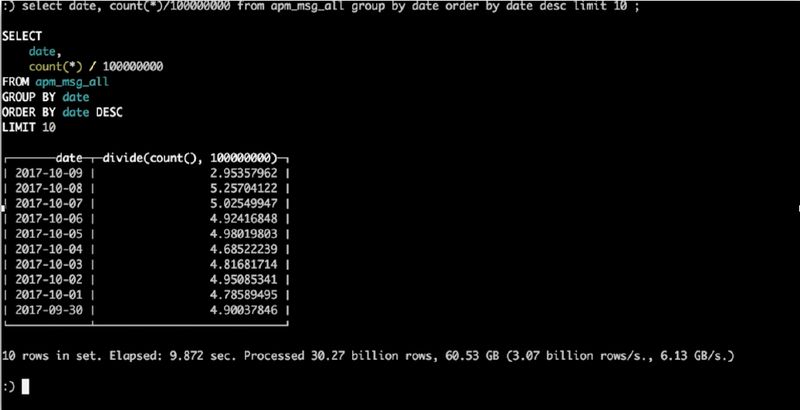
select date, count(*) from xx group by date ,300 亿数据 group by 日期 查询 9.8 秒
官方压测
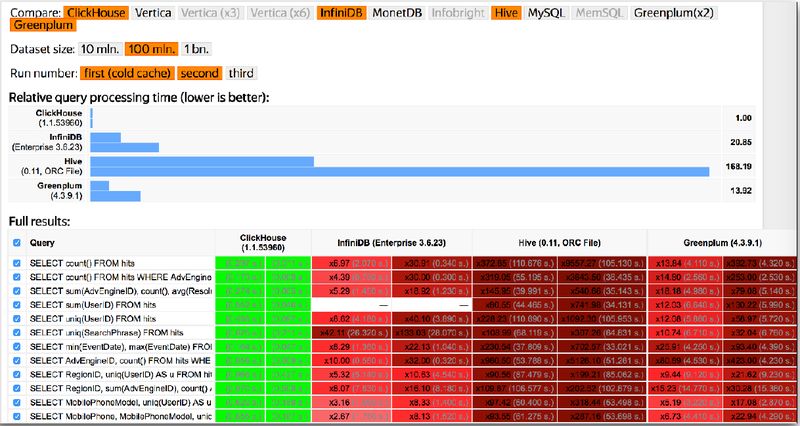
下面是 100M 数据集的跑分结果:ClickHouse 比 Vertia 快约 5 倍,比 Hive 快 279 倍,比 My SQL 快 801 倍;虽然对不同的 SQL 查询,结果不完全一样,但是基本趋势是一致的。ClickHouse 跑分有多块?举个例子:ClickHouse 1 秒,Vertica 5.42 秒,Hive 279 秒;
自从 ClickHouse2016 年 6 月 15 日开源后,ClickHouse 中文社区随后成立。中文开源组开始以易观、新浪、海康威视、美团、京东、58、腾讯、酷狗音乐和俄罗斯开源社区等人员组成,随着开源社区的不断活跃,陆续有神州数码、青云、PingCAP、中软国际等公司成员加入。一开始只是几个 ClickHouse 爱好者在群里讨论 ClickHouse 技术,后来因为加入的人越来越多,群内分享不太方便,社区建立了 ClickHouse 中文论坛。在交流中,我们了解到一些一线大厂已经把 ClickHouse 运用到生产环境中,社区也从各个公司运用中吸收了经验。
ClickHouse 目前已经应用于以下场景:
电信行业用于存储数据和统计数据使用。
新浪微博用于用户行为数据记录和分析工作。
用于广告网络和 RTB、电子商务的用户行为分析。
信息安全里面的日志分析。
检测和遥感信息的挖掘。
商业智能。
网络游戏以及物联网的数据处理和价值数据分析。
最大的应用来自于 Yandex 的统计分析服务 Yandex.Metrica,类似于谷歌 Analytics(GA),或友盟统计、小米统计,帮助网站或移动应用进行数据分析和精细化运营工具。据称 Yandex.Metrica 为世界上第二大的网站分析平台。ClickHouse 在这个应用中,部署了近四百台机器,每天支持 200 亿的事件和历史总记录超过 13 万亿条记录,这些记录都存有原始数据(非聚合数据),随时可以使用 SQL 查询和分析,生成用户报告。
五.ClickHouse 和一些技术的比较
商业 OLAP 数据库
例如:HP Vertica, Actian the Vector,
区别:ClickHouse 是开源而且免费的
云解决方案
例如:亚马逊 RedShift 和谷歌的 BigQuery
区别:ClickHouse 可以使用自己机器部署,无需为云付费
- Hadoop 生态软件
例如:Cloudera Impala, Spark SQL, Facebook Presto , Apache Drill
区别:
- ClickHouse 支持实时的高并发系统
- ClickHouse 不依赖于 Hadoop 生态软件和基础
- ClickHouse 支持分布式机房的部署
开源 OLAP 数据库
例如:InfiniDB, MonetDB, LucidDB
区别:这些项目的应用的规模较小,并没有应用在大型的互联网服务当中,相比之下,ClickHouse 的成熟度和稳定性远远超过这些软件。
开源分析,非关系型数据库
例如:Druid , Apache Kylin
区别:ClickHouse 可以支持从原始数据的直接查询,ClickHouse 支持类 SQL 语言,提供了传统关系型数据的便利。
六.总结
在大数据分析领域中,传统的大数据分析需要不同框架和技术组合才能达到最终的效果,在人力成本,技术能力和硬件成本上以及维护成本让大数据分析变得成为昂贵的事情。让很多中小型企业非常苦恼,不得不被迫租赁第三方大型公司的数据分析服务。
ClickHouse 开源的出现让许多想做大数据并且想做大数据分析的很多公司和企业耳目一新。
ClickHouse 正是以不依赖 Hadoop 生态、安装和维护简单、查询速度快、可以支持 SQL 等特点在大数据分析领域越走越远。
感谢易观 CTO 郭炜和新浪高鹏高总的资料支持和写序支持。
传送门
ClickHouse 官网:https://clickhouse.yandex/
ClickHouse 开源项目地址:https://github.com/yandex/ClickHouse
作者介绍
张海涛,目前就职于海康威视云基础平台,负责云计算大数据的基础架构设计和中间件的开发,专注云计算大数据方向。ClickHouse 中文社区人员,如果想进一步了解最新 ClickHouse 动态和技术研究成果,请加微信 cyrjkj 入群共同研究和运用。或者访问者访问 clickhouse.com.cn 加入开发加入开发者社区。
声明:本文来自AI前线,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
