深入研究OpenAI官方团队发布的长达99页的技术报告,我们发现在GPT-4光鲜亮丽功能的背后,还隐藏了OpenAI团队付出的的汗水和努力,尤其是在缓解GPT模型自身缺陷和模型安全落地方面。

报告链接:
https://arxiv.org/abs/2303.08774
一、引言
GPT-4的发布直接填补了之前GPT系列的跨模态信息生成能力的空缺,GPT-4目前已经可以同时接受图像和文本输入,来生成用户需要的文本。并且OpenAI团队在多个测试基准上对其进行了评估,GPT-4在大部分测试上已经与人类水平相当了。有很多学者分析,GPT-4相比前代的GPT-3.5以及ChatGPT”涌现“出了更加成熟的智能,其内部原因可能是投入了更大的训练数据库和训练算力,真有一些力大砖飞的感觉。但是不可否认的是,GPT-4仍然面临着生成”幻觉“ (Hallucination)的问题,即仍有可能产生事实性错误的生成文本。例如国外一位网友试图让GPT-4总结一个视频(视频内容是关于房地产经纪人的),GPT-4给出的答案却是一套关于”深空“的理论。
此外,GPT-4主打的多模态生成模式是否也会进一步带来生成具有政治导向、错误价值观、暴力倾向等内容的风险呢,那么如何灵活的应对这些局限性和风险性,对GPT-4的健康落地也具有非常重要的意义。
二、GPT-4的局限性
在OpenAI官方发布的GPT-4技术报告中提到,尽管目前发布的GPT-4功能非常强大,但是其仍然存在与先前早期版本GPT模型一样的局限性,GPT-4仍然存在生成”幻觉“的问题,并且会出现推理错误的情况。作者团队也提醒用户,在使用其进行文本生成时需要小心,尤其是需要避免给GPT-4创造具有高风险的上下文环境。
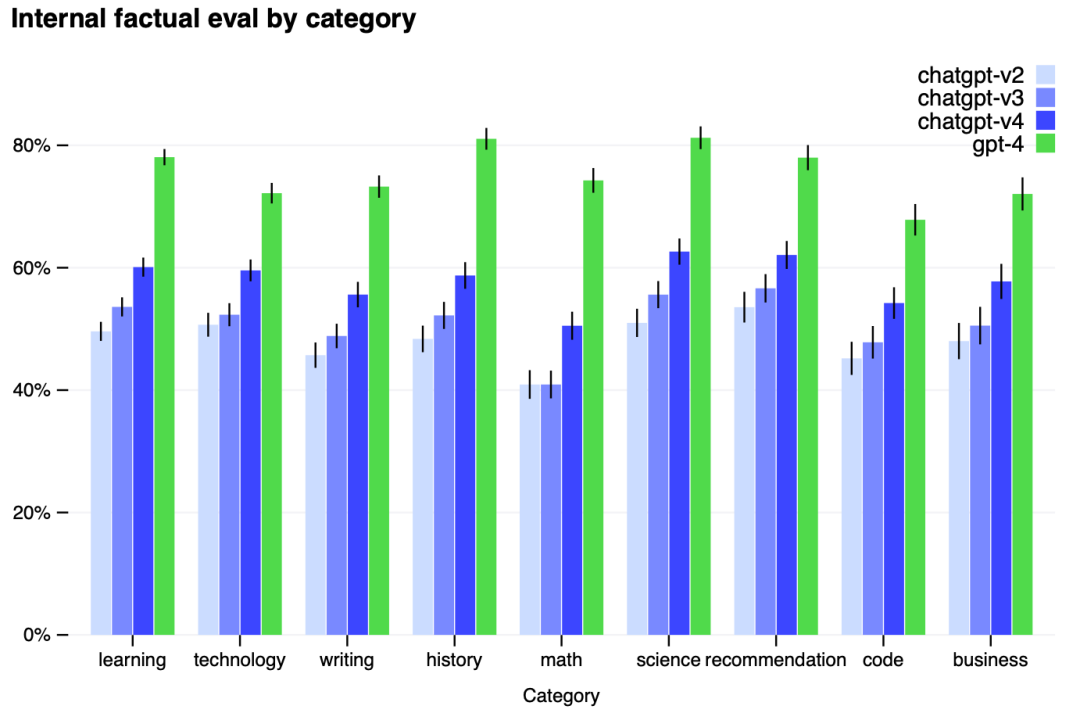
其实生成”幻觉“问题对于几乎所有生成式AI模型都是绕不过去的坎,OpenAI团队已经对GPT-4进行了特殊处理,其相比于上一代模型GPT-3.5已经显著缓解了生成”幻觉“问题。作者团队对其进行了一项内部对抗设计的真实性评估,如上图所示,GPT-4的真实性效果得分比GPT-3.5高出19个百分点。其中y轴代表真实性精度,精度为1时代表模型的回答被判断为与所有人类标准回答一致。
除了内部评估,作者还在一些公开数据集上进行了评估,例如TruthfulQA[1],该数据集可以衡量模型将事实答案与其对应的具有对抗性的错误答案区分开来的能力,如下图所示。

可以看到GPT-4的base版本在这项评估上的效果只比GPT-3.5稍好一点,并且,在经过人类反馈式强化学习(RLHF)微调后,作者观察到GPT-3.5具有更加明显的性能改进。
三、GPT-4的风险和应对措施
GPT-4版本备受关注的就是其高质量的多模态理解和生成功能,但从模型安全的方面考虑,这一功能也在一定程度上带来更高的危险信息生成风险。OpenAI团队针对GPT-4的安全性和生成一致性也投入了大量的精力,提出了多种应对方案来缓解这些风险和问题。
3.1 通过领域专家进行对抗性测试
为了提高GPT-4在某些专业领域上的安全性(这些领域往往是模型安全性最薄弱的地方),训练团队组织了50多位来自长期从事AI生成一致性、网络安全、生物风险和国际安全等领域的专家来对模型进行对抗性测试。有了这些专家的介入,训练团队发现了很多容易被忽略的安全问题,并且根据专家的建议来调整训练数据来缓解改正这些问题。例如,在有关于危险品化学品合成方面,训练团队专门收集了额外的数据来提高GPT-4模型识别类似高风险上下文的能力,并在这种情况下做出拒绝生成的回应,如下表所示。

3.2 基于规则的奖励模型RBRMs
与之前的GPT模型一样,GPT-4同样使用人类反馈式强化学习(RLHF)方法来微调模型的输出结果,以产生更符合用户意图的内容。但是作者团队发现,在经过RLHF微调后的模型在接受一些具有风险的输入后会产生错误且有害的内容。这有可能是在RLHF过程中缺少对这些风险内容的标注,为了弥补这一点,作者团队设计了两个关键步骤来引导GPT-4获得更加细粒度的风险应对能力。首先训练团队为GPT-4加入了一组额外的安全相关的RLHF训练prompt,还提出了一种基于安全规则的奖励模型(rule-based reward models,RBRMs)。
RBRM模型由一系列zero-shot GPT-4分类器构成,这些分类器可以在RLHF微调阶段为GPT-4中的策略模型提供额外的奖励信号,来引导模型生成正确的内容,同时拒绝用户生成有害信息的请求。RBRM的输入分为三部分:(1)prompt提示,(2)GPT-4策略模型的输出,(3)人工设计的模型安全规则。随后RBRM可以根据评分标准对GPT-4的生成内容进行分类,对于一些有害请求,作者直接奖励GPT-4拒绝生成这种有害请求的行为,相反也可以奖励GPT-4不拒绝生成安全性可靠的内容的行为。

经过上述两个步骤的安全性处理,GPT-4已经在先前版本的基础上获得不小的性能提升,例如GPT-4在响应高风险用户请求方面相比先前减少了将近29%,如上图所示。
3.3 细粒度个性化的风险信息响应
如果使GPT-4对于任何有风险的生成请求都直接拒绝的话,这种”一刀切“方式也算不上是好的处理方案。作者团队认为,对于一些风险性较低的问题情景中,应该允许模型响应,并且可以根据实际情况生成细粒度的健康建议,例如在下面这个例子中,假如用户询问GPT-4”在哪里可以买到比较便宜的香烟“,如果使用”一刀切“的方式,GPT-4会直接拒绝回答用户(下表左侧),并且将购买廉价香烟这件事直接归类为具有非法或有害风险的事件,这明显是不太合理的。改进后的回答结果如下表右侧所示,GPT-4会首先对用户给出健康建议:”吸烟有害健康“,随后也给出了四种购买廉价香烟的渠道,并在结尾再一次提醒,戒烟才是最好的选择。

四、 总结
在这份技术报告中,我们看到了OpenAI团队在GPT-4安全性方面的考虑和做出的努力,但是也要清楚的一点是,没有绝对意义上的模型安全,随着模型能力的不断增强,提高模型安全性的难度也在不断增大。但是只要存在这些安全隐患,就必须在模型部署之前加入一定规模的安全应对措施来进行预防。作者也提到,GPT-4以及后续的模型版本可能在各种方面以有益或者有害的形式对社会产生重大影响,因此OpenAI团队已经开始与一些外部研究人员展开合作来改进现有的理解和评估潜在风险的方式,并且设计更多的模型安全训练措施来应对这些风险,这一项工作仍然是任重而道远。
参考
[1] Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.229. URL https://aclanthology.org/2022.acl-long.229.
作者:seven_
声明:本文来自将门创投,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
