ChatGPT爆火后,网安行业内出现了更多关于AI的讨论。有的在讨论AI安全,有的在讨论大模型对网络安全产业供给和需求带来的变化。今天小编做一期观点综述,探析一下大模型时代AI对网络安全的影响。
一、什么是AI安全:安全的AI(AI Safety)和AI的安全(Security for AI )
安全的AI(AI Safety)与AI的安全(Security for AI)从中文语境下的理解容易先入为主而产生混淆。简单来讲,安全的AI(AI Safety)更关注AI是否对人类和社会而言是安全的,而AI的安全(Security for AI)更关注如何保护AI不被技术性外部威胁所破坏。
(1)AI Safety
AI Safety致力于构建安全的大模型。AI大模型作为一个工具,应当帮助人们,而不是取代人们或对人类社会造成伤害。AI Safety的具体内容包括:与人类意图对齐Alignment,可解释性Interpreferability,鲁棒性Robustness。
对齐(Alignment)要求AI系统的目标要和人类的价值观与利益相保持一致;如果AI和人类的价值观并不能对齐,可能会出现AI的行为并不符合人类意图的目标,在多种设定目标冲突时做出错误取舍,伤害人类的利益,脱离控制等问题;AI对齐的实现主要存在三方面的挑战,一是选择合适的价值观,二是将价值观编码成为AI系统中,三是选择合适的训练数据。
可解释性(Interpreferability)是指对模型内部机制的理解以及对模型结果的理解。人工智能应用以输出决策判断为目标的情况下所产生的决策的原因能够被人类理解的程度。人工智能模型的可解释性越高,人们就越容易理解大模型为什么会做出某些决定或预测。
鲁棒性(Robustness)可以理解为模型对数据变化的容忍度。假设数据出现较小偏差,只对模型输出产生较小的影响,则称模型是鲁棒的。
2023年4月6日,作为业界领航者,OpenAI官方发布了一篇名为《Our approach to AI safety》的博客文章,探讨如何安全地构建、部署和使用人工智能系统的六大策略,其主要内容包括:
发布前的严格测试,并且聘请外部专家进行反馈,通过RLHF等技术来改善模型的行为,建立广泛的安全和监控系统。例如,在最新模型GPT-4完成训练后,花了6个多月的时间在整个组织中工作,以使其在公开发布之前更安全、更一致。
在实践中改善模型,OpenAI将谨慎地逐步向更多人发布新的AI系统,并在吸取经验教训后不断改进。通过提供API和最强大的模型,使开发者能将技术直接应用于程序中。这有助于监测滥用情况并采取行动,建立缓解措施,以应对实际滥用方式,而非仅停留在理论层面。
OpenAI要求使用AI工具的用户年满18岁,或在父母同意下年满13岁。严禁技术应用于仇恨、骚扰、暴力或成人内容等场景,GPT-4在响应禁止内容方面相较于GPT-3.5的可能性降低了82%。除此之外,OpenAI与Khan Academy等非营利组织合作,打造AI辅助系统,充当学生导师与教师助手,并制定相应安全措施。
在最大可行情况下删除训练数据集中的个人信息,并且调整模型以拒绝对私人个人信息的请求,响应个人从其数据集中删除其个人信息的要求。这些步骤最大限度地减少了模型可能生成包含个人信息的响应的可能性。
OpenAI通过利用用户对被标记为不正确的ChatGPT输出的反馈作为主要数据来源,提高了GPT-4的事实准确性。GPT-4产生真实内容的可能性比GPT-3.5高40%。
解决安全问题还需要广泛的辩论、实验和参与,包括关于AI系统行为的界限。OpenAI将继续促进利益相关者之间的合作和开放对话,以创建一个安全的AI生态系统。
(2)Security for AI
Security for AI聚焦于对AI/ML模型的保护,包括大模型本身的安全与保护以及使用过程的安全,也就是更关注如何保护这些模型系统免受外部威胁和攻击,并且符合现实世界的合规框架。
人工智能系统的生命周期一般可以分为五个阶段:数据收集、数据预处理、模型训练、模型推理和系统集成,每个阶段都容易受到不同的安全威胁。
在数据收集阶段,针对硬件采集的代表性攻击方式是通过访问或篡改传感器提供的数据来进行传感器欺骗攻击(sensor spoofing attacks);而针对软件采集的方式会产生数据偏差(data biases)、虚假数据(fake date)、数据泄露(date breach)等安全风险。
在预处理阶段容易受到图像缩放攻击(image scaling attacks),即攻击者篡改图像并滥用人与机器之间的(视觉)认知差异,以实现欺骗和逃避攻击。例如,通过使用缩略图的方式降低原始图片的分辨率,显示的缩略图会对原始图片进行采样缩小分辨率,点击打开后的图片与缩略图在图像数据上会有巨大差异 ,而对于肉眼不会被察觉。
在模型训练阶段,AI大模型最容易受到的攻击类型是投毒攻击(poisoning attacks)。投毒攻击将有毒数据注入从而污染和篡改训练好的模型。传统机器学习方法没有假设输入模型的数据可能有误,意图不轨的攻击者可以通过注入大量“错误”的数据来搅乱数据的分布,调教大模型向他们所期望的道路偏移。另外一种经常被归类于投毒攻击的攻击类型是后门攻击。通过输入触发指令(trigger)后,模型进入深度神经网络中的隐藏模式,产生特定的隐藏行为。
推理阶段常常出现的攻击方式是对抗攻击(adversarial attacks),即对输入样本故意添加一些人为无法察觉的细微干扰,导致模型以高置信度给出一个错误的输出。对抗攻击与投毒攻击不同的是,对抗攻击并不会改变模型。
在AI的系统集成阶段,情况就变得更加复杂。在实际应用场景中,人工智能应用的系统集成不仅涉及人工智能技术本身的安全风险,还涉及车载系统、网络、软件、硬件的结合点问题。这些威胁包括人工智能数据和模型的机密性(confidentiality)、代码漏洞、人工智能偏见等。
二、对网络安全产业需求侧的影响
AI大模型的广泛应用会带来攻击门槛的降低和攻击面的增加。在攻击的倒逼之下,行业可能会产生三个方面的网络安全需求,一是大模型被用于攻击而催生出的安全需求,二是大模型本身的安全需求,三是为安全使用模型而产生的安全需求。
(1)大模型被用于攻击而催生出的安全需求
【钓鱼邮件】
由于ChatGPT用于文本生成的能力过于强大,可以预见钓鱼邮件问题将持续增加,据Darktrace发现,自从ChatGPT发布,网络钓鱼电子邮件的平均语言复杂度就上升了17%。

在ChatGPT发布后,钓鱼邮件数量显著上升且语言复杂度快速上升的情形下,邮件安全领域正在发生变革——从“安全”电子邮件网关转为智能AI方法,只有深入了解每个员工的日常互动,才能准确确定电子邮件是否归属其收件箱。每个用户如何使用其收件箱,以及每个用户的“正常”状态是什么样子,从行为入手检测异常,才能更加精准地为邮件安全保驾护航。
【恶意代码】
指使ChatGPT帮你写一封“用于哄骗”的钓鱼邮件是可行的,但直接要求ChatGPT生成攻击代码是大模型所拒绝的。因为ChatGPT具有使用规则的限制,禁止使用ChatGPT生成恶意软件,包括“试图生成旨在破坏、破坏或未经授权访问计算机系统的代码的内容”。然而这一规则并非无法绕过,通过对生成恶意代码的要求进行修饰,可以规避ChatGPT的安全措施,曲线实现生成恶意代码的目的。从技术上看,ChatGPT大大降低了编写恶意软件的难度门槛。Check Point公司的威胁情报团队经理表示,恶意人员无需任何编程经验就能够通过ChatGPT编写恶意软件,只需知道恶意软件或任何程序应该具备的功能,ChatGPT就能够编写代码,执行所需功能。
(2)大模型本身的安全需求
【Security for AI】
大模型本身的安全需求主要来源于Security for AI提及的人工智能系统生命周期的前四个阶段,即数据收集、数据预处理、模型训练、模型推理。大模型需要传统的企业安全堆栈保护自己,比如使用Cloudflare、Auth0来管理流量和用户身份。大模型需要确保其机器学习模型满足数据安全要求、保护用户隐私并且结果无偏见,并提供一定的可解释性,例如使用Calypso AI进行模型监控。ChatGPT在三月份经历了Redis Bug导致的信息泄漏和宕机,这就产生了对例如Datadog和Sumo Logic等APM、可观测性供应商的需求。大模型还有一些区别于其他软件开发公司的安全防护需求,比如Prompt注入攻击等,则对安全公司提出了更高的要求。海外已出现许多专注于Security for AI的公司,在一定程度上属于细分赛道的创新。
例如RSAC 2023创新沙盒冠军HiddenLayer,一家专注Security for AI的厂商,也是RSAC首次将冠军颁给AI安全这个细分赛道。HiddenLayer MLSEC平台是一种基于软件的非侵入式平台,主要用于监测机器学习(ML)算法的输入和输出,可以阻止对抗性攻击并提供对ML资产的健康和安全的可见性。平台基于不需要访问客户数据或知识产权的云架构,在不影响速度、效率和可靠性的情况下保护客户的ML资产。同时,平台可帮助客户维护ML算法,保护其免受推理、数据中毒、逃避或模型注入等攻击,并防止敏感训练数据被公开。HiddenLayer提出了Machine Learning Detection and Response (MLDR) 来防护机器学习算法。
非传统安全赛道的“大厂”咨询巨头毕马威也于2023年4月正式宣布成立一家尝试解决人工智能安全问题的初创公司Cranium。Cranium正在试图构建“一个端到端的人工智能安全和信任平台”,验证人工智能安全性并监测对抗性威胁。Cranium的构建是为了在客户端发现并提供AI系统的可见性,提供安全报告和监控,并创建合规性和供应链可见性报告。
(3)为安全使用模型而产生的安全需求
【数据防泄漏】
在应用ChatGPT时产生的数据防泄漏(DLP)是企业客户目前绝对的头号安全需求。三星半导体工厂的员工在将源代码输入ChatGPT以识别和消除错误并优化程序的同时,也无意中通过GPT向公众泄露了机密的生产数据。另一名三星员工使用AI聊天机器人总结会议记录,导致该会议记录被泄露。
上述数据泄漏事件只是冰山一角。根据CYBERHAVEN在3月21日发布的调查,8.2%的员工在工作场合使用过ChatGPT,6.5%的员工曾经将公司数据粘贴进去过,3.1%的员工曾经将公司敏感数据喂给过ChatGPT,而敏感数据占员工粘贴总数据的11%。
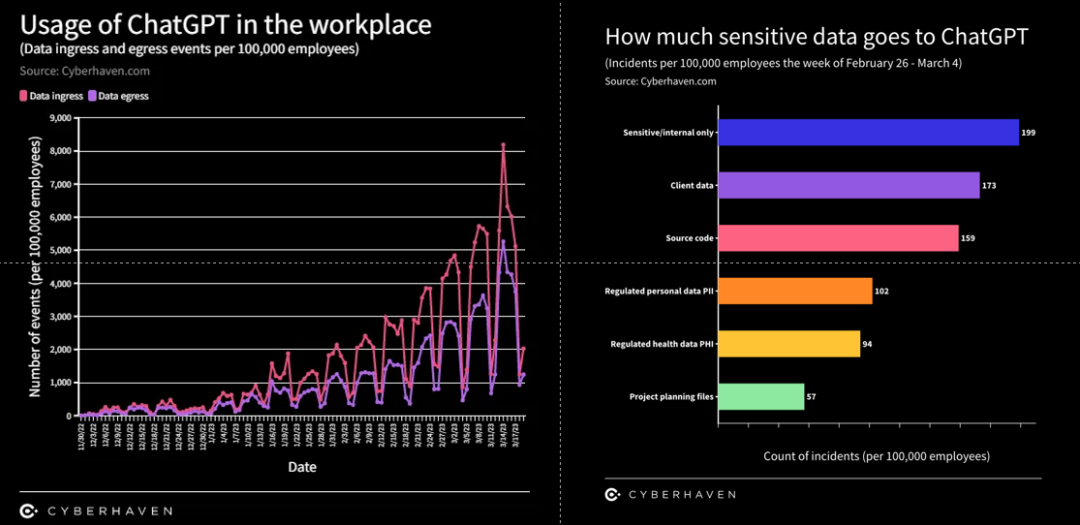
出于对使用ChatGPT而导致数据泄露的高风险性的考量,J.P. Morgan和Verizon已完全禁止使用ChatGPT,而亚马逊已向其员工发布了使用ChatGPT的警告和政策。甚至意大利数据保护局曾在今年三月底以涉嫌违反数据收集规则为由,对ChatGPT的开发公司OpenAI展开调查,并宣布禁止使用ChatGPT,且暂时限制OpenAI处理意大利用户数据。尽管ChatGPT于4月底在意大利恢复服务,但意大利数据保护局并没有放弃对其他人工智能平台的严格审查。
ChatGPT等大模型数据泄露事件问题的症结在于ChatGPT将输入的数据保存为知识库的一部分是无可避免的。OpenAI的使用条款规定,用户输入可用于“开发和改进其服务”。因此,一个用户输入的机密内容很可能将在之后被用于对另一个用户的生成需求的响应。
ChatGPT的广泛使用使数据泄露的几率增加了几个数量级。大多数DLP解决方案旨在识别和阻止某些文件和某些可识别的PII(例如,SSN、信用卡号、护照等)的传输。但用户丢给ChatGPT的是五花八门的文字,并且是否是高度敏感的机密数据则取决于客户公司的业务背景,因此传统的DLP手段对于ChatGPT来说几乎是完全失效的。在此背景下,对ChatGPT最简单粗暴的DLP应对措施是封禁其URL,但这又完全封死了员工借助ChatGPT来提高生产力的可能性。
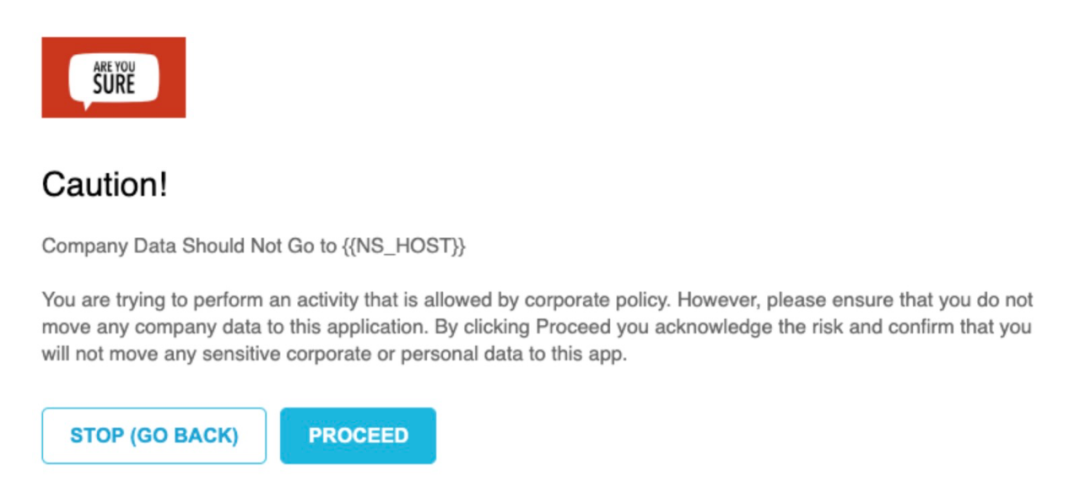
Netskope利用其在CASB的技术优势,提供了一种相对精细化的带内管理安全网关解决方案。比如对用户发出警告,只有在他们再次确认后才将问题提交给ChatGPT。
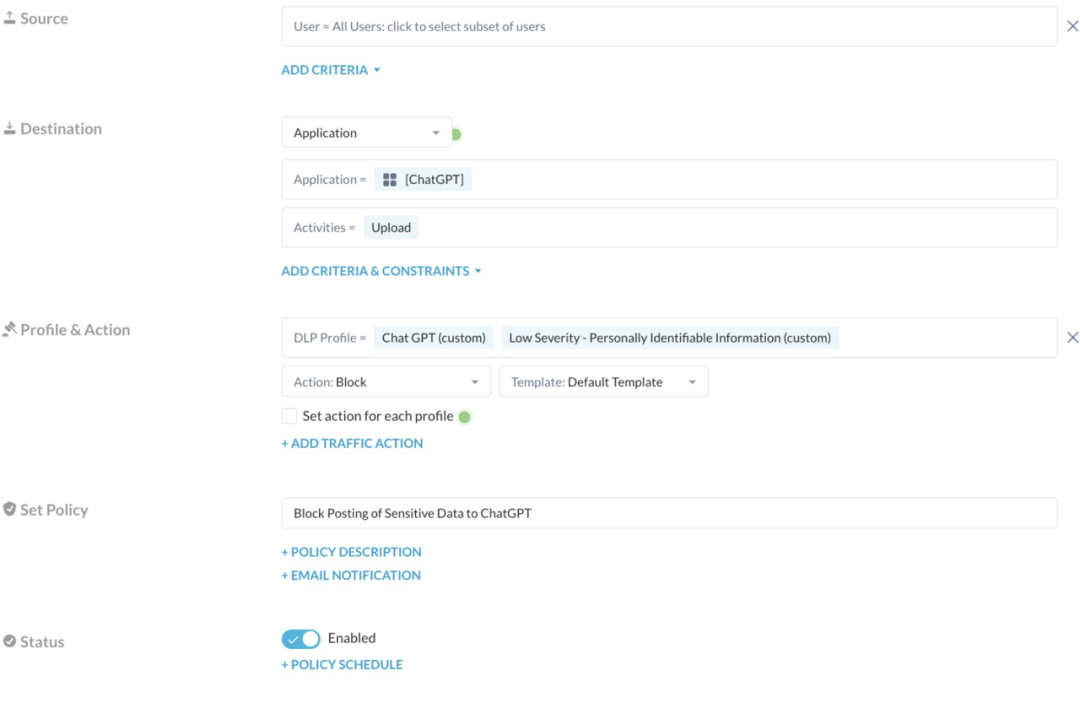
除了传统DLP具有的功能,如对可识别的PII的传输阻止外,Netskope的安全网关还可以创建更高级的可自定义的策略,例如拦截指定关键词等。当被监测的用户在ChatGPT上发布被策略禁止的字符串时,该行为会自动被Netskope阻止。
所有违规事件以及被监测用户试图上传的数据将通过Netskope的事件管理和取证记录供管理员查看,包括触发违规的实际数据、用户、应用程序等。
面对应用大模型导致数据泄漏等问题,除上述解决方式外,海外已经出现了专注于大模型的防火墙公司。
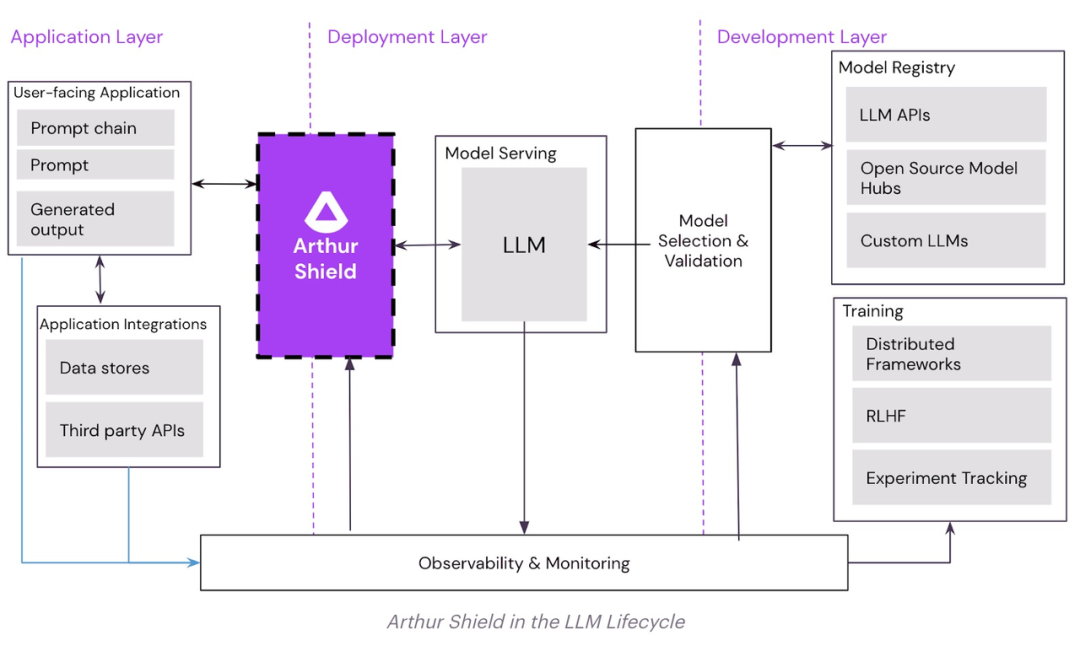
Arthur Sheild是首个用于大语言模型的防火墙,帮助公司更快、更安全地部署ChatGPT等大模型应用程序,保护组织免受部署大模型的安全问题。
Arthur Sheild能力可以包括:
防止PII或敏感数据泄露:Arthur Shield允许公司使用大模型在其完整数据集上进行训练或微调,同一大模型的其他用户无法从训练集检索敏感数据;
防止有毒的、攻击性的或有问题的语言生成:Arthur Shield允许公司阻止与其组织价值不一致的大模型响应;
防止幻觉:面对一些大模型自信地输出不正确的事实,Arthur Shield会检测到这些可能不正确的响应,并防止将它们返回给用户;
用户恶意提示:Arthur Shield检测并阻止恶意用户,包括试图让模型返回敏感训练数据或试图绕过安全控制等行为;
防止恶意注入:大模型应用程序通过从第三方网站和预训练文档嵌入数据库中检索来增强提示,这些来源不安全,可能包含注入大模型系统的恶意提示,导致未经授权的响应生成和数据泄露。
【API安全】
大模型爆火前,随着 5G、云计算、物联网的快速发展,加速了API在各领域的应用,目前已经在物联网、微服务、云原生等场景都得到了非常广阔的应用。随着5G、物联网技术落地,人类正进入万物互联时代, 从IaaS到PaaS、SaaS,从PC到移动APP、各种IoT设备,API无处不在。在大模型时代,无论从OpenAI的ChatGPT还是Google的PaLM,都以API的方式交付能力,必将导致API需求的井喷。
正如Salt Security发布的《State of API Security Report, Q1 2023》报告指出,94%的受访企业在过去一年中遇到过生产系统中的API安全问题,且与六个月前相比API攻击活动数量增加了400%,GPT的现象级火爆必然是背后的原因之一。GPT引爆的AI大模型带来的API安全需求或将成为2023年甚至AI大模型时代长期的安全重点。根据Future Market Insights的调查,API安全市场在2022年价值大约10亿美元,预计在未来10年能够维持25%左右的复合增长率。
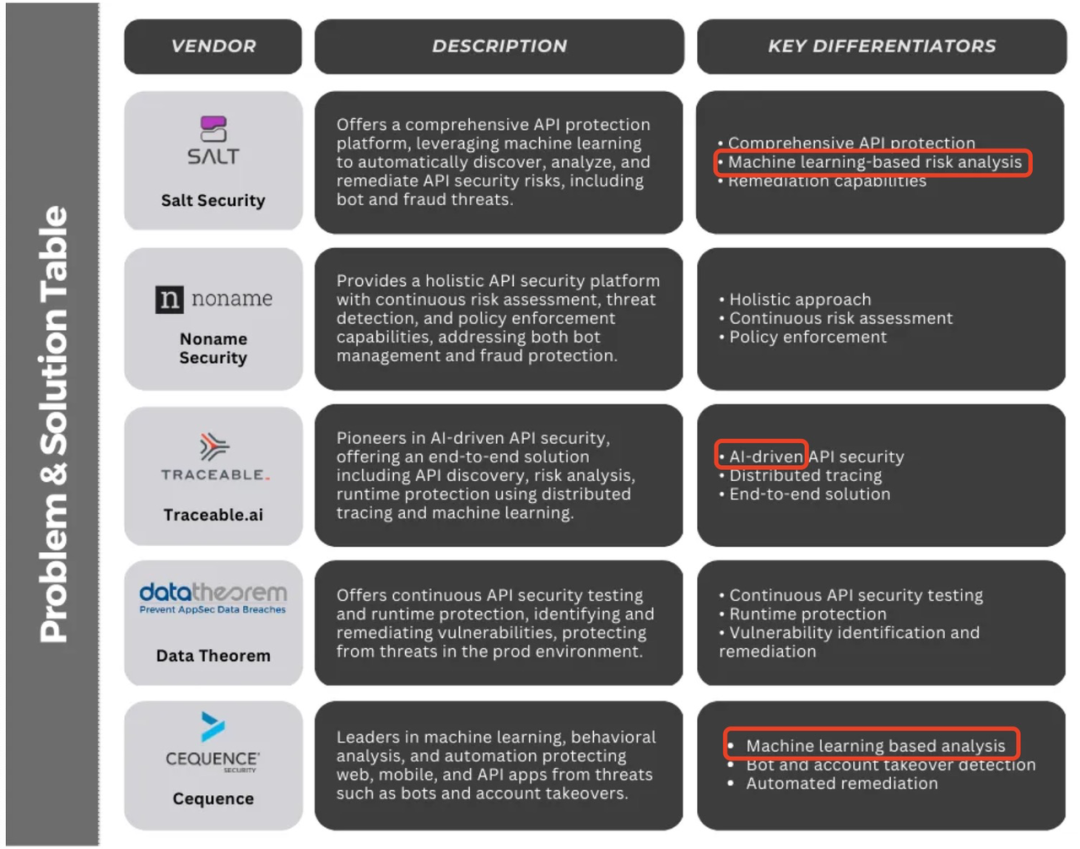
对于LLM的API使用者来说,API安全供应商可以让企业管理者对内部的API使用情况保持可见性,并尽可能避免经过身份验证的、无法防范的API使用威胁。对于OpenAI等模型和API的拥有者来说,非常需要API安全公司提供的Bot防御能力,除了正常用户会使用他们的API,还有大量恶意编写的机器人和被盗的账户会对它们进行大规模的自动攻击,API安全供应商可以通过AI/ML的能力找到偏离基线的恶意行为从而帮助客户对Bot形成一定的治理和防御。海外几家知名的API安全公司已运用AI/ML技术应对API安全的挑战。Salt Security、Traceable.ai、Cequence等公司使用机器学习和人工智能驱动的技术来检测威胁,使企业能够主动识别和解决潜在的漏洞和威胁。部分API安全供应商构建了安全数据湖(Security Data Lake),这是一个集中的大型存储库,旨在存储、处理和分析来自组织内各种来源的大量结构化和非结构化的安全相关数据,安全数据湖可以使用机器学习和AI算法来分析API安全数据的异常模式,帮助组织更快更有效地检测潜在的安全事件。
三、对网络安全产业供给侧的影响
大语言模型技术的广泛应用,能够赋能网络安全产业的诸多环节,甚至可能对部分环节带来颠覆性的改变。
OpenAI于2020年6月就发布了GPT-3,但并没有引起如此巨大反响,让人不禁思考基于GPT3.5的ChatGPT为何会掀起AGI巨浪,其技术进步究竟何在?
简单来说,GPT-3.5引发市场轰动的原因在于其相较于GPT-3涌现能力的解锁,使得其对于语义的理解能力有显著提升,表现结果呈现与人类对齐。根据安人心智董事长阳志平先生的测试,从人类理性思维的四类经典测试任务(语义错觉类、认知反射类、证伪选择类、心智程序类)对GPT-3.5进行评估,GPT-3.5的正确率约为58%,而人类测试正确率通常在40%-60%之间,这意味着GPT-3.5能够生成更加符合人类期待的反馈(如零样本问答、生成安全和公正的对话回复、拒绝超出模型知识范围的问题)。
具体而言,GPT-3.5解锁的突现能力主要体现在复杂推理能力和泛化到新任务的能力。根据艾伦人工智能研究所的研究,初代GPT-3主要展示语言生成、上下文学习和世界知识的能力,主要来源为大规模预训练;而GPT-3.5在GPT-3的基础上,进一步解锁了响应人类指令、泛化到没有见过的任务、代码生成与理解、利用思维链进行复杂推理的能力,主要通过代码训练、指令微调和基于人类反馈的强化学习(RLHF)解锁。
小编认为,以GPT为代表的大模型的本质是理解语言意图并根据意图进行任务分配,从而实现对话、计算、制图等能力,具有语言体系且流程性工作的占比较大的工作环节能被大模型所赋能。同时,出于工程落地难度及性价比的考虑,大模型更适合用于规模较大、所需人工较多的环节。
(1)安服团队效率提升
考虑到网安的日志为计算机领域的语言体系;GPT在github中预训练之后, 对于日志的理解具有天然优势;安全运营涉及大量流程性工作,部分环节人力需求较多。本文认为大模型的应用有望在安全运营中心(SOC)场景中降低安全服务人员的数量,实现降本增效。安全团队可以通过大模型增强的持续学习形成“肌肉记忆”来适应、响应安全事件,并在攻击得手之前将其遏制。
安全信息和事件管理(SIEM)是安全运营中心的基础,涉及到历史日志的分析和取证、实时分析日志和事件数据、提供威胁监控和时间响应。进一步来看,更加高级别的SIEM已经发展到用户行为分析(UEBA)和安全编排自动响应(SOAR),其中已初步涉及大模型的语义理解和代码生成能力:
用户行为分析(UEBA):传统的SIEM基于特征和规则进行分析,而用户行为超越了规则和相关性,可通过大模型的赋能研究攻击者行为模式,从而更加有效地检测内部威胁、针对性攻击和欺骗。
安全编排与自动响应(SOAR);涉及到将SIEM与企业系统集成并自动化响应事件。例如,在攻击者可以加密数据之前,SIEM可能会检测到勒索软件的警报并在受影响的系统上自动执行应对操作,大模型的代码生成能力或将提升系统的自动响应能力。
在具体场景上,根据安恒信息等业内厂商的观点,大模型可以赋能以下一些细分领域。
【数据分类分级】
数据分类分级的依据通常来源于法律法规、行业标准或地区标准文件,并以人工标注为主。人工智能模型在数据安全分类分级场景中占据越来越重要的地位,正在逐步取代人工繁琐单调的数据分类分级标注工作。
基于强化学习的人工智能模型已经在安恒信息AiSort数据安全分级产品中部署应用,AiSort能够精准识别数据业务含义,进行自动分类分级,大幅提高数据梳理的工作效率。AiSort内置了融合法律法规、行业标准等领域知识的预训练模型,同时支持模型有监督训练。用户利用有标签的数据源对模型进行训练,学习数据的特征与类别级别之间的内在关联,可预测出其它类似数据源的分类分级结果。产品在交互中接收人工反馈,引入强化学习RLHF来微调预训练的分类分级模型,在模型给出的候选分类分级结果中选择最优结果,通过奖励惩罚机制使模型不断优化自身,训练出一个分类分级领域适合客户的专有大模型。产品可根据数据的内容和描述等特征给出正确的分级结果,并且理解并引用标准文件中判断依据,帮助服务人员提升数据治理工作效率,在不同行业、不同业务条件下都能提供更加优质的数据安全分类分级服务。
【生成检测规则】
当前大部分的网络安全规则主要是依靠安全研究人员的经验来制作的,面对黑客层出不穷的攻击手段,专家经验的规则存在误报和无法识别新的攻击的问题。大模型可以帮助更好地自动生成检测规则。
在内网环境,大模型可以根据客户现场对误报的处理,从大量的原始日志、告警信息、误报中自动学习,自动生成检测规则。例如自动学习运营人员经常对哪些IP及端口的告警进行误报标记,给出生成检测规则的建议,并对这些IP及端口加入白名单或者封禁。在云上环境,利用MSS平台积累的大量数据,在此基础上研究场景,利用强化学习训练模型和人工反馈不断调试优化。开发运营反馈模块,针对告警排查过程中的各种日志证据,进行录入上报,利用大模型学习到其中的模式并自动的生成告警规则,在降低误报的同时也可以对新产生的攻击方式和手法自动生成检测规则。
【告警处置分析】
告警分析是安全运营的核心内容。伴随着组织机构的扩张、业务逻辑的复杂化,一个大中型企业每日的告警量很容易达到百万量级,从海量告警中筛选出重要风险事件给安全运营人员带来沉重负担。
针对告警处置,大模型可以学习安全分析师对各类风险场景的处置动作,自动生成处置规则。借助运营反馈模块,将告警排查过程中的各种日志证据进行录入上报。针对云上环境,可以利用MSS平台收集全国数据。在此大量数据基础上训练用于风险研判的大模型。针对特定告警和风险场景,由模型生成若干处置建议,通过人工反馈训练模型判断出最优的处置动作,使其学会生成正确的处置规则。
在日常的运营过程中,使用GPT技术学习大量历史运营分析报告内容之后,能够针对各类安全设备产生的告警事件和统计指标,迅速生成分析报告、捕捉关键异常、生成处置建议,协助分析师更快地洞察事件全貌。
【加密流量检测】
使用ChatGPT技术可以帮助网络安全领域的专家们构建科学的加密流量分析方案,通过分析网络流量,以及应用层面的安全检测,实现加密流量的安全检测,有效的抵御恶意攻击。ChatGPT技术在加密流量检测中可以通过分析网络流量,用来分析密钥空间,检测攻击模式,以及识别攻击行为来发现未知的网络攻击。ChatGPT技术的应用可以让网络安全管理者更有效地发现、识别和响应安全漏洞和攻击行为,为网络安全实现有效把控提供有力保障。另外,ChatGPT技术可以分析攻击者行为、以及及时响应各种威胁,为安全团队提供有效的应对措施。
(2)产品能力升级
大模型可以帮助网络安全公司迭代现有产品,让产品更加智能。
【静态代码分析】
对于代码分析而言,大模型的应用有技术层面和实际落地层面的问题:
分析复杂代码的能力不足:基于微软论文里给出的信息,目前的自回归模型在数学/推理任务中缺少规划能力 (planning),这使得这类模型即使面对稍微复杂一点的推理问题也很容易失败。推理能力是代码分析场景所必须要具备的能力,否则就难以做到精确分析;
Token长度限制:目前的GPT-4模型给出了32000tokens的输入上限。在面对真实软件项目时,这样的输入窗口太小,只能够进行代码片段的分析。即使通过embedding向量化,可用性也很有限。此外,由于输入窗口上限是由模型本身决定的,这就意味着难以通过工程的方法后期进行扩充;
稳定性问题:GPT是基于神经网络的模型,内部包含大量参数和随机性因素,这些随机性可以在对话场景下输出不一样的结果,呈现结果波动;在进行静态代码分析时,可能会由于API服务的速率限制、负载、网络延迟、服务器故障等原因,导致分析结果的不准确性和稳定性问题;
落地难度较大、具有局限性:涉及数据安全、计算成本、法律合规等问题。
综上,在代码安全风险检测方面,GPT在技术能力上还存在较大的缺陷和差距,其可在一些细分场景下提高SAST工具的用户体验,但不能对专业SAST工具实现替换,利用大模型进行代码分析任务不是更优的选择,但其可以作为现有技术的补充。首先,大模型可能可以提高代码分析精度,通过引入AI技术,可以帮助识别出更多危险函数;其次,大模型可以降低代码分析工具的使用门槛,帮助解读分析结果,涉及到人机交互、答疑解释的场景是大模型最为擅长的。比如,蜚语安全的代码安全分析产品Corax通过引入GPT-3.5的能力来改善修复建议的可阅读性,降低用户的使用门槛与成本。
ChatGPT之后,OpenAI还推出了Copilot X(基于GPT-4的GitHub Copilot升级版 AI编程软件),红杉资本发布开发人员工具2.0图谱(如下图),并认为人工智能将有巨大的机会改变软件工程。GitHub存有丰富的源代码,微软具备强大的安全能力,在AI编写代码能力之后,GitHub Copilot可能会把目标瞄向“帮助开发人员编写更高性能更安全的代码”,或将进军读取代码、扫描漏洞等安全领域,使得漏洞扫描不再基于规则,而由大模型驱动。

【WAF】
针对Web应用层的防护本身就涉及到对于语义的理解。传统WAF采用规则匹配的方式来识别和阻断攻击流量,随着Web漏洞数量的不断增加以及攻击方式不断变化,管理者通过持续更新和扩大规则库的方式来进行维护,维护工作繁琐且误报和漏报较为频繁。若赋予WAF更加高级的语义理解能力,就可以实现更加精准和智能的防护。
长亭科技的雷池(SafeLine)下一代Web应用防火墙即为全球范围内首款以智能语义分析算法为核心引擎能力打造的下一代WAF,除形成了质变的检测引擎的精准程度外,还可以通过插件形式灵活扩展、实现瑞士军刀般的功能增加,同时可以变形适配、安装部署进各种网络环境,与机器学习等技术更好的融合、增强流量分析的能力。根据长亭科技披露数据,其基于智能语义分析算法的下一代WAF产品可实现维护人员平均上线时间减少50%,维护人员成本降低70%。
【零信任防火墙】
在RSAC 2023发布新产品和集成的供应商中,Airgap的零信任防火墙(ZTFW)与ThreatGPT值得关注。
ThreatGPT建立在高级的AI/ML模型之上,旨在保护企业免受不断变化的网络威胁,为网络安全团队提供了更高水平的洞察力和生产力。ThreatGPT是Airgap零信任防火墙的一部分,可缩小攻击面,保护对关键设备的访问,并准确发现环境中的所有资产。Airgap ZTFW提供无代理分段,阻止任何威胁在设备之间或从一个网络层到下一个网络层的横向传播。Airgap无代理ZTFW无缝集成到现有的安全基础设施中,可以对旧的Windows服务器、物联网设备和现实网络中常见的无头机器进行微分段。ThreatGPT结合图形数据库和GPT-3模型,提供更强大的网络安全洞察。GPT-3模型可以分析自然语言查询以识别潜在的安全威胁,而图形数据库可以提供端点之间流量关系的上下文信息。
(3)产品整合与创新
近年来,防御端的趋势一直是整合,因为客户用的安全产品类型繁多,较多客户存在10-20种以上的安全设备,这样就给安全运维造成了非常大的难度,而安全也是要靠防御体系综合处理安全问题的,那么在AI大脑的作用下,充分调度四肢,对于系统整合性、内外部数据驱动更加看重。
【智慧大脑】
Microsoft-Security Copilot
大模型作为安全智慧大脑的概念被提出。
2023年3月,微软宣布推出下一代人工智能产品Microsoft Security Copilot,通过总结、理解威胁情报来简化复杂性并增强安全团队的行动力,该工具将帮助安全团队识别恶意活动,过滤海量流量和安全信号中的噪音,把重点 放在真正重要的信息上;此外,还将帮助安全团队关联和梳理攻击信息,优先处理重要安全事件并推荐最佳行动方案,迅速处理各种威胁。Security Copilot集成了GPT-4和微软的安全能力,接受自然语言交互,安全专业人士可以询问某个特定漏洞的概要,输入文件、网址或代码片段进行分析,或者从其他安全工具中获取事件和警报信息,所有的提问和回答都会被保存,调查者可以有完整的审计记录。Security Copilot的设计目的是辅助而不是取代安全分析师的工作,并且还包括一个便签板功能,让同事们可以协作和分享信息。安全专业人士可以使用Security Copilot 来进行事件调查或快速总结事件并帮助进行报告,这在一定程度上提供了一种新的安全产品形态。微软是安全领域产品最全,体系最完整,收入最多的超级巨无霸玩家,又通过copilot的形态率先为自己的安全产品配置了“大脑”,可能给其余安全厂商带来不同程度的“威胁”。
Palo-Cortex XSIAM
上文提到,企业使用的安全产品较多,拥有数十家安全供应商,从不同的供应商收集数据然后尝试将其交叉关联,这类似让数十个说不通语言的人交流。Palo Alto Networks内部先做了实验,从200家供应商那里收到6.7万条警报,用一个端点替换了这一切。XSIAM对数据进行交叉关联,并通过使用AI将平均响应时间从27天缩短到不到1分钟。让AI交叉关联数据,使其保持一致,在客户公司运行标准化的数据湖,并能够阻止威胁的发生。
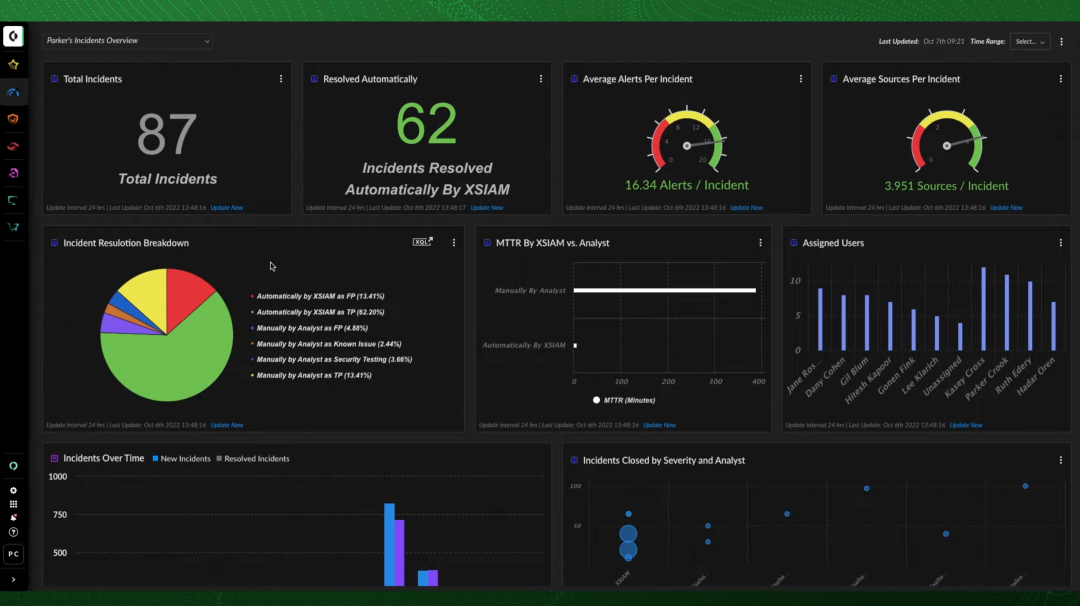
深信服-安全GPT + XDR
5月18日,深信服发布了其自研安全大模型。据深信服强调,安全GPT是完全自主可控的,不依赖开源模型服务(但架构于开源大模型之上),由深信服自主训练,训练数据部署在深信服托管云上,实现数据不出境。
在发布会的现场演示下,安全GPT赋能XDR后,在高级威胁检测、安全监测调查、热门漏洞排查等安全运营工作中表现出色:
准确率提高:通过前期5000万样本数据测试,相较传统检测引擎,赋能安全GPT技术的深信服XDR高级威胁检测率高达95.7%,误报率(安全告警里判错的比例)仅4.3%;
效率提高:运营人员花费3-6小时才能完成的安全监测调查工作,由安全GPT来完成只需5-10分钟,几番简单的对话,就可以快速有效完成任务;
深信服GPT的能力主要如下:
大幅提升对流量和日志的安全检测效果;
自动分析用户安全现状,并生成处置建议;
自动化调查、分析、研判,提升安全运营效率;
自然语言交互,提高用户体验,降低对运营人员的专业要求。
总结来看,微软安全副驾驶和深信服安全GPT都是将大模型赋能于自身的安全产品,使其在安全运营工作中提高效率、准确率、降低人力成本,大模型充当“智慧大脑”、“副驾驶”等角色,实现自动化SecOps加速,背后的安全能力仍由原来的安全产品提供,在一定程度上属于安全产品形态的创新。
深信服提出以下公式:1*安全工程师*安全GPT=N*安全专家。
该公式有两层含义:(1)从前多个安全专家做的事情,在GPT的赋能下,一个安全工程师就可以完成;(2)初级安全工程师,在GPT赋能下,拥有等同于安全专家的能力。

根据上述数世咨询定义的智能安全自主度模型,判断目前AI大模型在安全行业的自主程度仍处于L1或L2之间,处于“安全副驾驶”阶段,绝大多数的应用还局限于安全运营场景,以自然语言进行人机交互仍是其最大应用点,离“自动驾驶”还有较长的距离。
四、对网络安全厂商的潜在风险点
开源大模型本身可能存在未知的网络安全风险、数据出海风险、法律合规问题:大模型应用于国内网安公司,可能面临数据出海的问题,并涉及到法律合规的问题,国内网安公司无法直接接入GPT并进行商业化,调用开源大模型、本地化部署是必选项。
回答问题的准确性&推理结果的不可解释性:大模型对网络安全知识做增强学习能在一定程度上提高回答问题的准确性,但在投入运行阶段,向决策方解释模型的内部机制以及决策结果的解释,涉及到数据隐私、模型安全等方面的道德困境。
算力成本问题:如何更高性价比地利用大模型提高效率是网安公司必须的突破点,尤其是在普遍私有化部署的环境下。
网络安全产业已进入智能化时代,以AI对抗AI,以大模型对抗大模型,成为了业内共识。从RSAC 2023也能看出,网安厂商间的AI军备竞赛不会停止,AI大模型将对网安行业产生更持续更深远的影响,业界应时刻保持对AI大模型等技术的关注,拥抱新技术和新时代。
编辑:范云辰、施震
作者:陈坪
参考资料:
《2023 产业互联网安全十大趋势》
《Age of AI:大模型及OpenAI投资思考》
《Holistic Evaluation of Language Models》
《State of API Security Report, Q1 2023》
《Artificial Intelligence Security: Threats and Countermeasures》YUPENG HU, WENXIN KUANG, ZHENG QIN, KENLI LI, and JILIANG ZHANG, Hunan University
数世咨询《ChatGPT爆火出圈带来的AI网络安全的思考》 https://mp.weixin.qq.com/s/D5F80GhZXUsQVdgYxF4CwA
《云之后,大模型是网络安全的新机会吗?》https://mp.weixin.qq.com/s/nmeDrQX5dTRUT23-2sGI-g
《AI如何颠覆软件:你能为AI打工吗?》https://mp.weixin.qq.com/s/-f0GwSAOl4_o-4J_--S9XQ
蜚语安全《GPT之于代码分析,“掀桌”还是“救赎”?》https://mp.weixin.qq.com/s/mu1dnUjO66_Kgv7lM49INw
安恒信息《布局AI网络安全前沿研究 ,ChatGPT最全解读》https://mp.weixin.qq.com/s/t6morSfnPMNTr2xM0mV_ew
新智元公众号
浙商证券研究所《大模型如何影响网安行业的未来》
华安证券研究所《AI既是网安需求来源,也是网安下一形态》
https://openai.com/blog/our-approach-to-ai-safety#OpenAI
https://abnormalsecurity.com/blog/double-edged-sword-of-chatgpt
https://content.salt.security/thanks-state-api-report.html
https://www.cyberhaven.com/blog/4-2-of-workers-have-pasted-company-data-into-chatgpt/
https://www.sequoiacap.com/article/ai-powered-developer-tools/
https://community.netskope.com/t5/Inside-Netskope-Security/Netskope-DLP-use-cases-for-ChatGPT/m-p/3992
https://community.netskope.com/t5/Next-Gen-Secure-Web-Gateway-SWG/Netskope-Next-Gen-Secure-Web-Gateway-Controls-for-ChatGPT/td-p/3646
https://convequity.substack.com/p/chatgpt-sase-catalyst-for-netskope
https://www.arthur.ai/blog/announcing-arthur-shield-the-first-firewall-for-llms
https://www.crowdstrike.com/cybersecurity-101/machine-learning-cybersecurity/
https://www.cranium.ai
免责声明
*本公众号仅作为学习和研究使用,不构成对任何人的投资和建议,您直接或间接基于本公众号内容做出的投资应自行承担风险,航行资本及作者不对此承担任何责任。
*以上信息均为航行资本基于网络公开信息渠道整理,航行资本不为以上信息的真实性、准确性做任何保证。
*本公众号上所转载或引用内容均标注来源及出处,仅代表原作者本人,不代表航行资本立场。转载或引用内容的版权归原作者所有。如涉嫌侵权,请及时联系我们,我们将及时更正或删除有关内容。
*如需转载本深度调研,或对以往调研内容感兴趣,请联系:zhihouchen@voyagers-partners.com。
声明:本文来自航行资本,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
