本文发表于《指挥信息系统与技术》2023年第2期
作者:王 航,张宏军,程 恺,徐有为,申秋慧,李大硕
引用格式:王航,张宏军,程恺,等.面向知识图谱构建的电子战领域语料库建设[J].指挥信息系统与技术,2023,14(2):69-75.
简介
语料库构建是领域知识图谱构建的基础步骤和关键环节,高质量的语料能够提高知识抽取和知识推理等任务的准确率和置信度。目前,电子战领域尚无公开的语料库,这也成为了电子战领域知识图谱构建的难题之一。鉴于此,提出了一种基于领域本体的电子战领域语料库构建方法。试验结果表明,该方法可较好完成语料库构建工作,有助于电子战领域的知识体系梳理及语料库建设,可为电子战领域知识图谱构建提供支撑。
0 引言
电子战领域指涉及使用电磁能、定向能和水声能等技术手段,确定、扰乱、削弱、破坏和摧毁敌方电子信息系统与电子设备, 确保己方电子信息系统与电子设备的正常使用而釆取的各种战术技术措施和行动的专业领域。电子战作为现代战争重要的作战手段,其数据资源规模大且专业性强,而领域知识图谱构建能够充分利用数据资源,为电子战领域情报处理和频谱管控等提供支撑。面向知识图谱构建的电子战领域语料库指内容涉及电子战领域并且可提供知识图谱构建所需基础语料的语料库,包括经过处理的未标注和标注语料。
高质量语料库是知识图谱构建与运用的关键和基础,目前通用领域的语料库构建较成熟,学术界和工业界具备的大规模标注数据可支撑知识抽取和知识推理等知识图谱构建技术的研究与应用。但随着专业领域对挖掘数据深层关系的需求不断增强,通用型知识图谱已无法支撑专业领域智能应用,因此构建垂直领域知识图谱成为各专业领域的迫切需求。参考军事领域语料库构建方法,有助于对专业性较强的电子战领域语料库建设进行研究。周彬彬等针对军事语料实体,提出了一套统一的军事词性标记规范和军事语料标注规范,设计了一种基于军语词典的军事语料实体特征提取框架;冯鸾鸾等以维基百科中军事领域的新技术为基点采集语料,制定了一系列军事技术文本的标注规范,并通过人工标注方式构建了面向国防科技领域的技术和术语语料库。以上研究虽然表明利用自动标注方法构建高质量大规模语料库是可行的,但由于不同领域的语料库和语料库构建方法具有其领域特性,使得这些方法难以移植到电子战领域知识图谱构建中,因此需构建电子战领域语料库以进行面向知识图谱构建与研究。
针对现有研究并面向知识图谱构建的语料库建设需求,本文提出了一种基于领域本体的电子战领域语料库构建方法(本文方法)。设计了电子战领域知识本体,明确了领域知识的边界和层次结构;设计了基于领域词典的电子战领域源生数据获取方法,将从互联网爬取的电子战领域新闻、百科词条和学术论文等非结构化文档作为条令条例、理论著作和战例想定等现有文本资料的补充;根据领域本体设计标注体系,通过标注少量高质量语料形成种子语料,并通过自动标注算法迭代获取更多的标注语料,实现了电子战领域语料库建设以及语料库统计分析。
1 总体框架
语料库建设包括以下2个步骤:1) 源生数据建设:包括原始文本资料获取和原始语料生成;2) 数据资产建设:包括种子语料人工标注和联合语料自动标注。需说明的是,原始文本资料来源于互联网中电子战相关的学术论文、百科词条和新闻等公开资源,而领域本体构建用于指导数据资产建设。语料库构建方法总体框架如图1所示。
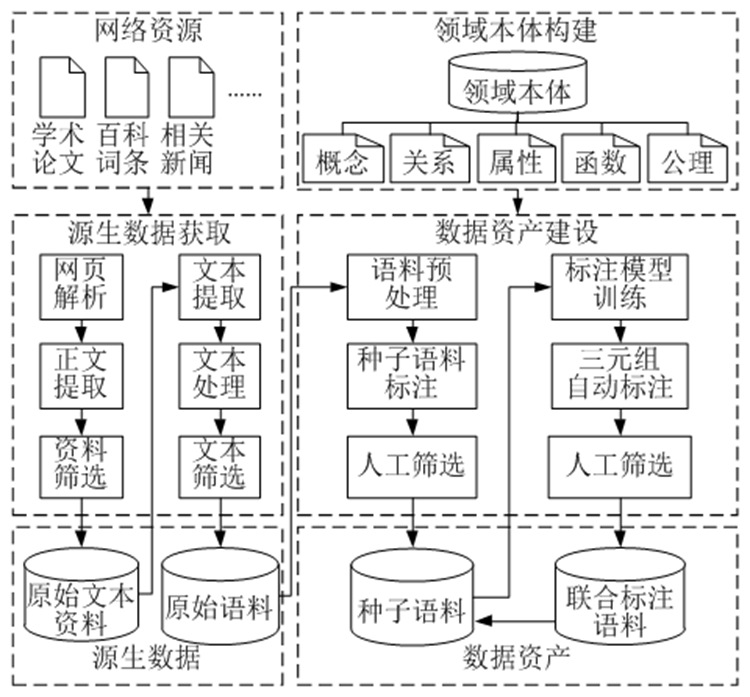
图1 语料库构建方法总体框架
语料质量是语料库构建的关键,低质量语料会对下游任务产生负面影响,因此从采集到形成数据资产的整个生命周期中均需保证数据具有较高质量。为确保数据在每个步骤中的可用性、一致性、完整性、合规性和安全性,需对数据的基本信息、状态和关联关系等进行管理。数据资源管理框架如图2所示。
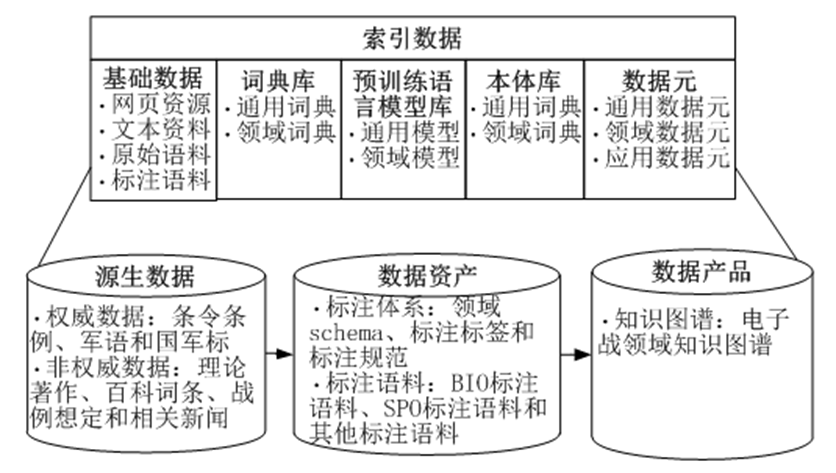
图2 数据资源管理框架
2 电子战领域本体构建
电子战领域本体是对电子战领域概念的一种描述,是该领域内公认的概念集合。由于知识具有显著的领域特性,因此领域本体可更合理而有效地进行知识表示。将本体方法融入语料库构建过程,建立电子战领域知识体系,明确语料库包含语料的边界、分类和层次结构,形成统一的电子战领域语料标注规范,从而确保语料库建设的一致性和规范性。
2.1 本体构建方法步骤
目前,本体构建尚无统一标准,现有本体构建方法依据涉及的领域和具体工程而不同。经典的本体构建方法包括数据建模集成定义(IDEF5)法、七步法、多伦多虚拟企业(TOVE)法、骨架法、Methontology法和五步循环法等。本文参考七步法的原则进行本体设计,并根据实际需求适当简化。图3给出了采用统一建模语言(UML)描述的电子战领域本体构建步骤。
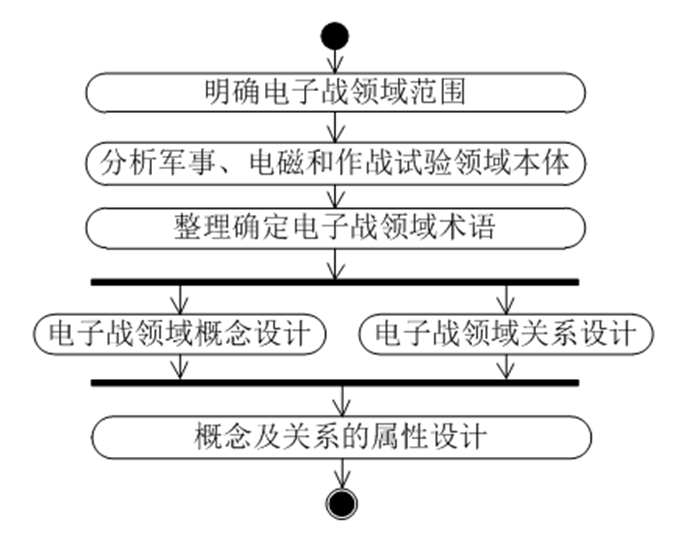
图3 电子战领域本体构建步骤
2.2 电子战领域本体内容
电子战领域本体包括领域内的概念、关系、属性、公理和函数。由于原始资料主要来源于互联网新闻,语料中蕴含的知识偏向于领域实体间的相互作用,因此本文根据性质和功能对电子战领域概念和关系进行了分类。图4给出了概念关系分类示例。
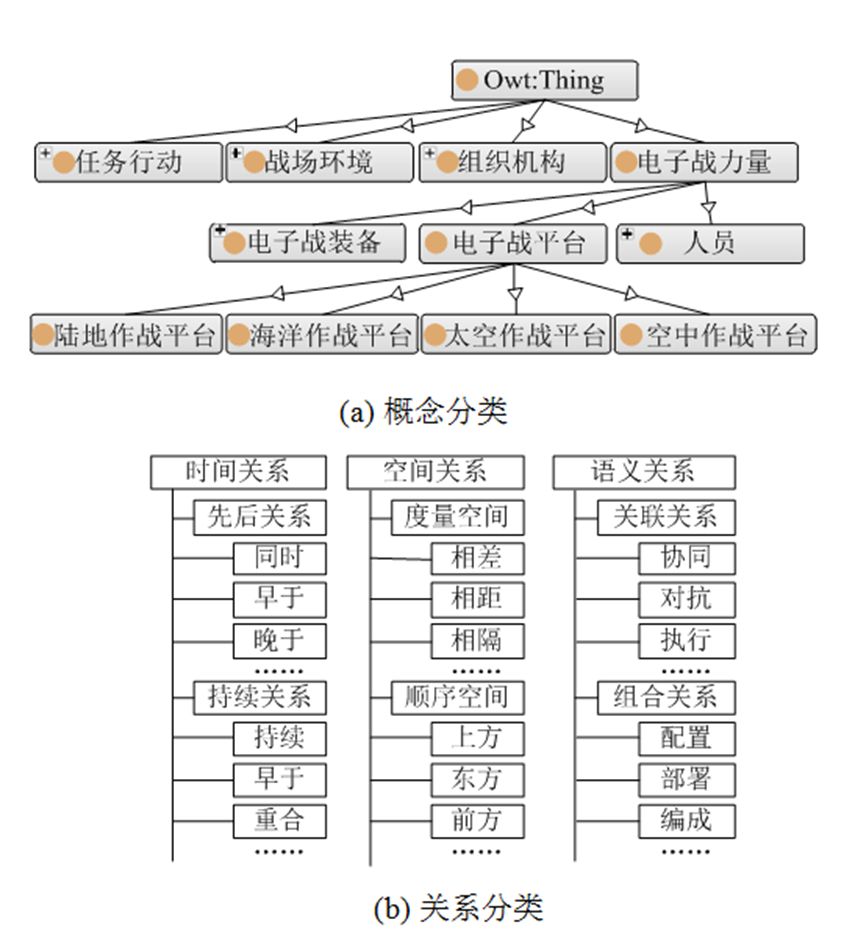
图4 概念关系分类示例
3 基于schema的电子战领域语料标注
电子战领域源生数据主要包括条令条例、理论著作和战例想定等内部资料,以及互联网上的专业文献、百科词条和相关新闻等,语料来源复杂且质量难以保证,为了构建电子战领域语料库,需设计一种既能减少人工标注又能保证标注精度的语料库构建方法。图5给出了采用UML描述的语料库构建方法框架。
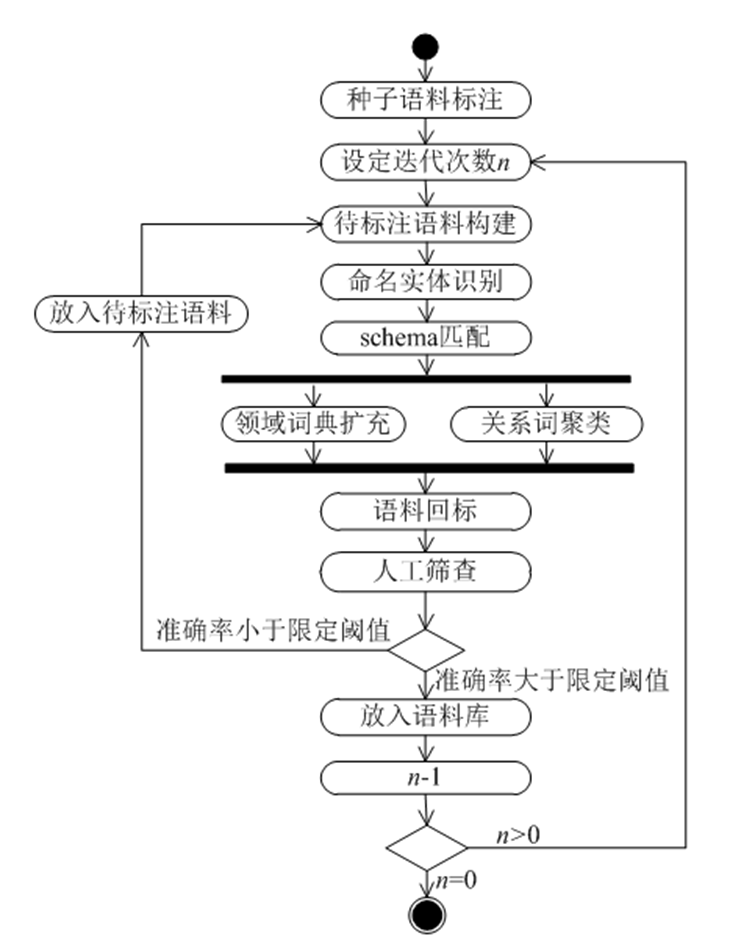
图5 语料库构建方法框架
3.1 标注体系设计
3.1.1 电子战领域关系schema构建
开放知识实体关系数量庞大,难以穷举所有实体关系类型,而领域知识通常具有清晰的层次结构和关联关系,因此可通过构建关系schema(关系模式,也称关系本体)的方式提高知识抽取精度。选取任务行动、战场环境、人员、电子战平台、电子战装备和组织机构6类实体的一级和二级概念,以及属性和属性值2种实体类型,作为电子战领域关系schema的8类候选实体类型。其中,人员、电子战平台和电子战装备3类二级概念属于一级概念作战力量,其他均为一级概念。选取协同、对抗、编成、执行、部署、配置、操作、对应和包含9类三级关系作为候选关系类型,根据构建的领域本体,共构建16种领域关系模式。电子战领域关系schema如图6所示。

图6 电子战领域关系schema
3.1.2 标注标签
为平衡知识抽取精度和人工标注的工作量,按照专业性较强、实体关系类型丰富和文档置信度较高等原则,选取部分专业文献、百科词条和新闻作为种子语料进行人工标注。标注体系采取实体BIO(B: begin,开始;I:inside,内部;O:outside,外部)标注,标注工具采用开源工具LittleAnn。标注标签设计应与电子战领域schema保持一致,同时加入属性和属性值2种实体标签用于实体属性标注。本文设计了组织机构(ORG)、电子战平台(PLF)、电子战装备(EWE)、任务行动(ACT)、战场环境(ENV)、人员(PER)、属性(PPY)和属性值(VAL)8类实体标注标签用于种子语料标注。
3.2 两阶段自动标注模型
为了确保知识抽取的精度,需要大量的标注语料训练模型,若采用人工标注则费时费力,因此本文设计了一种基于schema的自动标注方法来迭代训练模型,从而逐步提高模型精度。该方法采用pipline方式对实体关系进行标注,即先进行实体标注,再根据实体标注结果标注实体间关系。该方法便于人工检查标注结果,减少误差传递。
3.2.1 命名实体识别模型
由于种子语料规模较小,本文采用双向长短时记忆网络+条件随机场(BiLSTM+CRF)作为基础模型,并通过预训练领域词汇增强嵌入来提高模型在任务中的表现。实体标注模型如图7所示。
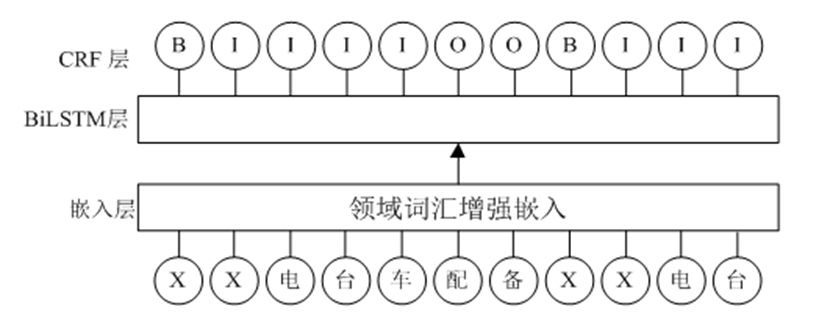
图7 实体标注模型
模型输入为 Word2vec预训练后的向量表示,中间层为能够捕捉长距离依赖和上下文信息的BiLSTM模型,并通过CRF层进行模型微调和标签约束。模型训练中,通过神经网络的反向传播不断更新模型中的所有权重和偏置项,使损失函数达到最小值,从而提高模型的标签预测效果。该模型对计算资源要求低,且训练速度比bert等大型预训练语言模型快,更适用于语料库构建的迭代过程。
3.2.2 关系模式匹配
为提高模型迭代效率,并确保标注精度,在语料库构建过程中采取构建关系触发词典的方法识别实体关系并进行关系标注。关系标注步骤如图8所示。
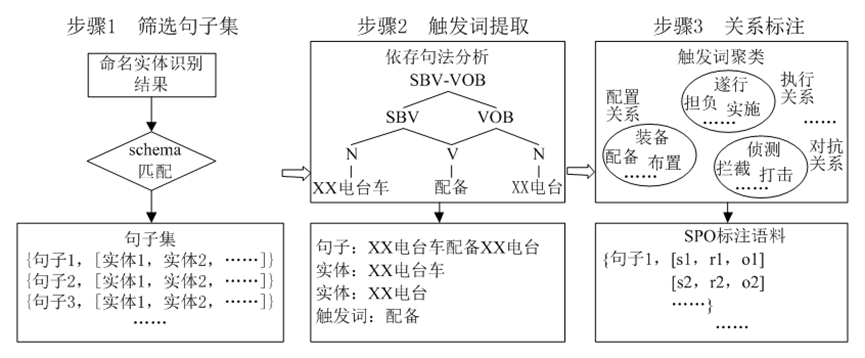
图8 关系标注步骤
首先,通过关系模式匹配筛选包含schema中实体对的句子;然后,通过依存句法分析提取句子中的触发词,对触发词按照schema的关系类型进行聚类;最后,经过筛选的实体关系对在原文中进行三元组标注,形成联合标注语料,并通过人工筛查后存入语料库供下游任务使用。需说明的是,由于相同实体对间不同的关系具有不同的触发词,因此将具有相同含义或用法的特征词聚集起来表示同一种关系类型可较好识别实体对间的多元关系。
4 语料库实现及质量分析
为了说明电子战领域语料库极其构建方法的可用性,对语料库的数据来源、语料篇数、句数以及实体关系数量及分布等信息进行统计分析,同时设计了知识抽取试验来验证语料库的应用效果。
4.1 语料库信息统计
语料库信息统计如图9所示。原始资源信息包括专业文献、百科词条和领域新闻等,其中专业文献通过线下收集,百科词条和领域新闻从8个网站通过网络爬虫采集,共抓取网页1万余个。经过去重和筛选,共获得文本资料5 297篇,占用空间资源60.1 MB。网络资源来源统计如图9(a)所示。
原始文本资料经过数据清洗和分句,去掉长度超出设定范围的句子,共获得未标注的原始语料35.4 MB,初始标注种子语料200篇,包括专业文献及理论著作50篇、百科词条50条以及领域相关新闻100篇,共有长句1 827条,标注实体8类共324个。随机选取17.7 MB原始语料进行标注,经过5轮迭代构建三元组标注语料,按照精确率P、召回率R和综合指标F1评分对实体与关系标注结果进行评价。实体关系迭代标注结果如图9 (b)所示。
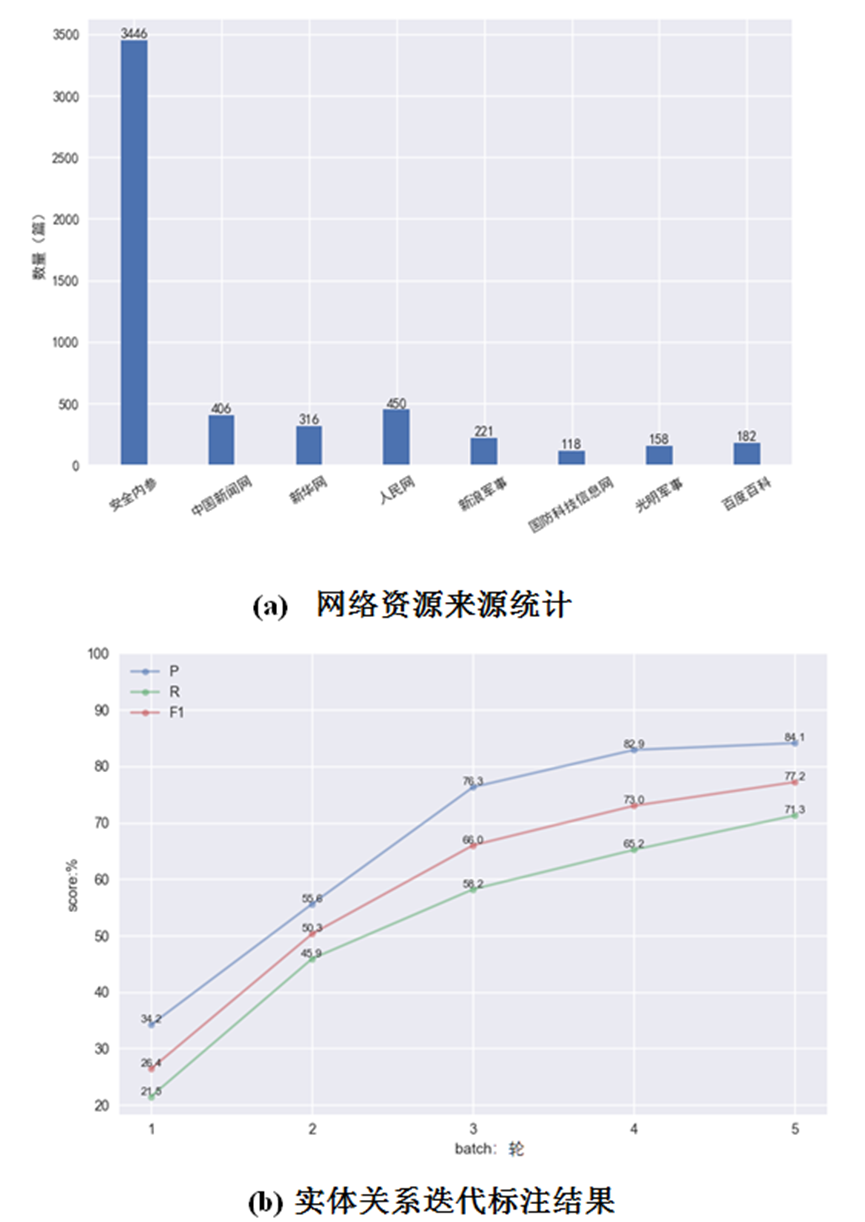
图9 语料库信息统计
由图9(b)可见,初始自动标注精度和召回率较低,均低于50%,通过迭代标注,P、R和F1评分均呈上升趋势,5轮标注结束后,最终实体关系标注精确率达到84.1%,召回率达到71.3%。
标注完成后,获得专业文献、百科词条和领域相关新闻3类文档。语料统计信息如表1所示。
表1 语料信息统计表
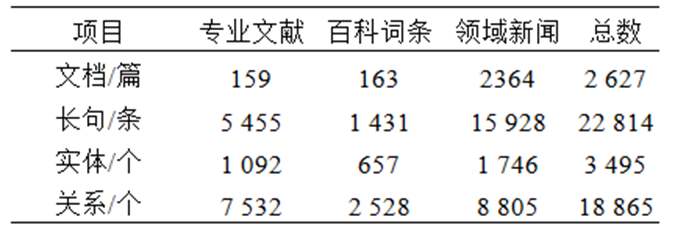
图10展示了实体及关系样本分布统计。由于数据来源不均衡,而领域相关新闻类文本资源是数据来源的主要部分,其实体及关系也呈现不均衡分布。
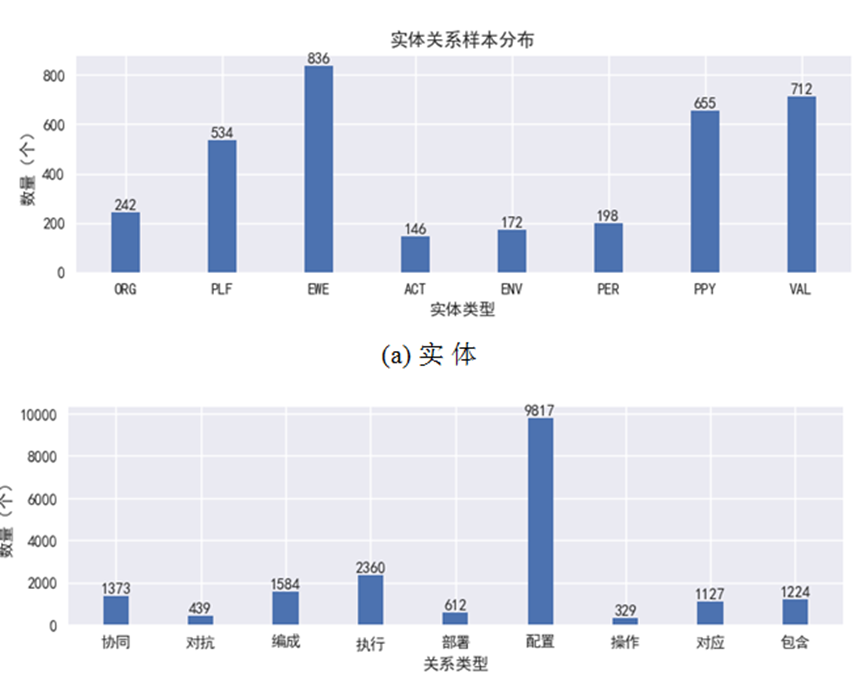
图10 实体及关系样本分布图
4.2 语料库应用效果
从下游任务看,面向知识图谱构建的电子战领域语料库在知识图谱构建相关的命名实体识别、关系抽取、属性抽取和知识推理等任务具有应用价值。本文通过知识抽取任务来验证语料库的运用效果,从电子战领域语料库中随机选择1 300篇标注语料作为知识抽取任务数据集,命名为EwIE,按照8∶2的比例划分训练集和测试集,同时选取DuIE2.0和CMeIE数据集作为对比。数据集统计信息如表2所示。
表2 数据集统计信息

关系抽取任务的基线模型采用CasRELTrans模型,即采用Transformer的编码层作为CasREL框架的编码端。模型参数设置如下:1个批次的样本数为128,学习率0.000 5,优化算法采用Adam,迭代次数设置为600,Transformer中隐层大小设置为128,注意力头为8,层数为1。选取P、R和F1作为评价指标,CasRELTrans模型在3个数据集上的表现如表3所示。
表3 CasRELTrans模型在3个数据集上的表现
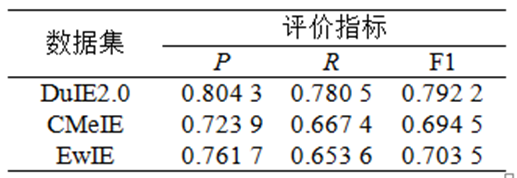
试验结果表明,同一模型在DuIE2.0、CMeIE和EwIE数据集上的表现不同。分析关系模式数量和语料规模对试验结果的影响如下:DuIE2.0和CMeIE数据集具有相近数量的关系模式,但前者的语料规模远超后者,模型在DuIE2.0数据集上取得了更好的效果,这体现了大规模和高质量的标注语料仍然是神经网络模型发挥性能的重要条件;比较EwIE和CMeIE数据集,前者语料规模低于后者但关系模式的数量更少,模型在EwIE数据集上效果更好,这表明设置的领域关系模式越简单越容易得到更好的效果,复杂关系模式则需要更大规模的训练语料作为支撑。
上述试验表明,构建的电子战语料库应用效果良好,从而验证了本文方法的可行性。与现有成熟的大型语料库相比,电子战语料库还需进行以下2个方面的改进:1) 语料规模扩充:需不断采集和标注新的语料;2) 关系模式细化:粗粒度的关系模式设计可确保用较少的种子语料获取较好的标注效果,但在知识抽取过程中会损失大量信息,而采用较细粒度的关系模式可获取更丰富的知识,从而使构建的知识图谱包含更多信息,满足更复杂的应用需求。后续需重点研究对上述问题的改进措施,从而提高电子战领域语料库的应用价值。
5 结束语
本文提出了一种基于领域本体的电子战领域语料库构建方法,构建了电子战领域本体,通过将领域本体融入语料库构建过程,提出了电子战领域语料标注规范,并设计了一种基于schema的自动标注方法,完成了面向知识图谱构建的电子战领域语料库建设。以电子战语料库为基础,可进行电子战领域知识抽取和知识推理等任务的研究,同时又可将其作为电子战领域语料采集的种子库,通过不断迭代来扩展语料库规模,从而提高应用价值。本文方法可应用于其他领域语料库构建,具有应用前景。
声明:本文来自防务快讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
