提示工程(Prompt Engineering,也称为In-Context Prompting)指在不更新模型参数的前提下、通过输入文本等方法来操控大型语言模型(Large Language Model)以指导其行为、引导其生成我们需要的结果的方法。提示工程是普通用户与大模型进行交互的方法,聪明的掌握提示工程技巧能够最大限度的发挥大模型的优点而规避其弱点,从而让大模型转化为真正有效的生产力。随着生成式人工智能的发展,普遍认为提示工程将是一门特别有前景的技能,甚至将会成为一个新兴的人机交互职业。法律科技公司CaseMark近期开放发布了一个法律提示语技术工程指南,我们对该指南进行译介,以供国内探索大模型在法律领域的深度应用时进行参考分析。
1 法律提示语技术工程导论
(一)提示语在人工智能中的作用
提示语技术工程是指为引导人工智能工具提供最佳答案或结果而设置的智能且高效的问题或“提示语”。ChatGPT等大型语言模型(LLM)是经过大规模文本数据的训练而构建的人工智能系统,能够根据提示语生成类人文本(human-like text)[1]。可以将其视为一个博学多才的朋友,当你向他提问时,你的问题设置得越好,他们的回答就会越精准。
一个精心制作的提示语可以使得人工智能的工作更加简单,同时输出的内容相关性更高。举一个例子,当你想要路线指引时,你对地点的描述越具体和清晰,你才会更有可能到达目的地。而在人工智能的环境下,当你所设置的问题提示语越具体和清晰,人工智能才能给出更精准的回答。
本指南主要强调提示语技术工程的三个基本规则:
(1) 清晰度:提示语应该表述清晰,不产生歧义;
(2) 具体性:提示语越具体,人工智能的回答更具有针对性。
(3) 上下文语境:提供语境信息有助于人工智能更好地理解提示语,尤其是在复杂任务中。
(二)法律提示语技术工程
法律提示语技术工程(LPE)是一项专业技能,已经受到全球律师事务所的追捧。为了弥补当前生成式人工智能的不足之处,法律提示语技巧要求提示的编撰者具备更精准的表达和更高超的技巧。
法律是一门依赖非结构化数据文本的知识密集型领域[2]。ChatGPT等大型语言模型有望通过设计文本生成、摘要、问题回答等方式来颠覆这一领域。
(三)ChatGPT提示中的常见误区
当我们使用人工智能时很容易进入某些误区,而导致无法获得最好的结果。本节重点讨论许多专业人士在使用ChatGPT时提示语中的常见误区,并提供避免这一问题的针对性建议。
目前,大多数人在ChatGPT中使用模糊且简短的提示语,并且缺乏上下文背景信息,提示语示例如下:
Draft an operating agreement for a private trust company domiciled in Georgia.
(为一家在乔治亚州注册的私人信托公司起草经营协议)
多数人看到这个提示,可能会说:“这个提示语有什么问题?我觉得很好。它甚至遵循了清晰度的基本规则!”
上文列出的三条基本规则:清晰度、具体性和上下文语境,三者并非互相排斥关系。为引导人工智能生成更好的结果,在编写提示语时,尽量满足所有规则。让我们分析上述示例提示语的问题:
1. 问题1:缺乏具体性
这个提示语缺少能够给出更精准结果的关键信息,具体分析如下图1显示:

图1:关于示例提示语缺乏具体性问题分析图
译者注:图1中完善建议第一点,增加关于合同内容的详细范围,以此明确合同撰写的范围是针对成员管理层面或者经理管理层面,使得合同权利义务部分更加清晰。同时也建议更加精准的表达地点信息。对于地点信息的准确性的表达会涉及合同履行、争议管辖或法律选择等问题的判断。
当然,上述示例中添加的信息并非十分详尽,如果要获得更好的结果,所提供给人工智能的指导或提示语越具体,效果就会越显著。
2. 问题2:缺乏上下文语境
信托公司的存在是为了作为指定的受托人来管理信托合同,然而上述的示例表达中并未提及任何关于信托合同的类型,是属于资产类型信托或其他类型。
以下是修改后的示例提示语,添加了相关背景信息以改善大型语言模型生成的结果,详见图2:

图2:关于示例提示语缺乏上下文信息的修改图
通过修改提示语去增加额外的上下文语境信息,本质上是为了大型语言模型生成更好的回答。ChatGPT等大型语言模型可以被看作是非常先进的文本预测机器,它们的工作原理非常简单。它们是基于之前出现的词语去猜测下一个词。例如,如果你说:“我要去杂货店买一些...”,人工智能可能会猜测你要说的是“牛奶”或“面包”。
当你提供给这个人工智能的信息越多,它的猜测就会越准确。这就是我们所说的“上下文”。比如你说:“我要做一个三明治,除了一个配料,其他都齐了。我要去商店买一些...”现在人工智能可以更好地猜测,因为它知道你要做三明治。
因此,当我们提供更多的上下文语境信息时,人工智能的回应会更精准。它们的回答会与我们所提出的问题更相关,提供更为详尽的信息,更一致地围绕问题话题展开,并更有效地处理复杂问题。
综上所述,当你向大型语言模型提供更详尽的上下文语境信息时,你会得到:
(1) 更相关的回答:人工智能模型更好地理解你的问题,因此能够生成与你需求更密切相关的回答。
(2) 更具体的回答:有了更多上下文语境信息,人工智能有更多信息可供参考模型,因此能够生成更具体和详细的回答。
(3) 高度一致性:更多上下文语境能帮助模型在较长的对话或文件中保持一致性,确保生成的文本在逻辑上与先前内容连贯。
(4) 更有效地应对复杂问题:复杂的问题或任务通常需要大量上下文。有了更多上下文语境信息,人工智能模型能更有效地处理这些情况。
然而,虽然通常情况下更多的上下文语境信息提示语会带来更好的回答,但是提供语境时的重要之处在于保持清晰和简明。如果提供不必要的信息,可能导致模型的回答变得模糊不清。最后,一个关键的要点是,大型语言模型不能像人类一样真正理解人类的上下文语境。它们是通过利用在数据训练中获得的模式来生成回应。
3. 问题3:产生幻觉
在我们最初的提示语示例中存在一个根本性的问题,详见图3:
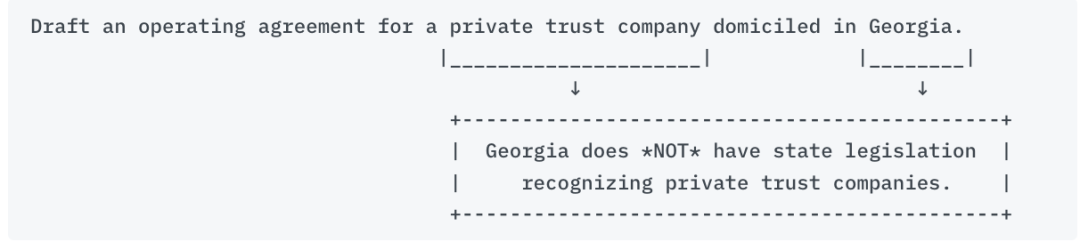
图3:描述示例提示语的问题图
美国私人信托公司的创建仅限于少数几个州,这些州已通过正式的州法规承认这些法律实体,而乔治亚州并不在其中。这意味着无法在乔治亚州创建私人信托公司。
然而,人工智能没有提醒我们这一事实,而是继续生成运营协议。在大型语言模型和人工智能领域,这种现象被称为“幻觉”。它指的是人工智能生成的信息看似可信,但实际上是虚构的或没有事实依据。
可以简单地理解为:当你询问朋友当前的天气,尽管他们并未看窗外,他们却自信地回答说外面是晴天。这是他们根据昨天的晴天状况做出了合理的猜测,但如果天气发生了改变,他们的猜测就可能不准确。这与人工智能“产生幻觉”的现象类似,而在法律领域可能会产生严重后果。幸运的是,有方法可以解决这个问题,以确保人工智能不会“产生幻觉”。这正是我们示例提示语所面临的问题。
4. 问题4:缺乏结构
通过在提示语中添加一些结构,我们可以看到大型语言模型的回答会有显著改进。我们将这些结构称之为提示语模板,它们是由各种的形状和大小。其中最常见的模版之一我们称之为“提示三明治”,详见图4:
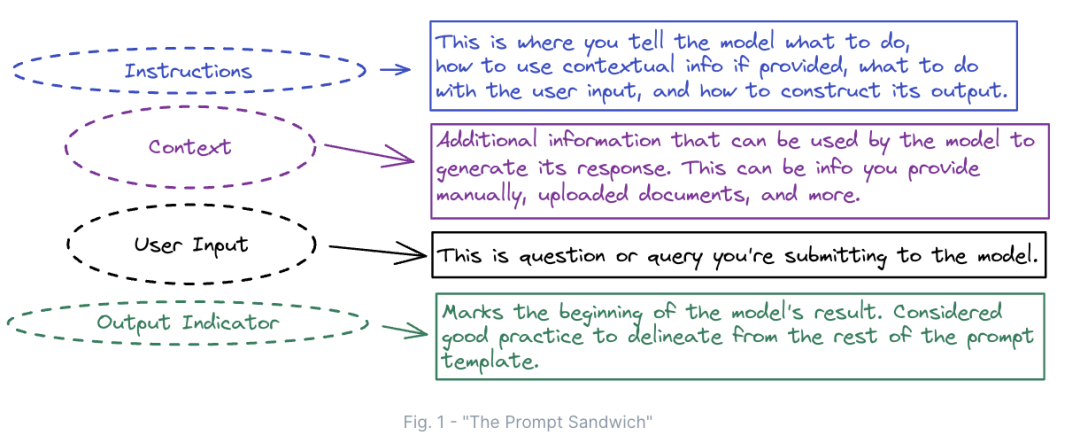
图4:“提示三明治”—提示语结构图
以这种冗长的方式制作提示似乎有点麻烦,但结果是完全值得的。让我们看一下如何使用这个模板来重写最初的示例提示语,详见图5:

图5:通过“提示三明治”结构化提示语示范图
现在增加额外的提示语看起来比之前更好。不仅结构更清晰,而且这个提示语也会获得更准确的结果。将这个提示语提交至ChatGPT,我们会收到正确的回答:
“I cannot complete this request due to regulatory uncertainty.”
(“由于监管的不确定性,我无法完成这个请求”)
如果将提示语中的司法管辖区更改成法律上承认私人信托公司的州(如内华达、怀俄明等),模型将使用我们所提供的上下文信息生成更准确的结果。
上述是一个快速示例,旨在展示如何通过使用简单的技巧产生更大的效益。在下一章中将介绍更多的提示语的技巧以发挥ChatGPT的真正潜力。
2 法律提示语技术工程应用的策略与技巧
提示语是提供给模型所输入的文字,比如问题、命令或上下文等信息。这些提示语对于模型输出的质量、相关性和准确性有着重要的影响,因此需要经过慎重和具有策略性的设计。
(一)常见提示语建议、窍门和技巧
1. 技巧1:巧妙利用语境
上下文语境是帮助大型语言模型理解任务、目标和用户期望的信息。语境可以包括指示、示例、关键词、格式、语气等等。让我们看一个下图6的例子:

图6:增加语境信息的示范图
修订后的提示语包括指示模型生成何种类型的文本(摘要),摘要应该有多长(不超过3句),应包括哪些信息(姓名、问题、结果),以及应该避免什么(观点、无关的细节)。这种表述有助于模型专注于任务并生成关联性高且简洁的摘要。
2. 技巧2:提供示例
常见的技巧是向人工智能模型提供示例,向其演示你所期望的输入-输出格式或行为。我们将这种技巧称为“少量示例提示法”。如果你向模型提供一些示例,模型可以将其用作生成结果时的参考。当你提供的示例是真实场景时,这个方法所获得的结果会变得非常有效。你可以将这种方法视为快速训练大型语言模型如何执行特殊任务。让我们看一下如何排版你在提示语中的示例。
首先,假设你向其提供一份法律文件,并希望它根据文件提供特定问题的答案,下图7为如何制作该提示语的操作示例:

图7:提供示例排版示范图
现在,如果您将上述示例复制并粘贴到ChatGPT中,您会看到一个与之前的回答格式相同的回应:
The name of the amendment allowing the right to own a firearm is the Second Amendment.
在本章的第三节“少量示例提示法”中,我们将深入探讨这一技术如何应用于不同的提示语中,以完成不同的任务。
3. 技巧3:使用强动词[3]
提高 ChatGPT 提示语的方法之一是使用强动词。因其相对于弱动词而言更具体、清晰和简洁。它们可以帮助人工智能防止生成模糊、消极或无关的回应。
下图8是关于如何在提示语中使用强动词的示例:

图8:使用强动词的示范图
4. 技巧4:避免幻觉
在上一个章节中我们已经提到关于人工智能的幻觉问题。大型语言模型的幻觉是指语言模型生成的文本流畅,但事实上是不正确或不一致的。而产生这种情形的原因可能是因为所提供给它的请求,它并没有足够的信息或知识去进行回答。有一些简单的方法可以避免幻觉的发生。其中最简单的方法是调整提示语。下图9是微调提示语的示例:

图9:微调提示语的示范图
通过在提示或上下文中加入简洁的声明,可以避免许多问题。这样一来,我们告诉模型,如果它不了解答案或没有相关信息,就不要履行请求。这种方法降低了大型语言模型产生幻觉的风险,同时提高了生成文本的质量和可靠性。
在本文的第三章会讨论如何防止幻觉的其他技术。
(二)提示语模板
在本文的第一章,我们介绍了提示语模板——“提示三明治”,并示范了如何在ChatGPT中使用这种结构来取得更好的结果。在本节中,我们将深入探讨如何在不同语境中使用其他提示语模板以获得更出色的结果。
常见任务类型模板:
1. 摘要(Summarization)
像ChatGPT这类大型语言模型非常擅长总结信息。为了充分发挥其处理大量文本并进行总结的能力,您可以提供一个模板。这个模板不仅要详细说明您所需的格式,还应为所需的信息预留一定的位置,并使用特定的标记或符号进行提示[4]。
下图10是关于概述1933《证券法》的一个基础提示语示例:

图10:基本提示语示范图
当我们发出这个请求,ChatGPT在生成一个可读且信息丰富的摘要方面表现出色。下图11为ChatGPT的回应:

图11:ChatGPT针对概述请求的示范图
如何才能让ChatGPT生成更好的摘要?我们可以采用更完善的提示模板,明确要求人工智能了解您所关注的特定信息类型(如日期、人物等)、格式偏好和所需长度等。让我们看下图12的示例:

图12:在图11的基础请求上使用模版的示范图
下图13为使用模板后的回应示例:

图13.1:使用模板后的回应示范图

图13.2使用模板后的回应示范图

图13.3使用模板后的回应示范图
这个提示语模板中有很多内容需要理解,但是请不要回避使用奇怪的语法。这种语法被称为“Markdown”,其用于调整原始文本中的标题、列表以及您在 Microsoft Word 和 Google Docs 中常见的其他元素的布局、样式和结构等格式。使用Markdown语法有助于引导人工智能模型以规定的格式生成响应,还允许您在其中嵌入指示,下图14是一个举例关于我们请求为每个部分生成的关键字、人物和事实列表:

图14:使用Markdown语法输入请求示范图
我们鼓励您修改此模板,看看是否可以根据您的具体案例获得更精确的摘要。例如,如果你的律所更喜欢以特定的方式起草案卷或法律分析,比如包括特定信息的格式和标准,请修改提示语模板并观察 ChatGPT 的回应。请记住,提示语技术工程是一个迭代过程[5]。
2. 分类(Classification)
大型语言模型(LLM)在文本分类任务方面表现出色,能够将文本分至特定的类别中。您可以向人工智能模型提供一个已选的类别列表(或让模型自行生成类别),同时提供待分析的内容。文本分类在各种领域都有广泛应用,包括欺诈检测、情感分析和内容监控等,因此对法律专业人士来说具有重要意义。
案例:人身伤害案
我们与多家专注于个人伤害领域的公司合作,他们花费大量时间制作医疗年表报告[6]和医疗摘要[7]。让我们设想一下,我们想要创建一个提示语,该提示语能够从病患的健康记录中识别出病患的诊断结论,这一诊断信息来自病患因事故在急诊室就诊后的出院记录。这是一个相对简单的分类问题。让我们下图15,如何使用以下提示语模板来实现这一目标:

图15:使用分类提示语模版的示范图
可以看到,上述案例示图利用了本指南中已经提供的技巧,创建了一个具有三个不同部分的提示语。首先输入一个指令提示语——识别患者的诊断结论。然后,嵌入了两个示例,该案例演示我们对人工智能模型预期的医学摘要类型。最后一个部分是我们的输入,包括医学摘要和输出分隔符—诊断。将这个提示语输入ChatGPT会返回结果:“脑震荡”,如下图16所示:

图16:分类提示语输入ChatGPT后生成的回应图
3.提炼(Extraction)
大型语言模型还可以有效地从大量文本中提炼信息。包括但不限于以下提炼提示语的常见案例:
(1)信息检索:从大型数据集或复杂文档中提取特定信息,如识别法律文件中的关键术语、短语或章节。
(2)专名识别(NER):又称为命名实体识别,指的是从文本中提取特定意义或者指代性强的实体信息,如人名、组织、地点、日期等。
(3)事件提炼:从给定文本中识别和提取关键事件、参与者等等。
案例:公司组织结构图
区块链行业最近经历了一系列动荡事件,其中最为著名的便是FTX的破产。FTX曾是备受瞩目的加密货币交易所和对冲基金管理公司,于2022年11月申请破产。更具体说是FTX及其100多个子公司均宣布破产。难以想象,破产律师需要付出多大的努力来梳理清楚所有这些公司之间错综复杂的关系,使得人们能够更容易理解...
使用ChatGPT可以更快速的解决这个问题,下图17为示例提示语模板,演示了如何执行命名实体识别(NER)以编制组织结构图:

图17:使用提示语模板执行专名识别请求示例图
上述为编造的案例,但是演示了我们可以引导ChatGPT来提取特定类型的信息以及附加的元数据[8]。在上述示例图中,我们不仅要求列举文本中提到的所有公司实体的详尽清单,还希望了解这些实体之间的关系。下图18为在ChatGPT中使用这个示例提示语的回应:
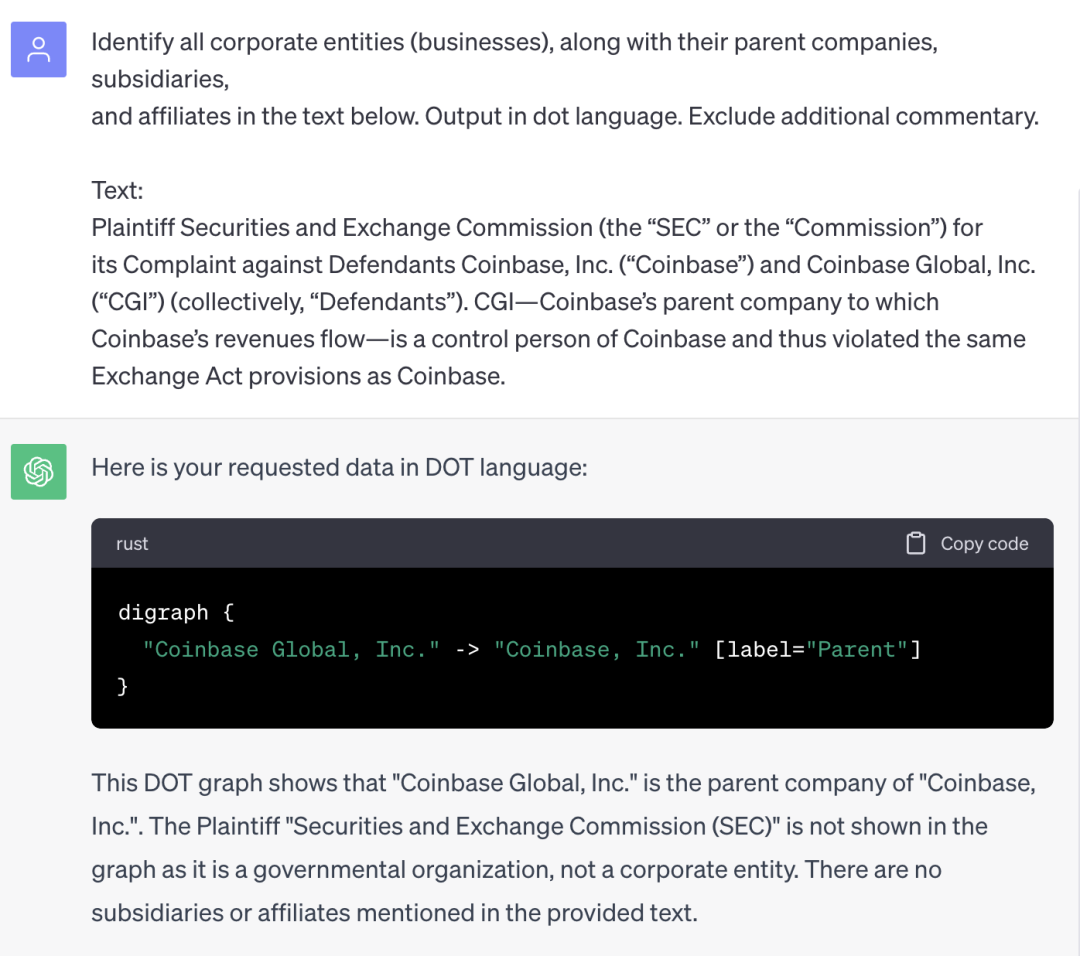
图18:ChatGPT执行专名识别请求的回应图
我们将在第三章中详细讨论“输出解析器”。在上面的示例提示中,我们为ChatGPT提供了具体的指令— 以Dot语言[9]输出。ChatGPT使事情简单明了,它能输入文本,并输出文本。然而,许多用户可能不了解的一点是,我们可以要求ChatGPT返回不同类型的文本,包括具有特定语法含义的文本,以及代表计算机编程语言等的文本。在这个示例中,我们主要关注的是生成某种组织结构视觉图。因此在这个提示语中,我们要求ChatGPT以Dot语言提供其响应(Dot语言用于生成视觉图表,将在第3章中详细介绍)。随后,我们可以使用ChatGPT提供的Dot语言回复来生成类似下面图19的图像:
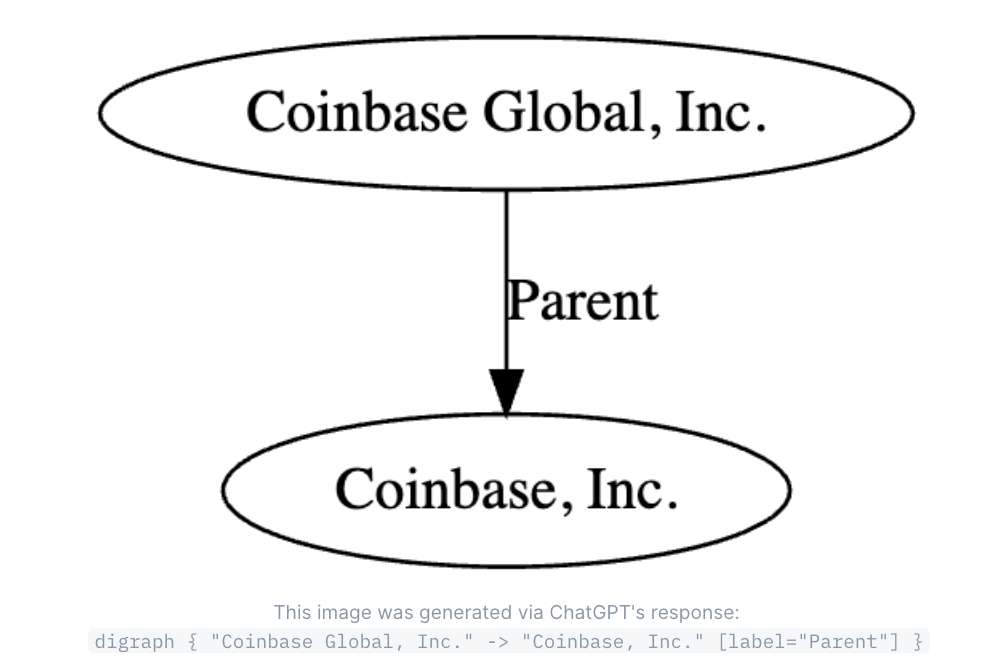
图19:使用Dot语言生成的视觉图
提炼提示语可以被律师事务所广泛使用,以解决各种不同的问题。在下一节中,我们将提供一个使用少量示例提示法的示例来演示简化无数律师和律师助理不喜欢的常规工作过程。
(三)少量示例提示法
人工智能专家们已经对如何从大型语言模型中获得更好的结果进行了大量研究。其中,他们花很多时间研究了一个观点——在提示语中提供一些示例是否能够帮助指导大型语言模型更好地理解其需要执行的任务。
研究人员发现,在大多数情况下,在提示语中提供示例会使得大型语言模型返回更精准的结果。在研究领域中,这种方法被正式称为“Few-shot”提示法。为使其更容易理解,我们称之为“Few-example”(少量示例)提示法。
在此之前,我们已经多次提到过少量示例提示法。这种策略某种程度上在提示技术中是通用的。让我们深入了解一些“示例”。
案例1:准备庭审
可以使用ChatGPT生成一个详尽的问题列表,用于传唤证人进行证词时提问。同时需要确保问题列表中不包含与案件无关的问题,详见下图20示例图:

图20:使用ChatGPT生成庭审问题示范图
案例2:案件摘要
通过提供ChatGPT一些示例,可以让您的法律研究、案例分析和策略更加出色。下图21为撰写案件摘要的示例,我们可以看到ChatGPT提供的响应与我们提供的示例格式相匹配的:
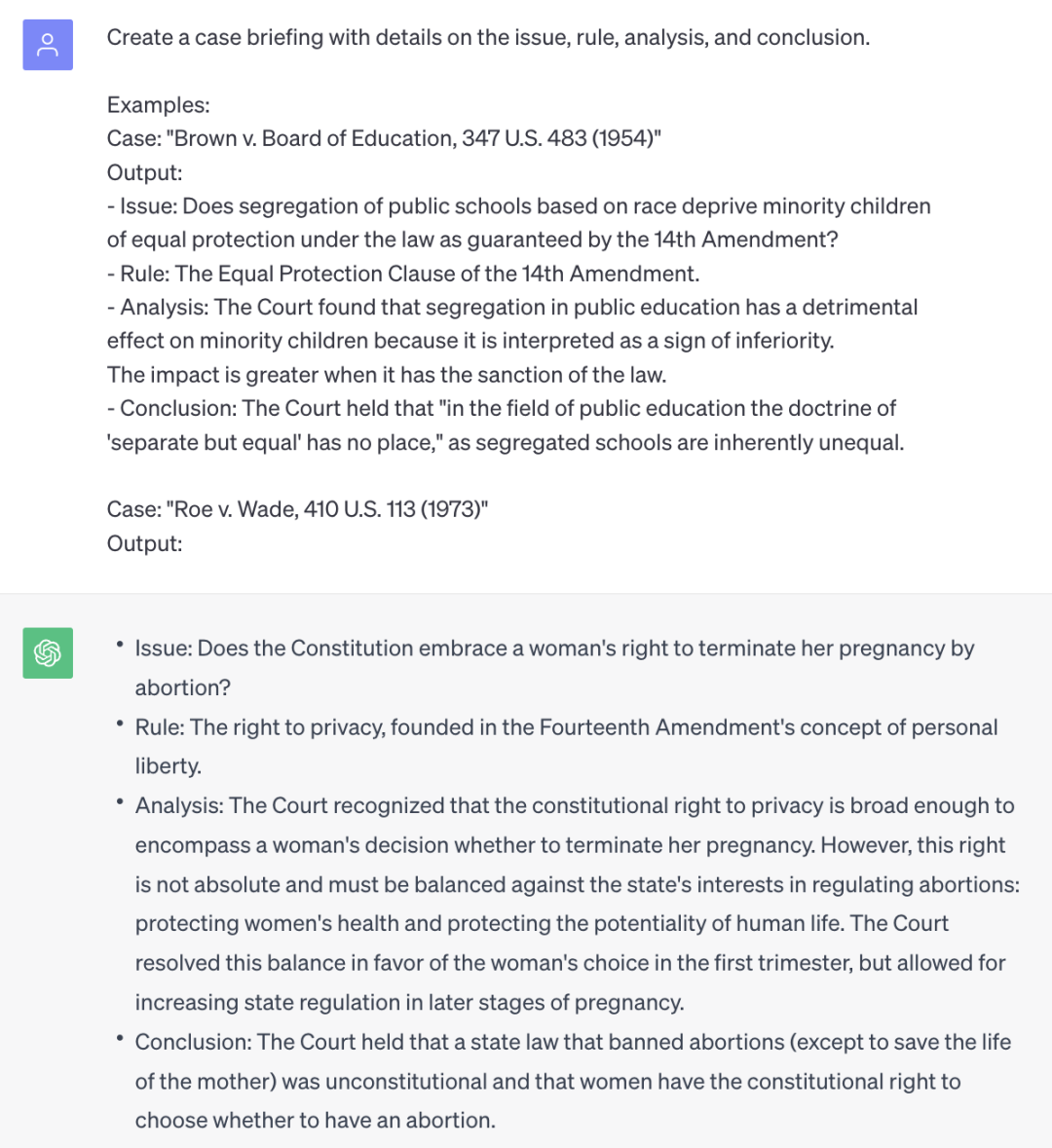
图21:使用ChatGPT少量示例法撰写案件摘要示范图
案例3:医学年表
让我们稍微变换方式,演示如何通过提供一些示例来引导人工智能模型以我们期望的格式返回响应。这个示例会涉及第3章中讨论的输出解析器(“Output Parsers”)。
许多公司选择使用电子表格来生成医疗年表报告。你可以将数据以不同的数据格式导入进Microsoft Excel(或类似的软件)。其中较常见的格式之一是逗号分隔的数值(CSV)。幸运的是,ChatGPT可以处理CSV数据。下图22是一个示例,说明如何让ChatGPT返回CSV数据,然后将其导入到电子表格中:

图22:使用ChatGPT返回CSV数据示范图
不必顾虑去解释输出中的所有引号和逗号。请参考下图23我们与ChatGPT的进一步互动,通过微调提示尝试让其生成结构化数据:

图23:使用ChatGPT生成结构化数据示范图
少量示例提示法类似于让人工智能模仿人类的学习方式,从极少的示例中进行学习。例如,当你向一个孩子展示一些狗的图片,并告诉他们“这些是狗”,他们通常可以识别以前从未见过的其他狗。但需要注意的是,尽管少量示例学习可以非常有效,但并不是绝对完美的。响应的质量可能会因提示的复杂性、提供的示例的质量和与内容的相关性,以及人工智能模型本身的固有限制而有所不同。尽管如此,少量示例法仍然是一种有价值且成本低廉的提示策略。
3 高级提示语技巧
掌握提示语技术工程需要熟知本章中将要介绍的高级提示策略和技巧。您将学会如何巧妙运用语言和提问策略来优化您的提示语创建过程,并在法律实践中取得卓越的成果。
1. 选择合适的模型和参数
提示语技术工程的第一步是为你的任务选择合适的模型和参数。不同的模型根据其结构、训练数据和目标具有不同的优点和缺点。例如,有些模型在生成流畅连贯的文本方面更为擅长,但在提取事实信息或进行逻辑推理方面表现略有逊色。另一些模型更具通用性,能够处理各种任务,但在适用于特定领域或应用的精细度层面略有不足。
要选择合适的模型和参数,需要考虑以下因素:
① 任务的类型和复杂性:确定任务的类型是分类、生成还是提取任务;是开放式或封闭式的问题;是需要具备常识、领域知识还是创造力。
② 输入和输出格式:所提供的文本类型是什么类型以及所希望的输出格式是何种类型。是句子、段落还是文档?数据是结构化的还是非结构化的?表达是正式的还是非正式的?
③ 数据的质量和数据:您有多少样本数据可以用来针对你的模型进行训练或进行精细度调整?您的数据的可靠性和多样性的程度如何?您如何处理缺失或杂乱的数据?
④ 性能和资源限制:您希望您的模型速度多快,准确度多高?您有多少计算能力和内存可用?如何平衡速度和质量?
根据上述的因素,您可能需要为不同的任务使用不同的模型和参数。例如,如果你想要生成一篇新闻文章的简短摘要,你可能想使用在大规模文本语料库进行预训练并在摘要数据集上能进行精细调整的模型,比如PEGASUS[10]或 BART[11]。如果你想要基于一些关键词生成一篇长篇故事,你可能想使用在创意写作集数据上进行训练的模型,并具有大量词汇和上下文范围情景文本,比如GPT-3[12]和DALL-E[13]。
2. 使用自然语言指令和示例
提示语技术工程的第二步是使用自然语言指令和示例去引导系统执行你的任务。自然语言指令是用以描述你想要系统去执行的句子,比如“撰写一篇名为‘高级提示语技术工程’的博客文章”或者“用三句话总结文本的主要观点”。自然语言示例是向系统示范如何执行任务的一对输入或输出文本。例如:
输入(提示语指令):撰写一篇名为“高级提示语技术工程”
输出(大型语言模型响应):提示语技术工程是为自然语言处理(NLP)系统设计的有效提示语的艺术和科学,提示语是引导系统执行特定任务的一段文本……
输入(提示语指令):用三句话总结本文的主要观点
输出(大型语言模型响应):这篇文章讨论了如何通过提示语技术工程来提高自然语言处理(NLP)系统的性能。它提供了选择合适的模型和参数、使用自然语言指令和示例、利用外部知识源和上下文,以及评估和优化提示的技巧和窍门。文章还提供了一些在不同领域中应用提示语技术工程的示例。
通过提供清晰的目标、期望和限制条件,自然语言指令和示例能够帮助系统更好地理解任务。还可以提供参考信息、模板和多样性信息来帮助系统生成相关性、关联性和一致性更高的响应。但是,对于提示语技术工程而言,自然语言指令和示例法并总是能满足要求或达到最佳状态。比如你的指令如下问题:
① 含糊不清:“写一篇关于猫的文章”(什么样的文章?猫的哪些方面?什么语调和风格?)
② 不完整:“写一首诗”(什么样的诗?关于什么话题?什么韵脚?)
③ 误导性:“写这篇本文的摘要”(如果文章太长或太复杂,如何总结?)
为了避免上述问题,你需要确认你的自然语言指令和示例满足如下条件:
① 具体:清晰明确地定义您的任务
② 完整:覆盖任务的所有重要方面和细节
③ 一致:将您的指令和示例与任务之间保持一致
④ 相关:仅提供任务所需和有用的信息
⑤ 多样:包括不同类型的输入和输出,以捕捉任务的多样性
3. 利用外部知识源和上下文语境
提示语技术工程的第三步是利用外部知识源和上下文语境信息来丰富你的提示语。外部知识源是指那些不包含在输入或输出文本中的信息来源,例如数据库、本体[14]、词典、百科全书或网页。上下文语境是与输入或输出的文本向相关的任何信息,例如作者、受众、文体、日期或地点。例如:
输入(提示语指令):
撰写一篇名为“高级提示技术”的博客文章
外部知识源:维基百科上的“自然语言处理”页面
上下文语境信息:该博客文章是为NLP爱好者网站撰写的
外部知识源和上下文语境信息可以提供额外的事实、概念、关系或观点来帮助系统生成更精准、更相关和更引人注目的回答。同时,通过核实信息的准确性、明确信息以消除不明确或模糊之处,以及引入多样化的元素,可以协助系统避免出现错误、不一致性和重复。然而,对于提示技术而言,外部知识源和上下文语境并不总是可用或可以访问的。有时,它们可能不完整、过时或不可靠,主要原因如下:
① 信息不全:维基百科上的“自然语言处理”页面未涵盖NLP的所有方面和应用
② 数据陈旧:维基百科上的“自然语言处理”页面可能无法反映NLP领域的最新研究和发展趋势
③ 缺乏可靠性:维基百科上的“自然语言处理”页面可能包含错误或偏见
为了克服上述困难,您需要确保您的外部知识源和上下文语境信息具备以下特点:
① 相关性:选择与您的任务最相关的来源和上下文
② 可信度:选择最值得信赖和最权威的来源和上下文
③ 时效性:定期更新来源和上下文以反映当前事态
④ 兼容性:将来源和上下文与输入和输出文本顺利融合
4. 评估和优化你的提示语
提示语技术工程的最后一步是使用反馈和指标来评估和优化提示语。反馈是您在提供提示语后从系统或其他用户收到的任何形式的响应或反应。指标是在提供提示语后用于评估系统性能或输出质量的任何定量或定性度量。例如:
输入(提示语指令):撰写一篇名为“高级提示语技术工程”
输出(大型语言模型响应):提示语技术工程是为自然语言处理(NLP)系统设计的有效提示语的艺术和科学,提示语是引导系统执行特定任务的一段文本……
反馈:其他用户对博客文章的积极评价
指标:博客文章的浏览量、点赞数、分享数、评论数
反馈和指标可以通过提供见解、建议或更正信息来帮助你评估和优化提示语。他们还可以通过提供学习机会、挑战或奖励来帮助提高您的编写提示语的技能。但是,反馈和指标对于提示技术并不总是可用或可靠的。有时,它们可能是主观的、矛盾的或杂乱的:
① 主观的:不同的用户可能对输出有不同的意见或偏好
② 矛盾的:同一用户可能对不同的输出有不同的反应或期望
③ 杂乱的:反馈或指标可能会受到外部因素或随机事件的影响
要处理这些问题,您需要确保您的反馈和指标是:
① 代表性:从多样化且具有代表性的用户样本中收集反馈和指标
② 一致性:比较相似输入和输出的反馈和指标
③ 可靠性:过滤掉不相关或不可靠的反馈和指标
5. 总结
提示语技术工程是增强自然语言处理(NLP)系统的强大技术。通过使用高级提示语技术工程的这些技巧和诀窍,您能够设计出高效的提示语,以引导系统生成高质量的响应。此外,您还能将提示语技术工程的原则应用于各种领域和应用,包括但不限于摘要生成、文本生成、信息提取、文本分类、语言翻译、问答系统、情感分析、对话系统、聊天机器人,以及推荐系统等。
(一)提示链
在大型语言模型的语境下,提示链是一门技术,通过将多个提示串联在一起,从模型中生成一系列输出结果的方法。提示链概念在于通过将复杂任务分解为较小的子任务,每个子任务可以由独立的提示来处理,从而使模型能够生成更长的文本序列或执行更复杂的任务。以下使用不同的方法来应用提示链:
1. 连续提示:是指向模型提供一个连续的提示序列,依次一个接一个,每个提示都在前一个提示的基础上构建。例如,第一个提示可能要求模型生成一个项目列表,而第二个提示可能要求模型描述列表上的每个项目。
2. 分层提示:是指使用一个层次结构的提示,其中一个高级提示被分解为较低级的提示,每个提示都进一步细化,直到任务完成。例如,一个高级提示可能要求模型编写一个故事,而较低级的提示可能要求模型生成角色、情节和句子。
3. 混合提示:是指将连续提示和分层提示的技巧结合在一起的方法。例如,高级提示可能要求模型生成报告,而低级提示会要求模型为报告提供数据分析、图表或表格。
4. 自我提示:是指训练模型基于目前所接受的输入指令生成自己的提示语。如此,即使人工提供的提示指令已经结束,模型也可以继续生成输出。
相对于使用单一的提示语而言,通过将提示语串联在一起,大型语言模型可以生成更长的文本或执行更复杂的任务。然而,需要注意的是,提示串联也可能带来新的挑战,比如确保提示协调一致,以及避免模型陷入无限循环。研究人员正在积极探索采用不同的方法来应对这些挑战,以提高提示串联在大型语言模型中的有效性。
(二)输出解释器
若想从 ChatGPT 获取更多结构化信息而不仅仅是文本时,可以使用输出解析器。例如,可以使用Markdown、HTML、表格等格式对输入的文本进行自定义或排版后以不同的形式输出。因此使用输出解析器可以让您的生活更轻松,并减少您在 ChatGPT 和文档之间必须进行的复制 + 粘贴 + 重新排版布局的次数。
1. Markdown
Markdown是一种使用纯文本语法来编写具有格式化的文本的简单直观的方法。它可以轻松地创建标题、列表、表格和链接。Markdown在某些行业广泛使用,但尚未被法律行业采纳。我们相信,随着ChatGPT和其他生成式人工智能工具被法律专业人士广泛使用,这种情况将会迅速改变。
在ChatGPT中使用Markdown的两个原因:
(1) 能够提高ChatGPT回应的可读性
如果提供一个简单提示语,请求ChatGPT去总结《1933年证券法案》,我们会得到一个类似下图24的回应:

图24:请求总结《1933年证券法案》的回应图
ChatGPT 在回复的文本格式排版上已经能够完成的很出色,其对文本进行一些视觉或结构上的修改,使其变得易读和清晰。但是我们可以做得更好,让我们尝试在原始的提示语上增加下列句子请求其总结《1933年证券法案》:
Format the summary using markdown elements such as headings, lists, blockquotes, and tables where appropriate.
(使用适当的 Markdown 元素对摘要进行排版,例如标题、列表、引用块和表格)
这个添加对ChatGPT返回的回复产生了显著的影响,详见下图25:

图25:增加排版请求后的回应图
(2) 可以优化将ChatGPT回应复制、粘贴到您的文档中并进行排版
在上面我们的第一个原因中看到的是已经处理过的Markdown,是我们希望在ChatGPT内值查看排版格式清晰的回复时所期待的展示。但是,如果我们想要将ChatGPT的回应复制并粘贴到我们的Word文档中,使用原始的Markdown会更容易处理。我们可以通过在提示语中增加“返回原始Markdown”或类似的表述来让ChatGPT返回“原始”Markdown。具体示例回复如下图26:

图26:要求ChatGPT以原始Markdown格式回复的回应图
如果你想要学习更多Markdown语法元素(例如上图中的“#”,“**文本**”等),请查看Markdown备忘录的链接[15]。将原始Markdown复制并粘贴到常见的文字编辑软件中后,软件将根据Markdown的规则对文本进行排版,自此您不必再进行繁琐的重新排版的工作。
2. HTML
HTML是一种用于创建和呈现网页的标记语言。对于律师和法律助理,让ChatGPT以HTML格式返回其响应可以简化更新律所网站或博客的过程。此外,一些案件管理平台和其他法律软件工具会使用WYSIWYG[16]编辑器,您可以创建格式良好、易于浏览且具有视觉吸引力的法律文档。因此,让ChatGPT以HTML格式输出其响应可以为您节省大量的复制、粘贴和格式排版的工作。下图27是ChatGPT提供的HTML响应片段:

图27:以HTML格式输出的示范图
让ChatGPT以HTML格式返回其结果,只需要在提示语中添加“以HTML格式提供您的响应”。
3. Graphviz(Dot language[17])
Graphviz是一个免费的工具,用于创建各种可视化图表,从简单的实体关系图到更复杂的流程图。Graphviz 工具使用了一种名叫 Dot 语言,它可以编程方式绘制图表。这意味着我们可以要求ChatGPT以Dot语言提供响应,从而让它为我们创建图表。然后,我们可以获取生成的Dot语言文本,再使用Graphviz或其他常见的软件工具生成图表的图像。
我们在前面看到了ChatGPT以Dot语言输出响应,用于生成组织结构图。现在让我们开始讨论或思考关于遗产规划(estate planning)的话题,通过一条提示语,让 ChatGPT 为有业务或遗产规划指导需求的客户创建一个可视化呈现。
背景信息(虚构)
得克萨斯达拉斯的沃克家族拥有着不断增值的房地产投资组合,其中包括住宅租赁业务。约翰尼·沃克先生是这个家庭中的财富创造者,他与妻子杰西卡一同准备让他们的两个孩子加入业务来帮助他们管理房产。他们的律师马克·凯斯(此人物为虚构)为他们提供了法律建议,建议他们使用一种特殊的有限责任公司(Series LLC[18])的形式来管理他们的资产。
马克·凯斯是一个擅长提示语技术工程的专家,其让ChatGPT生成了以Dot语言呈现的示意图,展示了一个可能的组织结构。
输入的提示语:
Using Dot language, create a diagram for a Series LLC. The master LLC will be named "Walker Real Estate Holdings LLC" and 7 series (children) named to match this pattern: "Walker Real Estate Holdings LLC - Series {number}" where {number} is replaced with the number of the series.
(使用Dot语言,为一个有限责任公司创建一个组织结构图表。母公司将被命名为 “Walker Real Estate Holdings LLC”,并创建7个子公司,每个子公司的名称将按照以下模式命名:“Walker Real Estate Holdings LLC - Series {number}”,其中{number}将被替换为系列的编号。)
如下图28显示,ChatGPT返回了一个以Dot语言表示的图表结果:
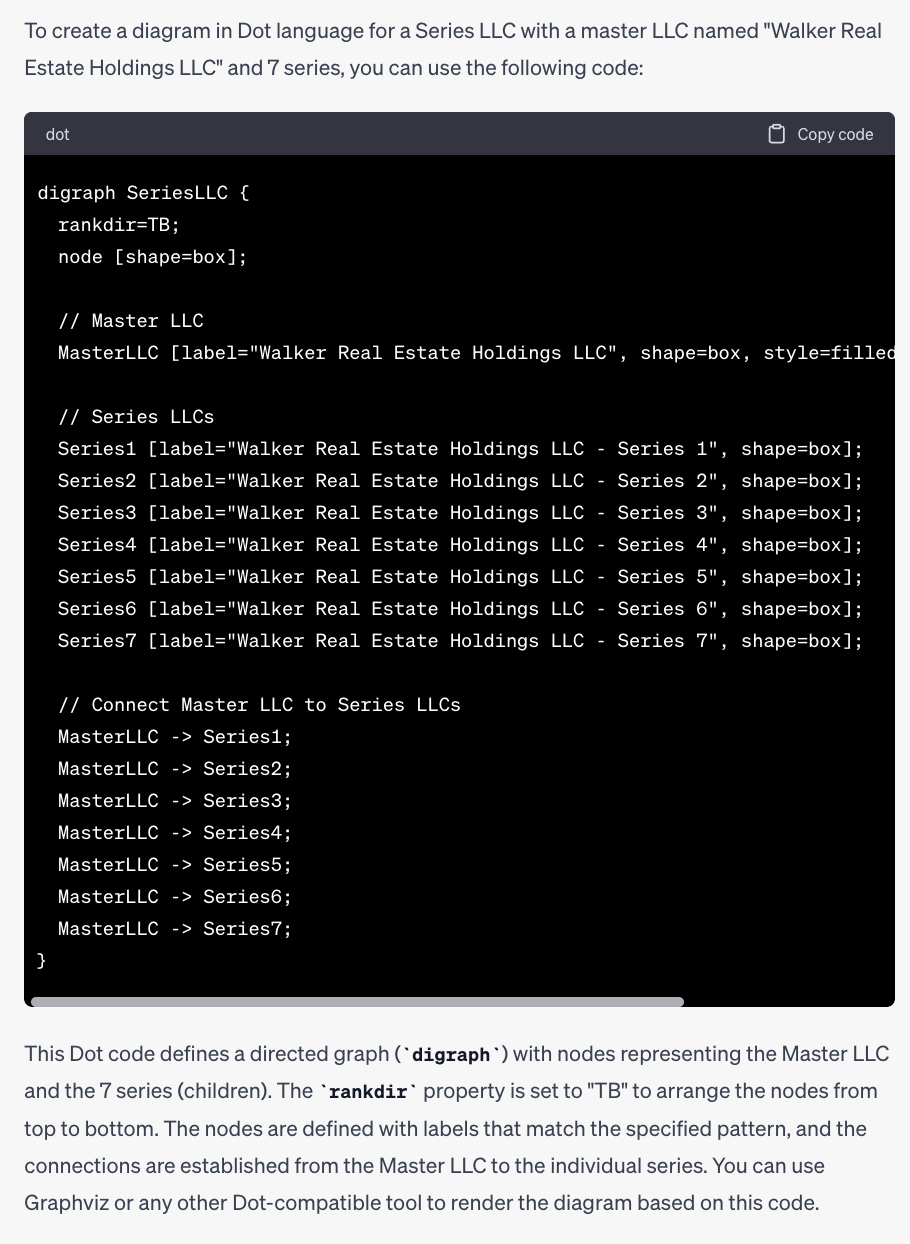
图28:以Dot语言回应图
随后,将上述代码复制进Graphviz工具,我们将获得以下图29的组织结构图:

图29:使用Graphviz生成的组织结构图
(三)ChatGPT插件[19]
ChatGPT插件的作用是增强ChatGPT的功能和性能,使其能够与外部应用程序互动、获取实时信息,并协助执行各种任务,包括日程安排和文件起草。对于法律专业人士而言,使用这些插件将使ChatGPT成为一款有价值且高效的工具。
在这一部分,我们将介绍目前最受欢迎的插件,我们特别关注能够提供以下功能的插件:
(1) 允许ChatGPT访问互联网以获取最新信息。
(2) 允许ChatGPT与 PDF 或 Word 文档互动,以进行内容摘要、信息提取和提出问题等任务。
(3) 允许ChatGPT访问外部应用程序(例如电子邮件、日历、案件管理平台等)以自动执行简单任务。
1. 确认启用插件的演示
2. 部分插件使用介绍
(1) ChatWithPDF
对于许多人来说,使ChatGPT能够处理PDF文档具有极大的价值,它可以总结大型PDF文档,根据PDF内容回答问题等,这对于法律专业人员等有无数用途。在我们深入示例之前,我们再次强调理解像ChatGPT和这类插件如何处理文档内容是非常重要的。如果您正在寻找一个具有安全性且私密的处理PDF文档的人工智能服务,请查看CaseMark AI[20]。
下面视频为一个使用ChatWithPDF插件的演示视频:
点击边框调出视频工具条
如上所示,与PDF文档进行互动是非常简单的。我们还可以在同一个对话框中提供多个PDF文件,如下图30所示。在处理多个PDF文档时,ChatGPT所生成的回应会参考您所提供的文本。

图片30:多个PDF文档演示图
(2) 使用 “Web Requests”插件让ChatGPT与互联网相连接
如果你曾经使用过ChatGPT,那么你很可能遇到过它经常出现的回答之一:“作为一个人工智能模型,我的知识库中的训练数据只包含了截至2021年9月的信息。”
“ChatGPT”中的“GPT”代表生成式预训练变换器[21],这意味着它是在从互联网抓取的大量现有文本数据上进行训练的。2021年9月之后在互联网上发布的任何数据都没有用于训练ChatGPT。因此,它不了解最近的事件,也与外部世界没有联系。因此ChatGPT不能告诉您迈阿密,佛罗里达州的当前温度。
然而,使用能够连接到互联网的插件可以解决此问题。在下面的互动演示中,我们将指导您完成安装和使用可以为ChatGPT搜索互联网的插件:“Web Requests”:
点击边框调出视频工具条
上例演示可以了解如何利用插件与PDF文档进行互动,并从互联网获得实时信息。下一个示例将演示如何同时启用多个插件来扩展ChatGPT的功能,用以帮助您应对更复杂的任务。
(3) 同时使用多个插件
让我们通过在同一聊天会话中使用多个插件来强化我们的ChatGPT工作流程。请查看下面的演示,该示例使用ChatWithPDF插件用以从研究论文中提取信息。同时启用了“Web Requests”插件,让ChatGPT能够访问互联网。
接下来,我们要求ChatGPT返回2023年对《内部税收法典》(Internal Revenue Code)所作的任何修正案信息。
您可以探索数百种可用的ChatGPT插件,看看哪些插件可以在使用ChatGPT时让您更加高效。在2023年7月初,OpenAI宣布推出了代码解释器,许多人声称这是插件的下一个演进阶段。我们将在下一节中看一看代码解释器。
(四)ChatGPT代码解释器
一些网友(包括我们自己)将OpenAI的代码解释器称之为“革命性的创新”和“ChatGPT能力下一个演进阶段”。现在,ChatGPT不仅能够像经验丰富的程序员一样编写代码,而且还可以通过代码解释器去执行代码。通过使用代码解释器功能,为用户提供了在更复杂场景中应用 ChatGPT 的机会和条件。
例如,遗产规划律师可以上传信托合同的模板,并让 ChatGPT 根据客户的信息填写合同。税务律师可以上传客户的股票交易电子表格,代码解释器可以计算资本收益等重要数据,然后将结果导出并在税务报告中使用。律师助理可以在几秒钟内生成客户接待表的 PDF 文件。从而简化文件生成过程。法律专业人员会发现 代码解释器在许多场景下执行各种不同任务方面是非常有用的。
下图31为OpenAI在2023年7月的公告中的描述:

图31为OpenAI在2023年7月的公告描述图
让我们回顾一下我们之前提到的使用代码解释器的一个示例。上一章节中,我们介绍了使用ChatGPT插件上传 PDF 文档,并让ChatGPT根据上传的文档提取信息并回答问题。
在下面的演示示例中,我们将使用代码解释器生成一个可下载的PDF,这个文档内容为发送给律所新客户的客户接待表格。
4 在律所落实使用人工智能的责任
特别是像ChatGPT这样的大型语言模型的人工智能,通过自动处理琐碎的任务、提供建议等方式增强法律实践能力,为律所提供显著的效益。但是,对于任何强大的工具而言,负责任地使用人工智能是至关重要的。本章节提供了关于如何以合乎道德和安全的方式在法律实务中使用人工智能的指南。
(一)数据泄漏
当模型在其回复中无意识地重复或泄漏敏感信息时就会发生数据泄露。这种现象并非有意地披露,而是模型设计和学习的副作用。然而,它强调了与这些模型负责任的互动的必要性,特别是在隐私和保密至关重要的情况下。
(二)落实人工智能伦理政策
您不希望您的公司在没有了解相关后果后盲目使用人工智能并将工作委托给它。您应该在公司强调人工智能不是替代品,而是一种可以帮助您的公司出色地完成任务的工具。
实施人工智能伦理政策是律师事务所应采取的基本步骤。此政策将指导您的团队如何在使用这些系统中保持高度的职业标准,以确保您在享受人工智能的益处的同时维护最高的专业标准。
以下是实施强有力的人工智能伦理政策的蓝图:
① 定义人工智能伦理原则:政策应从清晰的原则开始,该原则反映了您公司使用人工智能时伦理上的承诺。这可能包括尊重隐私、数据保护、非歧视、透明度和问责制。
② 阐明数据隐私和安全协议:概述如何在保护客户机密和数据安全的同时与人工智能进行互动。强调不将客户的敏感信息输入到人工智能系统中的重要性,以及遵守数据隐私法规。
③ 解决潜在的人工智能滥用问题:该政策应识别潜在的人工智能滥用行为,并解释如何防止这些滥用行为。这可能涵盖滥用生成内容或过度依赖未经人工验证的人工智能的建议。
④ 提供有关提示语技术工程的指导:应包括关于如何为人工智能系统起草有效和合乎道德的提示的指南。它应该强调提示语中上下文语境、清晰度和适当性的重要性。
⑤ 建立报告机制:建立一个系统用于员工提交人工智能使用相关的任何道德问题的报告。用此方式鼓励公司内部的责任感和问责制的建立。
通过在公司内实施人工智能伦理政策,您将建立一种负责任的人工智能使用文化,保护客户,遵守法律,并提高您的法律服务质量。
(三)推广人工智能素养
在人工智能和数字转型时代,人工智能技术的素养变得和法律专业知识一样重要。在您的公司内推广人工智能素养,使每个人都能充分利用大型语言模型等技术的好处,同时保持您公司的道德和专业标准。
以下是如何在您的公司培养人工智能素养建议:
① 培训计划:组织关于人工智能技术及其在法律实践中应用的研讨会和培训课程。不仅应涵盖像ChatGPT这样的工具的实际使用技巧,还应包括对其局限性和伦理影响的内容。
② 定期更新:人工智能技术发展迅速。定期更新最新的人工智能趋势、工具和监管的变化,可以让公司中的每个人都了解最新情况。可以考虑为此目的创建时事通讯或内部博客。
③ 公开讨论:鼓励公司内部就人工智能进行公开讨论。这可以培养在法律工作中使用人工智能进行学习和批判性思维的文化。
④ 清晰的指南:起草关于如何负责任地与人工智能系统进行交互的清晰的指南,重点关注数据隐私和保护、具体和上下文语境提示语的重要性,以及理解人工智能响应。
⑤ 进行实践:没有什么比边做边学更有效的了。为公司中的每个人提供与人工智能工具互动的机会并在日常任务中使用它们来加快学习过程。
通过推广人工智能素养,您可以确保您的公司在法律行业保持领先地位,提高生产力的同时并在科技先进性和客户保密性方面保持良好的声誉。
5 研究现状
(一)作为税务律师的大型语言模型
1. 引言
《大型语言模型作为税务律师:法律能力的发展案例研究》[22]一文中,作者旨在探讨目前人工智能模型是否能替代专业税务律师的工作。税法被选为该研究的主题的主要原因是:
① 税法本身结构的复杂性:税法具有复杂的结构,其应用需要逻辑推理和数学技能。
② 研究资料来源的集中性:税法的法律权威主要集中在两个来源上,即美国联邦法规下的财政部法规和美国法典第26编(也称为内部税收法典)。
③ 与现实经济生活的紧密性:税法影响着个人和公司的财务状况和经济活动,涉及税收政策、税务规定和税收征收等方面。
2. 提出理论
该篇论文中作者提出在结合了被增强的提示语和正确的法律文本的情况下使用大型语言模型可以在某些任务上表现出高水平的准确性,但尚未达到专业税务律师的水平。他们认为,随着大语言模型的不断进步,它们在法律推理方面的能力可能会对法律职业和人工智能治理产生重要影响。下图32为这项研究的结构图:
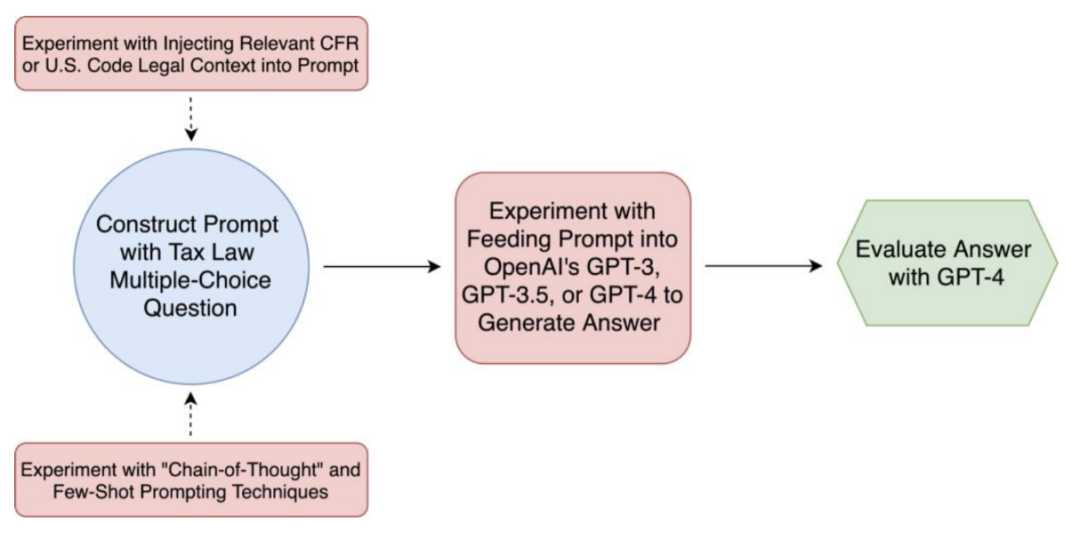
图32:研究结构图
3. 使用提示语技术工程测试
作者采用了各种提示语技巧来增强大型语言模型在税法背景下的性能,这些技巧包括:
① 思维链引导提示法(CoT):这一技术要求大型语言模型逐步思考其回答的过程,旨在鼓励模型生成更富有推理和思考性质的回答。然而,研究结果表明,CoT提示并不总能在所有模型和检索方法上产生一致的改进效果。即便如此,该方法确实提升了GPT-4的性能,这表明大型语言模型可能需要具备一定的能力水平,才能通过额外的推理来提高其性能。
② 少量示例提示法:在这种方法中,大型语言模型会被提供一组包含三个其他问题和答案的示范例子,同时还有当前正在提出的问题。这些示例的目的是为模型提供上下文语境和参考模式,以便它在生成自己的回答时可以遵循这些示例的模式。作者的研究发现,少量示例法提示技术对GPT-4的性能产生了显著的改进效果,但是对性能较弱的模型,这个技术可能无法产生相同程度的改进效果。
③ 自我反思和自我完善技术:该技术是用于改善大型语言模型的性能。首先,大型语言模型会被提示使用自己以前生成的答案和问题的背景信息。其次,大型语言模型被要求识别问题中可能存在的任何不明确或模糊之处,或对自己当前的答案进行自我审查和反思。最后,大型语言模型生成的响应(包括对问题模糊之处的识别或对答案的怀疑)可以用来进一步改进答案的生成。尽管该篇论文没有提供这些技巧的具体研究结果,但是认为它们具有提高性能的潜力。
④ 文档检索:作者尝试了不同的检索方法,每种方法都有自己的提示语模板,该模板为大型语言模型提供了不同的背景内容。他们发现,为大型语言模型提供更多的法律文本和更相关的法律文本时会增加大多数模型的准确性。
总的来说,研究结果表明这些提示语工程技术的有效性会因大型语言模型的背景而有所不同。然而,这些技巧都在不同程度上增强了大型语言模型(LLM)在税法上的推理能力并能生成准确的回答。
4. 针对模型的测试
这篇论文对OpenAI在过去三年中发布的四个大型语言模型的性能进行了测试评估。针对每个模型的研究结果如下:
① GPT-4:这是研究中评估的最先进的模型。研究人员发现,GPT-4在应用“思维链提示法”(CoT提示技术)时获得了显著的性能提升,这一技术要求大型语言模型在回答问题时逐步思考其思维过程。这表明大型语言模型在通过额外的推理来改善性能时可能需要具备一定的能力水平。此外,GPT-4还在应用“少量示例提示法”时表现出了明显的性能提升。该方法涉及向大型语言模型提供一组包括三个其他问题和答案示例以及当前问题的示例,有助于模型更好地理解问题并生成更准确的答案。最重要的是,当提供“黄金标准”法律文件时,GPT-4的回应性能得到了明显的提升,而不是执行从向量数据库中提取相关文档的相似性搜索。
② GPT-3.5:这个模型是通过监督式微调的方式进行训练,而不是依赖人类反馈的强化学习(RLHF)。与GPT-4的测试结果表现并不一致。该模型在应用少量示例提示法时表现较差,而思维链提示法优势也没有那么显著。
③ GPT-3(davinci):这个模型在Open AI公司提供的CPT-3系列中被认为是“最强性能”版本。但是,随着时间的推移,大型语言模型的技术在不断取得进步,其无法与后来的新模型相媲美。同时,对于这个模型来说,使用高级提示语技术工程对其性能提升不如其他模型显著。
④ GPT-3(text-davinci-002):这是GPT-3.5的早期版本,经过“监督式微调的方式进行训练,而不是从人类反馈中进行强化学习(RLHF)”。这个模型的性能与GPT-3(davinci)类似,略逊于新模型。
5. 结论
就目前而言,资深税务律师无需担心其工作被替代的问题。但是,初级税务律师应该开始学习利用ChatGPT,否则他们可能会被同行超越。
该研究的结果为大型语言模型(LLMs)在税法背景下的能力提供了一些核心见解。
首先,研究发现,“思维链提示法”(CoT)和少量示例提示法的效果因特定大型语言模型和背景而有所不同。CoT提示法鼓励大型语言模型逐步思考其回答的过程,这提高了最先进的模型GPT-4的性能,但并没有使所有模型和检索方法的结果表现一致。由此表明大型语言模型可能需要具备一定的能力水平才能受益于额外的推理。少量示例提示法向大型语言模型提供了一组包括三个其他问题和答案范例以及当前问题的示例,这显著提高了GPT-4的性能,但对于性能较弱的模型来说,其测试效果并不相同。
其次,研究发现,为大型语言模型提供更多的法律文本和更相关的法律文本会使大多数模型的准确性略有提升。这表明,在提示过程中使用的法律文本的质量和文本的相关性可以影响大型语言模型生成准确回答的能力。
最后,也许最重要的是,研究发现,导致准确性持续提高的主要实验因素是所选用的大型语言模型。新模型的表现始终优于旧模型,这表明了大型语言模型技术的迅速发展以及它们在处理复杂主题(如税法)时推理能力的不断增强。
下图33为研究结果可视化图表:
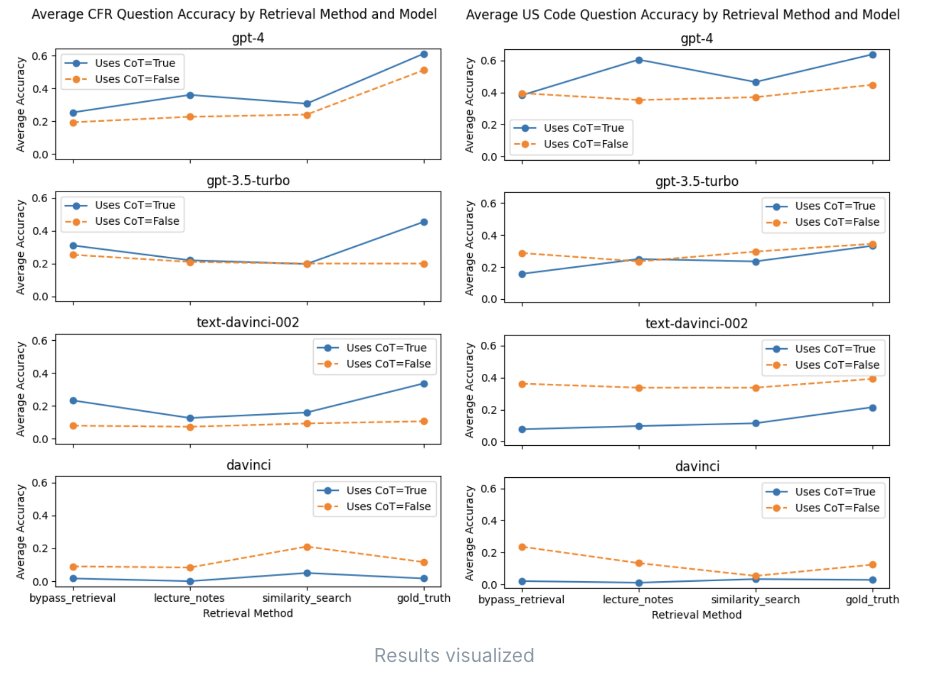
图33:研究结果可视化图
这些结果展示了大型语言模型在法律领域的潜力,同时强调进一步研究和开发以增强它们能力的重要性。研究结果表明,随着大型语言模型的不断进步,它们在法律服务中可能会发挥越来越关键的作用,具有提高效率、降低成本,并使法律咨询更易获得的潜能。
(二)法律判决预测的提示语工程技术
1. 引言
《多语言法律判决预测的法律提示语工程技术》[23]一文是由汤姆逊·路透(Thomson Reuters)实验室的研究人员Dietrich Trautmann带领下围绕法律提示语技术工程(LPE)的概念展开,重点研究法律提示语技术工程在法律判决预测领域的应用,研究基于给定的法律实施、证据、先例和其他相关信息来预测法律案件结果。
2. 提出理论
能否使用大型语言模型来自动预测法院的决定?更具体地说,它在讨论法律提示语技术工程是否能够引导大型语言模型以零样本方式有效地执行法律判决预测(LJP)任务。提醒一下,零样本提示是最基本的提示形式,也是最常见的。零样本提示指向模型提供一个任务(例如,提出一个问题),没有其他信息。在文中,还提到了几种提示策略,例如少量示例提示法,它可以在相对少的工作量下显著改进ChatGPT和其他大型语言模型的结果。
3. 为什么作者只采用了零样本提示语?
大型语言模型(LLM)的内在的一般性知识是否能够转化为对法律的基础理解。在测试中,除了来自欧洲人权法院和瑞士联邦最高法院的案件文本外,没有提供任何额外的上下文信息。最终,实验中使用的提示栈如下图34所示:
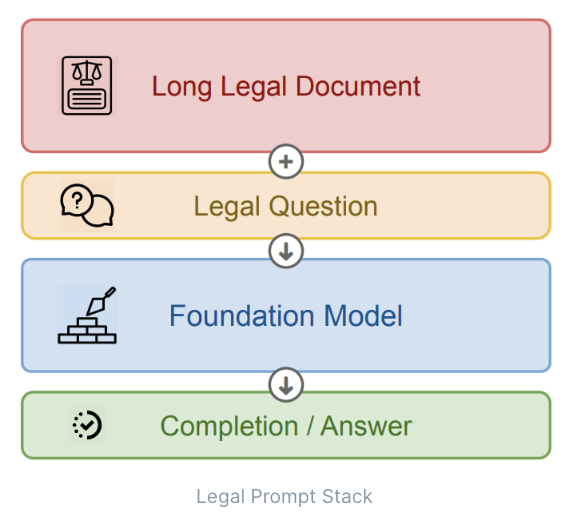
图34:法律提示栈图
使用零样本是测试通用大型语言模型(LLM),即未经进一步训练或微调的模型是否能够进行法律推理的最有效方式。使用更高级的提示语技术工程将极大可能歪曲结果导致违背研究的目的。
4. 测试方法
作者采用了分离和手动的法律提示语工程。在这个过程中,他们创建并测试了人类可阅读的提示语,并将法律判决分为两个类别的任务(是与否),以下是这个过程的总结:
① 首先,研究者尝试仅使用一份长篇法律文档作为语言模型的输入。语言模型试图继续生成,但结果对预测有罪或无罪没有帮助。
② 然后,他们在文档后添加了一个重新构造任务的问题。这种方式改善了模型的输出,但在许多情况下仍然不够有效。模型没有给出是或否的答案,而是继续列出其他问题。
③ 为了改善模型的输出,他们添加了“Question:” 和“Answer:”的指示符。但是,模型仍然给出难以归类为是或否的自由形式的回应。
④ 接着,他们加入了 “A, Yes"”和“B, No"”的答案选项来指导模型的回应。
⑤ 最后,他们使用了一个特殊指示符来区分文档和提示。
具体如下图35的演示:
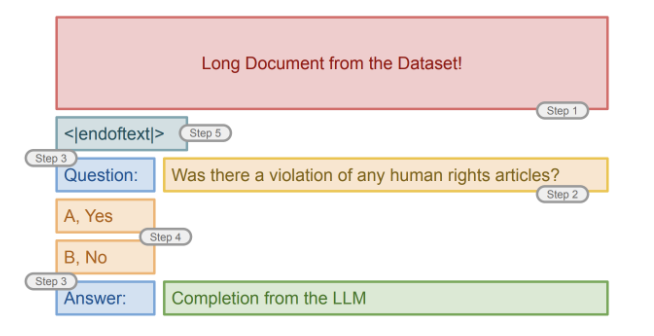
图35:测试方法演示图
5. 结论
研究结果表明,零样本法律提示语技术工程(LPE)比常用的标准方法表现更佳,证明了将通用大型语言模型应用于法律领域的可行性。然而,与目前领先的监督式方法相比,其效果仍有待提高。尽管有其局限性,该研究展示了法律提示语技术工程在法律领域的应用潜力,以及它在处理多语言环境下的适用性。
6. 为什么这项研究很重要
人工智能模型在法律专业人士的决策过程中提供帮助,同时能促进法律研究,并提高法律程序的效率。正在测试的法律判决预测(LJP)任务仍然具有挑战性,原因有三:首先,法律语言本身非常复杂;其次,执行这项任务需要强大的逻辑推理能力;最后,法律文件通常篇幅较长。
通过分析和理解大型语言模型在特定领域(如法律判决预测)中的表现和处理方式,可以获得有价值的信息,这些信息有助于推动人工智能技术在更广泛的行业中的应用和发展,而不仅仅局限于法律领域。
[1] 类人文本是指AI所生成的文本,其质量和风格与人类写作的文本相似,通常包括语言、逻辑、上下文和语法等。
[2] 知识密集型领域指的是指的是需要大量专业知识和深度理解的领域,通常需要深入学习和专业培训的领域。
[3] "强动词"(Strong Verbs)是指在语言中使用的具体、生动、有力和描述性的动词,用于准确、清晰地表达动作或状态。
[4] 原文所使用的占位符(placeholders)一词直接使用难以理解,因此将上述词语进行了表达上的替换。
[5] 迭代过程是指这个过程需反复进行的,不断尝试和改进,以获得最佳的结果。
[6] 是医疗文件的一种,通常包括按时间顺序列出的医疗事件、诊断、治疗和手术等详细信息,以帮助医疗专业人员和法律专业人员了解病人的医疗历史。
[7] 是对患者医疗记录的精简总结,通常包括主要诊断、治疗、手术和病人的医疗历史等关键信息。
[8] 元数据(metadata)是描述其他数据的数据。它提供了关于数据的信息,以帮助理解、组织、管理和使用这些数据。元数据可以包括各种信息,如数据的来源、创建日期、作者、数据类型、格式、关键词、标签、访问权限等。
[9] "dot language" 是一种用于描述图形的脚本语言,通常与图形可视化工具一起使用。它是Graphviz图形可视化软件的一部分,用于创建各种图形,如流程图、组织结构图、网络拓扑图等。通过dot语言,用户可以定义图形的节点、边和布局,然后使用图形可视化工具生成实际的图形表示。
[10] PEGASUS 是一种预训练的自然语言处理(NLP)模型,由Google于2019年发布。它被设计用于执行文本摘要任务,即从长文本中生成简短、精炼的摘要。
[11] BART(Bidirectional and Auto-Regressive Transformers)是一种预训练的自然语言处理(NLP)模型,由Facebook AI于2020年发布。BART 是一种基于变换器(Transformer)架构的序列到序列(Seq2Seq)模型,旨在处理各种自然语言处理任务。
[12] GPT-3(Generative Pre-trained Transformer 3)是由OpenAI开发的自然语言处理(NLP)模型,是基于变换器(Transformer)架构的深度学习模型的一种。GPT-3 在大规模文本语料库上进行了预训练,使其具备了广泛的语言理解和生成能力。
[13] DALL-E(pronounced as "dolly")是由OpenAI开发的一种深度学习模型,属于生成式对抗网络(GANs)的一种变体。它是专门用于生成图像的模型,具有独特的能力,能够从文本描述中生成符合描述的图像。
[14] 本体(Ontologies),它是一种在计算机科学和信息科学领域使用的术语。本体是一种用于描述领域内各种实体、概念和关系的形式化知识表示方法。在知识工程和人工智能领域,本体被用来构建模型,以帮助计算机系统更好地理解和处理特定领域的信息。
[15] https://www.markdownguide.org/cheat-sheet/
[16] "WYSIWYG" 是 "What You See Is What You Get" 的缩写,中文意为"所见即所得"。在一个WYSIWYG编辑环境中,用户在编辑内容时所看到的内容和最终呈现的外观是一致的。这意味着用户可以实时预览他们的工作,无需理解或处理复杂的标记语言或编程代码。
[17] Dot语言是一种用于描述图形的文本语言。它通常用于创建各种类型的图形,如流程图、组织结构图、网络图等。
[18] Series LLC(Series Limited Liability Company)是一种特殊的有限责任公司结构,允许公司创建多个子公司,每个子公司都具有独立的资产、债务和管理结构,但在法律上仍被视为单一法人实体。
[19] 如果要访问插件,您必须是ChatGPT Plus 用户。若想了解如何在您的 OpenAI ChatGPT 帐户中访问插件,请参考此链接:https://help.openai.com/en/articles/7183286-how-to-access-plugins
[20] https://www.casemark.ai/
[21] "GPT" 是 "Generative Pre-trained Transformer"(生成式预训练变换器)的缩写。这是一种计算机科学领域的术语,指的是一类基于变换器(Transformer)架构的预训练自然语言处理(NLP)模型。这些模型被广泛用于文本生成、对话生成、自动翻译、摘要生成等自然语言处理任务。最著名的GPT模型系列包括GPT-1、GPT-2、GPT-3等,它们在NLP领域取得了卓越的成就,能够生成高质量的自然语言文本并用于各种文本生成任务。
[22] Nay, J. J., Karamardian, D., Lawsky, S. B., Tao, W., Bhat, M., Jain, R., Lee, A. T., Choi, J. H., & Kasai, J. (Year). "Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence." Retrieved from https://arxiv.org/abs/2306.07075.
[23] Trautmann, Dietrich, Alina Petrova, and Frank Schilder. "Legal Prompt Engineering for Multilingual Legal Judgement Prediction." Retrieved from https://arxiv.org/pdf/2212.02199.pdf.
调研论文
[24] Trautmann, D., Petrova, A., & Schilder, F. (2022). Legal Prompt Engineering for Multilingual Legal Judgement Prediction. https://arxiv.org/pdf/2212.02199.pdf.
[25] Exploring the Role of AI in Legal Systems: A Comprehensive Review. https://arxiv.org/pdf/2301.13688.pdf.
[26] Generative AI for Legal Applications: Opportunities and Challenges. https://arxiv.org/pdf/2110.08207.pdf.
工具
[27] OpenPrompt-An Open-Source Framework for Prompt-Learning. https://github.com/thunlp/OpenPrompt.
[28] PromptSource-A Toolkit for Creating and Managing Prompts for Generative AI. https://github.com/bigscience-workshop/promptsource.
资源
[29] OpenAI Platform Documentation. https://platform.openai.com/docs/introduction.
[30] Pinecone - Language Models and Applications. https://www.pinecone.io/learn/langchain/.
[31] The Prompting Guide - An AI Prompting Resource. https://www.promptingguide.ai/.
撰稿 | 张子彤,清华大学智能法治研究院实习生
选题&指导 | 刘云
编辑 | 沈廖佳
注:本公众号原创文章的著作权均归属于清华大学智能法治研究院,需转载者请在本公众号后台留言或者发送申请至computational_law@tsinghua.edu.cn,申请需注明拟转载公众号/网站名称、主理者基本信息、拟转载的文章标题等基本信息。
声明:本文来自清华大学智能法治研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
