2023年11月17日,美国情报高级研究计划局(IARPA)发布“偏见效应和生成式人工智能显著局限性”(Bias Effects and Notable Generative AI Limitations,BENGAL)项目公告,旨在分析大型语言模型(LLM)威胁模式和威胁量化方式,开发类似于“病毒扫描”软件的工具,从而寻求应对威胁和漏洞的新方法。
该项目将分别研究四个主题领域内的威胁模式,分别包括:LLM不同分析视角中的偏见、人工智能幻觉与推论、敏感环境中的安全信息流、弹性处理不完善或有缺陷的信息源。本文将介绍该项目的公告的具体信息情况,以此了解美国应对AI大模型幻觉的最近技术研究方向与趋势。


IARPA最新BENGAL项目,大模型幻觉威胁模式,量化漏洞新方法!
编译:奋斗小青年
全文摘要与关键词
1.目标任务:解决LLM幻觉等漏洞,开发新能力→保证AI安全+提高IC效率
2.研究内容-LLM的威胁模式及其量化方式:①自动描述和检测偏见+利用LLM引导人们观点;②AI幻觉产生的理论基础与检测;③敏感环境中的安全信息流;④弹性处理不完善或有缺陷的信息源;⑤其他
3.进度安排:预期2年(1年完成初步概念验证,1年完成演示示范)
4.评述:该项目是解决当前AI大模型幻觉的一个重要尝试,项目直指LLM威胁模式及其量化方式,或将实现一些列技术突破,并将大大提高IC界效率,此外,也可有效解决由LLM幻觉产生的错误/虚假信息问题,从而继续推动大模型的应用普及。其研究内容路径值得参考借鉴,其技术研究动向也值得跟踪与关注。
目标解决大型语言模型(LLM)的潜在漏洞。大型语言模型(LLM)正在被迅速采用,公众已经观察到LLM可能表现出错误或潜在有害行为。LLM的易用性、类似人类的对话、复杂性和缺乏可解释性易使LLM出现漏洞,并使恶意应用程序得以存在。模型可能隐藏对用户的威胁,包括快速生成错误/虚假信息或引出敏感信息。
研究LLM的威胁模式及其量化方式。BENGAL旨在了解大型语言模型(LLM)威胁模式和威胁量化方式,寻求应对威胁和漏洞的新方法,或弹性地处理不完善的模型。
开发新能力,保证AI安全+提高IC效率。IARPA寻求开发新的能力,以便安全地采用和使用生成式人工智能技术,从而大大提高情报界(IC)的效力和效率。
02 研究内容
研究主体内容分为4个部分:
研究大语言模型不同分析视角的偏见和归纳
人工智能幻觉与推论
敏感环境中的安全信息流
不完善或缺陷来源下的弹性工作
2.1 不同分析视角中的偏见和归纳
准确、自动地描述和检测偏见。提高对LLM偏见(认知、人口、意识形态、文化、时间等)的认识能力,IARPA 将重点开发新技术用来准确、自动地描述和检测偏见,并利用LLMs引导人们从不同角度看待事件。具体研究包括:
客观量化偏见的方法;
描述视角空间特征并测量视角差异的计算技术;
利用人和LLMs交互来识别分析师的盲点;
归纳代表不同观点的输出(例如,特定群体或组织会如何解释这一事件?);
从具有不同偏见/观点的LLM之间的模拟对话中获得见解。
2.2 人工智能幻觉与推论
重点关注检测幻觉的能力。生成式LLM会产生虚假、无根据的输出("幻觉 "或 "混淆"),从而导致错误的分析和决策。IARPA重点关注检测幻觉的能力,同时最大限度地提高并得出正确和可信的推断。具体研究包括:
在缺乏基本事实证据的情况下,最大限度地提高LLM产出有价值推论的能力;
用新颖且可解释的方法量化生成模型输出的置信度(例如,确保用户的可信度,或生成高质量的合成训练数据,以减少对敏感、稀疏或有噪声数据源的依赖);
研究LLM产生幻觉的理论基础(例如,幻觉是不可避免的吗?)。
2.3 敏感环境中的安全信息流
重点关注LLM技术及其安全性。IC的分级系统限制对敏感信息的访问,如果将信息限制在某些人和系统范围内,会妨碍IC组织间的重要合作和关键信息的及时共享,从而对国家安全构成威胁。IARPA重点关注LLM技术,这些技术既能增加信息流,又能最大限度地降低敏感信息泄露的可能性,使LLM能够在尽可能广泛的数据和任务范围内安全使用。具体研究包括:
在预训练或微调的LLM中有针对性的“反学习”(unlearning)(例如,从 LLM中删除以下信息的方法:有关个人的信息或从特定文件中提取的被视为敏感的信息,而不会影响模型的性能);
解耦敏感信息:给定被视为敏感信息的描述(如,收集的来源/方法),对文档或文档集合进行净化,从而在保留原始文档含义的同时,可验证地删除敏感信息;
确定何时可以使用无害事实的集合来获取特定敏感信息的方法。给定一组查询,量化用户试图从LLM中获取特定敏感信息的可能性,或者,给定一组LLM响应,量化LLM试图访问用户敏感信息的可能性。
2.4 弹性处理不完善或有缺陷的信息源
评估特定信息源可靠性。IC重点关注评估特定信息源可靠性的LLM技术,特别是其内容用于训练LLM或在仅有稀少信息的情况下使用LLM解释发展情况的信息源。IC还对能使分析人员和其他用户在不完善或恶意信息源的情况下灵活工作。具体研究包括:
评估给定信息源(如个人或组织)的可靠性,以确保训练数据的完整性或评估接收到的信息;
推断信息源意图的自动化和可解释技术;
量化信息源确证;
从不完整或有偏见的内容中提取可靠情报。
2.5 其他研究内容
研究非通用LLM型文本生成模型及其不同版本的方法;
侧重于现有方法/工具的系统集成或工程设计的研究;
不以LLM技术为主要重点的网络安全研究;
不会产生功能性原型技术的研究;
需要访问机密数据的方法;
重新提交已由国家科学基金会、国家卫生研究院、国防部、情报界或其他联邦机构授予的工作的研究。
03 进度安排
项目分为两个阶段:A阶段 (基准期)和B阶段 (选择期)。
A阶段:初步概念验证
为期12个月,用于演示概念验证原型,并在第 4、7 和 10 个月提交初步软件交付成果和性能自我评估报告。
在A阶段BENGAL公司应提出并实施自己的测试和评估协议。独立的测试和评估 (T&E) 团队将验证执行方的结果并验证软件性能。目前独立评估团队尚未选定,但可由政府机构、联邦资助研发公司 (FFRDC)、大学附属研究中心 (UARC) 或能源部实验室等机构担任。A 阶段结束时,执行方应提交一份最终报告。
B阶段:示范
如果实施,将在A阶段概念验证研究的基础上进行示范,为期12个月。如果项目主题合适,可以考虑缩短项目期限。项目时间表见图1。
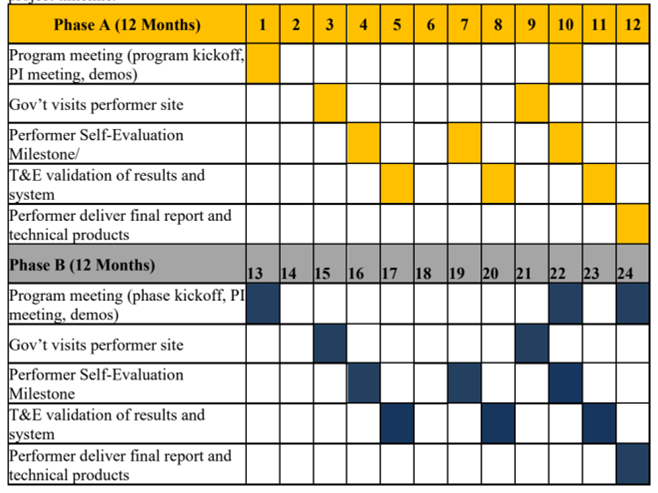
图:项目进度安排
04 评述
由AI大模型幻觉产生出的错误/虚假信息,已经对情报界构成了巨大威胁,为此,IARPA发出“偏见效应和生成式人工智能显著局限性”项目公告,试图深入研究分析LLM的威胁模式,并通过对各类威胁模式的量化,来解决这一新兴威胁。然而,LLM参数数量庞大,在理解和解决偏见效应和幻觉问题时面临着独特挑战,包括:
①庞大的训练数据。LLM预训练使用来自网络的数以万亿计的数据,难以消除虚假、过时或有偏见的信息;
②LLM的多功能性。LLM跨任务、跨语言且跨领域,在全面评估偏见效应和幻觉问题、解决潜在漏洞方面极具挑战;
③LLM的信息源十分庞杂以至错误数据不易察觉。BENGAL项目旨在处理和解决这些问题,因其动态属性和技术难度之大,需反复迭代,才有可能使“偏见效应和生成式人工智能显著局限性”逐步得到控制。
总体来说,虽然面临诸多困难,IARPA此次项目公告涉及的研究目标和研究内容较为具体,可执行性较强,具有参考和借鉴意义,其后续技术研究发展动态值得持续跟踪与关注。
参考文献:
https://www.iarpa.gov/newsroom/article/bengal-baa
https://sam.gov/opp/affad5d251934a2a8c4c8e4c9f33433d/view
声明:本文来自认知认知,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
