工业数据往往不含有个人信息,不具有人格权等特征,在数据共享和开发利用中具有先行先试的价值。德国海德堡大学和慕尼黑联邦国防军大学的学者近期在《European Journal of Law and Economics 》发表了《Industrial Data Sharing and Data Readiness: A Law and Economics Perspective》一文,本文以该文章为基础并结合其他资料阐述工业数据共享相关内容。
1 工业数据利用现状
工业数据指的是企业生产等产生的数据,区别于企业收集到的个人信息等具有鲜明的人格特征的数据。根据欧盟委员会估计,数据经济中大约有80%的机器生成数据至今仍未使用,并且认为这些数据可以促进经济的增长和创新。为提高新型数据经济增长的潜力,欧盟委员会也提出了“数据共享、数据自由流通”等倡议。[1]当下生产数字化(智能工厂)和数字化产品不断出现,应用到工业数据的场景主要有以下几个方面:
·智能城市
··污染指数
··相应的措施防止传染病的传播
·智能生产
··智能和资源高效的农业
·智能服务
··智慧医疗
··智能无人驾驶汽车
··智能可穿戴设备
·……
在数据利用阶段,某一公司为特定目的而收集的任何数据都可能成为其他经济参与者或公共实体为不同的目的而收集的最重要的资产。[2]例如,智能汽车过去收集的数据同样可以应用于未来的无人驾驶汽车,并提供更好、及时甚至预测性维护服务。同样地,智能汽车收集到的驾驶路径、地理位置也可以应用于地理数据服务的提供者(例如谷歌地图)。通过数据的分析,数据服务提供方可以获取关于一个单向道路的方向的变化,并且告知公共当局在一个给定的时间内的道路的使用量和交通状况。同时,公共部门也会在工业数据共享中受益。例如,基于汽车收集的数据可以分析是否需要增加交通安全管理,通过收集和分析获得的匿名化的临床、遗传等数据可以用于各地的卫生保健工作等等。
数据的社会效益甚至将会随着包含在更大的数据集中的数据而增加,数据集汇集了来自不同来源的数据,比如来自不同汽车制造商的数据,这些数据汇集起来,能够产生比单一数据更大的效用。不同数据之间的关联(也称为“数据挖掘”),以满足企业或者公众的需求。[3]
数据的有效利用依赖于数据的商业化,如何才能让数据在数字经济中发挥作用,数据共享政策是否能够最大限度地发挥数据的效用,都是需要进一步探讨的问题。
2 工业数据的新特点
企业对于收集到的大数据享有的权利,与个人信息权面临着一样的问题,因为两类数据都具有一定的商业利用和交易价值。[4]与之不同,工业数据共享不同于传统的数据共享,工业数据不具有人身属性,不具有能够识别特定个人信息的数据,因此不具人格权争议。例如河流或者空气的污染指数,道路交通状况以及匿名病患的健康指数等等都属于工业数据。智能城市的操作、智能和资源高效农业,或采取措施防止传染性的疾病的传播。显然,这种新的数据经济的发展需要依赖数据的商业化。
《Industrial Data Sharing and Data Readiness:A Law Economics Perspective》这一文章研究了工业数据共享中企业的动机和企业能从中获得的好处。作者假设了两种不同的政策条件,一种是不强制企业提供数据,另一种是强制企业共享最低数量的数据。研究表明,政策会对数据生成的最佳投资水平以及整体效益(福利)产生不同的影响。
数据具有非竞争性的特点,主要表现为数据不会随着使用而减少。当下,数据的数量迅速增长但是并没有得到有效地利用,对于数据的讨论也日益激烈,如个人数据是否属于财产。欧盟委员会的《数据法》提供了一个数据访问和使用的法律框架,根据这一框架,公司今后应该更方便地向消费者、公共机构和第三方提供数据。近年来,许多公司建立了数据生态系统,以实现数据的共享。然而,许多问题也由此产生。例如企业出于各种原因不愿意共享数据,它们担心数据被第三方重新使用会失去对数据的控制。所以作者认为,目前面临的挑战是利用各种手段来促进对平时不公开的数据进行访问。另一方面,政策和技术也制约着数据驱动创新潜力的发挥。欧盟《数据法》第四条第一款规定,“在用户无法直接从产品中获取数据的情况下,数据持有者应向用户提供其使用产品或相关服务所产生的数据,不得无故拖延、免费提供,并在适用的情况下持续实时提供”。这一规定在科研界、政界以及产业界引发了激烈的讨论。公司生产数据必然会有相应的成本,只有当公司能够将下游数据货币化的时候,公司才会有足够的动力去创造和筹备以供再利用的数据。这一要求可能会导致发展数据驱动型产品和服务的动机被扭曲。为了探求企业社会效益与数据生产成本之间的平衡,本文搭建了工业数据共享模型,研究了数据生成制造商和数据使用者两类参与者。研究了没有数据共享政策和有最低量的数据共享标准政策下的两种情况,以探究数据政策对于企业数据共享的影响。
作者通过搭建模型发现,数据共享政策的福利属性具有不确定性。如果数据接收企业为数据支付费用合理,同时获得足够利益,另一方的数据提供者没有因为数据共享导致竞争加剧,那么数据共享政策具有积极影响(正向福利属性)。反之,则会产生消极影响(负向的福利属性)。
3 数据再利用和储备的现状
欧盟委员会正在制定的《数据法案》规定:“同一数据集可为各种目的无限量地使用和重复使用,其质量和数量不会有任何损失”。这也表明《数据法案》认为数据具有非竞争性的特点。《数据法案》旨在确保从数据创建到数据购买和再利用之间的质量和数量保持一致。在这一基础之上,数据的质量和数量在规范的数据市场中是否保持不变是本研究问题的核心。
文章《Industrial Data Sharing and Data Readiness:A Law Economics Perspective》主要从工业数据共享的动机和共享数据对企业的利好进行探讨。文章假设两种政策:一种是强制企业共享最低数量的数据,另一种是不强制企业共享数据。文章研究发现,政策会对数据共享生成的最佳投资水平以及整体福利产生不同的影响。
(一)防止先行者通过数据进行垄断
根据研究表明,企业收集数据有助于根据用户的偏好调整产品,以增加销售额,来降低创新的边际成本。如此会导致最先收集到数据企业具有一定的优势,并且具有垄断性质,使得新进入者无法实现发展,最终阻碍创新。而此时,企业的数据共享就是解决数据垄断问题的方法。
通过强迫数据生成公司和政府干预市场是科研界和政界争论十分激烈的问题。疫情之初的时候,公众要求谷歌允许政府获取位置数据来减少侵扰。目前由于数据垄断、数据共享的交易成本高等原因,市场失灵阻碍了市场中数据共享的机会。而工业数据共享是有可能解决数据垄断问题的一种方法。
据此,作者搭建了两个市场模型。一个是私人市场模型,其以付费交换为前提,没有共享政策的情况下,不需要进行数据的共享;第二个是半公开的市场模型,这一模型解决了数据质量和可以使用的数据成本这两个重要的经济问题。此外,总结了近期工业数据共享相关的文献表明:第一,数据共享可能性随着数据生产成本增加而降低;第二,数据生产成本会对数据生产研究人员共享数据的可能性产生负面影响。
(二)数据储备情况以及数据成本、数量和价值
既有文献通过测量公司数据的存储能力、数据管理和处理水平以及数据的使用状况,评估公司的数据准备情况。根据既有的研究,71%的公司参与数据储备的水平较低。研究发现,低水平的数据共享活动与低水平的数据储备有关。此外,筹备数据的共享过程还取决于数据的真实性等因素既有的研究也表明,法律问题和数据安全问题成为企业数据共享意愿的重大障碍,这也直接影响着数据储备的成本。同时,不同行业的数据生产和数据共享的成本差别也非常大。根据上述文献的分析和总结,作者在模型中假定,收集和整理数据会对数据的数量、数据创建公司对数据的价值以及数据使用公司对数据的价值产生积极影响,并基于此建立了相关的模型。
4 工业数据共享的法律经济学模型分析
作者区分了没有企业数据共享政策和有企业数据共享政策两种情况,在对于变量和等式的分析之后,得出了相应的研究成果。[5]数据共享对数据生产者来说并不是最优的,但是对于社会是最优的。总体的福利取决于数据生产者和数据接收企业的准备程度。
作者分析了一家数据创建公司M(亦即数据制造商),其进行数据的准备和创造工作,另一家公司C则是接受M数据共享的企业,本文称之为数据获取公司。C可能会出于商业目的重新使用M公司所创造的数据。在作者搭建的三阶段模型当中,创建、准备和共享数据的动机取决于两个因素。首先,取决于数据共享对于制造商作用的影响。其次,数据共享公司M共享数据的动机取决于该公司的数据准备情况。M的数据准备程度越低,其建立和实施数据共享生态系统的成本就越高,其数据共享的积极性也就越低。在该模型中,β表示数据共享可能会对M产生的负面影响。β>0,衡量M的数据价值在与C共享时的变化程度。如果0<β<1,则数据共享对M的数据价值的负面影响超过其正面影响。在这种情况下,通过共享数据,数据生成公司的数据竞争优势会大大降低。
情形一:在没有数据共享政策的情况下,作者给出如下命题。
如果β≥1,则在无数据共享政策下始终共享数据。(2)如果β<1,若p≤1-β,则共享数据;若p≤1-β,则不共享数据(p表示共享数据的价格)。
当β≥1的时候(即数据共享公司M的竞争环境和数量类型使得数据共享对M 的数据价值的积极影响占主导地位),数据共享的正效应占主导地位,制造商愿意以任何价格共享数据,也就是说,即使价格为零,制造商也会共享数据。如果β很低,制造商只有在价格(p)足够高时才愿意共享数据。然后,如果β接近1,即使价格(p)很低,制造商也愿意共享数据。
情形二:有数据共享政策的情况下
共享数据的平均值表述M公司对最低数据量有监管要求。数据最低量要求越高,制造商更愿意共享数据的可能性就会越低。k(0<k<1)作为参数,k反映了如下事实,即C只从M的数据创建工作(e0)中部分获益。(原因是根据《欧盟数据法案》,亦即有数据共享政策的情形下,M所有的数据创建成果都必须与C共享)。
情形三:从没有数据共享政策向有数据共享政策过渡的情况。
这一假设情形,作者探讨的问题是,在什么条件下,从没有数据共享政策到有数据政策的过渡会导致共享数据的质量下降。共享数据的质量是由创建数据付出的成本决定的。
通过讨论,作者认为,在没有数据共享政策的前提下,M不共享数据,而在有数据共享政策条件下,M才共享数据,这一过渡才会更大程度的产生积极影响。
情形四:从没有数据共享政策过渡到有数据共享政策的模糊福利效应。
模型概述:
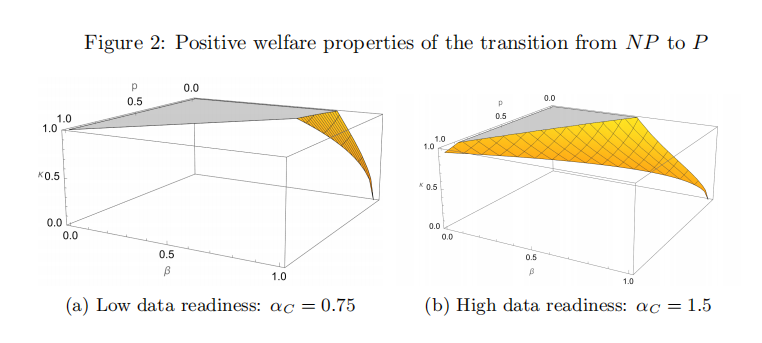
(注:两幅图中,橙色区域是在没有数据共享政策和有数据共享政策下总体福利相同的参数集。对于橙色区域以上的参数集,从没有数据共享政策到有数据共享政策过渡具有正向福利特性。与左图相比,右图中的橙色区域以及橙色区域上方的β、k和p的参数集更大。这是因为右图中的C数据准备度相对较高。)
通过图示模型以及公式的探讨,不同的情况探讨之下,作者得出了如下结论,要使数据共享具有正向的福利特性,必须满足以下条件:价格(p)足够低,而β和k足够接近于1。换句话说,即如果数据获取公司C没有为数据支付过多的费用,并且从M公司的数据生成中获得了足够的利益,同时如果数据被共享,M的数据价值不会减少太多,那么数据共享就具有正向的福利特性。同时,如果C的数据储备程度相对较高,那么,数据共享的福利效应会更大。
5 结论与发展建议
没有数据共享政策情况下,数据创建公司可以自由决定是否自愿共享数据;数据共享政策下,对制造商要共享的最低量有监管要求。数据共享政策可能在两个方面扭曲激励措施。一方面,数据生成公司创建数据的积极性可能会下降;另一方面,数据共享最低数量标准要求过高,没有可供共享的数据。后续可以继续研究,在无数据共享政策下,数据创建公司可以自由决定是否共享数据、免费情况下数据共享的情况、数据共享进一步研究的考虑以及由数据共享驱动的合资企业的可能性等等。
企业是进行数据处理的重要市场主体,是数据产权的主要享有者和利用者。数据资源持有者的权利和加工使用者的权利。“数据二十条”指出:“推动建立工业数据确权授权机制。对各类市场主体在生产经营中采集加工的不涉及个人信息和公共利益的数据,市场主体享有依法依规持有、使用、获取收益的权益,保障其投入的劳动和其他要素贡献获得合理回报,加强数据要素供给激励。”保护数据处理者的劳动成果同时是促进大数据产业与数字经济发展的必要举措。数据处理者在生产数据的过程中付出的大量劳动与投资得不到保护,其生产数据的积极性会降低,导致可供利用的数据总量会减少。在数据生成和数据的商业利用的最初阶段,总会带有一些人类的行为。制造商可能会决定使用配备传感器和机器人来控制和引导生产过程。智能汽车的车主决定这辆车去哪里,以及汽车将在哪里记录有关交通密度或道路物理状况的数据。患者为其血液检查提供血液,其结果可能会进入随后分析的数据集。[6]在所有这些情况下,数据处理者必然会第一时间获得生成的数据,可以据此进行相应的生产活动,甚至可能必须根据数据保护规则给予数据共享的同意。原则上,可以得出这样的结论:没有必要为了激励数据的生成与创造,授予处于价值链初期的企业利用该数据的专有权。
也就是说,建立工业数据共享政策是必要的,因为在数据收集之初,数据共享企业必然获取到第一手的工业数据;工业数据共享政策有利于促进其加快创新转型,同时,为其他企业的发展带来利好,促进企业的创新与社会的发展。
[1] Nathalie Jorzik & Paula Johanna Kirchhof, Frank Mueller-Langer,Industrial Data Sharing and Data Readiness: A Law and Economics Perspective, European Journal of Law and Economics, October 2023, p.2-27.
[2] Josef Drexl, Designing Competitive Markets for Industrial Data- Between Propertisation and Access,8(2017) JIPITEC 257 para 1.p.257-292
[3] Josef Drexl, Designing Competitive Markets for Industrial Data- Between Propertisation and Access,8(2017) JIPITEC 257 para 1.p.257-292
[4] 梅夏英:《在分享和控制之间 数据保护的私法局限和公共秩序构建》,《中外法学》2019年第4期,第850页。
[5] Nathalie Jorzik & Paula Johanna Kirchhof, Frank Mueller-Langer,Industrial Data Sharing and Data Readiness: A Law and Economics Perspective, European Journal of Law and Economics, October 2023, p.2-27.
[6] Josef Drexl, Designing Competitive Markets for Industrial Data- Between Propertisation and Access,8(2017) JIPITEC 257 para 1.p.257-292
撰稿 | 王嘉慧,清华大学智能法治研究院实习生
选题&指导 | 刘云
编辑 | 沈廖佳
注:本公众号原创文章的著作权均归属于清华大学智能法治研究院,需转载者请在本公众号后台留言或者发送申请至computational_law@tsinghua.edu.cn,申请需注明拟转载公众号/网站名称、主理者基本信息、拟转载的文章标题等基本信息。
声明:本文来自清华大学智能法治研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
