由于去中心化交易所(DEX)缺乏监管,套利者可以利用信息差异和价格差距,通过以太坊区块链等平台获利。去中心化交易所套利为欺诈行为带来了可能性和机会,并会严重损害以太坊生态系统的运行。除此之外,大量的套利交易造成了交易所的拥堵,加剧区块链网络负载。因此,套利的普遍性和影响的复杂性使得本文尝试探索并描述套利行为的独特特征,这些特征不同于其他欺诈行为,如洗钱和庞氏骗局,以便能够更好地进行套利行为的检测和监管。本文首次尝试通过特征融合和正向无标记学习(PU Learning)来检测以太坊的套利行为。我们首先进行了深入的分析,并融合利用了两方面的套利特征,包括。1)根据专家知识明确表示节点活动水平的统计特征;以及2)通过图机器学习隐含编码交易信息的结构特征。然后,我们应用PU Learning来生成可靠负样本,以补偿不平衡的套利数据集。我们通过对以太坊上的套利数据集进行广泛的实验来评估我们提出的方法,并证明它可以在检测以太坊的套利活动方面达到90%的准确率。
该成果“Detecting Arbitrage on Ethereum Through Feature Fusion and Positive-unlabeled Learning”发表在计算机网络领域顶级期刊IEEE Journal of Selected Areas in Communications (IEEE JSAC)。IEEE JSAC每年出版12期,旨在关注并传播计算机网络及通信方面的最新研究进展和技术。2022年影响因子是13.081,属于中国计算机学会CCF A类期刊。

论文链接:ttps://ieeexplore.ieee.org/document/9917563
研究背景与动机
作为一个去中心化的交易所(DEXs)平台,以太坊区块链因其匿名性吸引了许多投资者。然而,匿名性是一把双刃剑。一方面,它导致了去中心化支付和数字资产的加密货币市场的急剧增长。另一方面,它带来了巨大的非法金融风险和网络犯罪。为了帮助监管以太坊生态系统,已有许多研究来检测区块链上的异常行为,如洗钱和庞氏骗局。然而,套利,一种通过价格差异获利的频繁发生在去中心化交易所中的行为,还没有得到全面的研究。套利交易是由于同一时间不同交易所之间的价格差异,以及不同的供求关系而产生的。以 "泡菜溢价 "为例,这是加密货币价格快速波动的典型代表,2018年1月,韩国的比特币价格比美国的价格高出43%。这种价格差异必然会吸引投机者从中获利。根据chainalysis年度报告指出,每天的潜在套利利润通常超过7500万美元。这些套利交易不仅使交易所或正常用户狡猾地获得利润,而且还加剧了以太坊网络的拥堵。
然而,套利行为随着时间的推移不断演变,变得越来越复杂,在提取其特有特征来区分套利交易与其他欺诈行为方面存在巨大的挑战。第一个挑战是:如何捕捉跨DEX的套利行为的快速演变和异质性特征。例如,以太坊的早期套利者只需要用外部账户(EOAs)直接买卖币。由于以太坊网络的快速发展和对DEX的监管加强,目前大部分的套利行为由自动智能合约和套利机器人执行。第二个挑战是:如何弥补没有负面样本的不平衡数据集,以确保分类模型的有效性。截至2021年7月21日,以太坊记录了1.63亿个不同的地址和12亿条交易记录。这个数据集只包含正类样本和未标记的样本。为此,为了应对上述挑战,在本文中,我们通过异质特征融合和正向无标记学习(PU Learning),提出了一个新的套利地址检测模型。我们将套利地址检测形式化为一个图上的节点分类问题。由于每个套利节点在交易图中与其他节点的积极交互,构成了特定的网络结构特征。因此,我们通过表征学习来利用结构特征。同时,我们通过专家知识获得套利地址的固有统计特征。然后进行特征融合,形成异质性的特征向量。
核心贡献
我们从统计和结构特征两方面对套利活动进行了透彻的分析,并进行特征融合来描述套利的行为模式。
为了从众多未标记的以太坊地址中获得可靠的负类样本,我们采用了PU Learning来克服负类样本缺失的挑战。
我们进行了广泛的实验来验证我们的检测模型的可行性和有效性。结果表明,我们的检测模型可以达到 90%的精度。
表格1 统计特征定义

表格2 标记的和未标记的数据对比

方法概述
1)异质性特征提取。从以前的工作中可以得出结论,单一维度的特征不能很好地表征异常行为,特别是对套利行为。直观地理解,账户的属性可以在一定程度上反映账户类别,但套利行为的演变严重阻碍了基于统计特征的分类器的分类性能。为了克服第一个挑战,我们提出了双重异质套利特征的定义,并引入了特征融合来实现它们。与套利有关的异质性特征分为两类:统计特征和结构特征。
对于统计特征,包括账户特征和时间特征,我们从基于专家知识的启发式角度进行提取。统计特征定义如表1所示,正类样本和未标记样本的分析数据如表2所示。具体来说,我们从套利账户中得出三个值得注意的发现,即1. 套利者的平均账户余额很小;2. 与未标注的地址相比,标注的套利地址标准偏差较小;3. 大多数套利地址的输入金额和输出金额是相同的。
为了提取结构特征,我们采用了网络嵌入方法。一个节点的嵌入表示是通过聚合边缘特征、图特征和邻居特征来构建的。在特征提取过程中,我们分别得到统计特征和结构特征。特征融合将这些特征连接起来,形成异质的特征向量。尽管套利行为的统计特征会随着时间的推移而变化,但异质特征可以通过聚合邻居节点、交易和整个图的特征来获得节点的隐藏结构特征,这大大弥补了单维特征的不足。
2)PU Learning两步法。在这个套利检测案例中,我们只有正类样本和大量的未标记的数据。未标记的数据不能直接作为负面样本,因为它们可能包含正类样本。直接用未标记的样本作为负样本训练分类器会导致分类错误。PU Learning被引入到我们的方法中来处理第二个挑战:缺乏负类样本的问题。PU Learning可以从未标记的数据集中选择最有可能成为负样本的数据,以最大程度地减少噪声。具体来说,为了找到可靠的负样本,我们采用两步法中的spy technique。简而言之,我们从集合P中随机选择一些"Spy",这些Spy构成了数据集S。然后就有了两个新的数据集Pr和Ur,即Pr=P\S,Ur=U∪S。Pr和Ur被用来训练分类器f。分类器f输出数据集中的实例vi属于正类的概率。因为数据集Ur中的间谍实例具有更高的可能性被分类为正类样本,所以我们将数据集Ur中的概率值按升序排列。不难想象,与间谍实例相似的概率值是潜在的正类样本,而比间谍实例小很多的概率值是可靠的负类样本。而根据阈值θ,原始的未标记实例集U被预测为确定可靠的负面实例。阈值θ将Ur分为两部分。如果一个实例f(xi)的概率小于阈值,它就属于可靠的负集RN。在我们的工作中,阈值θ=0.15被选中。当一个未标记的地址的预测概率是大于0.15时,我们认为它是一个可靠的负类样本。
性能评估
1)PU Learning的影响:从表3可以看出,通过PU Learning得到的数据集在分类性能上优于随机抽样的数据集。更具体地说,在"W/PUL"组中,虽然不同方法的准确率不同,但所有四种方法都提供了良好的分类性能,其精确性都在80%以上。相反,在"W/o PUL"组中,检测模型的最高精度不超过70%。原因是"W/o PUL"数据集中的负类样本并不"可靠"。此外,为了证明Spy technique的优越性,我们在实验中分别采用Rocchio和1-DNF作为比较方法。表格4证明了Spy technique相较于其他方法的优越性。
表格3 PU Learning对于实验结果的影响
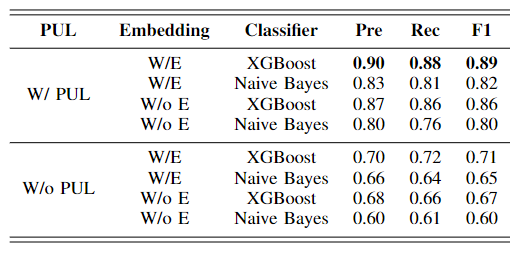
表格4 不同PU Learning方法对于实验结果的影响

2) 特征融合对于实验结果的影响:如图1所示,"Stru+time"和"Stru+account"这两个特征向量的表现都比只有"Stru"向量好,而且 "Stru+account"特征向量在套利检测中发挥了更重要的作用。这一结果表明,尽管网络嵌入算法可以聚合结构和边缘特征,但它只能代表一个单一维度的特征。套利行为本身是一种金融行为,其特征不仅反映在交易网络中,而且还反映在其固有的金融属性中。这也验证了我们的统计特征选择的策略的正确性。
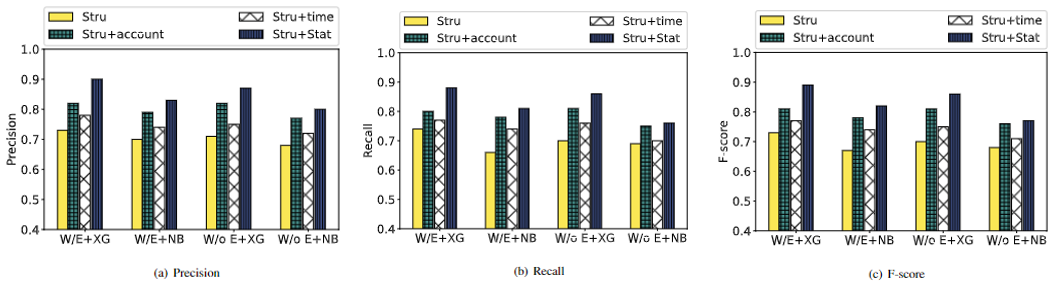
图1 特征向量对于实验结果的影响
详细内容请参见:
Hai Jin, Chenchen Li, Jiang Xiao, Teng Zhang, Xiaohai Dai, and Bo Li, “Detecting Arbitrage on Ethereum Through Feature Fusion and Positive-unlabeled Learning.” In IEEE Journal of Selected Areas in Communications (IEEE JSAC), volume 40, issue 12, pp.3660-3671, 2022.
DOI: 10.1109/JSAC.2022.3213335
声明:本文来自穿过丛林,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
