公安部第一研究所 华为技术有限公司
刘军 张翔 苏智睿 孟凡辉 林建平 卢毅
视频图像重压缩技术是对视频图像再次进行压缩编码的过程中,通过深度压缩提高压缩率,同时在保持视频帧/图像空间尺寸、视频帧率和视频/图像编码格式不变的前提下,使视频图像的分辨率(力)尽可能保持不变,从而很大程度上缓解了安防领域海量视频图像数据存储压力。应用视频图像重压缩技术的产品种类繁多,但各个厂家对视频图像重压缩性能的评价指标、评价方法不统一,对指标的解读也不统一,往往强调优势指标,淡化劣势指标,从而对用户的产品选型造成误导。中关村公共安全视频智能应用技术联盟针对视频图像重压缩技术评测指标及方法进行了调研论证,组织多家单位提出了T/PVIT 0002-2022《视频图像重压缩技术评测指标及方法》,该标准规定了用于评价视频与图像重压缩性能的测试指标、测试环境、测试样本库、测试过程以及综合评价方法,在业内视频图像质量通用指标的基础上,增加了智能分析偏差指标,确保了视频图像经过重压缩后,智能分析偏差可衡量、可控的目标。
1 背景
随着各行业数字化的深入发展,越来越多行业采用视频监控辅助安防与生产运营,当前视频图像画质大幅提升,1080P高清已全面普及,4K超高清视频图像正在推广。更高清的视频图像在看得更清,看得更远的同时,也带来更高传输带宽和存储空间需求。海量视频图像数据如何传得回、存得下已经成为当前视频图像系统亟待解决的问题,解决这一问题的核心要依靠视频图像的编解码技术的发展。近年,视频图像重压缩技术因为其在在不改变分辨率、不改变视频帧率、时长、编码格式等条件下,实现视频图像数倍以上的高质量压缩,在安防领域应用日益广泛。

图1 图像分辨率发展
具备视频图像重压缩功能的整机、压缩软件、压缩板卡等产品众多,但压缩后视图质量参差不齐,压缩率普遍虚高,达成90%压缩率,已经严重牺牲画质。此外在智能时代用户还关注压缩后视频图像是否会影响到机器识别的目标检索、人脸识别、车牌识别等AI智能分析的结果。因此,如果视图压缩技术应用不当,不只是看不清画面,甚至会严重影响AI分析的精度,造成无法解析出目标,影响业务系统的正常运行。
如何提供一套可靠评测方法来判定视图压缩后的主观质量和压缩后对机器分析影响程度,量化评测视频图像重压缩技术的性能,并在基于兼容当前H.264/AVC[1]、H.265/HEVC[2]和JPEG[3]的能力下,量化视频图像压缩以后智能分析结果的偏差,便于用户选择合适的视图压缩技术与方案,成为当前急迫的需求。
2 评价指标和方法
2.1 概述
《视频图像重压缩技术评测指标及方法》标准面向具备视频图像重压缩功能的整机、压缩软件、压缩板卡等产品规定了用于视频与图像重压缩技术综合评价的方法。该方法在指定的压缩倍数,在主观质量无明显损伤的前提下,通过计算视频图像重压缩后相比重压缩前的图像客观质量损伤和智能分析损伤程度来综合评价视频图像重压缩的性能。同时,该标准还规定了测试样本库规模、组成分布、软硬测试环境、测试过程以及各测试指标的计算方法,并对测试指标项的取值区间通过分级形式进行了说明。
2.2 评测指标
2.2.1客观质量损伤指标
该标准规定PSNR、SSIM[4]、MS-SSIM[5]、VMAF[6]等客观质量损伤类指标来衡量检测到的压缩失真与原始图像之间的差异程度,从而评估图像质量损伤程度;由于各指标的数值范围并不相同,且各指标的子区间范围的物理含义并不明确,需要研究如何将各个指标归一化到具有相同物理含义的尺度,然后对归一化后的指标分数进行加权得到最终评分。
该标准通过与主观打分结果进行拟合来归一化。主要包括以下几个步骤:
1)数据准备:对原始格式的监控视频以10%~90%等差的9个压缩率分别进行重压缩。然后对视频进行等间隔抽样,得到重压缩后图像和压缩前图像。
2)指标计算:对每张重压缩后图像和对应的压缩前图像计算客观指标数值,得到客观指标数据。
3)主观打分:对每张重压缩后图像和对应的压缩前图像进行主观打分,得到主观得分数据。
4)主观拟合:通过对相同主观得分的客观指标数据拟合高斯分布来确定相邻主观得分的客观指标数值分界点,然后基于二元组(客观指标数值分界点, 主观得分)拟合质量得分曲线。
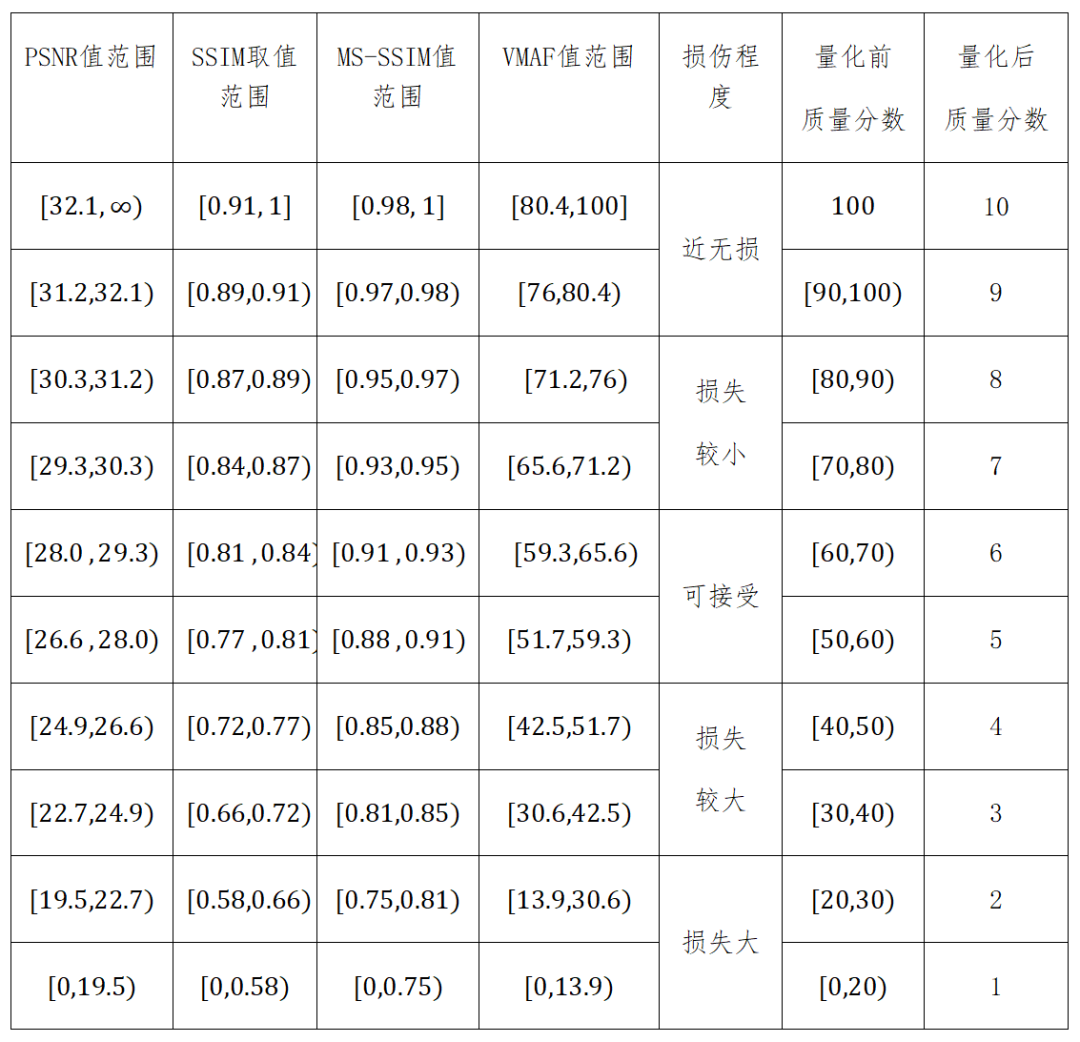
参考H.265标准采主观分级方式,该标准基于拟合后的质量得分曲线进一步将质量得分量化为若干个离散的质量等级。量化后的10级质量损伤及其对应的各个客观指标数值范围如表1所示。
表1 客观指标取值范围与图像质量损伤程度对应关系表
2.2.2智能分析指标偏差
该标准从安防场景的实际业务出发,常见智能分析目标对象(机动车、非机动车、人、人脸)及其相关智能分析任务(目标检测、人脸比对、车牌号码识别和行人重识别)的指标偏差作为重要的评测指标以衡量重压缩对后端智能分析结果的影响。图2展示了典型安防监控场景和其中的智能分析目标对象。
目标检测偏差用于衡量目标检测算法模型在压缩前图像与重压缩后图像上的目标检测指标Recall(IoU@0.5)之间的差异。其中,Recall(IoU@0.5)表示已标注目标的召回率;人脸比对偏差用于衡量人脸识别算法模型在压缩前图像与重压缩后图像上的人脸分别与标注人脸进行1:1比对并计算Accuracy指标后的精度差异;车牌号码识别偏差用于衡量车牌识别算法模型在压缩前图像与重压缩后图像上的车牌识别指标Accuracy之间的差异。行人重识别(Person Re-identification)是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。行人重识别偏差用于衡量行人重识别算法模型在压缩前图像与重压缩后图像上的行人重识别指标(mAP)之间的差异。

图2 典型安防监控场景和其中的智能分析目标对象图,智能分析目标对象包括机动车、非机动车、人和人脸
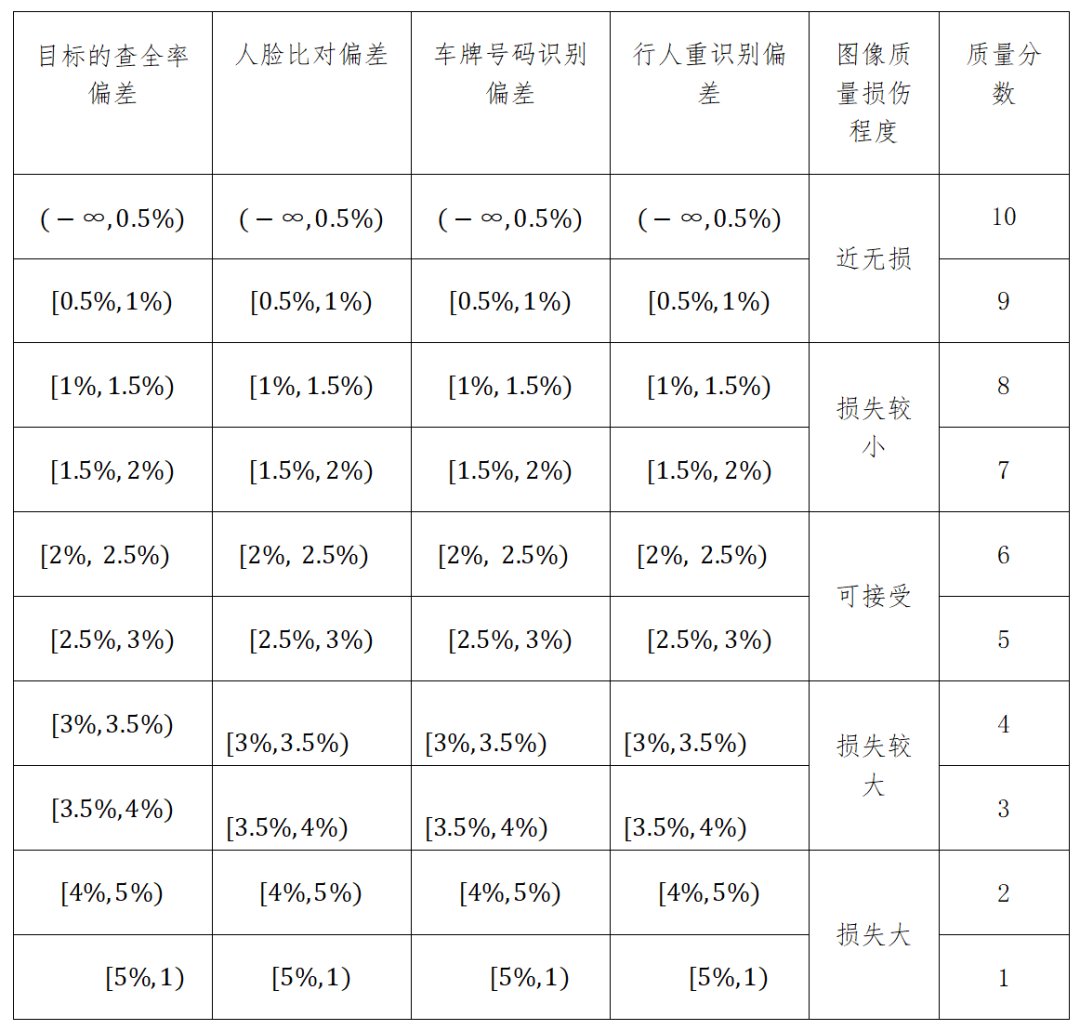
各项指标与图像质量损伤程度对应关系见表2。
表2 各项指标与图像质量损伤程度对应关系表
2.3 评测方法
2.3.1测试系统
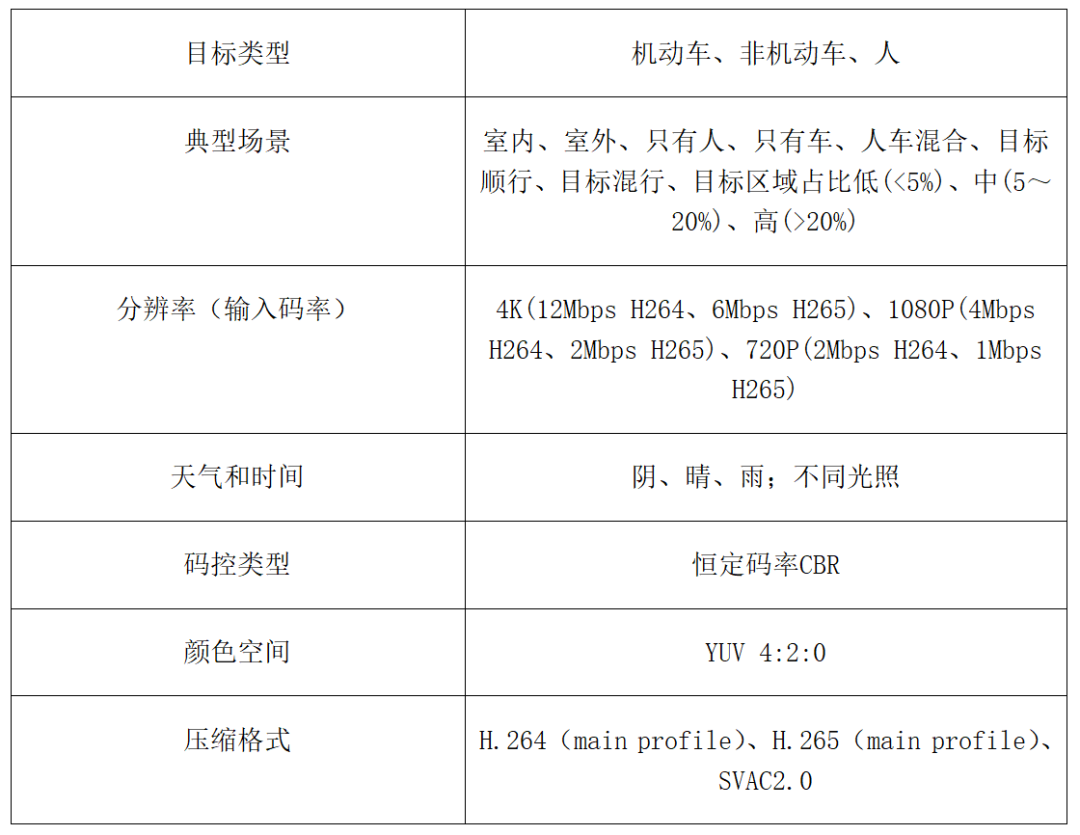
测试系统包括测试工具、测试平台以及智能分析测试模型。其中,测试工具包括测试样本库、用于解码测试样本码流的标准解码器、用于各测试指标的计算的指标计算软件及脚本。我们从安防监控应用的实际情况出发,规定了图像和视频的测试样本库特性,如表3和表4所示。其中,目标类型与智能分析目标对象一致,场景覆盖了典型地点、天气、时间、目标区域占比以及目标运动类型。
表3 测试图像的特性
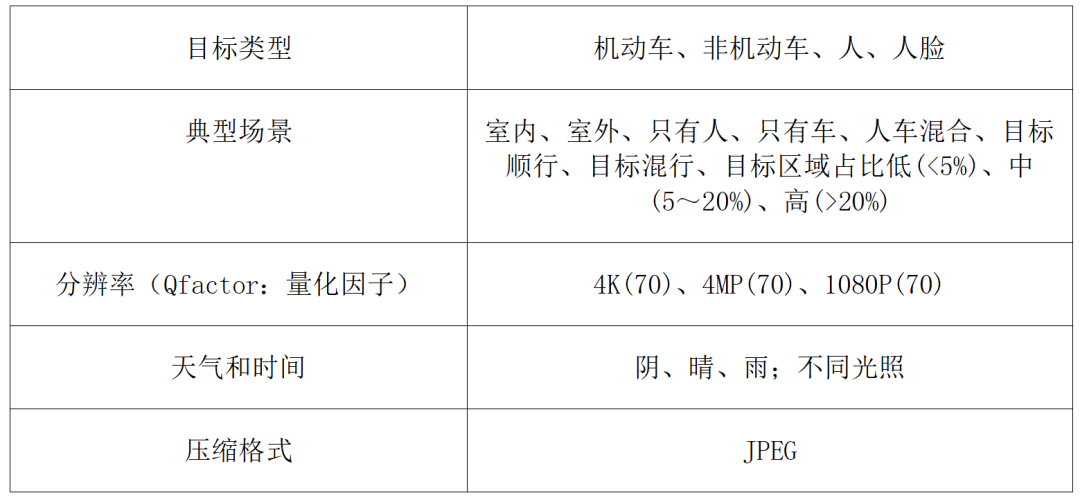
表4 测试视频的特性
2.3.2整体评价流程
如图3所示,选取图像视频测试样本库中的一个测试样本,经过解码、重编码操作获得对应的重压缩样本。依次遍历每一个样本,形成重压缩测试样本库。对图像视频测试样本库和重压缩测试样本库中的主观测试样本对进行主观损伤评价。若主观损伤评价结果为不可接受,则直接输出质量不合格的结果;否则,进行后续的指标测试和综合评价。指标测试模块基于图像视频测试样本库和重压缩测试样本库计算客观质量损伤指标、智能分析偏差指标和压缩倍率。最终,由综合评价模块输出评价结果。

图3 整体评价流程图
主观打分方法,采用DSIS(Double Stimulus Impairment Scale,双激励损伤量表),分别对图像和视频进行主观评价打分。对背景环境和前景目标采用不同的主观质量打分策略;对于客观指标及其质量分数的计算将会遍历样本库中的每个样本,分别计算四个客观质量损伤指标及其质量分数,然后取平均得到样本库结果。对于智能分析指标偏差及其质量分数的计算则基于整个样本库和智能分析标签数据,直接计算四个智能分析指标偏差及其质量分数。
最后利用上述所有测试的客观质量损伤指标和智能分析偏差指标分别对图像与视频进行综合质量评价。实际应用中,采用基于指标赋权模型的综合质量分数计算方法,模型权重按照人眼视觉和机器视觉应用场景进行分别设置,最后根据综合质量评分确定重压缩质量损伤的等级。权重分配时,考虑到客观质量损伤中结构相似度指标与多尺度结构相似度指标关联性较高,其权重较低,其余三个指标平均分配权重。智能分析偏差可根据业务需求,分配指标项权重。客观质量损伤指标与智能分析指标偏差维度权重根据应用场景进行调整。在计算综合质量分数时,各维度、各项指标的权重值可参考表5。
表5 人眼视觉应用场景权重列表举例
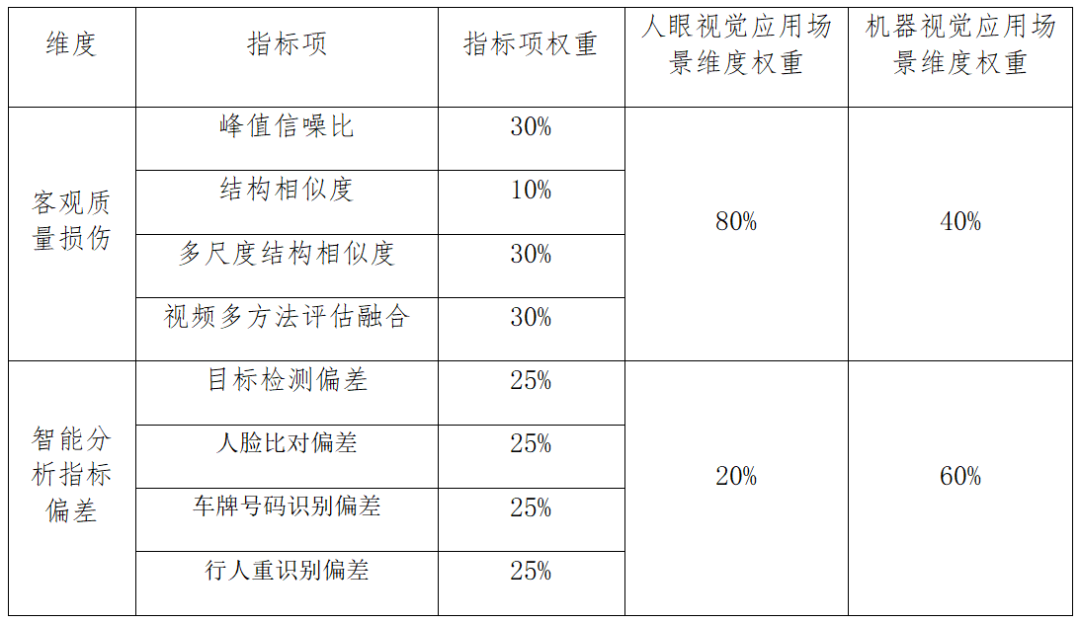
综合质量分数可参考如下方式计算:
综合质量分数=∑k(维度k分数 X 维度k权重),其中,维度k为客观质量损伤、智能分析指标偏差中的一项。
客观质量损伤维度的计算通过各指标的加权获得,维度k分数=∑j(指标项j分数 X 指标项j权重),其中,指标项j为维度k下的指标项。
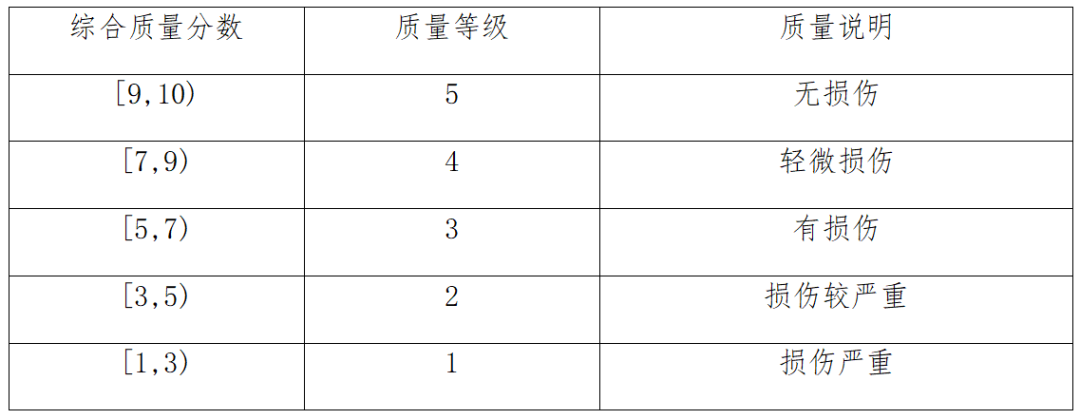
根据综合质量分数,采用五级制的客观评价方法划分视频图像重压缩质量损伤等级,等级越高,表明重压缩质量损伤越小,详见表6。
表6 视频图像质量损伤分级
3 标准应用实例
按照上述评测方法对某厂家的智能存储设备进行全流程评测,结果如下表所示。
表7 智能存储设备评测结果(视频)
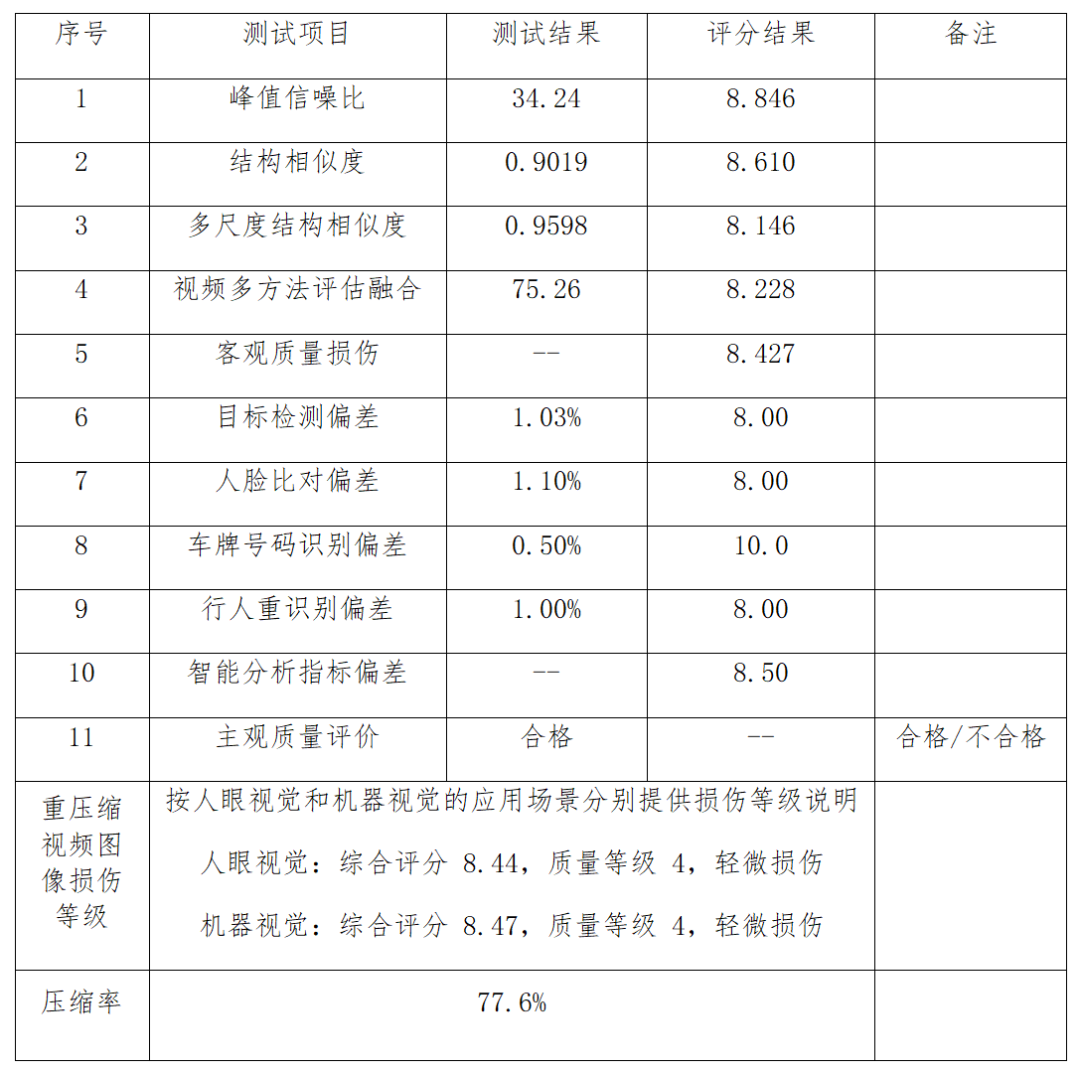
上面结果是按照表6的权重参数计算得到的综合质量分数和损伤等级结果。对于特定应用场景,比如场景中只有人,用户可以将车牌号码识别权重设置为0,其他三个智能分析指标偏差权重平均分配,得到针对该场景的智能分析指标偏差结果。
4 结语
《视频图像重压缩技术评测指标及方法》标准提出了通过主观质量评价、客观质量损伤和智能分析指标偏差三大类一整套评价指标,对重压缩后视频图像进行综合质量评价。其中,主观质量评价只用于判定质量是否合格,可以极大减少评测成本,提高实操性。通过对客观质量损伤指标进行主观拟合,可以将各指标统一到同一尺度,并且具有更好的可解释性。提出的四个常用智能分析任务的指标偏差可以较好地反映重压缩对后端机器分析结果的影响。该方法采用指标赋权模型,可以通过调整各指标的权重,满足人眼视觉和机器视觉各细分场景的质量评估需求。
后续标准研究方向将从重压缩性能评测方法拓展到不同编码格式,以适应基于深度学习的视频图像编码等先进压缩技术的发展趋势,进一步针对基于感知的精细编码、智能量化参数等各类基于深度学习的智能编码开展测试评价方法研究。此外,还需要优化综合评价模型,建立行业典型场景测试数据集与测评基准,推动视频图像压缩质量测评技术的标准化,从而促进视频图像压缩技术应用于更广泛的领域和行业。
参考文献
[1] Thomas Wiegand, Gary J. Sullivan, Gisle Bjontegaard, and Ajay Luthra. 2003. Overview of the H.264/AVC video coding standard. IEEE Transactions on Circuits and Systems for Video Technology 13, 7 (2003), 560–576.
[2] Gary J. Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. 2012. Overview of the high efficiency video coding (HEVC) standard. IEEE Transactions on Circuits and Systems for Video Technology 22, 12 (2012), 1649–1668.
[3] Gregory K. Wallace. 1992. The JPEG still picture compression standard. IEEE Transactions on Consumer Electronics 38, 1 (1992), xviii–xxxiv.
[4] Z. Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli,”Image qualityassessment: from error visibility to structural similarity,” IEEE Trans. IP,vol. 13, pp. 600-612, 2004.
[5] Z. Wang, E.P. Simoncelli, and A.C. Bovik, “Multi-scale structuralsimilarity for image quality assessment,” ACSSC’03, pp. 1398-1402, 2003.
[6] Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823. Project link: https://github.com/timesler/facenet-pytorch.
声明:本文来自公安部检测认证标准化,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
