欧盟在数据驱动创新的背景下,提出“欧洲数据战略”,其中引入“欧洲共同数据空间”的概念,并在《数据治理法》(DGA)中进一步阐述了这一概念。欧盟网络安全局(ENISA)作为提升整个欧洲网络安全水平的机构,于2024年1月发布《欧盟数据空间中设计个人数据保护》(Engineering Personal Data Protection in EU Data Spaces)。[1]报告从个人数据保护工程角度,讨论了欧盟数据空间的设计和部署。报告将介绍欧洲数据空间中数据保护的注意事项,并通过设想制药领域的两个具体应用场景,进一步阐释欧盟数据空间应如何设计个人数据保护。
1 背景:欧盟数据空间
在数据驱动创新(DDL)的时代背景下,欧盟于2020年宣布一项为期五年的“欧洲数据战略”,提出“单一欧洲数据空间”的愿景。欧洲数据战略提出建立“欧洲共同数据空间(以下简称“欧盟数据空间”)”,并在数据治理法(DGA)中进一步阐释这一概念。
欧盟数据空间将创建一个尊重隐私、安全和符合其他相关监管要求的数据共享框架,同时通过实施一系列措施来促进部门间的合作,最终旨在促进创新、经济增长和数字化转型。尽管欧盟数据空间可以产生诸多好处,但由于数据空间中各方有着不同的战略目标和特定的数据需求,协调各方的利益是一项具有挑战的工作。此外,由于欧盟数据空间是在现有欧盟政策和法律框架中运作,探究部门间共同的术语、设计和合规框架,明确适当的数据工程工具至关重要。
(一)欧盟数据空间的设计原则
首先,DGA提供了一个整体的治理框架,强调欧盟数据空间需要遵守欧盟其他相关的政策和法律。其次,为了实现“最有效和最负责任的数据访问和使用”,必须设计、设置和维护欧盟数据空间,提供安全和受监督的数据处理环境,同时保障技术互操作,保护商业秘密、第三方知识产权和个人数据。最后,将采纳有关重新使用条件以及相关的技术和组织措施(TOMs)的基本和统一建议,特别是为了帮助数据持有者了解和调整安全和保密规则,并调整其公司政策,以符合欧盟数据保护要求(GDPR)。
(二)欧盟数据空间的核心:互操作
数据持有者有义务推进互操作。实际上,数据共享服务提供商应“促进按照其从数据持有者那里收到的格式交换数据,并且仅在跨部门内部或跨部门之间增强互操作性,或是由数据用户要求,或根据欧盟法律规定,或为了确保与国际或欧洲数据标准的协调,而将数据转换为特定格式”。互操作首先应在欧盟层面加以定义,同时还应考虑技术标准或公认规范。中介机构可促进个人数据的互操作和共享,协助数据持有者对个人数据进行匿名化或假名化,制定和执行个人数据共享协议或促进个人权利的行使。
2 欧盟数据空间中数据保护的注意事项
(一)欧盟数据空间关键术语
根据DGA的定义,欧盟数据空间由三个主要参与者组成:数据持有者、数据中介和数据使用者。
● 数据持有者:是法人,不是相关特定数据的数据主体,但有权授予访问或共享某些个人数据或非个人数据的权利。
● 数据中介:充当数据持有者和数据使用者之间中介的实体。数据中介通过提供数据访问等服务,在促进安全和可控的数据共享方面发挥着作用。
● 数据使用者:能够合法获取某些个人或非个人数据,并有权将从数据中介中获得的数据用于商业或非商业目的的自然人或法人。
DGA适用于“行为、事实或信息的任何数字表示形式”,包括个人数据。数据持有者负责确保数据被合法和适当地收集、处理和存储,数据中介提供服务以促进受控数据共享、处理和存储,数据使用者接收并将数据用于各种目的,例如分析和研究。当共享数据包含个人数据时,需要同时满足DGA和GDPR的规定。DGA和GDPR创建了一个在数据持有者、数据中介和数据使用者共同努力下,确保负责任且合规地共享、处理和使用数据的框架。

欧盟数据空间主要参与者关系图
(二)数据共享环境中输入隐私和输出隐私问题
在进行数据共享之前,首先需要考虑数据共享环境中(欧盟数据空间)可能出现的数据主体的隐私风险,主要是面临输入隐私和输出隐私两方面的挑战。输入隐私问题的目标是允许在共享的数据中进行处理,同时确保共享环境无法恢复到初始数据状态,从而避免个人被单独识别或辨认。输出隐私问题的目标是防止在共享环境执行计算后挑出或识别个人。
处理输入隐私和输出隐私问题是欧盟数据空间中数据隐私与安全的关键,目的在于确保个人数据从收集到结果共享的整个过程均受到有效保护。解决这两种风险的方法是遵守GDPR的原则,并遵守数据保护工程相关的要求[2]。
(三)数据保护工程的作用
欧盟数据空间旨在实现数据共享机会和个人数据保护之间的平衡,避免二者之间相互阻碍。但是,如果不解决欧盟数据空间中固有的法律和技术方面的数据保护问题,将会阻碍数据共享,并限制欧盟数据战略的实施。因而,数据保护工程(Data protection engineering)对推动欧盟数据空间的部署起到关键作用。
数据保护工程不仅是为了遵守GDPR而存在的“合规工具”。数据保护工程可以在数据共享和数据保护之间取得平衡。数据保护工程通过采取适当的措施和必要的保障,在实现数据共享的同时,同时最大程度降低信息滥用、数据泄露或其他安全威胁风险。尤其是在新兴技术方面,采用新的、尚未确立最佳实践的措施,可能会对技术采用产生不利影响。数据保护工程可以通过制定标准并借鉴现有的良好实践来促进新技术的实施,由此降低采用这些技术时的复杂性和不确定性。
在欧盟数据空间中,数据中介在处理风险方面起到关键性作用。当数据控制者确定数据处理活动中存在潜在的风险,就会出现如何缓解已确定的风险问题。此时,数据中介可能需要做出有关风险缓解的决策。例如,隐私增强技术(PETs)的应用是风险缓解的标准方法之一。数据中介要能够准备好这些技术的实施方案,并能够根据数据控制者的指示,在每个相关的数据共享场景中动态地部署这些实施方案到相应的数据集上。
(四)数据空间中的数据保护影响评估
数据保护影响评估(DPIA)旨在确保控制者能够充分解决“有风险”的处理操作中有关隐私和数据保护的风险。DPIA可以提供一种结构化的方式解决和减轻数据主体的风险,并帮助组织在“有风险”的处理操作中遵守“设计数据保护”的要求。[3]数据保护工程通过(半)自动化的方式收集和提供有关DPIA所需信息,由此帮助数据控制者执行DPIA的要求。
● 数据中介在DPIA中的作用
由于DPIA中的关键活动是确定和评估涉及数据主体权利和自由的风险,数据中介可以执行这类活动,并自动向数据控制者提供已识别的风险及有关信息。这样,数据控制者可以将这些风险整合到其DPIA中。
● DPIA的复杂性
DPIA的过程不仅仅是对数据控制者和数据处理者风险列表的串联,同时还需要考虑额外的来自协作实体(即数据控制者和数据处理者)的组合风险。组合风险与单一的组织风险存在差异,因为组合风险取决于具体的交互操作,并且只有在分析整体协作和处理操作时才能观察到。因而,支持具有多个数据控制者和数据中介的整体DPIA是一项非常重要且复杂的任务。这需要在整个处理操作和欧盟数据空间部署的过程中对其加以密切关注。
(五)问责制的主要内容
控制者有责任并且能够证明其行为符合GDPR第5(1)条规定的个人数据处理原则。因此,控制者有责任采取必要的措施以符合GDPR的要求,并能够随时证明其合规性,而无需监管机构进行具体询问和要求评估合规性。
无论控制者或处理者是公共实体还是私人实体,所有愿意促进个人数据重复使用以实现社会和经济利益的数据持有者,都必须通过相应的内部机制(政策、程序、基于风险的评估、控制措施以及其他与数据共享相关的措施)、数据共享协议和合理的隐私管理计划(PMPs)来符合问责制的要求。根据《数据治理法》关于欧盟数据空间的规定,问责制主要包括以下十个方面:
1. 明确数据持有者和数据使用者的责任和义务
数据持有者必须遵守法律义务,例如GDPR下的义务(在与任何其他方共享个人数据之前建立合法基础),接收数据的使用者同样须遵守法律义务(在合法的基础上进行其处理活动)。此类义务可以在协议中规定(参见第9项)。
2. 个人数据共享的有效内部治理
需要有效处理数据共享产生的责任和义务。例如,起草数据共享协议,采取和实施额外的技术和组织措施(TOMs)。这种治理模型应明确界定涉及数据共享与数据处理者和子处理者(或中介和其他有权第三方)共同监控数据处理的情况。
3. 个人数据共享的合作外部治理
明确数据持有者如何与其他目标合作伙伴,同部门机构和主管机构、欧洲委员会、欧洲数据创新委员会(EDIB),以及任何负责更好地规范数据再利用的利益相关方进行合作,特别是在处理可能存在的数据泄露方面。
4. 实施数据共享计划
制定政策、程序和其他措施,以确保数据持有者在共享个人数据时承担应有的责任,并有效降低数据共享所带来的风险。
5. 有针对性的数据共享问责工具的设计
降低个人数据共享带来的风险,包括临时访问和保障数据再次使用的安全机制,以及对数据持有者或使用者进行补充尽职调查。
6. 平衡安全/风险缓解目标和共享足够质量数据的要求
数据持有者和数据使用者必须将数据保护嵌入到应用程序、设备和系统的设计中(即PETs),同时确保这些措施不剥夺数据使用者使用有质量、相关性和相对可靠性的数据。在实践中,数据共享效率的评估包括数据安全与数据质量两个方面。
7. 对设想的数据共享实践进行道德评估
有针对性的评估应考虑与数据共享处理相关的风险(不存在任何非法、不公平或欺骗性行为,或没有任何分享个人数据以损害或不利于个人或一群个人的意图),以及此类数据共享处理的好处(任何因为缺乏数据再次使用而损害公共利益的情况)。
8. 数据持有者和数据使用者之间透明的信息共享
接收个人数据的一方必须就所拟进行的处理目的进行有针对性的风险评估,并明确告知数据持有者。数据持有者必须考虑可能希望对接收方施加的任何额外保障或控制,以确保数据的安全性、公平性和保密性。
9. 通过基于部门或有针对性的数据共享协议,在欧盟数据空间内(访问)以及从一个数据空间到另一个数据空间(互操作)制定数据共享实践的合同框架
数据持有者和数据使用方需要考虑其具体的责任和义务,并以适当和与已识别风险相称的方式对其加以明确规定(具体情况分析)。明确各方的责任、设定具有约束力的义务以及确定责任框架,这些都是建立信任的关键。具体而言,协议需要详细说明在数据共享安排下,各方作为数据持有者、数据使用者、数据控制者、处理者、子处理者、中介或第三方的特定资格。或者,为确保所有个人数据都是合法收集并且提供透明信息,可以通过规定保障措施条款的方式进行严格评估,例如数据自愿和透明的限制性使用或制定有针对性的合同保障措施。
10. 对个人的透明度
数据持有者和数据使用方都必须确保个人了解他们的个人数据是如何被共享和再次利用的,并告知个人如何在实践中行使他们的权利(例如拒绝数据共享或删除的权利)。这种“透明度”义务可能取决于数据共享是否由法律规定或由公共部门决定,还是临时或个人决定的结果。
除此之外,数据持有者和数据使用者在《数据法》下从事类似的行为同样要承担相应的责任义务,这可以通过实施上述提及的构成要素来处理。
(六)通过保障措施和可信的中介机构实现高效的欧盟数据空间
实践中,问责制和处理并非创建有效和可互操作的欧盟数据空间唯一的途径。在制定数据共享项目之前,数据持有者应考虑是否需要与接收方签订数据共享协议,以履行其责任义务或降低对个人已识别风险的影响。这包括明确数据共享的目的、定义安全措施,并确保每一方清楚其角色和责任、各自的治理义务。
此外,无论是“旨在帮助个人行使GDPR下的权利”,或是“促进大量相关数据的汇总和交换”,还是“加强数据的高效汇总以及双边数据共享”,数据中介发挥着至关重要的作用。尽管数据中介的任务和责任在实践中仍需进一步调整和证明,但其应当始终坚持“不将交换的数据用于任何其他目的”。因此,必须在实践中就技术和组织措施达成协议,并进一步明确其规定。
3 应用场景分析:健康—医药用途
2020年欧盟发布欧盟医药战略,旨在应对制药行业面临的各种机遇和挑战,以确保欧盟公民对于药品的可获得性、可负担性和可持续性。[4]报告将药品数据空间作为一种可能的手段,旨在支持数据使用者对于药品市场供应情况和药品功效的研究和分析。两个应用场景均说明了不同参与者应该如何部署脱敏数据保护工程技术,从而向数据用户提供有用但得到充分保护的数据集。
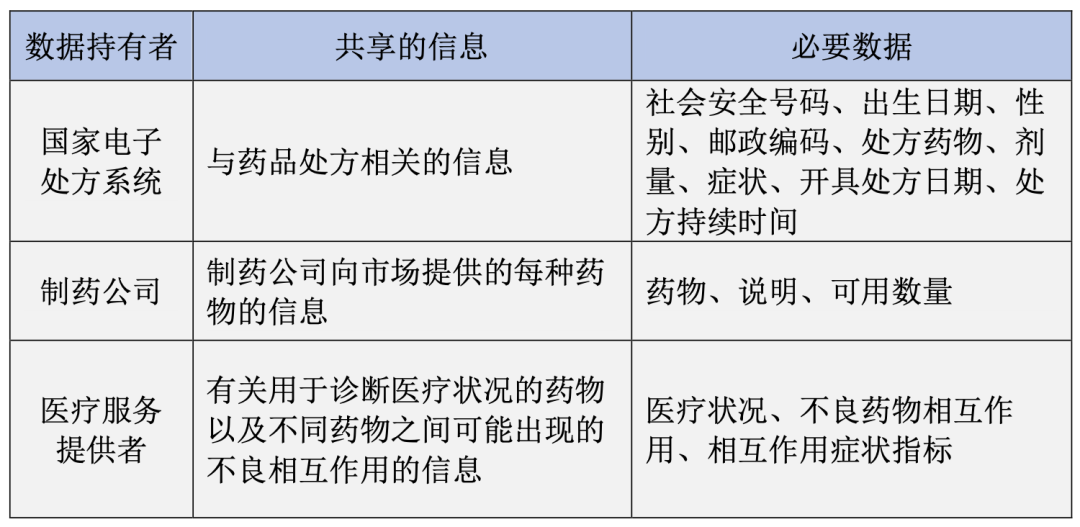
(一)应用场景一:市场上药品的供应情况
设想的药品数据空间的预期用途之一是确保市场上药品的可用性。假设存在三种主要的数据持有者:国家电子处方系统、制药公司和医疗服务提供者。国家监管机构为数据使用者,旨在收集有关药物处方现状、制药公司药物的可用性以及在特定组合不推荐时需要替代药品的情况。
1. 使用的技术方法
本应用场景中,数据保护工程的目标是确保中介机构能够响应数据使用者(国家监管机构)的请求,并且保证数据使用者无法识别或挑出个人。为了实现这一目标,数据持有者在共享数据时应使用特定的脱敏数据保护工程技术,具体来说:
● 国家电子处方提供者基于只有数据持有者知晓的密钥k(key k),通过用确定性生成的假名(deterministically generated pseudonym)替换特定字段(specific fields),为每个要共享的记录创建标识符(identifier)。相同的密钥k适用于所有记录。例如,可以使用一个带密钥的哈希函数(keyed hash function)(例如消息认证码 - MAC)[5]。在当前情况下,社会安全号码(SSN)可以用作标识符。
● 因为尚未解决所有的数据保护风险,由处方提供者共享的数据集不能被视为完全匿名化(fully pseudonymised)。这是因为所谓的准标识符(quasi-identifiers)[6]仍存在重新识别的风险,因此数据持有者需要进行适当的脱敏处理。这方面的技术包括属性泛化(attribute generalization)。在本应用场景中,准标识符(及其可能的泛化)包括以下内容:
(1)出生日期:将其替换为一定范围的年龄(例如,50-55岁)。
(2)邮政编码:将其替换为邮政编码的前三个字符;这三个数字足以提供有关居住地更广泛地区的信息。
(3)开药日期:用月份和年份替换,而不是使用完整的日期。
2. 注意事项
在这个设想的数据共享情景中,数据持有者与数据中介共享数据集之前进行脱敏处理(masking)和泛化(generalisation)。然而,这种方法在实施中存在一些挑战,即如何建立一种机制来确保各个数据持有者在相同水平上实施泛化至关重要。例如,如果一个数据持有者选择了“45-50”岁的泛化字段,那么另一个数据持有者就不应该选择不同的泛化字段,比如“40-50”岁。因此,数据持有者需要“共同同意(jointly agree)”特定的参数。但参数的正确选择又是一项困难的工作,因为其高度取决于每个特定数据集。
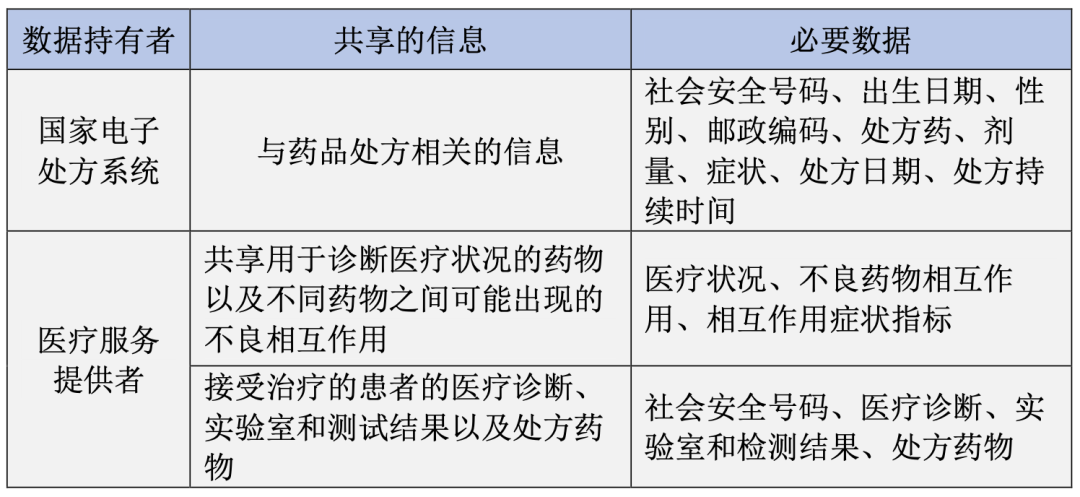
(二)应用场景二:药品功效研究和分析
药品数据空间另一个用途是支持药品功效的研究和分析。在这种情况下,主要有两类数据持有者:国家电子处方系统和医疗服务提供者。此时,数据使用者为研究机构,旨在评估药品在治疗特定症状方面的有效性以及不良药物相互作用如何影响其有效性的信息。
1. 使用的技术方法
在此用例中,实施数据保护工程有两个设计目标:其一是中介机构应该能够响应数据用户(研究机构)的请求,而无法识别或挑出个人;其二是数据使用者不能识别或挑选个人,并且不能关联数据。为了实现这两个目标,数据持有者在共享数据时应使用特定的脱敏数据保护工程技术。
● 国家电子处方提供者将要分享的数据集进行脱敏处理。社会安全号码(SSN)字段被替换为基于仅为数据持有者所知的密钥k生成的确定性生成的假名,并且准标识符被替换为范围。需要再次指出的是,上述每种泛化的程度取决于输出结果的风险水平是否不会允许再识别或单独识别个体。[7]
● 医疗服务提供者使用基于仅数据持有者知晓的密钥k的确定性生成的假名来掩盖数据集中要共享的SSN。由于不同的数据持有者使用不同的密钥对相同的字段进行假名化,因此数据中介无法将来自不同数据持有者的数据相关联,这些数据所引用的是相同的SSN。
● 中介机构将利用多态加密和假名化(PEP)技术[8]将数据集传输给数据使用者,同时,中介机构还将作为转码器。[9]每个数据集将为每个数据使用者分配不同的假名,从而防止跨多个数据使用者的假名链接(pseudonym linking)。此时,中介机构对已经假名化/泛化的数据进行了脱敏处理的同时,充当了可信任的第三方假名化实体(third-party pseudonymising entity)。[10]
2. 注意事项
本用例设想了数据持有者在将数据集与数据中介共享之前对其进行了脱敏处理和泛化操作。然而,数据中介在这之后还需要进行额外的脱敏处理。这种情况下,数据中介不仅是数据共享媒介(brokers),还强调了其作为可信任组织者的角色。然而,这增加了数据中介的责任和义务。即使不深入分析数据中介应被视为控制者还是处理者,它都必须能够满足数据主体和数据使用者的需求和权利,跟踪数据来源和数据处理任务,并在数据处理生命周期的多个阶段评估和更新数据使用政策。
4 结语
欧盟数据空间是欧洲数据战略中的一个新兴概念,旨在推动欧洲数据经济的发展。确保欧盟数据空间在现有欧盟政策和法律框架内运作至关重要。数据保护工程为数据控制者提供了一种实用的选择,在强化数据保护原则和保障个人权利行使的同时,最大限度地降低了信息滥用、数据泄露或其他安全威胁的风险。尽管欧洲数据空间具有巨大潜力,但如何在数据共享机会与数据安全之间取得平衡仍需要实践进一步的发展和探索。
[1] ENISA,Engineering Personal Data Protection in EU Data Spaces,https://www.enisa.europa.eu/publications/engineering-personal-data-protection-in-eu-data-spaces.
[2] ENISA,Data Protection Engineering: From Theory to Practice,https://www.enisa.europa.eu/publications/data-protection-engineering.
[3] European Data Protection Supervisor,Data Protection Impact Assessment (DPIA),https://www.edps.europa.eu/data-protection-impact-assessment-dpia_en
[4] European Commission, A pharmaceutical strategy for Europe, https://health.ec.europa.eu/medicinal-products/pharmaceutical-strategy-europe_en.
[5] ENISA,Recommendations on shaping technology according to GDPR provisions - An overview on data pseudonymisation,https://www.enisa.europa.eu/publications/recommendations-on-shaping-technology-according-to-gdpr-provisions.
[6] L. Sweeney, k-anonymity: a model for protecting privacy, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol. 10, no. 5, p. 557–570, 2002.
[7] ENISA, Data Pseudonymisation: Advanced Techniques and Use Cases, https://www.enisa.europa.eu/publications/data-pseudonymisation-advanced-techniques-and-use-cases.
[8] M. Hildebrandt, E. Verheul, B. Jacobs, C. Meijer and J. de Ruiter, Polymorphic Encryption and Pseudonymisation for Personalised Healthcare: A Whitepaper, 2016.
[9] ENISA, Engineering Personal Data Sharing, https://www.enisa.europa.eu/publications/engineering-personal-data-sharing.
[10] 同前注[5]
撰稿 | 寇晨雪,清华大学智能法治研究院实习生
修改、指导 | 刘云
编辑 | 朱正熙
注:本公众号原创文章的著作权均归属于清华大学智能法治研究院,需转载者请在本公众号后台留言或者发送申请至computational_law@tsinghua.edu.cn,申请需注明拟转载公众号/网站名称、主理者基本信息、拟转载的文章标题等基本信息。
声明:本文来自清华大学智能法治研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
