文丨中国邮政储蓄银行运营数据中心 黄海 杜金鑫 韩泽瑞
随着数据中心基础设施规模的持续增长,设备运行风险缺乏有效数据辅助监测与管理等问题日渐凸显。对此,邮储银行提出了一种基于数据挖掘的网络设备风险评估方式,通过建立设备运行风险评估模型,提前分析设备健康状况和维护需求,预测设备老化风险并制定科学合理的维护计划,从而进一步提高数据中心网络设备整体服务能力。
近年来,邮储银行业务量持续增长,IT架构转型加速推进,数据中心的基础设施规模也随之不断扩大。然而,网络基础设施资源的长期运行同样也带来了复杂性、不确定性、维护难度、维护成本等诸多问题,尤其是老旧设备运行风险缺乏有效数据作为研判依据。为改善上述情况,邮储银行基于大量的静态设备信息数据、动态线上配置数据、线上运行数据以及运维数据,通过从静态和动态两方面进行统计分析,建立设备预测性维护模型,有效提高了设备的整体可靠性和稳定性,在降低维护成本和运行风险的同时,助力信息系统业务连续性水平跨上新的台阶,进一步增强了银行的核心竞争力。
一、网络设备维护难题和挑战
在传统的数据中心网络硬件基础设施运维过程中,通常是基于人工操作和运维经验来判断是否需要进行设备更新维护。这种方式虽然能够发现问题并及时处理,但整体效率较低,且容易出现漏检和误判的情况。尤其是随着设备数量和类型的不断增加,网络硬件基础设施维护及更新替换正面临新的更大挑战:
一是数据质量挑战。网络设备的运行和巡检信息不仅数据量庞大,而且具有多元化的特点,需要耗费大量时间进行人工分析和判断,同时相关结论的准确性和可靠性也难以保障。二是维护流程复杂。网络设备维护通常需要多人乃至跨部门合作,这不仅增加了制定设备更新、替换策略的复杂性,决策的时效性也往往较为滞后。三是维护决策的可解释性和实际应用性不强。网络设备维护牵涉到多个复杂因素的综合分析,导致最终决策经常显得复杂和抽象,不便于记录、解释和理解。
二、设备运行风险评估模型设计
针对上述痛点问题,邮储银行探索建立设备运行风险评估模型,以更好地预测设备老化风险、制定设备维护计划,并通过对设备基础指标信息、运行信息和巡检信息等进行深度分析,同步评估设备的健康状况和维护需求。
1.数据源选取与预处理
邮储银行为设备运行风险评估模型选取的设备信息数据涵盖了两地四中心所有网络设备,相关数据主要采集自网络设备CMDB库和网络自动化平台设备信息采集库。结合数据建模需求,邮储银行选择数据指标特征建立指标分析体系,全面覆盖设备名称、设备的型号、设备的服务级别、设备的品牌、设备的上架加电时间、设备是否监控、设备类型、设备的用途、质保开始日期、质保结束日期、设备评分、设备的状态、下架时间、设备资产信息、运行质量、配置信息等内容。
2.特征分析与处理
针对数据源各原始指标特征,邮储银行从七个方面开展了特征分析与处置:一是对各种不合法字符和不合逻辑的数据进行了处理,并对部分空值进行了预处理,即把各处空值填充为“指标_unknown”。二是针对训练数据的类别不平衡问题,采用了基于欧式距离的Smote算法和Smote-enn算法进行重采样,并引入类别权重法来检验数据类别的均衡性。三是对设备的品牌、设备的用途、设备的服务级别、设备是否监控等各类信息进行了独特编码转换。四是对数据列中设备类型、设备的型号等进行了目标编码变换。五是对时间序列中设备的上架加电时间进行了信息拆分。六是对数据列中质保开始日期、质保结束日期进行组合预计算,确定了新的数据列“质保时长”。七是对整体数据进行了Z-score标准化。通过上述一系列举措,邮储银行确定了最有助于模型训练和预测的指标特征,并对其进行了可视化呈现(如图1所示)。
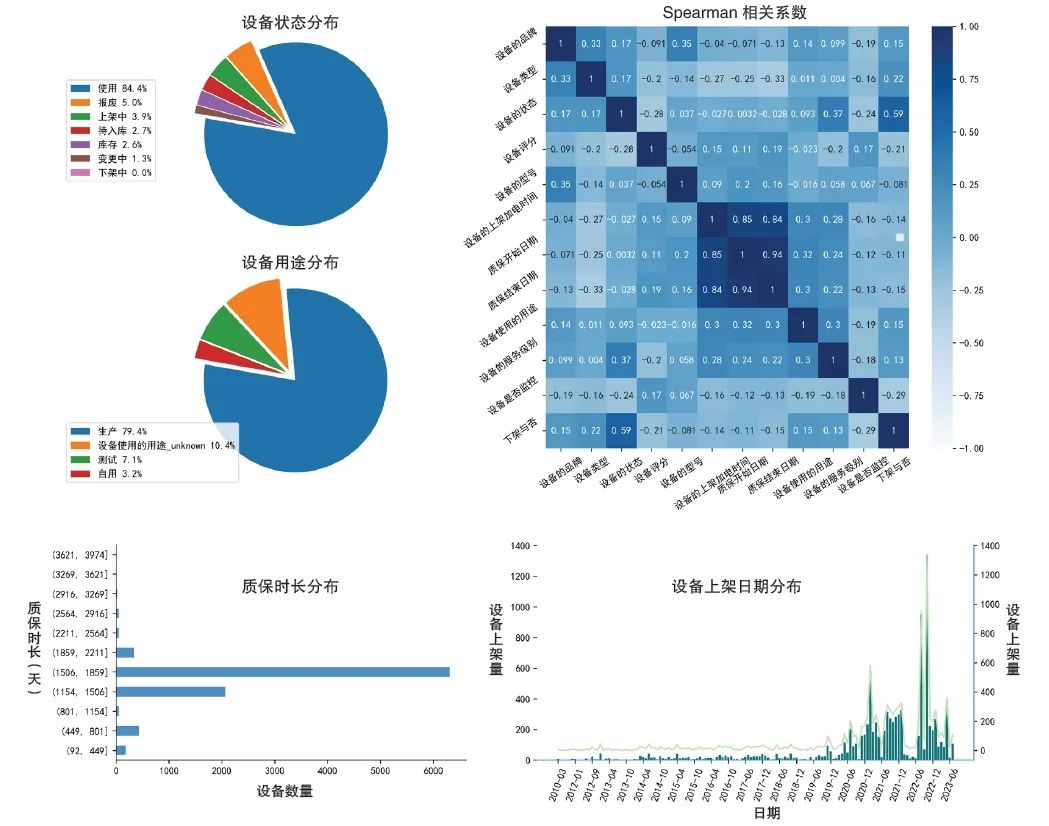
图1 重要指标特征分析结果
分析结果显示,在设备用途上,生产设备占比最多(79.4%);在设备状态上,使用中的占比最多(84.4%);在质保时长上,大部分设备的质保时长在3~5年之间;在设备上架日期上,大部分设备上架于2020年之后。此外,“Spearman相关系数”反映了两特征之间的相关程度,完全正相关为1,完全负相关为-1,绝对值越接近0,则两特征之间的相关性越弱。综合来看,设备的上架加电时间、质保开始日期、质保结束日期这三个特征的相关程度较高。
3.模型构建
在实际建模过程中,邮储银行选择采用深度神经网络模型进行DNN建模。基础DNN模型主要由1个输入层、3个隐藏层和1个输出层构成。其中,输入层负责输入特征数据,可将输入数据转化为神经网络内部可以处理的格式,并传递到下一层;隐藏层位于输入层和输出层之间,负责将输入数据转换为更高层次的特征表示,每个隐藏层输出指定的维度向量。第一个隐藏层更多关注初步的模式和特征,而后续的隐藏层则逐渐对特征进行抽象和组合,最终为输出层提供能够直接用于预测或分类的高层特征表示;输出层是神经网络的最后一层,用于输出神经网络针对输入数据的预测或分类结果。基础DNN模型如图2(a)所示。具体而言,邮储银行使用了Tensorflow搭建DNN模型,模型输入向量为37维,含有三个隐藏层(维度分别为64、64、64),隐藏层的激活函数为ReLU,输出层由Sigmoid激活函数将结果映射到(0-1)之间,表示预测为正样本的概率,损失函数为交叉熵损失。然而,由于正负样本的不平衡,在模型训练时,令正负样本权重之比为25:1。对此,邮储银行在基础DNN模型的基础上,通过减少网络宽度、增加网络深度,进一步设计了改进模型。改进DNN模型如图2(b)所示。与基础DNN模型相比,改进DNN模型增加了隐藏层的数量,维度分别为32、64、32、64、32,从而使模型具有更好的特征提取能力。
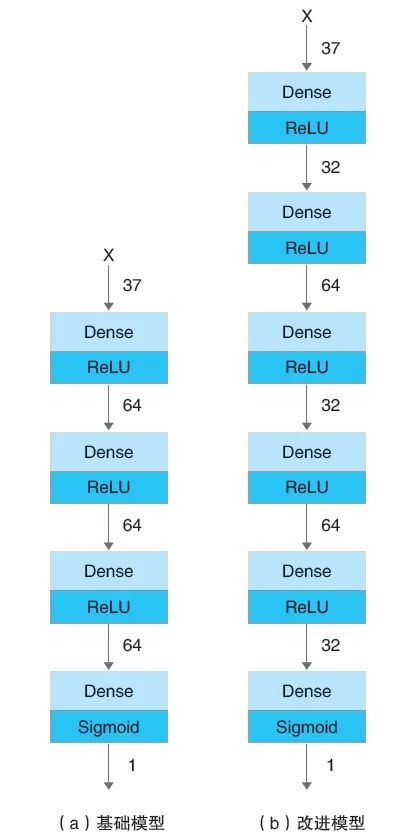
图2 基础DNN模型与改进DNN模型对比
4.模型评估与验证
模型建成后,邮储银行着重从以下六个方面对模型进行了反复训练和评估。一是数据集划分,即将原始数据集划分为训练集、验证集和测试集,以便在训练过程中更好地评估模型性能。二是优化算法,即采用自适应矩阵估算法(Adam),通过自适应学习率和二阶矩阵来更新模型参数,加速模型收敛并提高训练效果。三是超参数调优,即通过调整模型的超参数来优化模型性能。四是交叉验证,即使用交叉验证技术来评估模型性能,以避免发生过拟合和欠拟合问题。五是模型选择,即根据模型在验证集上的表现来选择合适的模型。六是监控方案,即通过监控模型在实际应用中的表现,来确保其稳定性和可靠性。
5.结果分析
分析模型经过训练、评估、验证后的输出结果发现,改进模型在各项评价指标上均有较大提升,与基础模型相比效果明显更好。实际操作中,邮储银行通过混淆矩阵实现了对预测结果的全面直观诠释,并通过计算准确率、精确率、召回率以及F1值,实现模型分类质量评估。其中,准确率表示预测正确的样本占总样本的比例,精确率表示预测为正的样本中实际为正样本的概率,召回率表示实际为正的样本中被预测为正样本的概率。一般而言,准确率和召回率均是越大越好,但随着召回率的提高,准确率通常会下降,所以需要能够综合考虑二者的评价指标,而F1值是最常用的平衡精确率和召回率的调和平均值。与基础模型相比,改进模型的准确率提升了0.016;在正样本中,各项指标提升较为显著,精确率提升了0.192,召回率提升了0.027,F1值提升了0.138;在负样本中,改进模型的召回率也有较大提升;在精确率、召回率、F1值的宏平均和加权平均值上,改进模型也都优于基础模型。DNN模型混淆矩阵对比如图3所示。
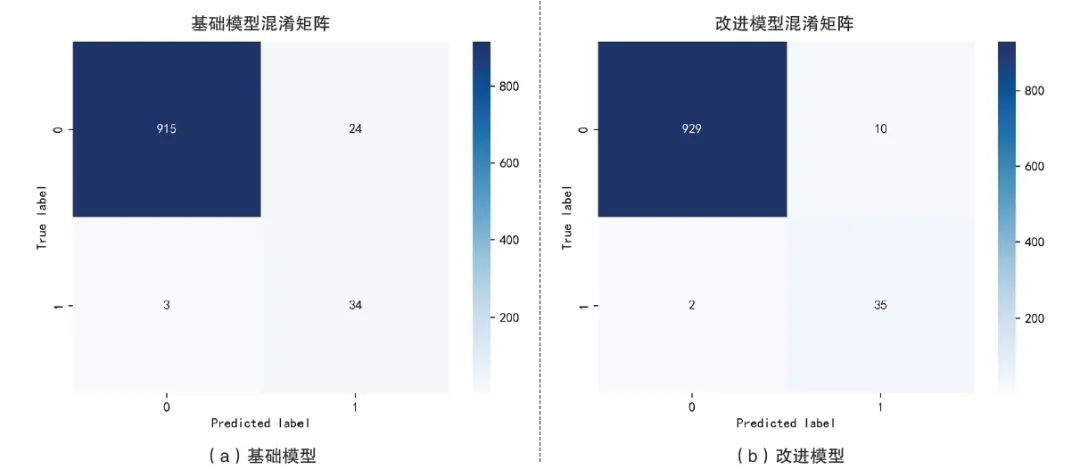
图3 DNN模型混淆矩阵对比
通过混淆矩阵对比,将可更加直观地显示改进模型的准确性和可靠性。与基础模型相比,改进模型在以下三个方面的表现更加优异:一是改进模型的特征提取能力更强。改进模型通过强大的特征提取能力,能更好地识别和区分上下架状态的设备,从而提高预测的准确性。二是改进模型对设备上下架状态的预测更为准确,有助于进一步提升设备管理效率,减少人力成本。三是改进模型在精确率和召回率方面都有较大提升,即在识别上下架设备时将产生更少的错误预测,从而降低整体错误率。
三、应用展望
综上所述,设备运行风险评估模型旨在为网络设备的维护管理提供决策支持和信息服务,即从设备维护计划、预算编制、升级替换决策、故障处理等方面,辅助优化和提高网络管理效率,进而为网络设备的规划、设计和管理提供可靠支撑。后续,基于设备运行风险评估模型,邮储银行将逐步对两地四中心网络设备开展下架需求预测,推动网络硬件基础设施资源的更新替换;同时,通过进一步引入大数据和人工智能技术,持续提升模型的实用性和适用性,基于更加智能的设备管理策略,为网络硬件基础设施资源的采购、维护、规划、设计和管理等提供科学依据。在预测精准性方面,邮储银行将探索使用更为先进的神经网络模型持续优化模型结构,并尝试引入元分类器等搭建预测大模型,进行更加精准的类别预测、回归预测等,以高质量运营保障赋能银行业务发展。
本文刊于《中国金融电脑》2024年第4期
声明:本文来自中国金融电脑+,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
