报告导读
观点1:承载大语言模型部署的平台中,Ollama因其易用性和普适性,占比最高,可见降低开发难度和硬件需求对大语言模型的普及有着重要的推动作用。
观点2:我国大语言模型服务部署量占全球部署量的接近一半,国内大陆地区对于大语言模型技术的需求更为旺盛,北京(19%)、浙江(16%)、广东(15%)三省尤为突出,作为对比的是港台地区合计不到10%。
观点3:个人用户和企业用户对大语言模型服务的部署量比例约为4:6,说明个人用户对构建数据可控、模型可调的“智能助手”具有较强的需求和热情,但安全意识欠缺,对信息加密和服务认证部署覆盖率极低。
观点4:通过追踪大语言模型服务持续开放情况分析发现,大部分尝鲜用户会逐步放弃维护,只有少量的大语言模型服务会持续投入到实际应用中。
自2025年春节以来,随着国产大模型的崛起,越来越多的企业和开发者开始尝试在本地部署私有化的大模型服务。这一趋势的驱动力,一方面源于企业对数据隐私保护的刚性需求,希望通过本地化部署避免敏感数据外流;另一方面则是对模型可控性的追求,开发者需要根据业务场景进行定制化调优。为满足这一需求,开源社区涌现出多个热门的部署工具,其技术路线各具特色。
目前使用最多的是基于Ollama部署模型,结合Open WebUI提供服务的解决方案,该方案采用容器化架构,并通过量化压缩技术将大模型封装为可移植镜像,配合直观的Web界面实现一行命令、开箱即用。另外,一些解决方案会基于LiteLLM为各类模型提供webAPI接口,供其他应用调用;另有基于vLLM快速本地化部署方案能够基于PagedAttention等内存优化技术,通过异步批处理显著提升GPU利用率,特别适合高并发推理场景。
然而这些工具在追求部署便利性和推理效率的同时,普遍存在安全机制缺失的隐患。技术分析显示,Ollama默认开放11434端口且未设置身份验证层,vLLM的REST API未集成权限控制系统,LiteLLM的代理服务也未强制要求认证。这些未鉴权的服务一旦暴露在公网环境中,就变成了暴露面中的薄弱环节。攻击者可绕过认证直接批量调用模型造成拒绝服务攻击,甚至可以通过文件上传实施恶意文件和代码注入,轻则造成服务中断,重则造成严重的数据泄露、模型灭失或系统入侵风险。
本报告基于中国电信云堤·广目测绘能力,综合分析了包括Ollama、vLLM、LiteLLM、LocalAi等各类常见大模型网络服务软件的主机在公网服务的暴露情况和安全情况,进而揭示大语言模型公网暴露的一系列问题。
不同国家大语言模型
服务软件的公网暴露情况
如图1所示,大模型软件在全国各省都有一定数量的公网暴露。其中,北京、浙江、上海、广东等沿海或经济发达省份的暴露数量明显较多,而中西部地区相对较少。
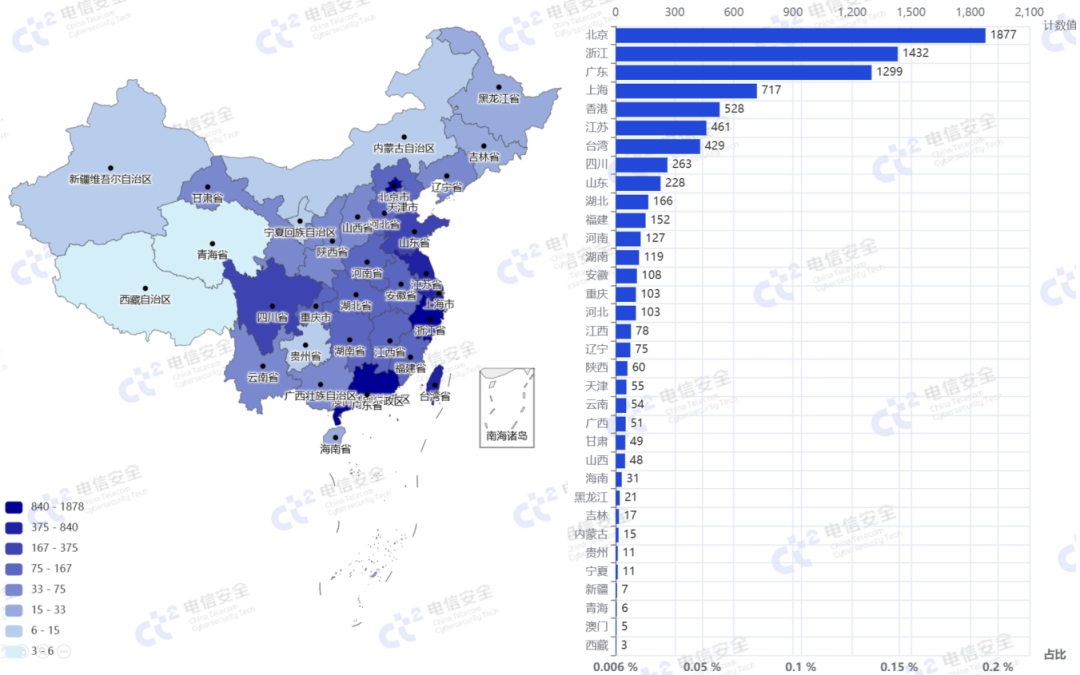
图1 大模型软件的公网暴露主机国内省份分布情况
特别值得注意的是,尽管港台地区公网IP资源较为丰富,但在大语言模型服务软件的使用情况上落后于大陆地区,这体现了大陆地区对于新技术的需求更为旺盛、跟进速度较快。排名靠前的省份大多是IT产业集中的地区,其企业和个人用户规模较大,因此出现大模型实例暴露的可能性更高,尤其是在互联网企业和研究机构较为密集的一线或新一线城市。
通过分析这些公网暴露的大模型软件服务IP注册情况可以发现,除了六成以上的企业单位IP,个人注册的IP开放大模型服务的比例接近四成。这表明,在当前“大模型热”的时代浪潮中,个人用户对构建数据可控、模型可调的“智能助手”具有较强的需求和热情。对于企业单位,分析其注册企业名可见“科技”“信息”等IT行业率先跟进,带动一系列如“管理”“健康”等其他产业积极探索AI赋能新质生产力的创新方法。
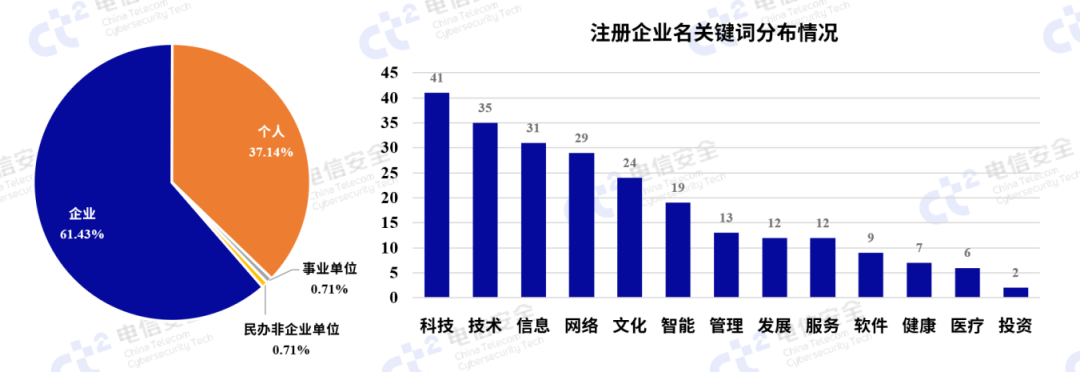
图2 国内公网暴露大模型软件服务IP注册信息情况
如图3所示,通过分析公网暴露大模型软件的类别情况,可以看出Ollama和LiteLLM占主导地位,其中Ollama 以 87.17%的占比远超其他软件,这表明 Ollama 在全球范围内,依靠其本地部署易用性以及较低的计算资源要求,使得个人开发者和企业更倾向于使用。LiteLLM占比11.46%,作为API代理层,主要用于连接不同LLM提供商,而非本地部署推理。其余大模型软件仅占1.37%,在公网暴露实例中的占比极低,主要应用于大规模云推理(如AI服务器或数据中心),而非个人开发者的本地运行。
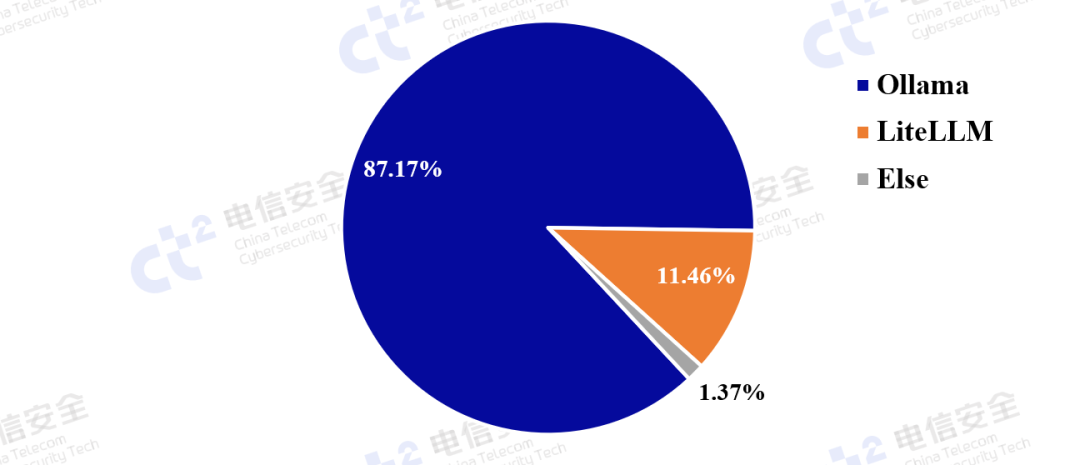
图3 公网暴露大模型软件的类别情况
进一步分析头部两个软件在不同国家的使用情况。如图4和图5所示,LiteLLM在美国和德国的暴露数量相对较高,同时也覆盖了亚洲主要经济体,而中国使用该服务的暴露数量较少。vLLM等部署方式对GPU的要求更为严格,对纯CPU设备支持度较弱,而国内GPU的成本受国际贸易影响较高,导致部署数量较少,因此vLLM的使用数量少于Ollama。而Ollama以其“开箱即用”的特性快速占据了中国市场,相比于LiteLLM需要自行构建上层接口应用,Ollama提供了更为完善的容器化Web服务;相比vLLM对大型算力设备的更高支持,Ollama更适合低算力设备的快速运行,更符合国内需求。
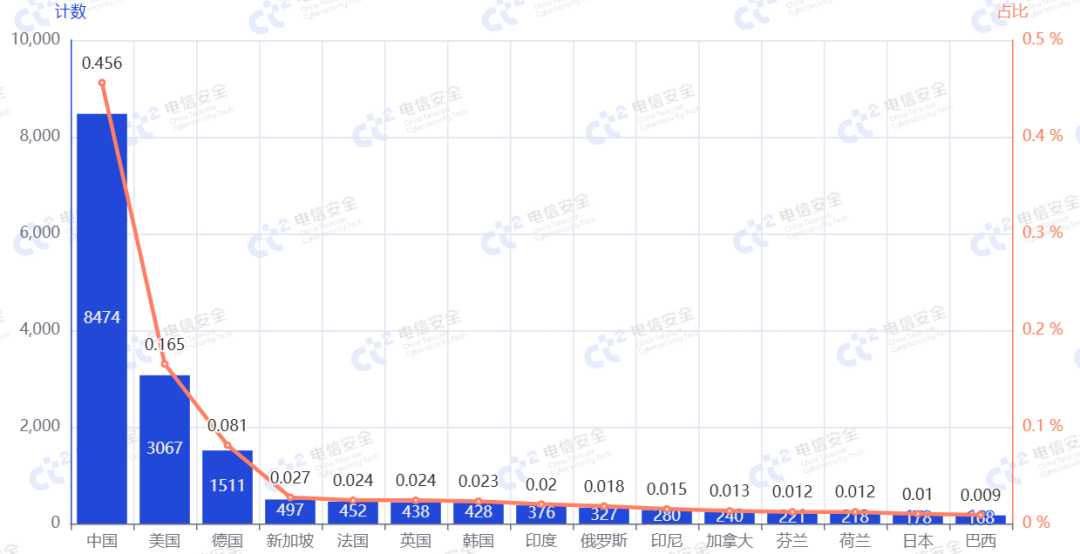
图4 Ollama的公网暴露国家分布情况
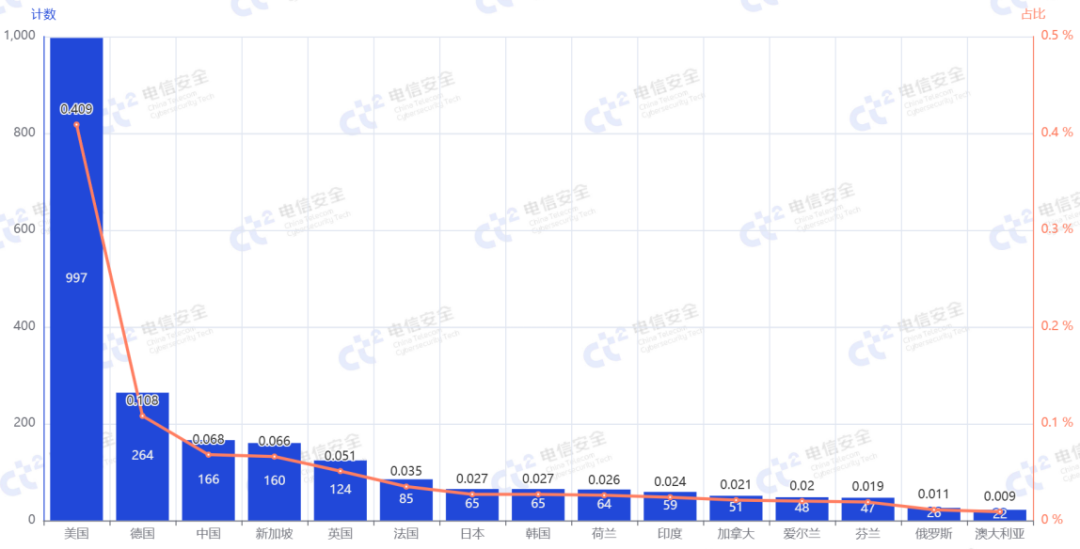
图5 LiteLLM的公网暴露国家分布情况
尽管这些软件的研制起源于美国,但从使用情况来看,它们几乎都随着“大模型热”的趋势在国内迅速部署和应用,形成了遍地开花的局面。可见,我国个人用户对大语言模型的定制化需求,以及企业用户对AI模型赋能现有生产力的需求,都表现出强烈的态势。
大语言模型服务软件
公网暴露安全问题
然而突飞猛进的部署增量带来了一系列的安全问题,同样不容忽视。根据中国电信云堤·广目的测绘结果发现,只有12.9%的主机使用了HTTPS替代默认的HTTP协议,这些使用明文协议传输的服务极易遭受中间人攻击。此外,为观察大语言模型服务运行情况,本文抽选了1000余个目标进行服务状态跟踪,在2周的时间窗口上,大语言服务关闭了约40%,另有约5%转为了其他服务,仅有约1%的服务追加了登录认证机制,剩余54%仍保持大语言模型服务开放状态。可以看出,随时间的持续,有一部分尝鲜用户会逐步放弃维护,只有少量的大语言模型服务会持续投入到实际应用中。
由于缺乏身份验证、加密通信、速率限制、计费管理、内容过滤、负载均衡等技术措施,这类软件在公网暴露后,可能引发未经授权的访问、敏感数据泄露等安全隐患。尤其是在弱口令或未配置安全访问机制的情况下,攻击者可能利用扫描工具直接访问暴露的接口,并将其作为拒绝服务(DDoS)攻击的目标。
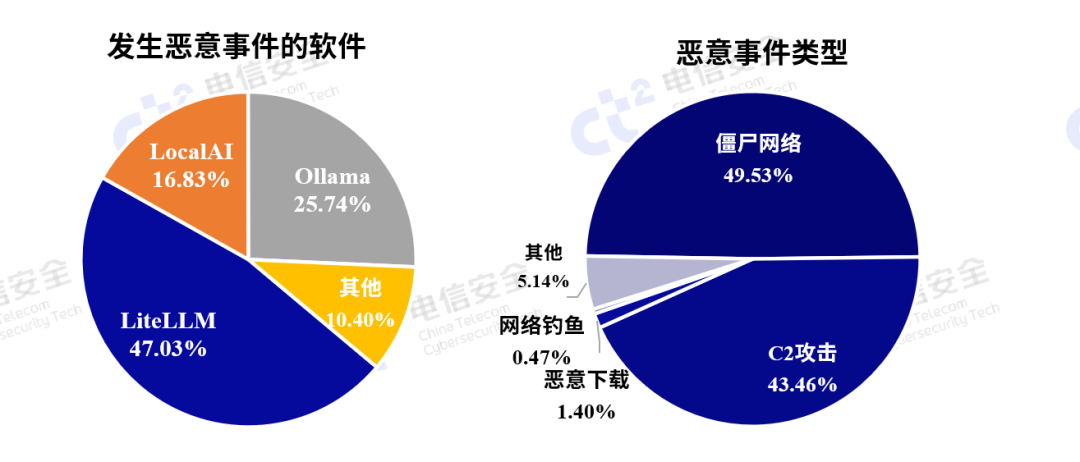
图6 公网暴露大模型服务主机发生恶意事件的情况
中国电信云堤·广目测绘分析了自2024年12月至今大模型服务主机发生的恶意安全事件,如图6所示,恶意事件中 LiteLLM 占据了 47.03%,位居首位。这表明 LiteLLM 在大模型服务中暴露的风险较大,由于其支持多个来源的LLM ,容易受到未授权访问和滥用。而 Ollama虽然使用占比较高,但恶意事件并不高,这与其作为本地部署的解决方案有关,虽然在使用中具有更高的私密性,但如果没有严格的安全防护,也容易成为攻击目标。LocalAI占16.83%,尽管使用比例较小,但在恶意事件中占比较大,显示出其作为新兴软件还存在诸多的安全隐患。
从恶意事件类型的分布来看,C2攻击和僵尸网络占主导,设备被感染或受到社会工程学攻击,成为攻击的跳板。这种攻击通常难于防范,且难以追踪,具有高度隐蔽性。网络钓鱼和恶意下载占比较低,分别为0.47%和1.40%,其低频率反映出,威胁虽然存在,但相比C2攻击,其危害较小。
针对当前恶意事件风险,企业应采取多层次的防护措施。首先,对于模型服务软件,应该强化身份验证和访问控制,确保只有授权用户才能访问,防止恶意用户滥用。同时,加强服务端设备的安全防护,通过主机安全防护软件可有效发现和阻止设备被感染。对于C2攻击,应部署安全网关和入侵检测防护系统,及时发现并隔离异常流量。为应对日渐规模化、体系化的DDoS攻击,应部署DDoS防护和流量清洗系统,减少对正常服务的影响。此外,对网络钓鱼和恶意文件传输的防范可通过安全网关和内容过滤实现,防止恶意文件和链接进入用户网络。
通过这些综合措施,结合专业安全团队的常态化运营保障,可以有效降低恶意事件的发生频率,保护大模型服务的安全性与稳定性。
结论
人工智能大模型领域正在蓬勃发展,这对于我国通过科技革命推动经济高质量发展,从规模化扩张转向科技创新引领的新质生产力发展模式,具有重要意义。本报告基于互联网空间测绘基础数据,依托中国电信云堤·广目测绘产品强大的网络资产与企业实体的关联挖掘能力,通过深度挖掘发现,我国在人工智能领域呈现出创新能力强、产业需求迫切、技术进展迅速的特点。
然而,这一领域的安全问题迫在眉睫。由于LiteLLM、Ollama和LocalAI等大模型服务在公网暴露,且缺乏身份验证、加密通信等基础防护措施,攻击者可以轻易进行未经授权的访问,导致敏感数据泄露,甚至通过弱口令或未配置安全机制直接发起攻击。通过对近期安全事件的跟踪,发现大模型安全攻击的隐蔽性和难以追踪性进一步加剧。为应对这些安全风险,企业需要采取纵深防御、多层次防护的安全策略,使用更专业的安全运营产品及服务,通过DDoS防护、流量清洗、安全网关及内容过滤等技术措施,保障大模型服务的安全性和可用性。
供稿:基础能力部 郝逸航 王德威
声明:本文来自中国电信安全,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
