基本信息
原文标题:Investigating Large Language Models for Code Vulnerability Detection: An Experimental Study
原文作者:Xuefeng Jiang, Lvhua Wu, Sheng Sun, Jia Li, Jingjing Xue, Yuwei Wang, Tingting Wu, Min Liu†
作者单位:
中国科学院计算技术研究所(Institute of Computing Technology, Chinese Academy of Sciences)
中国科学院大学(University of Chinese Academy of Sciences)
京东集团(JD.com, Inc.)
中国移动研究院(China Mobile Research Institute)
中关村实验室(Zhongguancun Lab)
关键词:代码漏洞检测(Code Vulnerability Detection, CVD)、大语言模型(Large Language Model, LLM)、代码智能(Code Intelligence)、网络安全(Cyber Security)、实验研究(Experimental Study)
原文链接:https://arxiv.org/abs/2412.18260
开源代码:暂无
论文要点
论文简介:本研究探讨了大型预训练语言模型(LLMs)在代码漏洞检测(CVD)任务中的有效性。传统的学习型漏洞检测方法依赖于中型序列模型的微调或从零开始训练较小的神经网络,而近年来LLMs在代码理解和生成任务中展现了强大的能力。然而,关于LLMs在代码漏洞检测中的作用仍然缺乏系统性研究。本论文填补了这一空白,通过微调四种常见的开源LLMs进行CVD实验,并与五种其他基于图或中型序列模型的漏洞检测方法进行了对比。研究采用五个广泛使用的CVD数据集,并探讨了类别不平衡和代码样本长度对模型性能的影响。本研究的所有代码及资源均已开源,以促进社区在该领域的进一步研究和复现。
研究目的:在软件开发中,代码漏洞检测(CVD)至关重要,它能够发现潜在的安全风险并避免系统漏洞的发生。传统的代码漏洞检测方法主要包括两种:动态分析方法(如模糊测试、符号执行)和静态分析方法(基于深度学习的代码分析)。近年来,基于深度学习的静态分析方法在代码漏洞检测中得到了广泛应用,尤其是序列模型(如CodeBERT)和图神经网络模型(如Devign)等。
然而,随着大型预训练语言模型(LLMs)的发展,越来越多的研究开始关注它们在代码智能任务中的应用,如代码理解和生成。但关于LLMs在CVD任务中的有效性仍然缺乏系统研究。因此,本研究的目标是:
探索LLMs在代码漏洞检测中的能力:通过微调四种主流的开源LLMs,并评估其在多个CVD数据集上的表现。
统一CVD实验环境:以往的研究在数据集和实验环境上不统一,影响了不同方法的可比性。因此,本研究统一了五个CVD数据集,并实现了九种不同的基准模型,以提供公平的对比实验。
研究类别不平衡和代码长度的影响:在CVD数据集中,漏洞样本通常处于少数,而漏洞模式往往出现在较长的代码段中。因此,本研究特别设计实验来研究类别不平衡和代码长度对LLMs性能的影响。
研究贡献
系统性探索LLMs在CVD任务中的表现:本研究首次全面评估了LLMs在代码漏洞检测任务中的有效性,并比较了LLMs与其他基准模型的性能差异。
分析类别不平衡和代码长度的影响:本研究设计了数据重采样实验,量化分析类别不平衡和代码长度对模型性能的影响,揭示了LLMs在处理这些问题时的优势与不足。
开源代码和数据集:为促进社区研究,本研究提供了完整的开源代码、数据集预处理脚本以及实验结果,以便相关研究人员复现实验并开展进一步研究。
引言
近年来,随着软件系统的复杂度增加,代码漏洞的数量也迅速增长。自动化漏洞检测已经成为企业和研究机构关注的重点。传统的漏洞检测方法依赖动态分析技术,如模糊测试(Fuzzing)和符号执行(Symbolic Execution),但这些方法需要执行代码,计算成本较高。相比之下,基于深度学习的静态分析方法仅依赖于代码本身,无需运行代码,因此在CVD领域得到了广泛应用。
早期的深度学习方法主要采用图神经网络(GNNs)和基于Transformer的预训练模型:
图神经网络(GNNs):如Devign,通过构造代码图(AST、CFG、PDG等)来提取漏洞特征,适用于结构化信息分析。
序列模型:如CodeBERT、UniXcoder,将代码视为文本序列,通过Transformer模型学习漏洞模式,适用于大规模代码分析。
近年来,大语言模型(LLMs)在自然语言处理和代码智能任务中取得了巨大成功。然而,它们在CVD任务中的潜力仍未被充分探索。本研究通过微调四种开源LLMs(Llama-2、CodeLlama、Llama-3、Llama-3.1),并在五个常见CVD数据集上进行实验,分析它们的性能表现,并与现有的基准方法进行对比。
相关工作
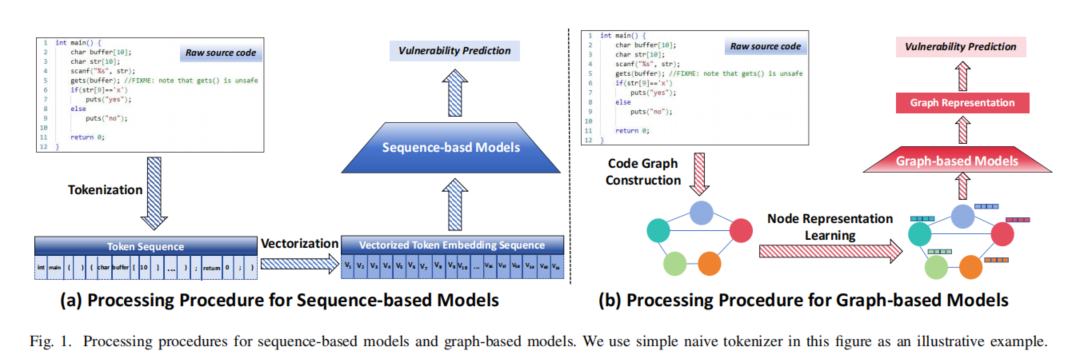
1. 代码漏洞检测(CVD)方法:
动态分析方法:如模糊测试、符号执行,通过执行代码来发现漏洞。
静态分析方法:基于深度学习的代码漏洞检测方法,主要包括图神经网络(GNNs)和序列模型(Transformer)。
2. 预训练模型在代码分析中的应用:
中型预训练模型(如CodeBERT、UniXcoder):在代码理解和漏洞检测任务上取得了成功,但受限于最大序列长度(512个Token)。
大语言模型(LLMs)(如Llama-2、CodeLlama):具备更强的长序列建模能力,但在CVD任务中的有效性尚未得到充分验证。
3. 现有研究的局限性:
研究数据集不统一,影响不同方法的可比性。
很少有研究关注LLMs在长代码样本中的表现。
类别不平衡问题影响CVD模型的检测性能,现有研究较少讨论这一问题。
研究动机
1. 统一评测环境:现有研究使用的数据集和实验环境不一致,难以比较不同方法的性能。因此,本研究统一了五个主流CVD数据集,并实现了完整的基准模型。
2. 探索LLMs在CVD中的潜力:尽管LLMs在代码生成等任务中取得了成功,但它们在代码漏洞检测任务中的有效性尚未得到充分研究。
3. 分析类别不平衡和代码长度的影响:CVD数据集中漏洞样本通常较少,且漏洞模式常见于长代码段。本研究设计实验量化分析这些因素对模型性能的影响。
BENCHMARK 设计
本研究针对代码漏洞检测(CVD)任务,构建了一个完整的基准测试框架,涵盖多种模型、五个广泛使用的数据集以及统一的评测标准,以确保实验的公平性和可复现性。
1. 评测模型
研究者选择了三类模型进行评估:
图神经网络(GNN)模型:Devign、ReGVD、GraphCodeBERT,这些模型利用代码的图结构进行漏洞检测。
中型预训练序列模型:CodeBERT、UniXcoder,这些基于Transformer的编码器在代码分析任务中表现出色,但受限于512个Token的输入长度。
大语言模型(LLMs):Llama-2、CodeLlama、Llama-3、Llama-3.1,这些模型具备更强的代码理解能力,并可处理更长的代码片段。
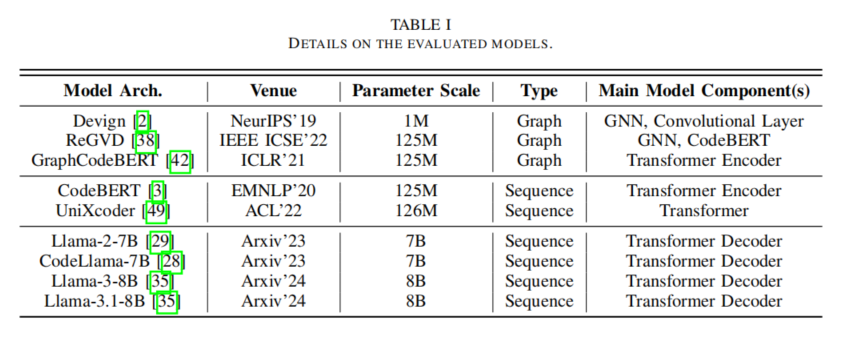
2. 数据集
实验采用五个主流CVD数据集(ReVeal、Devign、Draper、BigVul、DiverseVul),涵盖不同类型的代码漏洞,并按代码长度分为短代码(≤512 Token)和长代码(512-1024 Token),以分析代码长度对模型性能的影响。
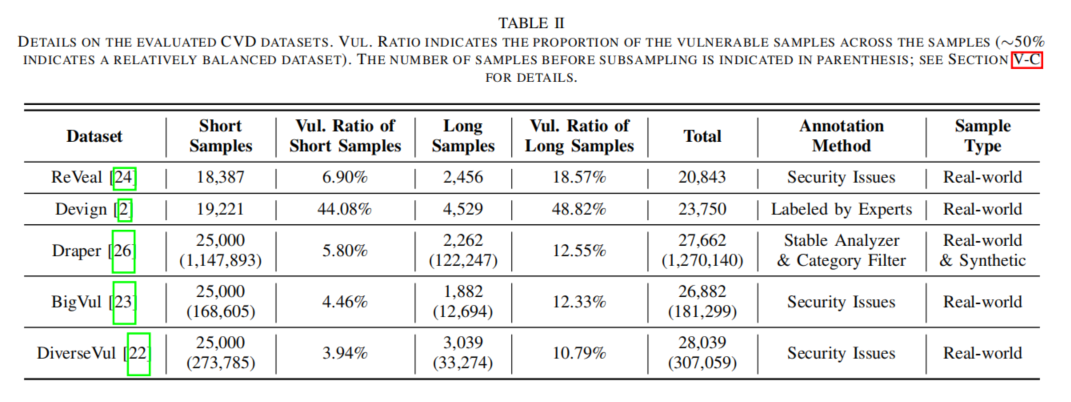
3. 评测指标
使用准确率(Acc)、精确率(Pre)、召回率(Rec)、F1分数、假阳性率(FPR)等指标全面评估模型性能,重点关注F1分数以应对数据集类别不平衡的问题。
研究实验
1. 实验设置
实验环境
所有实验在 Ubuntu 20.04 服务器上运行,硬件配置包括 AMD Ryzen 24核处理器 和 NVIDIA L20(48GB)GPU,主要计算框架为 PyTorch 2.1.0,CUDA 版本为 12.1。
数据集划分
研究采用ReVeal、Devign、Draper、BigVul、DiverseVul 五个数据集,并按照代码长度分为 短代码(≤512 Token) 和 长代码(512-1024 Token) 两个子集。所有数据集均按 8:1:1 的比例划分为 训练集、验证集和测试集。
模型与超参数
图神经网络模型(Devign、ReGVD):输入特征维度设为200,优化器采用 Adam,学习率 1e-4,权重衰减 1e-3。
中型预训练模型(CodeBERT、UniXcoder):块大小512(短代码)/1024(长代码),优化器AdamW,学习率2e-5。
大语言模型(LLMs)(Llama-2、CodeLlama、Llama-3、Llama-3.1):采用 LoRA 低秩适配微调,关键超参数包括:秩 16,缩放因子32,Dropout 0.05,优化器 AdamW,学习率 1e-4,训练 5 轮。
评测指标
采用准确率(Acc)、精确率(Pre)、召回率(Rec)、F1分数、假阳性率(FPR) 作为评测指标,其中F1分数 作为核心评估标准,以应对数据类别不平衡的问题。
2. 实验结果
本研究在五个主流代码漏洞检测(CVD)数据集 上,系统评估了三类模型(图神经网络模型、预训练序列模型、大语言模型LLMs),重点分析了类别不平衡和代码长度对模型性能的影响,并得到以下关键结论:
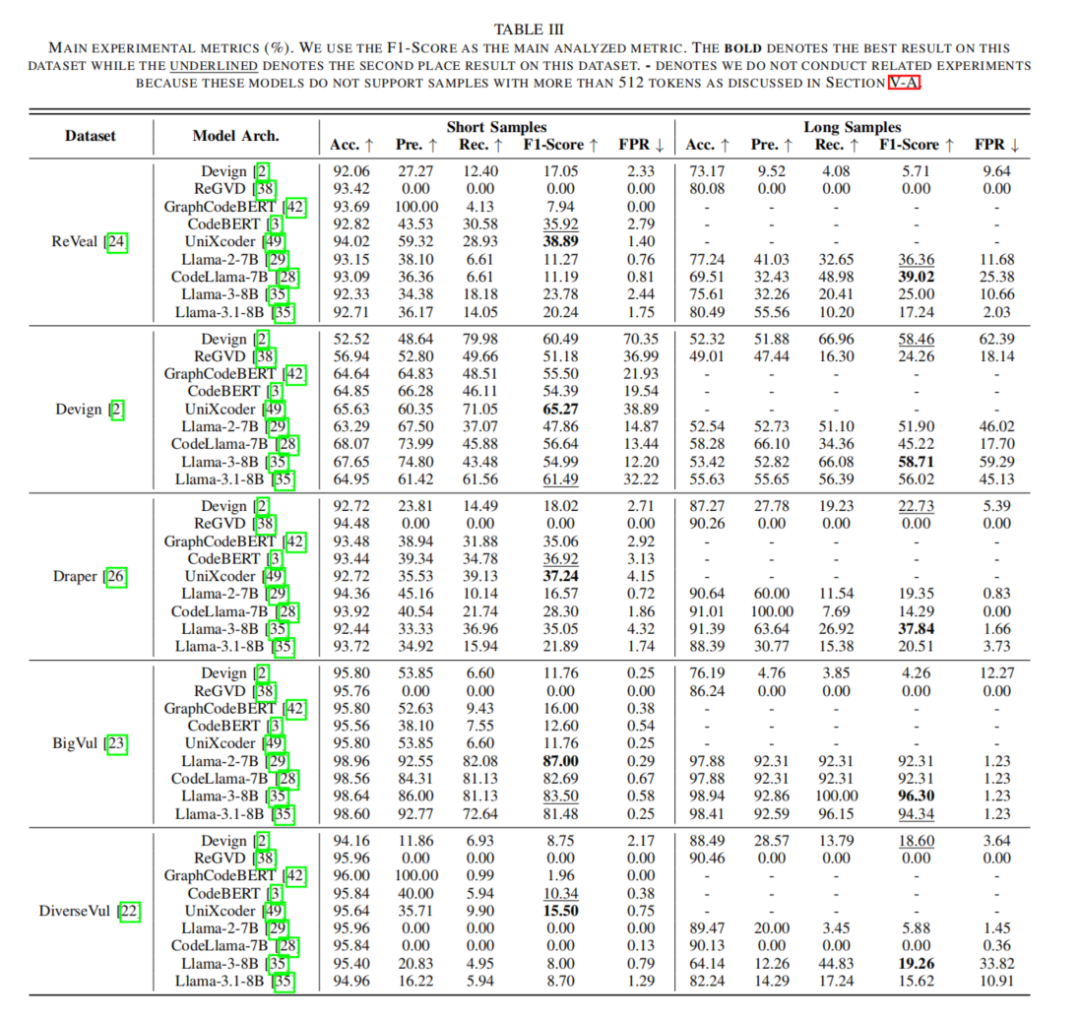
1. 类别不平衡影响显著
在类别均衡的Devign数据集 上,所有模型的表现均优于其他数据集,而在类别极度不均衡的DiverseVul数据集 上,所有模型的表现均较差。
一些模型(如 ReGVD、Llama-2、CodeLlama)在高度不平衡数据集上,甚至出现召回率为0的情况,表明它们无法有效学习漏洞特征。
2. 中型预训练模型在短代码数据集上表现优异
在短代码数据集上,CodeBERT和UniXcoder普遍优于LLMs,特别是在 ReVeal、Draper 和 DiverseVul 数据集上,它们的F1分数最高。
这表明中型Transformer预训练模型在小规模漏洞检测任务上仍具优势,尤其是在类别不均衡的情况下。
3. LLMs 在长代码数据集上具有明显优势
LLMs在长代码样本 上的表现远优于图模型和中型序列模型,主要得益于更强的长序列建模能力。
长代码中漏洞样本占比更高,使LLMs能更有效地学习漏洞模式。
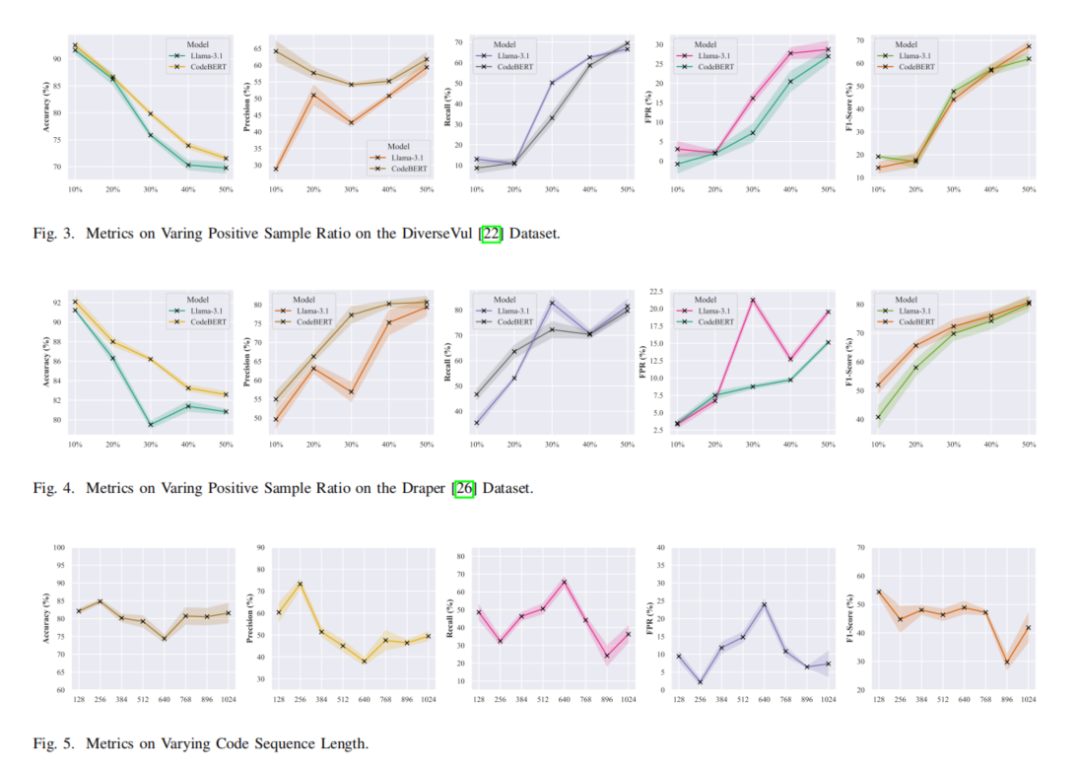
4. LLMs 假阳性率较低,检测结果更可靠
在大多数数据集中,LLMs假阳性率(FPR)较低,比其他模型更具实用性。
低FPR代表较少误报,提高了模型在实际应用中的可信度。
本研究进一步通过实验,分析了类别不平衡和代码长度对LLMs的影响,以优化其漏洞检测能力。
论文结论
本研究系统性评估了LLMs在代码漏洞检测任务中的表现,并探讨了类别不平衡和代码长度对模型性能的影响。实验结果表明,LLMs在长代码样本上的检测能力较强,但受类别不平衡问题的影响较大。未来研究可以进一步优化数据集质量,并探索更有效的微调方法来提升LLMs在CVD任务中的检测能力。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
