我想起了当年因手搓的一个框架被领导挑战的场景,他说:“你的这个框架有什么理论依据没?”
我:……
从那时起,我就默默下定决心,要把世界上存在的所有安全框架都看一遍,于是推出了《锐安全安全建设参考架构体系全景图》。
每次向客户展示这张全景图时,都能直接把他震住。你可以不懂,但是你最好知道,而且最好知道它们大概的作用,客户才敢放心地把规划交给你。
这不,《锐安全安全建设参考架构体系全景图》升级到5.0啦!
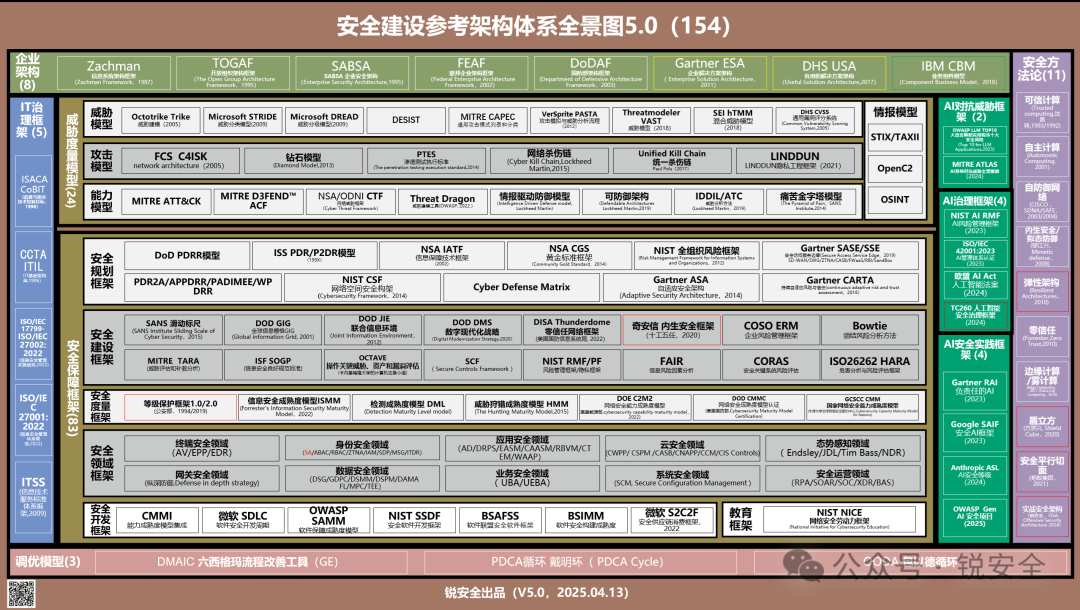
图:锐安全 安全建设参考架构体系全景图 5.0
该版本最大的变化是增加了“AI安全架构”版块(图上绿色部分)。
并且这次一口气儿更新了10个AI安全相关的框架,当客户问你AI安全怎么做时,你再也不用心虚了。
增加的“AI安全”部分内容又分为三大模块:AI对抗威胁框架(AI Adversarial Threat Framework)、AI治理框架(AI Governance Framework)和AI安全实践框架(AI Security Practice Framework)。
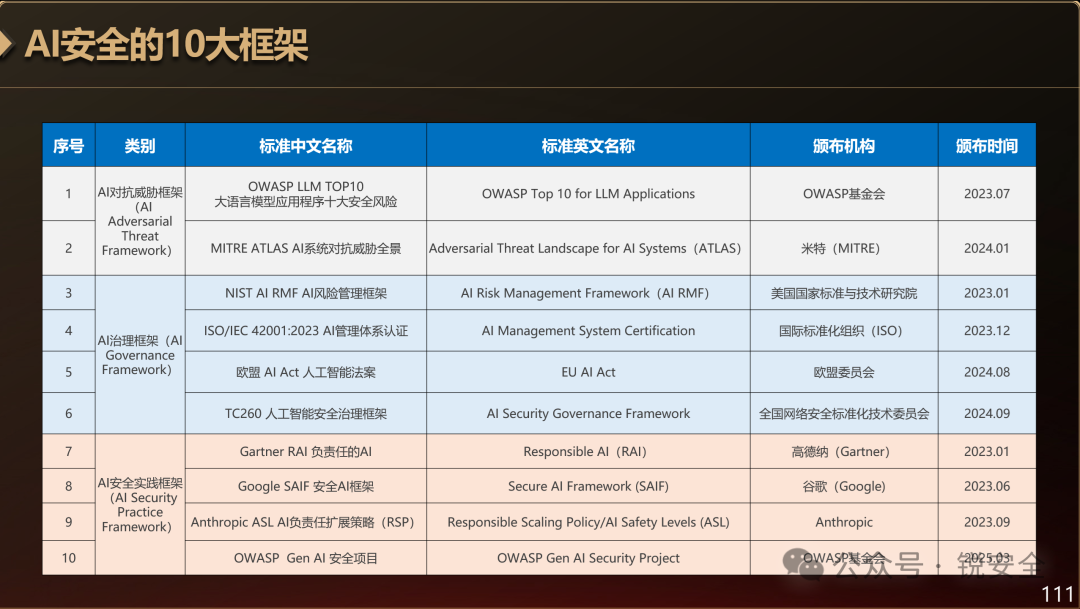
图:AI安全的十大框架
其中,“AI对抗威胁框架”包含两个要素,按发布时间排序如下:
1、 OWASP大语言模型应用程序十大安全风险。
2、 MITRE ATLAS AI系统对抗威胁全景。
其中,“AI治理框架”包含4个要素,按发布时间排序如下:
1.NIST AI RMF AI风险管理框架。
2.ISO/IEC 42001:2023 AI管理体系认证。
3.欧盟AI Act 人工智能法案。
4.TC260的人工智能安全治理框架。
其中,“AI安全实践框架”包含4个要素,按发布时间排序如下:
1.Gartner RAI 负责任的AI框架。
2.Google SAIF 安全AI框架。
3.Anthropic ASL AI AI负责任扩展策略。
4.OWASP Gen AI 安全项目。
这些框架我看了一遍,受益匪浅,不光对AI安全的认知更清晰了,对AI的理解也更深刻了。
研究框架真的可以让你在短时间内建立起非凡的领域理解力。因为每一个框架都是逻辑自洽的顶级智慧。
今天,就用我的方法让你快速掌握AI安全。
 OWASP 大语言模型应用程序十大安全风险
OWASP 大语言模型应用程序十大安全风险
OWASP是全球性的应用安全非营利组织,OWASP TOP10是一个从2003年就开始的、持续了二十多年的安全项目,它是衡量“关键web应用程序安全风险”的参考标准。
那么如今正火的大语言模型(LLM)应用程序,会面临哪些风险呢?

图:OWASP 大语言模型(LLM)应用程序十大风险
1. 提示词注入(Prompt Injections):绕过过滤器或使用精心制作的提示操作LLM,使模型忽略先前的指令或执行非计划的操作。
2. 数据泄漏(Data Leakage):通过LLM的回复意外泄露敏感信息、专有算法或其他机密细节。
3. 不完善的沙盒隔离(Inadequate Sandboxing):当LLM可以访问外部资源或敏感系统时,未能正确隔离LLM,从而允许潜在的利用和未经授权的访问。
4. 非授权代码执行(Unauthorized Code Execution):利用LLM通过自然语言提示在底层系统上执行恶意代码、命令或操作。
5. SSRF漏洞(SSRF Vulnerabilities):利用LLM执行意外请求或访问受限制的资源,如内部服务、API或数据存储。
6. 过度依赖大语言模型生成的内容(Overreliance on LLM-generated Content):在没有人为监督的情况下过度依赖LLM生成的内容可能会导致不良后果。
7. 人工智能未充分对齐(Inadequate AI Alignment):未能确保LLM的目标和行为与预期用例保持一致,从而导致不良后果或漏洞。
8. 访问控制不足(Insufficient Access Controls):未正确实现访问控制或身份验证,允许未经授权的用户与LLM交互,并可能导致漏洞被利用。
9. 错误处置不当(Improper Error Handling):暴露错误消息或调试信息,导致敏感信息、系统详细信息或潜在攻击向量的泄露。
10. 训练数据投毒(Training Data Poisoning):恶意操纵训练数据或微调程序,将漏洞或后门引入LLM。
你看,当你看到这里,至少知道了大语言模型目前面临的“关键风险”是什么?
看之前,我觉得最近火山引擎推出的“大模型防火墙产品”不太有必要,但是看完之后,觉得很有必要。因为当自然语言成为交互的桥梁,自然语言自然也就成了攻击的武器。

MITRE ATLAS AI系统对抗威胁全景
MITRE公司是世界著名的研究真实世界对抗技术的非营利组织,它的ATT&CK框架(Adversarial Tactics, Techniques, and Common Knowledge)是一个衡量攻击手法的参考标准。
它在2024年1月份,推出了一个面向AI安全的框架ATLAS(Adversarial Threat Landscape for AI Systems),翻译过来就是:AI系统对抗威胁全景。

图:ATLAS全景
整个ATLAS体系,包含面向AI系统的14个攻击阶段和66种技战术。

图:ATLAS攻击阶段与技战术
你看,当你看到这里,对AI安全的理解,就又多了一个“过程维度”,而且你看到了“威胁全景”。
对ATT&CK技战术进行识别和防御,传统称为“ATT&CK覆盖”,对所有安全产品来说,都是一次巨大的挑战。

NIST AI RMF AI风险管理框架
美国国家标准与技术研究院NIST于2023年年1月发布了《AI RMF AI风险管理框架》,是AI风险管理领域的扛鼎之作。
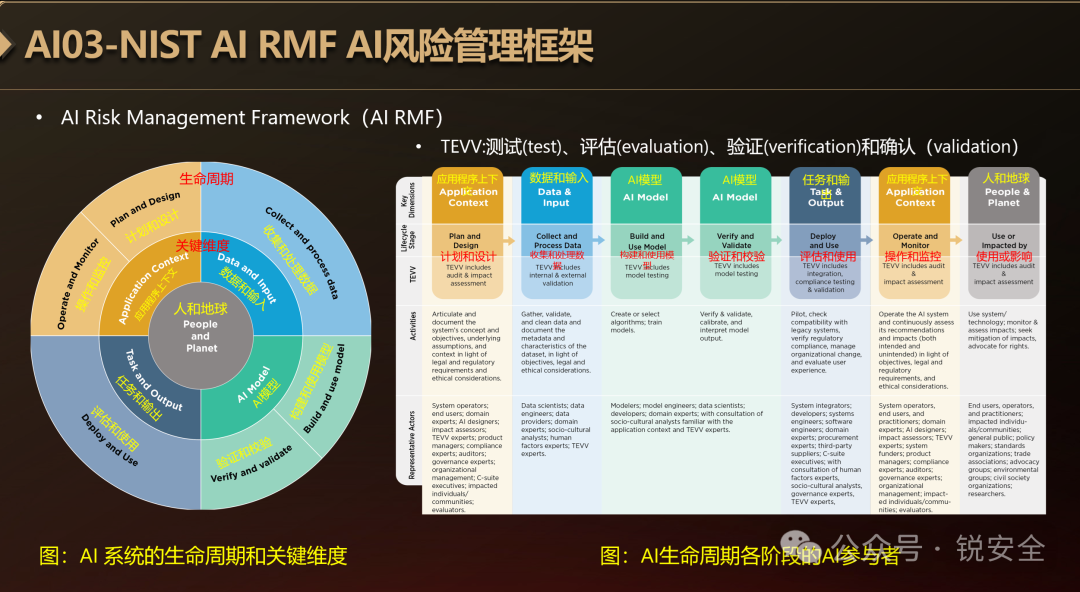
图:NIST AI RMF AI风险管理框架
它的内圈是表征一个AI系统的五个关键维度:
1. 应用程序上下文
2. 数据和输入
3. AI模型
4. 任务和输出
5. 人和地球
这五个关键维度其实就是一个AI系统的“技术流程”。
外圈则展示了AI生命周期的六个阶段:
1. 计划和设计
2. 收集和处理数据
3. 构建和使用模型
4. 验证和校验
5. 评估和使用
6. 操作和监控
这六个阶段其实就是一个组织围绕“AI系统五个关键维度”而产生的“业务流程”。
理想情况下,风险管理工作从应用程序环境中的计划和设计功能开始,并在整个AI系统生命周期中执行。
有了上面的认知框架,那么整个AI系统的治理体系就出来了:
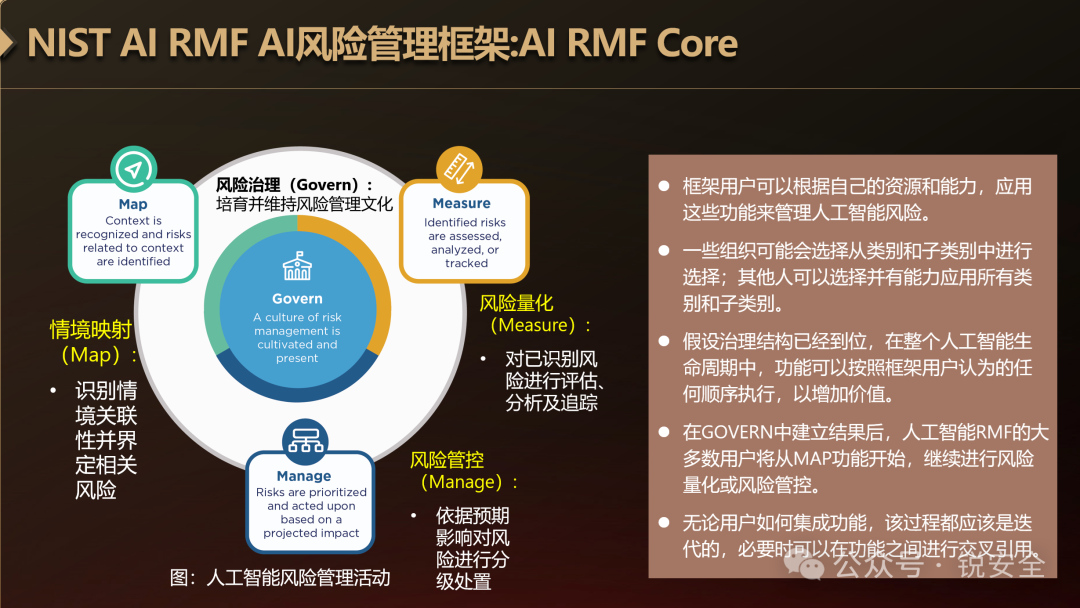
图:AI RMF治理体系内核
那么整个AI系统的风险管理动作也就确定了,由以下四部分组成:
l情境映射(Map):识别情境关联性并界定相关风险;
l风险量化(Measure):对已识别风险进行评估、分析及追踪;
l风险管控(Manage):依据预期影响对风险进行分级处置;
l风险治理(Govern):培育并维持风险管理文化。
你看,当你看到这里,对AI安全的理解就又多了一个“流程维度”。
至少你可跟客户聊大模型的TEVV了(测试-评估-验证-确认)。

ISO/IEC 42001:2023 AI管理体系认证
大名鼎鼎的国际化标准组织ISO于2023年12月发布了《ISO/IEC 42001:2023 AI管理体系认证》,据ISO自己说,该标准是世界上第一个人工智能管理体系标准。
它提出了一种结构化的方式来管理与AI相关的风险和机遇,从而平衡创新与治理。
它规定了在组织内建立、实施、维护和持续改进AI管理系统(Artificial Intelligence Management System,AIMS)的要求。
它专为提供或使用基于AI的产品或服务的实体而设计,确保负责任地开发和使用AI系统。
整个标准的主要内容是:组织环境(Context of the organization)、领导作用(Leadership)、策划(Planning)、支持(Support)、运行(Operation)、绩效评价(Performance evaluation)、改进(Improvement)等。
与这个标准相关联的标准还有:ISO/IEC 23053(机器学习工具)、ISO/IEC TR 24368(AI伦理)、ISO/IEC 38507(AI伦理和治理的指导)。
你看,当你看到这里,对AI安全的理解就又多了一个“系统维度”。
至少你可以跟客户建议:大模型都部署了,要不咱过一个评测,先拿个证再说?

欧盟 AI Act 人工智能法案
欧盟于2024年8月正式发布《欧盟 AI Act 人工智能法案》。
立法的目的是建立统一的AI监管框架,确保以人为本、可信赖的人工智能,保障健康、安全、基本权利(民主、法治、环境等),同时促进欧盟内部市场的创新与公平竞争。

图:AI Act
法案里制定了AI的八原则:
1. 以人为本(Human-centric AI)。
2. 安全性与合规性(Safety and Compliance)。
3. 透明性与可追溯性(Transparency and Traceability)。
4. 非歧视与公平性(Non-discrimination and Fairness)。
5. 人工监督与控制(Human Oversight)。
6. 数据隐私与保护(Data Privacy and Protection)。
7. 生态信任与法律确定性(Trust and Legal Certainty)。
8. 禁止特定有害实践(Prohibition of Harmful AI Practices)。
并对禁止的AI、高风险的AI、和生成式AI分别进行了定义。
而且,AI法案禁止以下8种做法:
1. 社会信用评分系统。
2. 工作和教育中的情绪识别系统。
3. 用于利用人们的弱点(例如年龄、残疾)的 Al。
4. 行为操纵和规避自由意志。
5. 无针对性地抓取面部图像以进行面部识别。
6. 使用敏感特征的生物识别分类系统。
7. 特定的预测性警务应用。
8. 执法部门在公共场合使用实时生物识别(有限的预先授权情况除外)。
通过这些限制,欧盟描绘了一幅清晰的图景: 欧盟人工智能法案涵盖的所有企业都必须在其运营中优先考虑公平、隐私和人类自主性。
你看,当你看到这里,对AI安全的理解就又多了一个“监管维度”。
咱们就可以跟客户聊安全的生意了:您看,欧洲都监管起来了,离咱们的监管也不远了。

TC260 人工智能安全治理框架
全国网络安全标准化技术委员会于2024年9月发布了《人工智能安全治理框架》。
该框架主要讲了人工智能安全治理原则、人工智能安全治理框架构成、人工智能安全风险分类 、技术应对措施、综合治理措施、人工智能安全开发应用指引等六部分内容。
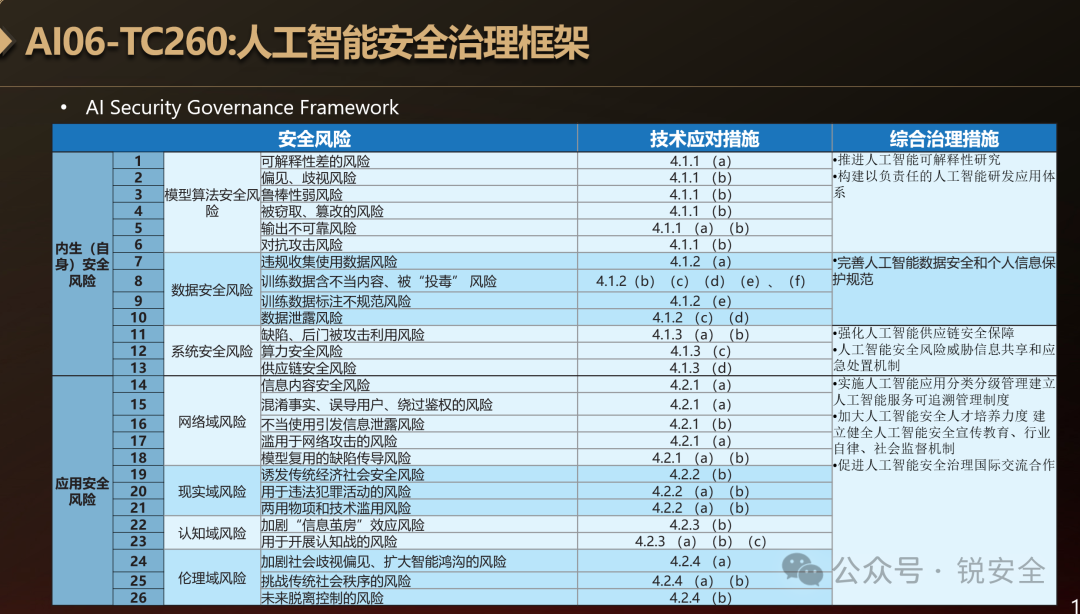
图:人工智能安全治理框架风险分类表
该框架定义了AI两大类风险:内生(自身)安全风险、应用安全风险。
其中,内生(自身)安全风险包括:模型算法安全风险、数据安全风险、系统安全风险三类风险。
其中,应用安全风险包括网络域风险、现实域风险、认知域风险、伦理域风险等四类风险。
以上总共包括2大类、7小类共计26个风险点。
你看,当你看到这里,对AI安全的理解就又多了一个“中国视角”。
至少可以跟客户这样聊:咱们国内有一个AI的标准,看到大模型有内生风险和应用风险,咱们得早做打算啊。

Gartner RAI 负责任的AI
Gartner于2023年1月推出了一个“负责的AI框架(Responsible AI)”。

图:Gartner Responsible AI
它包括了一个可信AI架构和12个原则,目的是将可信AI系统到负责任的AI系统。
你看,当你看到这里,对AI安全的理解就又多了一个“可信维度”。
在这里,咱们可以建立一个这样的认知:大模型安全分为三个维度:大模型基础设施安全、大模型安全防护(AI Security)和大模型安全可信(AI safety)。

Google SAIF 安全AI框架
Google于2023年6月则推出了一个《Google SAIF 安全AI框架》,里面有一个AI风险地图,很有意思。
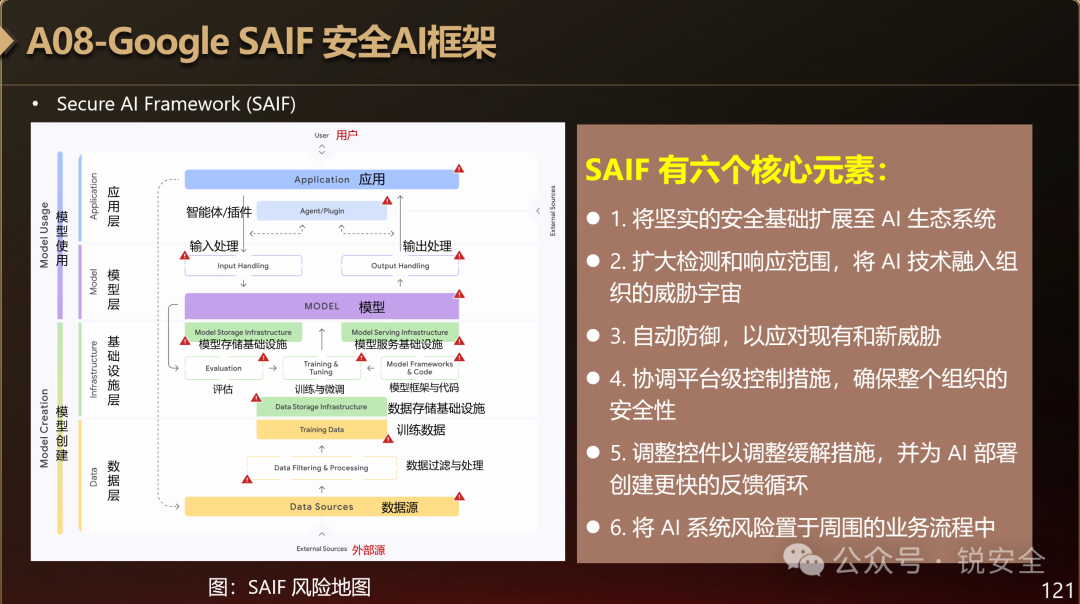
图:SAIF风险地图
上图中把整个AI系统分成了两大过程、四个层次。
两个过程是:模型创建和模型使用。
四个层次是:数据层、基础设施层、模型层、应用层。
1. 数据层里有两类数据:外部数据和训练数据;
2. 基础设施层里有三类基础设施:数据存储基础设施、模型存储基础设施和模型服务基础设施;
3. 模型层有三个要素:模型框架与代码、评估、训练和微调;
4. 应用层有输入处理、输出处理和智能体与插件。
图上“红色叹号”的位置就是AI系统的暴露面,这些一拆解,你是不是对AI安全的整体架构瞬间就清晰了许多?
除了上面那个风险地图外,Google其实着重讲了SIAF框架的六大核心要素:
- 将坚实的安全基础扩展至 AI 生态系统;
- 扩大检测和响应范围,将 AI 技术融入组织的威胁宇宙;
- 自动防御,以应对现有和新威胁;
- 协调平台级控制措施,确保整个组织的安全性;
- 调整控件以调整缓解措施,并为 AI 部署创建更快的反馈循环;
- 将 AI 系统风险置于周围的业务流程中。
你看,当你看到这里,对AI安全的理解就又多了一个“企业视角”。
在这里,咱们至少可以建立这样的认知:大模型分为两过程、四层次和六要素,以及通过这张图,就可以清晰地看到大模型的风险暴露面。

Anthropic ASL AI安全等级
Anthropic在2023年9月颁布了《负责任扩展策略(Responsible Scaling Policy, RSP)》。
里面有一个AI安全级别的创意:

图:ASL系统
这几个级别的说明如下:
ASL-1是指基本不会造成灾难性风险的系统,例如一个2018年的大型语言模型或一个只会下国际象棋的AI系统。
ASL-2是指显示出危险能力的早期迹象的系统,例如有能力提供制造生物武器的方法的模型,但这些信息由于可靠性不足或无法超越搜索引擎能提供的信息而没有太多用处。目前的前沿大型语言模型(包括Claude)似乎是ASL-2。
ASL-3是指与非AI基线工具(例如搜索引擎或教科书)相比显著增加灾难性误用风险或显示出低级自主能力的系统。
ASL-4及更高版本(ASL-5+)尚未定义,因为它距离现有系统太远,但可能会涉及灾难性误用风险和自主性的质变升级。
你看,当你看到这里,你对AI安全的理解就又多了一个“分级视角”。
至少咱们可以得出一个这样的认知:大模型未来要分级,大模型安全未来也要分级。

OWASP Gen AI 安全项目
《OWASP Gen AI安全项目》于2025年3月发布,是《OWASP 大语言模型应用程序十大安全风险》项目的升级版。
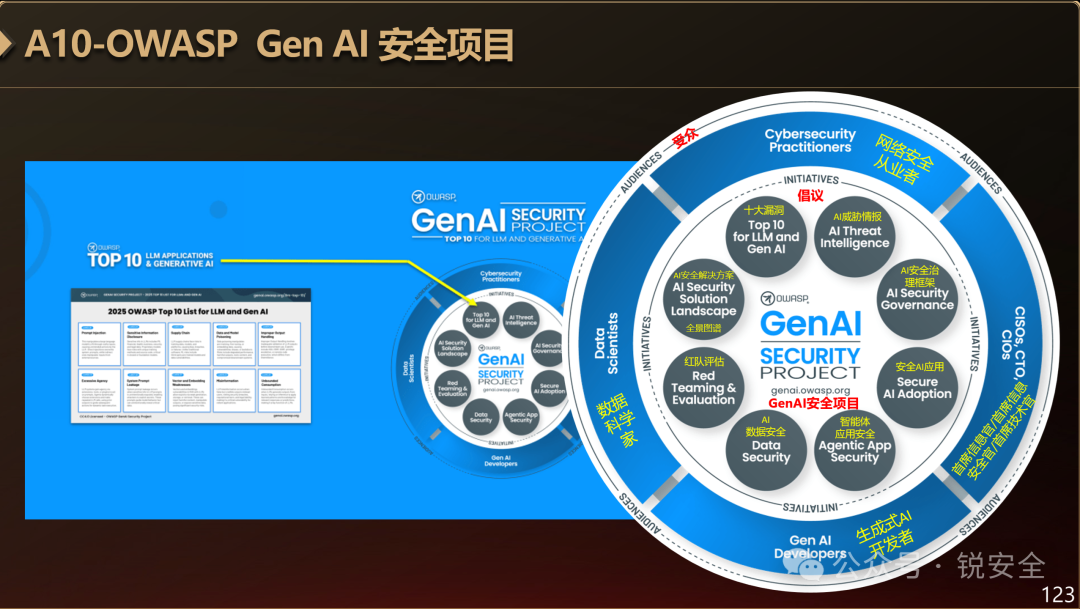
图:OWASP Gen AI 安全项目
升级后的GenAI安全项目,其实已经不再是一个攻击者视角的漏洞排行,而是一个完整的AI安全框架。
这个框架有两个环,第一个环是“倡议环”,有八大倡议:
1. 大语言模型应用十大漏洞
2. AI威胁情报
3. AI安全治理框架
4. 安全AI应用
5. 智能体应用安全
6. AI数据安全
7. 红队评估
8. AI安全解决方案全景图谱
这八大倡议其实就是AI安全的八个方面。
第二个环是“受众环”,其实是指该框架适用的客户,有四大受众:
1. 网络安全从业者
2. 首席信息官/首席信息安全官/首席技术官
3. 生成式AI开发者
4. 数据科学家
你看,当你看到这里,对AI安全的理解就又多了一个“组织视角”。
如果咱们谁准备给客户写大模型安全的解决方案,这个框架非常好,它其实是一个大模型安全的“规划方案”,非常齐全,而且也好落地。

我们常说,安全市场的碎片化源于安全技术的伴生属性,这是安全的坏处。
但是安全还有一个好处,就是当我们把安全搞懂了,它的保护对象我们也就懂了。
所以搞安全的人被称为“万金油”,什么都懂,什么都会,会让客户心里特别踏实。但是反过来,如果你什么都不懂,就会让客户感觉特别地不踏实。
所以,当你把这些框架看完,是不是对AI本身也有了深刻的理解?
而且,恭喜你,你已经变成AI安全专家了。
来吧!咱们一起创造一个AI安全的新江湖!
参考资料:
[1] OWASP Top 10 2017更新解读,2027-04-28.https://mp.weixin.qq.com/s?__biz=MjM5ODYyMTM4MA==&mid=2650388164&idx=4&sn=df7ead2861d41bc0fe678de59774b9a1
[2] Projects for Good.https://owasp.org/projects/
[3] OWASP Top Ten.https://owasp.org/www-project-top-ten/
[4] OWASP LLM TOP10大语言模型应用程序十大安全风险,2024-12-31.http://www.owasp.org.cn/OWASP-CHINA/owasp-project/owasp-59278/
[5] OWASP Top 10 for Large Language Model Applications.https://owasp.org/www-project-top-10-for-large-language-model-applications/
[6] OWASP Top 10 for LLM is now the GenAI Security Project and promoted to OWASP Flagship status,2025-03-26.https://genai.owasp.org/2025/03/26/project-owasp-promotes-genai-security-project-to-flagship-status/
[7] Introduction.https://genai.owasp.org/
[8] https://atlas.mitre.org/matrices/ATLAS
[9] 网络安全人士必知的人工智能对抗模型MITRE ATLAS,2024-01-27.https://mp.weixin.qq.com/s/-wbDMuOs6MzHYMGT0NM65A
[10]NIST AI RMF AI风险管理框架.https://doi.org/10.6028/NIST.AI.100-1
[11]什么是 ISO/IEC 42001?,2023-12.https://www.iso.org/standard/81230.html
[12]EU AI Act.https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
[13]EU AI Act.https://www.artificial-intelligence-act.com/
[14]人民邮电报.全球首部!欧盟《人工智能法案》正式生效,2024-08-02.https://www.secrss.com/articles/68782
[15]Responsible AI.https://www.gartner.com/en/information-technology/glossary/responsible-ai
[16]SAIF.https://saif.google/
[17]Google发布安全人工智能框架SAIF, 2023-06-12.https://www.secrss.com/articles/55542
[18]https://saif.google/secure-ai-framework/saif-map
[19]https://developers.google.cn/machine-learning/resources/saif?hl=zh-cn
[20]The Framework for AI Cybersecurity Practices (FAICP), from ENISA.https://www.faicp-framework.com/
[21]ASL.https://www.anthropic.com/news/anthropics-responsible-scaling-policy
[22]https://www-cdn.anthropic.com/17310f6d70ae5627f55313ed067afc1a762a4068.pdf
[23]Anthropic AI负责任扩展策略 (Responsible Scaling Policy) 及其启示, 2024-01-19.https://www.secrss.com/articles/63015
[24]NIST Trustworthy and Responsible AI Report Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations,2025-03-24.https://csrc.nist.gov/pubs/ai/100/2/e2025/final
[25]美国NIST发布保护AI系统免受对抗性攻击最新指南,2025-03-28.https://www.secrss.com/articles/77117
[26]NIST Trustworthy and Responsible AI NIST AI 100-2e2025 Adversarial Machine Learning.https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-2e2025.pdf
题图:架构全景图
题图创作者:晓兵与AI小助手
算法提供:
声明:本文来自锐安全,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
