原文标题:Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools(无幻觉?领先法律AI研究工具的可靠性评估)
文章来源:Journal of Empirical Legal Studies, Volume 22, Issue 2, June 2025
作者:Varun Magesh1;Faiz Surani1;Matthew Dahl2;Mirac Suzgun1;Christopher D. Manning1;Daniel E. Ho1
1斯坦福大学法规、评估与治理实验室 2耶鲁大学
编译:王子康(澳门科技大学法学院硕士),马超(对外经济贸易大学法学院副教授)
摘 要
在法律实务领域中,融入人工智能(AI)的产品数量急剧增加。这类工具旨在协助完成一系列核心法律任务——从判例法的检索与总结到法律文书的起草等。然而,这些工具所使用的大语言模型容易出现“幻觉”(即编造虚假信息),使其在高风险领域的应用充满风险。近期,某些法律研究服务提供商宣称检索增强生成(retrieval-augmented generation,“RAG”)等方法能够“消除”或“避免”幻觉,或保证提供“无幻觉” 的法律引证。由于这些系统的封闭性,系统性评估此类主张颇具挑战。本文设计并报告了首个针对 AI 驱动法律研究工具的预先注册实证评估,结果表明服务商的宣传存在夸大。尽管相较于通用聊天机器人(如GPT-4),幻觉现象有所减少,但Lexis+ AI和汤森路透(Westlaw AI 辅助研究及Ask Practical Law AI)开发的AI法律研究工具仍分别有17%至33%的概率产生幻觉。作者还记录了不同系统在响应能力和准确性上的显著差异。本文作出了四项关键贡献:首次评估并报告了基于RAG的专有法律 AI工具的性能;引入了一套全面且预先注册的数据集,用于识别和理解此类系统的漏洞;提出了区分幻觉与准确法律回应的清晰类型学;为明确法律专业人士在监督和验证AI 输出方面的责任提供了证据,而这一责任的界定仍是AI在法律领域负责任整合的核心开放性问题。
一、引言
大语言模型有望执行复杂的法律任务,但其应用仍受制于一个关键缺陷:它们倾向于生成错误或误导性信息——这一现象通常被称为“幻觉”(hallucination)。
近期,LexisNexis和汤森路透(Westlaw母公司)等法律科技企业声称,通过使用检索增强生成(RAG)等先进技术,基本可防范法律研究任务中的“幻觉”问题。但这些宣传均缺乏实证依据,且“幻觉”一词在营销材料中往往未被明确定义,导致公众对这些工具实际缓解的风险产生混淆。因此,本研究旨在通过评估LexisNexis(Lexis+ AI)和汤森路透(Westlaw AI辅助研究及 Ask Practical Law AI)提供的人工智能法律研究工具(并以GPT-4作为对照)的性能,来填补这些空白。
二、幻觉问题与RAG
在法律场景中,模型产生幻觉主要有三种表现:背离训练数据、背离提示输入、背离客观事实。作者关注旨在帮助律师理解法律事实的研究工具,故聚焦于第三种类型:事实性幻觉(factual hallucinations)(译者注:在法律领域中,事实性幻觉是指模型输出与客观事实或法律相悖的内容的一种现象)。
在诸多领域,RAG被视为并大力推广为使LLM在特定领域有效运行的关键技术。它允许通用型LLM有效利用企业或领域特定数据,并通过直接提取检索文本生成更详细准确的回答。特别是在法律领域中,RAG 常被视为解决“幻觉”问题的方案。
FIGURE 3展示了RAG将查询转化为响应的过程:
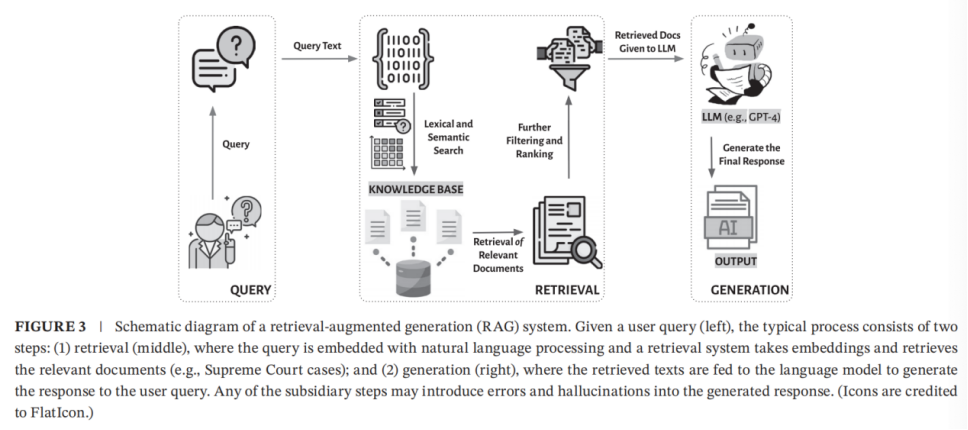
RAG 将查询转化为响应主要包含两个步骤:(1)检索(retrieval);(2)生成(generation)。检索是从海量文档中筛选相关文件的过程,搜索引擎通过关键词、用户信息和其他上下文,从互联网数百万网页中快速定位少量相关页面。获取检索文档后,生成步骤将这些文档与原始查询文本一同提供给LLM,使其结合两者生成回答。许多RAG系统会对输入输出进行额外预处理和后处理,但检索和生成是RAG的核心特征。
但RAG难以完全解决法律领域的幻觉问题:
首先,法律检索极具挑战性。法律查询往往不存在单一明确的答案。在普通法法系中,判例法由法官逐年撰写的裁判文书形成,先例如同接龙小说般逐案层累。这些法律文书并非原子事实(atomic facts。译者注:原子事实指世界中最简单、不可再分的事实单元);甚至有观点认为,法律是一种“本质上争议的概念”(essentially contested concept。译者注:本质上争议的概念是指因概念内涵具有开放性、价值负载性,不同理论流派难以达成共识的基础性概念,如“正义”“权利”等)。因此,在法律场景中判断检索内容极具难度:理想情况下,RAG需跨时间和地域从多源信息中定位内容,以恰当地回答查询。而在最坏的情况下,若问题新颖或存在不确定性,可能没有任何可用文档能明确回答该查询。
其次,法律场景中的文档相关性不止于文本层面。多数检索系统基于文本相似度识别相关文档,但仅因文本相似而实际无关的干扰性文档会对通用问答任务性能产生负面影响。此类问题在法律领域可能更复杂:不同法域、不同时期的适用规则或相关判例可能存在差异,即便是在同一时空下表述相似的文本,若未满足特殊条件也可能不适用。若特殊条件下的规则与普遍适用规则冲突,问题会更严重——LLM可能接受过更多支持普遍规则的文本训练,因而更忠实于训练数据而非检索语境。因此,设计高质量研究工具需审慎处理检索中的非文本要素,并使模型尊重不同信息源的权威性。
最后,生成有意义的法律文本绝非易事。法律文书通常面向熟悉同一议题的专业群体,且需依赖大量背景知识才能正确理解和适用。有效的生成式法律研究工具不能仅做简单文档摘要,而需综合不同文本中的事实、裁判要点和规则,同时兼顾法律语境。
三、法律幻觉的定义
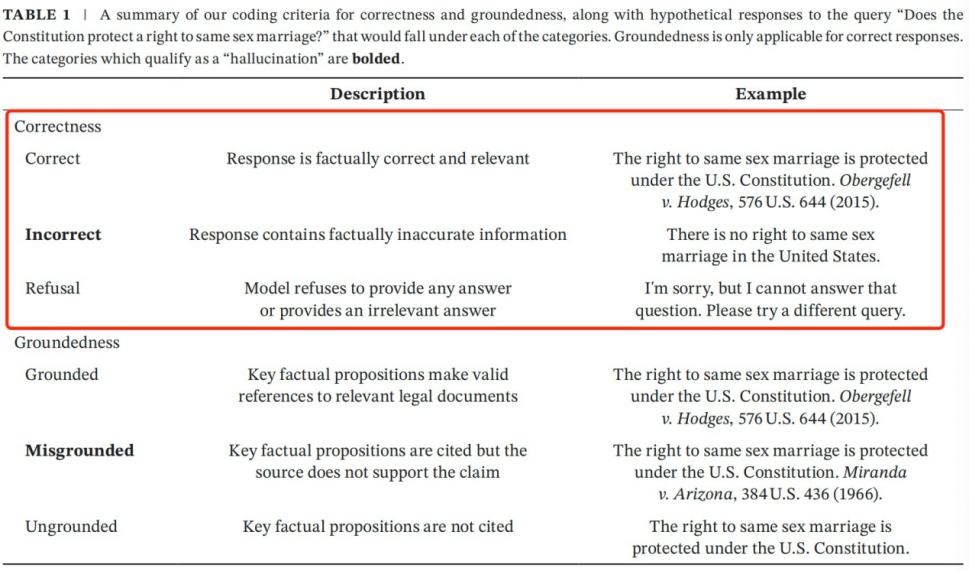
作者从两个核心维度分析了法律幻觉:正确性(Correctness)与依据性(Groundedness)。正确性指工具响应的事实准确性,依据性指模型响应与所引来源的关联性。
(一)正确性
1. 若响应既事实准确又与查询相关,则视为“正确”(correct);
2. 若包含任何事实性错误信息,则视为“错误”(incorrect);
3. 若模型直接拒绝响应,则标记为“拒绝回答”(refusal)。
三种分类的示例见TABLE 1上半部分(红框部分)。
(二)依据性
对于正确的响应,作者进一步评估其依据性:
1. 有依据(grounded):响应中的关键事实主张有效引用了相关法律;
2. 依据错误(misgrounded):关键事实主张虽引用了来源,但曲解了内容或援引了不适用的法律。
3. 无依据(ungrounded):关键事实主张未引用任何来源。
依据性分类的示例见TABLE 1下半部分(红框部分)。
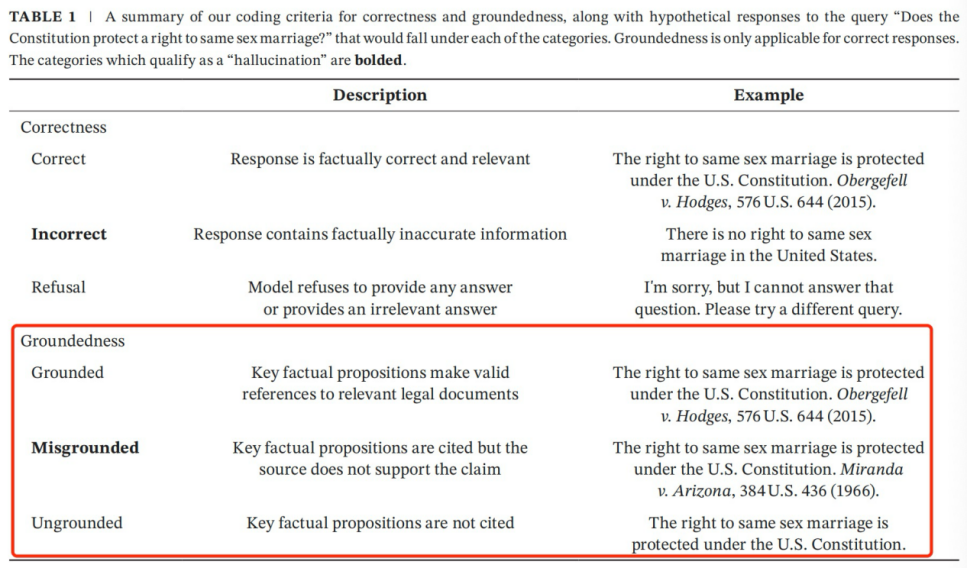
基于上述维度,作者对幻觉作如下界定:若响应存在错误(incorrect)或依据错误(misgrounded),即构成幻觉。质言之,模型作出虚假陈述或虚假声称某来源支持其某陈述的行为,均属于幻觉。
(三)准确性与完整性
除幻觉外,作者还基于正确性与依据性维度定义了另外两类标签:
1. 准确响应(accurate responses):即正确且有依据的回答;
2. 不完整响应(incomplete responses):包括拒绝回答和无依据的回答。
四、研究方法
作者研究了三款基于RAG的法律AI工具的幻觉率和响应质量:LexisNexis 的Lexis+ AI、汤森路透的Ask Practical Law AI和Westlaw的AI辅助研究(AI-AR)。同时,作者还评估了GPT-4的幻觉率和响应质量。
(一)查询构建
作者设计了一组多样化的法律查询,以考察法律RAG系统性能的不同维度。该基准数据集旨在模拟真实法律研究场景。
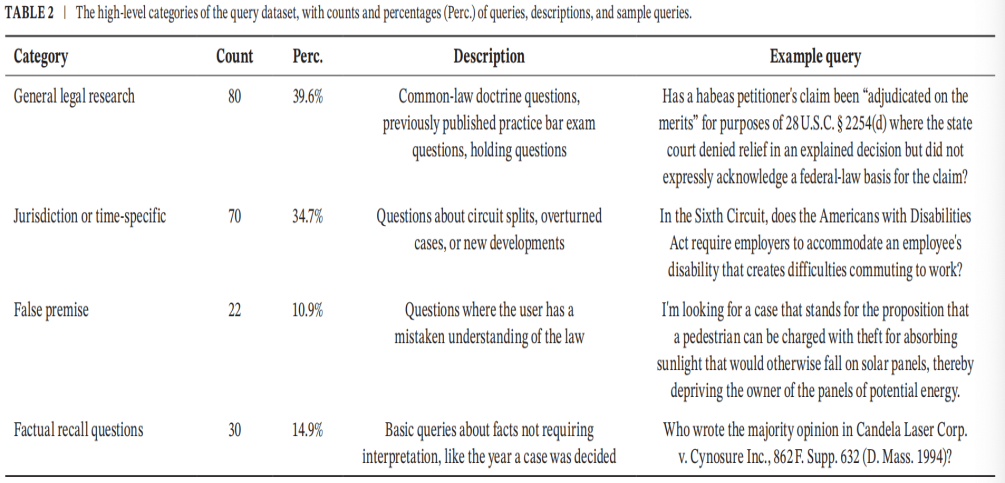
为便于解读,作者将查询分为四大类:
1. 一般性法律研究问题(General legal research questions):含普通法教义问题、裁判要点问题和律师资格考试问题。此类查询包含具有可靠答案的律师资格考试问题,旨在评估完整生成响应中的幻觉。
2. 法域或时间特定问题(Jurisdiction or time-specific questions):含关于巡回法院分歧、被撤销的判例或法律新发展的问题。
3. 虚假前提问题(False premise questions):即用户对法律存在误解的问题。该查询旨在考察LLM是否倾向于假定查询前提为真(即便前提明显错误)。
4. 事实复述问题(Factual recall questions):即关于案件事实(无需解释)的查询,如裁判文书作者和法律引用事项。该查询旨在考察RAG能在多大程度上克服通用LLM在编码法律知识方面的已知缺陷。
TABLE 2 描述了这些类别,并为每类提供了一个示例问题:
(二)查询执行
对于Lexis+ AI、汤森路透的Ask Practical Law AI和Westlaw的AI-AR,作者通过将查询复制粘贴到各产品的聊天窗口中执行。对于GPT-4,作者通过 OpenAI API(模型gpt-4-turbo-2024-04-09)向LLM发送以下指令(后附查询):
“你是一个协助回答法律问题的助手。除非绝对必要,否则不要含糊其词,务必精确回答问题并引用判例法支持主张。”
(三)评分者间信度(Inter-Rater Reliability)
作者根据上述关于幻觉的定义对每个模型响应进行了评分,并评估了数据集中不同评分者的评分者间信度。结果表明,评分者与初始评分在最终结果标签上的科恩卡帕系数(Cohen"s kappa)为0.77,评分者间一致性为85.4%,表明任务和标签分类体系定义良好。
五、研究结果
(一)幻觉在各类查询中普遍存在
结果表明,在作者的查询中,有超过六分之一的问题导致Lexis+ AI和Ask Practical Law AI作出误导性或虚假信息回应。Westlaw的幻觉率显著更高——其回应中有三分之一包含幻觉。
FIGURE 4左栏按产品细分了响应类型。结果表明,Lexis+ AI、Westlaw AI-AR和Ask Practical Law AI的查询准确率(即正确且有依据)分别为65%、41%和19%,不完整回答率分别为18%、25%和62%。
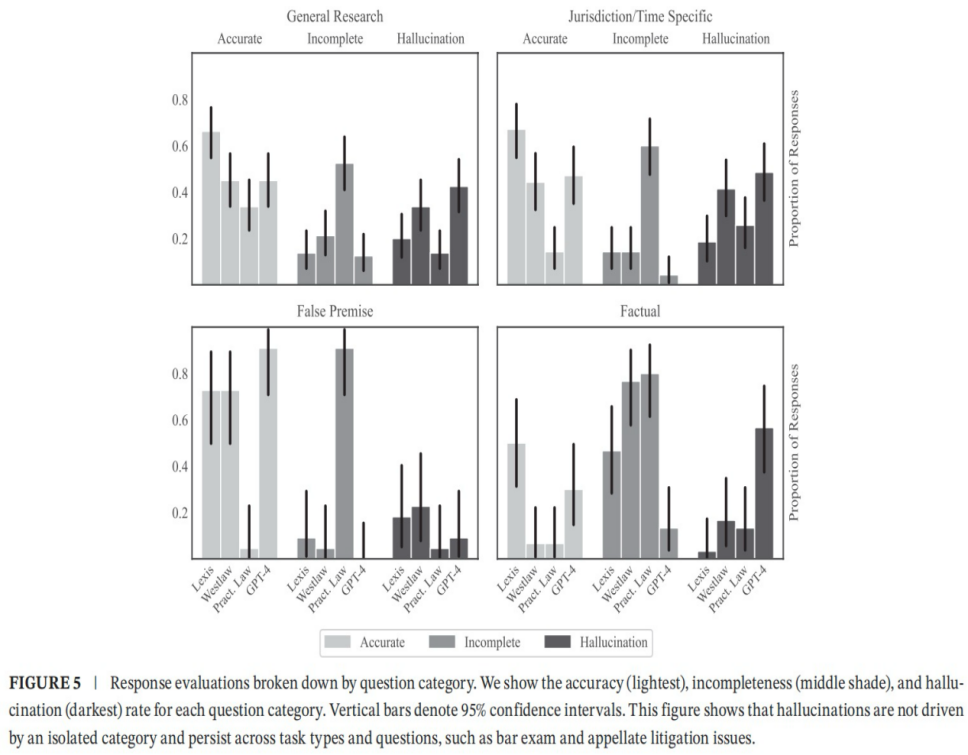
FIGURE 4右栏展示了响应时的幻觉率,表明即使在有回应的情况下,Lexis+ AI的幻觉率在统计上也显著低于Westlaw AI-AR和Ask Practical Law AI。
FIGURE 5按查询类型细分了这些统计数据。结果表明,法域和时效性问题的幻觉率略高,一般性法律研究问题的幻觉率居高不下,虚假前提问题的准确率最高。
(二)幻觉可能具有隐蔽性
具体表现为:
1. 误解裁判要点。系统似乎无法始终如一地识别案件的裁判要点。这是一个严重的问题,因为法律研究的核心在于区分裁判要点与案件的其他部分。
2. 混淆法律主体。系统可能无法区分诉讼当事人的主张与法院的裁判表述。如某产品在一个案例中将被告的主张错误归为法院的立场。
3. 忽视法律渊源层级。所有模型均难以理解法律渊源的层级体系。
4. 虚构内容。系统偶尔会生成与检索文档无关或严重偏离的内容,如虚构不存在的法律条款。
(三)法律RAG错误的类型学
1. 简单检索错误。三个产品的许多幻觉源于检索质量低下——未能找到解决用户查询最相关的可用来源。如当被要求定义某法律概念时,某产品依赖一个看似相似但实际无关的法律术语进行定义。
2. 援引不适用的法律渊源。当模型援引或讨论不适用于查询事项的法律渊源时,即构成该错误,具体原因可能包括法域错误、成文法错误、法院错误或渊源已被废止。
3. 附和倾向(sycophancy)。即,即使用户错误,系统也倾向于认同用户。
4. 推理错误。即,即使检索结果相关且有用,也未必总能通过文本推理得出正确结论。
六、结论
本研究表明,用于法律研究的AI工具并未消除幻觉。这些工具的使用者必须继续验证关键问题是否有准确的引用支持。同时,法律领域的AI工具需要严格、透明的基准测试和公开评估。供应商主导的基准测试工作虽然方向正确,但远远不够。此外,尽管与传统的关键词搜索方法和通用AI系统相比,法律AI工具能为法律研究者提供相当大的价值,尤其是在用于法律研究的第一步而非用于做最终结论时。但在供应商提供确凿的可靠性证据之前,宣称法律AI工具无幻觉的说法至多是毫无根据的。
关于我们
“实证法研”公众号专注于传播法律实证研究的理念与方法。平台运营团队由国内外多所高校师生跨学科组成。目前公众号由马超(对外经济贸易大学法学院)负责日常运营工作,郑兆祐(伦敦大学政治学系)、周文章(山东大学法学院)和詹小平(四川大学法学院)担任顾问委员。公众号联系邮箱:empirical_legal@163.com,诚挚欢迎学界同仁关注我们,并提供您的建议。
声明:本文来自实证法研,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
