
原文标题:TrafficLLM: Enhancing Large Language Models for Network Traffic Analysis with Generic Traffic Representation
原文作者:Tianyu Cui, Xinjie Lin, Sijia Li, Miao Chen, Qilei Yin, Qi Li, Ke Xu原文链接:https://doi.org/10.48550/arXiv.2504.04222笔记作者:宋坤书@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、研究背景
网络流量作为互联网交互和传输的基础,不仅被用于进行正常的网络活动,也被攻击者利用进行各种恶意活动。网络流量数据分析在威胁检测、事件调查和环境监控中发挥着越来越重要的作用。现有研究已在许多任务中取得了显著进展,特别是基于机器学习的方法在多样化流量模式学习方面展现出巨大的潜力,但其对不同任务和未知数据的模型泛化能力较差。此外,随着网络环境变化,模型的性能还会进一步下降。
为此,本文提出了一种基于开源大语言模型(LLM)的双阶段微调框架——TrafficLLM,旨在通过专家指令和原始流量数据学习通用流量表示,从而提升泛化能力。TrafficLLM设计了三大核心模块:缩小流量与文本之间的输入差异的流量领域分词(Traffic-domain Tokenization)、对文本和流量数据进行多模态学习的双阶段微调流程(Dual-Stage Tuning Pipeline)和促进LLM泛化到新环境的基于参数高效微调的可扩展适配(Extensible Adaptation with PEFT)。实验结果表明,TrafficLLM在10项下游任务中比现有研究方法的性能有着较高的提升,并在真实环境测试中展现出更强的适应性。
2、TrafficLLM框架设计
TrafficLLM通过一个双阶段微调框架,使用大量的专家指令和原始流量数据来构建领域知识,自动提取任务相关的流量模式,形成跨任务的通用表示,以提升LLM不同流量分析任务中的泛化能力。TrafficLLM主要设计了三个模块:流量领域分词、双阶段调优管道和基于参数高效微调的可扩展适配。TrafficLLM框架结构如下图:
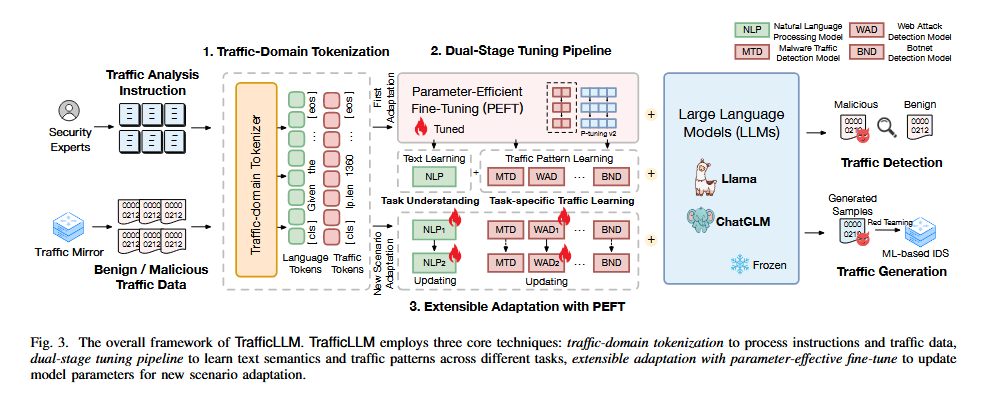
2.1 流量领域分词(Traffic-Domain Tokenization)
流量领域分词的核心在于将异构的网络流量数据和自然语言映射到同一特征空间,从而使LLM能够直接处理原始网络流量。为此,TrafficLLM首先从原始包和流量中提取元信息(如tcp.srcport:443、ip.len:1360等),并结合专家指令框架以生成调优数据:在每条数据前插入 指示符,将协议字段与对应值组织成“字段名:值”的对,并附以任务指令(如“请检测该流量属于哪个应用”或“请生成一条 Skype 流量包”)。这种基于指令学习的调优数据设计,有助于LLM获取领域知识,从而捕获有价值的语义,用于跨任务的模式学习。
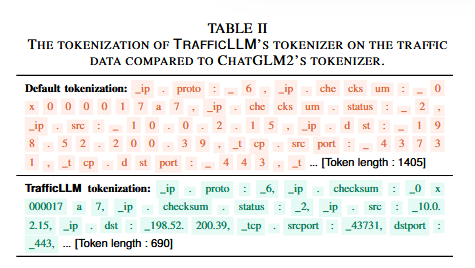
在此基础上,TrafficLLM使用大规模调优数据训练了专用的流量领域分词器(基于BPE方法),将常见字段名和值作为整体token保留,这与LLM默认分词器将tcp、checksum等拆分成子词的方式有着显著的不同。该分词器不仅能准确保留语义信息,还能将平均token长度从原生LLM的1445降至699,实现处理效率的提升。分词器的对比如下表:
2.2 双阶段微调流程(Dual-Stage Tuning Pipeline)
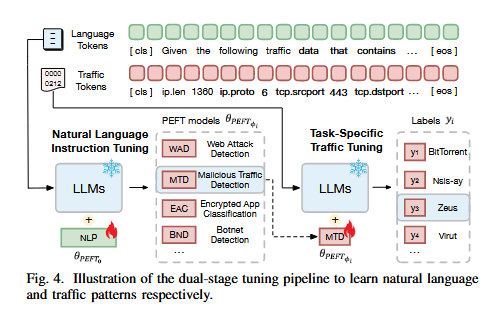
TrafficLLM提出了一个双阶段微调流程,旨在帮助LLM获取领域知识,以实现多样化流量分析任务的通用表示学习。该流程可以帮助LLM获得两种能力:一是理解任务相关的自然语言,以确定应执行的任务;二是学习跨不同任务的特定流量模式。通过专家指令的指导,TrafficLLM能够自动从编码输入中提取任务特定的流量模式,进而在不同任务之间构建通用的表示。
TrafficLLM利用LLM在模式挖掘和泛化能力上的优势来学习通用的流量表示。这些流量表示可以通过深度Transformer架构的强大记忆能力,获得从元信息中学习到的不同流量模式。TrafficLLM自动整合这些异构数据,并确定它们对不同任务的重要性。通过这些通用表示,TrafficLLM可以实现流量检测和流量生成这两项主要任务。
双阶段微调流程分为两个阶段:
自然语言指令微调:第一阶段的目标是使LLM理解专家给出的任务指令,并准确预测需要执行的任务名称。在这一阶段,LLM通过处理自然语言指令文本来学习任务的上下文。模型通过自回归目标优化其参数,以便理解和预测任务名称。这一阶段的关键在于准确地将任务指令与相应的任务类型匹配,从而为后续任务学习打下基础。
任务特定流量微调:第二阶段专注于根据已理解的任务指令,学习特定任务的流量模式。在这一阶段,TrafficLLM通过微调流量数据(如数据包或流)来适应任务特定的流量表示。对于流量检测任务,LLM根据输入的流量数据和指令预测流量标签;对于流量生成任务,LLM生成符合指令要求的生成流量。
通过这两个阶段的结合,TrafficLLM能够在VPN、Tor等多种网络场景下执行不同的流量分析任务,并生成高质量的流量表示。两个阶段的流程如下图:
2.3 基于参数高效微调的可扩展适配(Extensible Adaptation with parameter-effective fine-tuning, EA-PEFT)
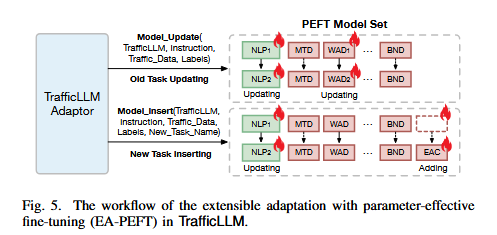
TrafficLLM通过EA-PEFT实现了对新流量环境的快速适应。EA-PEFT的核心是将不同任务的流量表示能力拆分成不同的附加参数,从而支持TrafficLLM选择性地更新部分能力,以支持其在新环境中迅速更新表示。这种方法解决了传统机器学习方法中重新训练模型的高成本问题,通过冻结LLM的原始参数,仅调节额外的参数来进行微调。
在流量领域适应过程中,TrafficLLM通过使用额外的PEFT参数(如 θ 和 θ φ )分别实现任务理解和任务特定的流量学习。EA-PEFT技术使TrafficLLM可以更新模型或注册新任务,使其能够轻松适应新环境。实验结果表明,EA-PEFT显著降低了适应成本,其工作流程如下图:
3、实验设计
TrafficLLM的实验在一台配备5个NVIDIA A100 80G GPU的超级GPU服务器上进行,采用的操作系统为Ubuntu 18.04.1,内存为1TB。使用PyTorch 2.0.1构建TrafficLLM原型,并通过Python脚本将TrafficLLM适配器和PEFT模型集成到EA-PEFT框架中。实验中主要使用Llama27B和ChatGLM2-6B作为基础LLM,并选择P-Tuning v2作为PEFT方法。为了避免数据不平衡问题,数据预处理阶段对每个类别进行数据采样,训练集、验证集和测试集的比例设置为8:1:1。
在数据集方面,为了全面评估TrafficLLM的有效性,实验中收集了多个流量数据集和自然语言指令,以用于LLM的适配和实验。实验使用了10个不同场景的流量数据集,涵盖了约40万条训练数据。这些数据集用于评估TrafficLLM在不同任务中的泛化能力。对于流量检测任务,实验选择了8个数据集来衡量TrafficLLM检测恶意和良性流量的能力。此外,还使用了这些数据集来实现流量生成,通过生成的流量数据来评估TrafficLLM的流量生成能力。同时,为了评估模型在未知数据上的泛化能力,实验还设置了概念漂移和APT攻击检测任务,使用了APP-53 2023和DAPT 2020这两个具有代表性的数据集。
在自然语言指令方面,研究人员邀请了安全专家和大学生对每个下游任务的任务提供描述,并利用ChatGPT重写这些指令,以增加指令的多样性。每个指令至少被重写20次,最终收集了约10K条文本指令用于进行训练。
4、实验结果评估
实验结果表明,TrafficLLM在各种检测和生成任务中表现出色,具体结果如下:
4.1 检测任务中的泛化能力
TrafficLLM在不同检测任务中有良好的泛化能力,在10个数据集、229类流量上,TrafficLLM的F1分数范围为0.9320-0.9960,比所有的基准模型最多提升80.12%。相较于预训练模型PERT和ET-BERT,TrafficLLM在F1分数上最多提升9.63%。即使推理阶段随机缺失15%的特征,TrafficLLM仍保持0.9171的Macro-AUC,远超ET-BERT和PERT,体现出其强大的泛化能力。在不同数据集上的流量检测对比如下表:
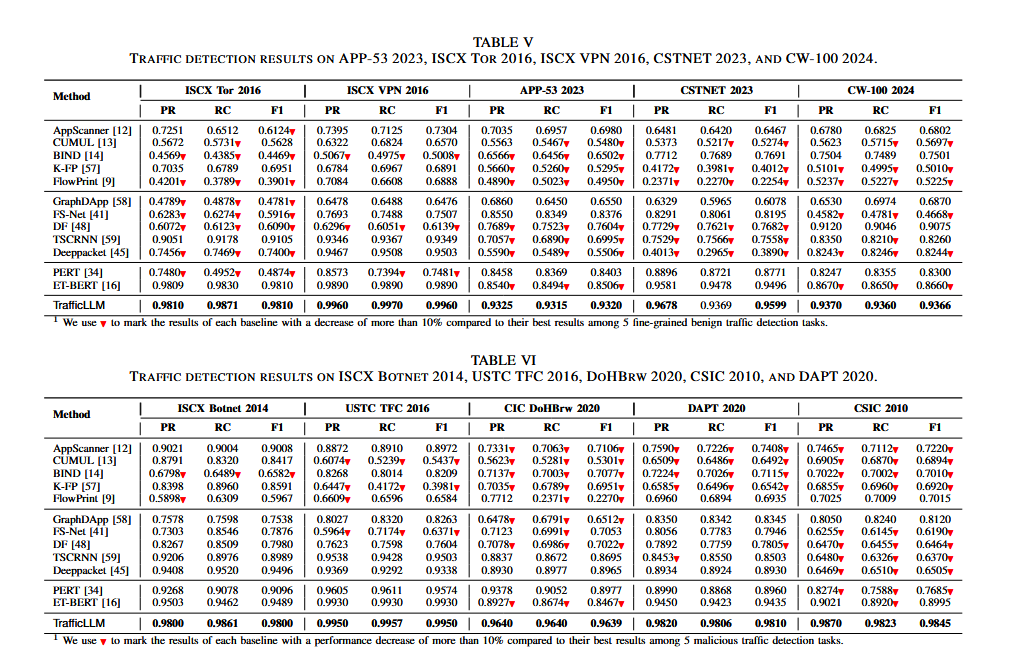
4.2 生成任务中的泛化能力
TrafficLLM在不同生成任务中展现了优秀的泛化能力。与现有方法相比,它在流量分布上最多提升了73.76%,比最好的方法JSD降低约39.32%。生成流量在真实分类器上的平均F1得分为0.9483,比最好的方法提升4.68%,在小样本训练场景下也取得了最高0.8739的平均F1分数,显著优于现有方法。真实数据包和生成数据包的分类性能对比如下表:
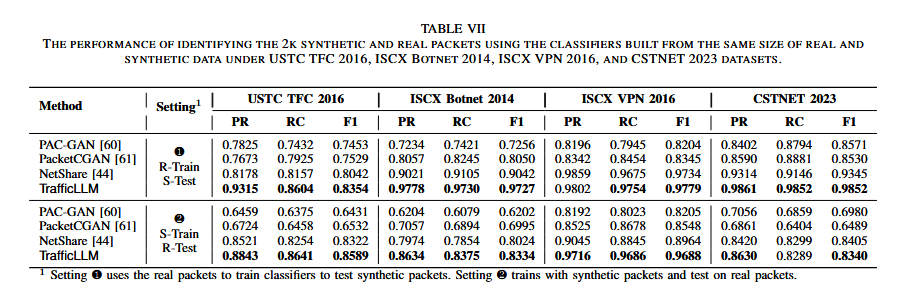
4.3 未知数据上的泛化能力
TrafficLLM在未知数据上展现了卓越的泛化能力。在时间漂移和版本漂移场景中,其F1分数比现有方法高出4.3%-18.6%,在APT攻击检测中达到89.3%的平均F1分数。进一步分析表明,TrafficLLM的泛化能力主要来源于预训练的大模型知识和针对流量领域的微调(PEFT),缺少这两部分会导致性能大幅下降。
4.4 深入分析
TrafficLLM具有良好的可适配性,能够在Vicuna、Mistral和Gemma等多种开源LLM上稳定运行;6B规模的模型已能超越现有的机器学习方法。核心组件(如流量领域分词、双阶段微调和EA-PEFT)对性能和资源消耗影响显著,修改它们会导致最大78.7%的性能下降。训练开销适中,在NVIDA A100-80GB GPU上训练6B模型需14小时、23GB显存,推理阶段资源占用少,可以考虑使用更小的LLM或使用压缩方法来加快自适应速度。
4.5 真实世界评估
在真实世界评估中,TrafficLLM在一场包含1901支队伍、3000余人参与的全国大赛中进行了广泛测试,结果显示58%的选手模型准确率超过90%,24%的选手超过96%,验证了TrafficLLM易于使用且性能强大。同时,TrafficLLM在一家大型安全公司实际部署,用于恶意流量(MTD)与Web攻击(WAD)检测任务,分别达到98.7%和99.8%的F1分数,误报率较传统方法降低69%-95%,展现了其在企业场景下的高准确性和强泛化能力。
5、本文贡献
提出了TrafficLLM,一种基于专家指令与原始流量数据进行双阶段微调的框架,帮助LLM从领域知识中获取通用的流量表征并具备强泛化能力;
设计了三项核心技术(流量领域分词、双阶段微调流程、EA-PEFT),解决了LLM在流量领域应用的挑战;
构建了首个大规模流量领域LLM适配数据集(包含40万条指令文本和流量数据),以供未来研究使用;
进行了广泛的实验,实验结果表明TrafficLLM在多种下游任务上优于15种现有方法,其在未知数据和真实环境中也展现出优异的泛化能力。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
