
原文标题:Encrypted traffic classification: the QUIC case
原文作者:Jan Luxemburk, Karel Hynek, Tomas Cejka原文链接:https://doi.org/10.23919/TMA58422.2023.10199052发表会议:TMA笔记作者:宋坤书@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、研究背景
QUIC协议是一种新型的可靠传输协议,目前以获得广泛采用。它已经在基于Chromium的浏览器和Firefox中实现,Google、Meta和Microsoft等大型公司也用它传输核心服务。QUIC协议正逐步替代传统基于TCP的协议,如SMB协议就是基于QUIC实现的,HTTP/3也选择了QUIC作为传输层协议,这表明其在未来网络通信中存在着巨大的应用潜力。
与TCP协议相比,QUIC最显著的特性就是强制加密通信,所有数据都通过TLS加密,这使得攻击者无法对QUIC的有效载荷内容进行检测和分析。QUIC连接握手重用了 TLS握手的结构(如ClientHello、ServerHello、Certificate),但这些内容都被进行了加密混淆处理。因此,为了监测QUIC流量,需要额外解密这些握手消息,随着QUIC流量的增长,传统的监控方式难以处理如此大规模的解密,这使得我们思考如何在不解密的情况下对QUIC流量进行有效监测。
尽管近年来对加密流量(如TLS)分类的研究取得了一些成果,但在QUIC流量分类的研究仍处于起步阶段,现有研究的数据集较小且流量类别不足。本文使用大型运营商主干线路采集的CESNET-QUIC22数据集,评估了三种QUIC流量分类方法:多模态卷积神经网络(mmCNN)、LightGBM树模型和基于IP的分类器。该数据集包含超过1.53亿个流和102种服务标签,实验结果揭示了不同方法的性能差异和实际适应性,为未来的QUIC流量分类的研究提供了重要参考。
2、QUIC流量分类器设计
CESNET-QUIC22数据集收集了捷克CESNET2教育科研网络中连续四周QUIC流量,覆盖超过1.53亿条网络流,并附带丰富的特征信息,如基于流的统计数据(传输的数据包数、字节数)、数据包直方图及数据包元信息序列(数据包大小、到达时间间隔、方向等)。每条流量都标注了服务标签(来源于解密后的QUIC初始握手包中的SNI域获取的Web服务名称),共涵盖102种不同服务,其中包含Google的27项服务和Facebook的9项服务。
本文介绍了三种用于QUIC流量分类的模型,分别是多模态卷积神经网络(mm-CNN)、LightGBM和基于IP的分类器。所有模型均在CESNET-QUIC22数据集上进行训练与评估,使用第一周的3000万条流作为训练集,剩余三周中抽取了2000万条流作为测试集。评估指标包括准确率、宏平均F1分数和宏平均召回率。
2.1 深度学习分类器(多模态CNN)
多模态卷积神经网络(mm-CNN)是本研究采用的第一个模型,具备同时处理不同类型网络数据的能力。在输入方面,模型使用了数据包元数据序列(Sequence of Packet Metadata, PSTATS)和流量统计信息(Flow Statistics, FLOWSTATS):PSTATS是前三十个数据包的元信息序列(数据包大小、方向、包间间隔),FLOWSTATS是流的统计特征(双向传输的字节数、数据包数、持续时间和数据包直方图等)。实验中对数据进行预处理,其中,数据包大小和时间被进行了归一化处理,数据包方向被编码为±1,极端值被裁剪以抑制异常影响。
网络结构方面,mm-CNN采用了两条独立的输入链,分别处理PSTATS和FLOWSTATS。前者通过一维卷积层处理,后者则通过全连接层处理,两者在中间层合并形成共享表示。模型引入了批归一化,采用Dropout进行正则化、GeM进行池化操作,增强了模型的稳定性和泛化能力,最终输出结果通过softmax进行多分类。模型训练和评估遵循标准的深度学习流程,采用了AdamW优化器、one-cycle学习率调度器和交叉熵损失函数。多模态CNN的架构如下图:
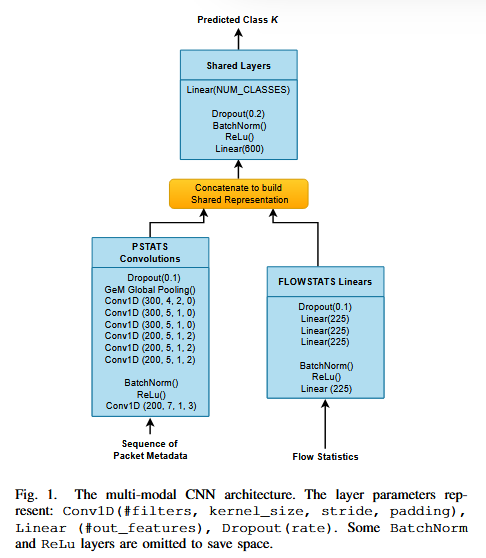
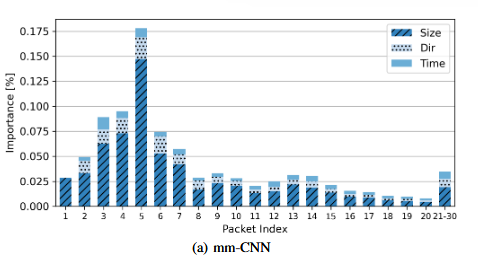
本文通过SHAP方法[1]计算每个样本的特征重要性,并将其聚合(绝对值的均值)以展示模型的全局特征。通过将全局特征重要性归一化,使其总和为1。观察PSTATS特征重要性可以发现,前几个数据包的大小信息对分类结果贡献最大,尤其是第5个数据包,这可能与服务器证书传输有关,尽管其被加密,但其大小仍能泄露对服务识别有用的信息。mm-CNN模型PSTATS的特征重要性如下图:
2.2 LightGBM分类器
第二种模型是基于梯度提升决策树的LightGBM。它使用与mm-CNN相同的PSTATS和FLOWSTATS输入特征,并保持一致的数据预处理方式。与mm-CNN中使用卷积处理序列不同,LightGBM将每个包位置视为独立特征,缺乏邻接信息的建模能力,但依然取得了优异的性能,显示出树模型在加密流量分类中的潜力。
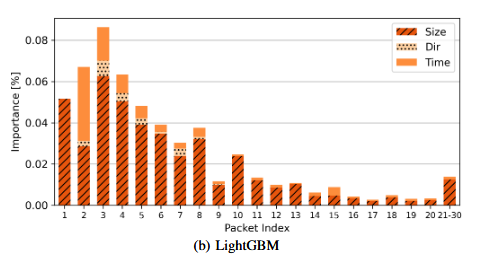
模型采用全量加载训练集,最多迭代100轮,并使用早停策略防止过拟合。通过Optuna自动调参以优化性能,调整的参数包括特征采样率、叶子数、正则化系数等。LightGBM的SHAP解释结果表明,其对前十个数据包的大小分布尤为敏感,方向信息相对不重要。该模型PSTATS的特征重要性如下图:
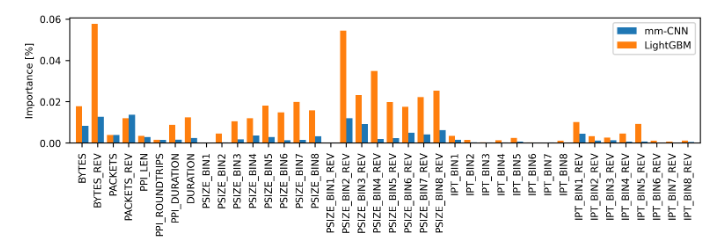
与mm-CNN相比,LightGBM更依赖统计特征FLOWSTATS,表明传统机器学习模型更偏好提取全局特征,而深度模型更能捕捉局部序列模式。LightGBM和mm-CNN分类器的FLOWSTATS特征重要性对比如下图:
2.3 基于IP的分类器
第三种方法是基于目的IP地址的简单规则分类器。该模型在训练时记录每个IP或其子网前缀下观察到的服务类别及出现次数,推理时根据目标IP查找训练集中最常见的服务进行预测。若目标IP未出现或存在多个服务共存,则退而采用子网进行匹配;若仍无法匹配,则放弃预测(记作错误)。
该方法几乎不依赖数据预处理,仅需统计出现频次,并设定两个超参数:子网匹配掩码P(如IPv4的/30)和精确匹配阈值exact_T。在实际评估中,发现设置exact_T为0表现最佳,即只要训练集中出现过该IP,便预测其出现最多的服务。子网匹配在此任务中效果较差,仅用于未见过的IP地址。尽管该方法简单高效,但对IP地址稳定性高度敏感,在动态IP场景下准确率明显下降,是一种受限明显的基线方法。基于IP的分类过程如下图:

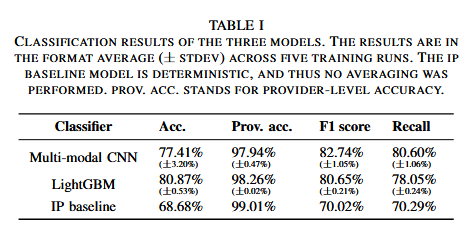
三种模型的分类性能如下表:
3、分类器性能随时间的变化
虽然表1中模型性能测试结果显示LightGBM的分类准确率最高,但为了判断其是否是最佳模型,本文分析了三种分类器在一个月内的性能随时间变化的情况,发现LightGBM虽然整体精度最高,但召回率不如mm-CNN,尤其在处理非主流服务时表现较弱,而基于IP的方法虽然整体精度略低,但在不同测试周中的表现最为稳定。例如,在第二周到第三周之间,LightGBM和mm-CNN的分类准确率出现大幅下降,分别下降了9.45%和13.48%,而基于IP的分类器则表现稳定。
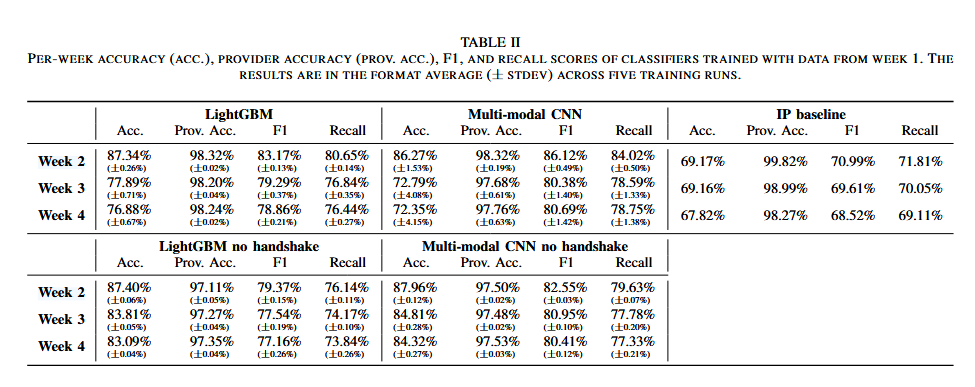
深入分析发现,性能下降主要源于Google服务中部分特征发生变化,尤其可能与TLS证书变更导致第五个数据包特征发生变化有关。通过将握手阶段数据(前8个数据包)置零,训练“无握手”版本模型后,性能在时间上变得更稳定,验证了该假设。这样做虽然准确率有了提升,但也带来了召回率的下降。分类器的每周准确率如下,上半部分为有握手阶段数据的情况,下半部分为去除握手阶段数据的情况:
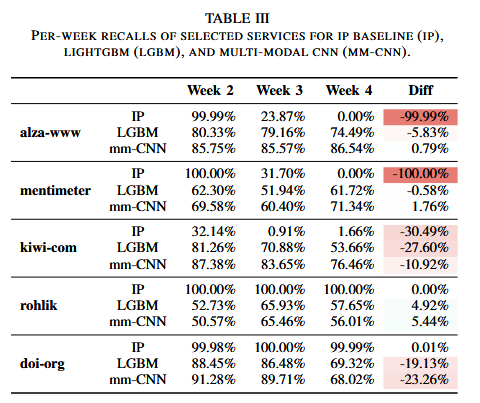
尽管IP地址分类器在IP未变化时效果非常稳定,甚至部分服务始终保持的召回率超过99%,但一旦改变其IP地址,其性能会骤降至0%。相比之下,机器学习模型虽对数据漂移更敏感,但在应对IP变化时却更具鲁棒性。针对不同的服务,分类器召回率对比如下表:
4、本文贡献
基于CESNET-QUIC22这一规模最大、类别标签最多、跨度最长的QUIC流量数据集,系统评估了多种分类模型在连续时间段上的性能,揭示了不同分类器的性能差异及其性能随时间的变化。
首次指出去除初始握手数据包有助于提高模型对数据漂移的鲁棒性,这为加密流量建模提供了新的视角。
为大规模QUIC流量分类任务设定了新的基准,并为为未来的研究奠定了基础。
参考文献:
[1] S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in Advances in Neural Information Processing Systems 30. Curran Associates, Inc., 2017, pp. 4765–4774. [Online]. Available: http://papers.nips.cc/paper/ 7062-a-unified-approach-to-interpreting-model-predictions.pdf
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
