基本信息
原文标题:
SECVULEVAL:BenchmarkingLLMsforReal-WorldC/C++VulnerabilityDetection
原文作者:
MdBasimUddinAhmed,NimaShiriHarzevili,JihoShin,HungVietPham,SongWang
作者单位:YorkUniversity
关键词:C/C++漏洞检测、基准数据集、LLMs、多智能体系统、上下文感知
原文链接:https://arxiv.org/abs/2505.19828
开源代码:暂无
论文要点
论文简介:大语言模型(LLMs)在各类软件工程任务中展现出了潜力,但由于缺乏高质量的基准数据集,评估其在漏洞检测中的有效性仍具挑战性。现有大多数数据集仅限于函数级标签,忽略了更细粒度的漏洞模式和关键上下文信息。这些数据集还普遍存在数据质量问题,如标签错误、注释不一致和重复数据,可能导致模型性能虚高和泛化能力薄弱。此外,由于仅包含易受攻击的函数,这些数据集缺失了更广泛的程序上下文(如数据/控制依赖关系和过程间交互),而这些信息对于准确检测和理解真实世界的安全缺陷至关重要。缺乏上下文的情况下,检测模型的评估基于不现实的假设,限制了其实际应用价值。
为解决这些局限性,本文提出了SECVULEVAL——一个全面的基准数据集,旨在通过丰富的上下文信息支持对LLMs及其他检测方法的细粒度评估。SECVULEVAL聚焦于C/C++语言中真实存在的语句级漏洞,这种细粒度特性使评估模型定位和理解漏洞的能力(而非简单的函数级二分类)更加精准。通过整合丰富的上下文信息,SECVULEVAL为现实软件开发场景中的漏洞检测基准设定了新标准。该基准包含25,440个函数样本,覆盖1999年至2024年C/C++项目中5,867个唯一CVE漏洞。研究者采用基于多智能体的方法对最先进的LLMs进行了评估,结果表明:在给定函数中,模型准确预测易受攻击语句的能力仍有显著差距。性能最佳的Claude3.7-Sonnet模型在检测带有正确推理的漏洞语句时,F1分数为23.83%,GPT-4.1紧随其后。研究者还评估了使用上下文信息对漏洞检测任务的影响,最后分析了LLM的输出结果,并揭示了其在C/C++漏洞检测中的行为特征。
研究目的:随着大语言模型(LLMs)在软件工程中的广泛应用,研究者对其在漏洞检测中的能力寄予厚望。然而,当前对LLMs安全能力的评估仍存在严重缺口。一方面,现有的漏洞检测数据集大多仅提供函数级别的粗粒度标签,无法满足模型对漏洞发生位置和成因的细致学习需求。另一方面,这些数据集普遍缺乏代码执行上下文信息,如变量依赖、函数调用链、类型定义及全局状态,导致模型在缺乏“环境感知”的情况下进行漏洞判断,容易产生误判或遗漏。
为了解决这些问题,本文旨在构建一个全新的漏洞检测基准——SECVULEVAL。该数据集不仅覆盖1999年至2024年间大量真实CVE,还对每个漏洞样本进行了语句级别的精准标注,并融合五类关键上下文信息。研究目标是通过SECVULEVAL,系统评估和推动LLMs在真实世界漏洞检测中的表现,使其更具实用性和解释能力,从而助力开发更安全的软件系统。
引言
在当今高度依赖数字基础设施的社会中,C/C++语言仍是关键系统的核心构建语言。然而,这类底层语言天生缺乏内存安全保障,使得其编写的程序极易成为攻击者的目标。随着代码库日益庞大、复杂度不断提高,传统漏洞检测工具难以覆盖多样化的安全威胁,尤其是在面对跨函数依赖、控制流上下文等真实世界场景时表现有限。近年来,大语言模型(LLMs)在代码生成与分析领域取得突破,但它们在实际漏洞检测任务中的表现仍缺乏系统性评估,尤其是在“是否真正理解了漏洞”的层面存在诸多质疑。
本文指出,现有C/C++漏洞检测数据集多集中于函数级分类,缺乏对漏洞发生语句的精确标注,更未考虑程序执行所需的上下文信息,导致模型训练存在偏差,泛化能力弱,难以适应现实世界的复杂情况。为此,作者提出了SECVULEVAL数据集,专注于真实C/C++项目中语句级别的漏洞识别,并引入多维上下文信息,以期为LLMs的安全能力评估提供更科学、更贴近实战的测试平台。
相关工作
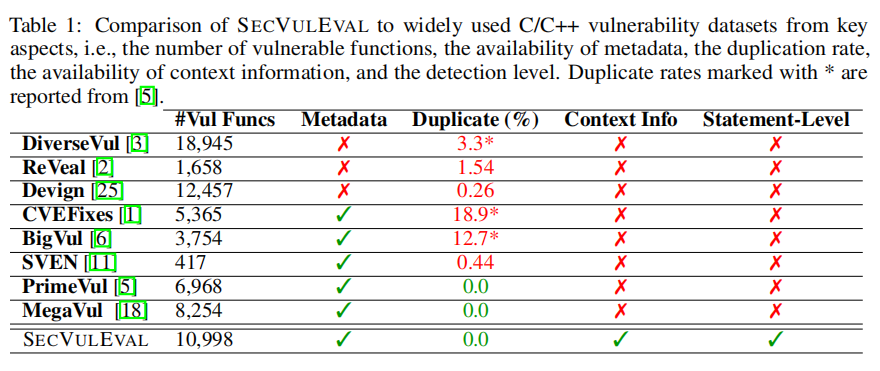
近年来,C/C++漏洞检测领域涌现出多个重要数据集,如Devign、BigVul、CVEFixes、DiverseVul、PrimeVul等,这些数据集为推动深度学习在安全检测中的应用发挥了重要作用。Devign数据集包含超过1.2万个样本,但缺乏CWE、CVE等关键信息,且存在高达20%的误标率;ReVeal数据集仅涵盖Chromium与Debian两个项目,覆盖面有限。BigVul与CVEFixes虽提供行级标签,但未能解决C/C++语言中语句跨行的复杂性,难以支撑语义层面的深度分析。
此外,许多数据集存在高重复率(如CVEFixes高达18.9%),这不仅影响模型泛化能力,还可能导致训练集与测试集间的数据泄露。SVEN虽具备人工标注的高准确率,但样本数量极少,仅收录417个函数。总体来看,这些数据集普遍停留在函数或行级别,缺乏语句级漏洞定位与必要上下文信息,限制了其在真实场景中的适用性。本文提出的SECVULEVAL正是为弥补这些不足而构建,提供更细粒度、更高质量的漏洞检测基准。
基准构建
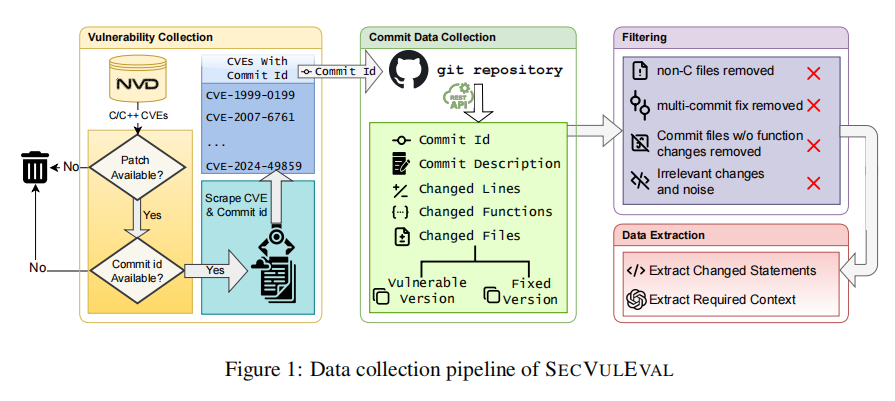
SECVULEVAL的构建过程分为四个主要阶段,旨在创建一个高质量、细粒度、具备上下文感知能力的C/C++漏洞检测数据集。首先,研究团队从国家漏洞数据库(NVD)中筛选出覆盖C/C++项目的有效CVE条目,仅保留具有修复补丁和Git提交记录的样本,并进一步剔除来源不明或重复的提交。其次,通过GitHubAPI获取每个补丁对应的代码变更内容,包括函数级和语句级的新增与删除记录,以及补丁前后的完整函数代码。
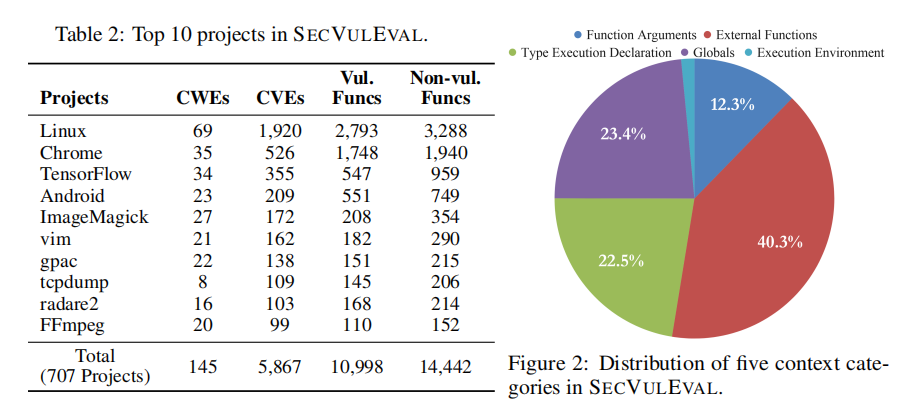
为了提升数据质量,作者引入多轮去噪策略,排除文档文件、无函数变更的提交、代码格式化操作及与漏洞无关的冗余更改。然后,通过对每个函数进行MD5哈希去重,彻底消除数据泄露风险。最后,为弥补传统数据集中缺乏上下文的问题,SECVULEVAL使用GPT-4.1自动提取五类关键上下文信息(如全局变量、类型定义、函数参数等),显著增强了模型对真实漏洞场景的理解能力。这一系统化构建流程,确保了数据集在准确性、代表性与实用性上的显著提升。
研究实验
为了全面评估当前主流大语言模型(LLMs)在C/C++漏洞检测任务中的表现,作者基于SECVULEVAL数据集设计了两项核心实验任务:语句级漏洞检测与上下文信息识别。实验的核心技术支撑是一套精心构建的多智能体检测架构,由五个不同功能的智能体(Agent)协作完成,分别负责函数标准化、风险规划、上下文识别、漏洞检测和结果验证。这种模块化设计基于已有研究表明,将复杂任务拆解为子任务交由多个LLM分工处理,能显著提升准确率与稳定性。
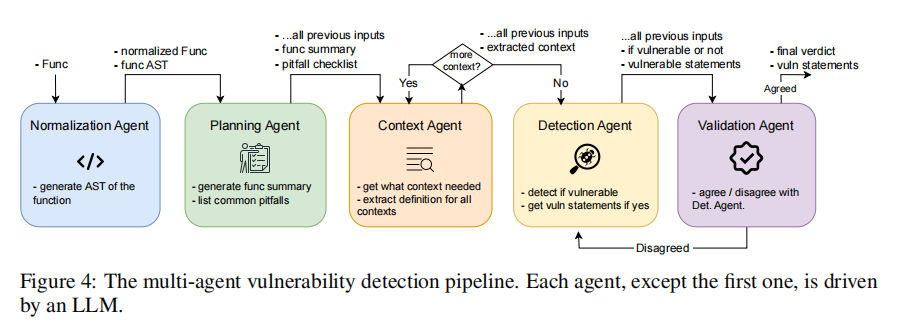
在第一个实验中,研究团队评估五个主流LLM(Claude-3.7-Sonnet、GPT-4.1、Qwen2.5-Coder、DeepSeek-Coder和Codestral)在语句级漏洞检测上的能力。每个模型在多智能体框架中运行,最终由验证智能体评估其是否能正确识别出漏洞所在语句,并给出合理解释。为确保评估客观性,作者从数据集中抽取300个样本进行人工验证。
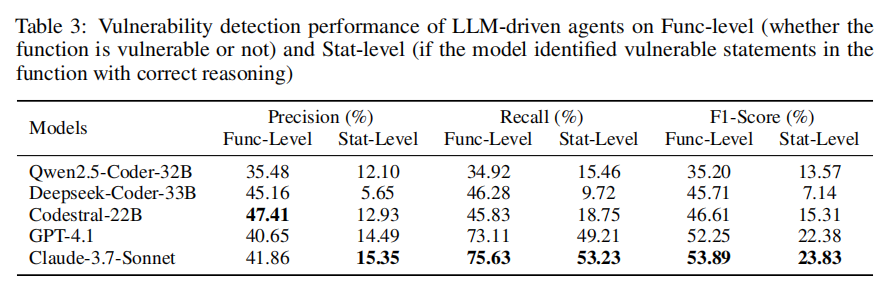
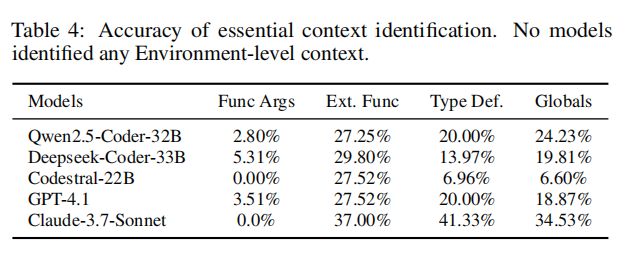
第二个实验聚焦于模型对漏洞上下文的理解与提取能力。在此任务中,模型需根据函数、补丁、CVE描述等信息,识别哪些外部符号(如函数参数、宏、全局变量)对漏洞判断是“必要”的。作者以人工注释的上下文为基准,量化每个模型在五类上下文上的识别准确率。
整体实验覆盖了模型从感知、理解到推理的全过程,旨在揭示当前LLM在代码安全领域中的优势与短板,为后续模型优化提供实践参考。
结果分析
实验结果显示,当前主流大语言模型在C/C++漏洞检测任务中仍面临诸多挑战,尤其是在语句级识别方面表现不佳。以性能最优的Claude-3.7-Sonnet为例,其在语句级检测任务中的F1分数仅为23.83%,而GPT-4.1为22.38%。尽管这两款模型在函数级别的检测中表现出较高的召回率(分别为75.63%和73.11%),但由于存在大量误报,精度普遍偏低,表明其更倾向于“宁可错杀、不可放过”的检测策略。相比之下,开源模型如Codestral和Qwen2.5则显得更为保守,虽然误报较少,但同时也错过了大量真实漏洞。
在语句级检测中,LLM需要具备更强的代码理解与推理能力,不仅要识别出漏洞语句,还要准确解释其成因。这对模型提出了更高要求,特别是在处理C/C++这种具备复杂内存管理和指针操作的语言时。实验还发现,函数长度对检测准确率有显著影响:所有模型在短函数中的检测表现明显优于长函数,表明模型在面对代码结构复杂、上下文跨度大的样本时处理能力不足。
另一个关键发现是模型在特定CWE类型上的误报倾向,例如CWE-476(空指针解引用)和CWE-190(整数溢出)常被过度标记为存在漏洞,即便代码中已包含防护逻辑。此外,模型经常错误地将free()或kfree()后的立即返回操作误判为“Use-After-Free”漏洞,暴露出其在控制流分析方面的薄弱环节。
总体来看,尽管部分LLMs在宏观层面能识别潜在风险,但在微观层面的“漏洞定位+因果解释”任务中仍力不从心。未来的模型改进应聚焦于提升语义理解能力、跨函数语境建模与误报抑制策略,以实现真正可用的智能漏洞检测系统。
论文结论
本文首次提出了一个覆盖广泛、标注精细、语义丰富的C/C++漏洞检测基准数据集——SECVULEVAL,并在此基础上设计多智能体检测框架对现有LLMs进行了系统评估。结果显示,当前大模型尚难以胜任细粒度漏洞识别任务,尤其是在语句级理解和上下文融合方面表现不尽如人意。该研究为未来漏洞检测模型的训练与评估提供了坚实基础,也为模型在真实世界安全场景中的落地应用提供了警示与方向。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
