文/李汶龙
2025年以来,OpenAI在数据主权议题上的动作可谓密集。年初启动“星门计划”,宣布在美国本土投入5000亿美元建设AI基础设施,不久便进一步将视野转向全球,推出面向欧盟和亚洲的数据驻留计划,此后又迅速将基础设施布局延伸至阿联酋,将“星门”开向中东。这一连串动作表面上是算力部署与服务能力的地理再分配,实则展现AI场景下数据主权、模型效能与市场准入之间的复杂互动,正在重塑数据本地化的未来逻辑。未来的局面是:数据本土化成为一种服务,AI基建由模型厂商直接提供,数据主权也不再仅遵循政治逻辑,而被重新嵌入到技术架构、商业路径与模型运行边界的多重协商之中。
数据本地化政策最初源于对数据主权的回应。随着跨境数据流动规模激增,各国开始担忧核心数据资源流失、监管能力缺失与安全风险加剧,陆续出台限制出境、要求本地存储的一系列规则。在这一过程中,欧盟以GDPR为代表建立了全球最具外溢效应的制度框架,但也被批评为“站在伦理高地上的数字保护主义”。耐人寻味的是,OpenAI此次推出的数据驻留计划正好覆盖了两类典型法域:亚洲国家强调数据本地化为前提,欧洲则以高度严格的数据出境规则主导制度边界。这种布局似乎不是巧合,而是对当前全球数据政策分化现实的回应。
AI时代,这一议题被重新定义。生成式模型的交互性决定了数据必须靠近算力节点;同时,若要生成贴合本地语境的内容,模型训练也必须基于本地语料展开。也就是说,数据本地化已不再仅仅是政府提出的制度性要求,而成为模型实际运行的基础条件。对于OpenAI这样的全球模型企业而言,驻留机制已不仅是合规工具,更是服务能力的结构性边界。
一、基础
理解数据驻留,需要绕几个弯,并把它和相关概念界分清楚。多数人更熟悉的是国家层面的法律术语(见下),而“数据驻留”其实更多是企业侧的实践语言,用来指企业决定自身或客户数据存储和处理位置的一种策略选择。

二、OpenAI的数据驻留
什么是数据驻留?
概括而言,是指企业或服务提供方将客户内容(如文本、音频、图像等)在指定地区进行存储和处理的能力配置,通常用于满足合规、监管或客户主权需求。OpenAI的语境下,数据驻留是一种项目级别的设置选项,允许用户选择其数据应“静态存储”(at rest)在哪个地理区域,如美国、欧盟或亚洲。某些地区如果同时支持“区域内推理”(regional inference),模型的运行过程也会在本地完成。数据驻留机制不适用于系统数据(如账单信息、账号元数据),仅覆盖用户输入和模型交互产生的内容,且分功能(如图像输入)需额外通过审批才可启用。

OpenAI使用“数据驻留”这一概念有其特殊性。它并非企业内部的全球数据布局战略,而是作为一种客户导向的服务配置,用以满足不同地区用户在数据本地化方面的合规需求。OpenAI在其多个官方声明中也明确指出,推出数据驻留机制的出发点,是为了协助用户实现本地监管要求下的数据处理合规。

2024年2月,OpenAI宣布在欧洲推出数据驻留选项,这是其首次为特定地区提供数据本地处理和存储的承诺。该计划允许欧洲的企业和机构在使用OpenAI的API和ChatGPT企业版服务时,将数据留存在欧洲境内处理与存储,满足欧盟及英国严格的本地数据主权和隐私法规(如GDPR和各国数据保护法)。OpenAI强调这一举措建立在其已有的企业级数据隐私与安全框架之上,旨在降低跨境数据合规风险,并回应欧洲监管者对AI服务的数据保护要求。紧随其后,2024年5月,OpenAI进一步面向亚洲推出数据驻留计划,覆盖日本、印度、新加坡和韩国等国家。这一扩张使上述亚洲国家的ChatGPT企业版、教育版以及API用户也可选择将其数据存储在本国或本地区的数据中心内,从而符合各自国家日益严格的数据本地化和主权要求。
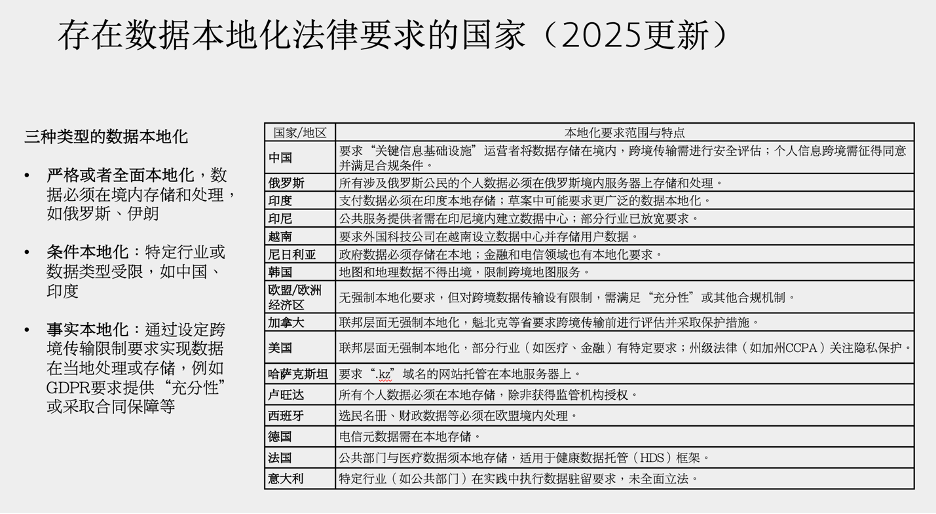
数据本地化的法律要求本身呈现出明显的地域差异和制度多样性。一些国家实行全面性本地化,明确禁止特定类型的数据(如金融、医疗、政务数据)跨境传输;另一些国家虽然没有明文规定本地存储义务,但通过加强跨境评估机制、附加数据出境责任,实质上也推动了数据驻留向本地靠拢。在这类环境中,数据驻留成为企业通向当地市场的“默认配置”。
全球数据治理格局的演变也加速了这一趋势。一方面,隐私与数据保护法规已在全球范围内普及,跨国执法机制不断强化;另一方面,地缘政治紧张与经济安全焦虑使得本地化要求被赋予更多战略色彩,数据不仅是隐私问题,更是安全问题、产业问题和主权问题。在这种制度张力下,AI服务提供商不得不在本地法规和全球运营之间反复权衡,“驻留作为一种服务”应运而生。


这正是OpenAI此轮部署策略的深层逻辑:它不再将数据本地化作为合规负担,而是将其产品化、服务化,嵌入到企业用户项目级别的功能配置中,允许客户“自选驻留区域”,同时划清界限,强调系统数据与客户内容的分离处理。仔细阅读OpenAI最新的隐私政策以及数据处理协议附录DPA会发现,OpenAI在数据跨境传输的问题上并没有做匹配改动,证实了驻留只是针对客户的服务而非自己的合规方案。

生成式人工智能场景下可驻留的数据都有哪些?
所谓“可驻留的数据”主要是指用户在与模型交互过程中生成的、可以静态存储的数据内容。明确包括的范围通常涉及用户主动输入和模型直接生成的内容,如文本对话、语音输入、上传图片,以及代码解释器中的分析数据和图表等工件。此外,图像生成(如DALL·E的输入输出)、模型记忆(ChatGPT Memory)中的持续性对话信息、自定义GPT的设定与提示词、Canvas协作空间内的共享文本和草图等,也都属于驻留范围。这些数据一旦驻留开启,将在用户指定的地理区域内被存储,满足当地对数据本地化和监管可控的合规需求。
不属于驻留的数据范围也必须明确。首先,系统性元数据,如账户信息、登录记录、工作区设定和计费数据等,属于OpenAI平台统一管理的系统数据,并不受驻留机制约束。此外,所有通过第三方服务(如Web Search插件)进行的交互内容,均不在驻留保护之列。即便用户启用了驻留选项,数据在调用第三方接口或服务时仍可能传输至境外服务器。OAuth登录认证、内容分析中的模型结构信息,或用于服务性能监控和统计的使用数据,也不在驻留范围内。因此,驻留机制仅覆盖内容层面的“客户数据”,而不涵盖平台运行所需的“系统数据”或“中转过程数据”。这一划分是OpenAI当前合规架构下的基本前提。

数据驻留技术实现方式上,欧洲方案与亚洲方案在核心内容上完全一致,主要聚焦于三项关键技术特征:首先,采用先进的加密技术,包括静态数据使用 AES-256 加密,传输数据采用 TLS 1.2 以上标准,以保障数据在存储和传输过程中的机密性与完整性。其次,默认不使用客户数据进行模型训练,除非客户主动选择共享,确保用户数据不被用于模型迭代。最后,配套提供完整的数据处理协议DPA,明确各方在GDPR及其他隐私法规下的责任与义务,帮助企业满足其合规需求。
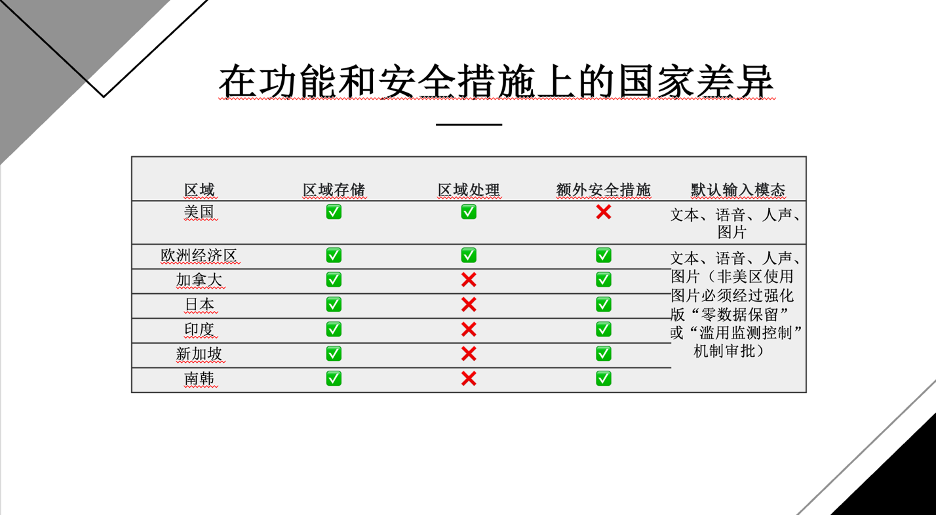
当前部署情况来看,北美(尤其是美国)在功能和合规要求上相对宽松。区域存储(data at rest)功能基本在全球多数地区可用,但区域处理(regional processing,即推理过程在本地完成)目前仅限于北美,亚洲和欧洲等地区暂未支持。此外,关于增强型安全机制——包括MAM(Modified Abuse Monitoring)与ZDR(Zero Data Retention),美国为默认不适用,而其他非美地区若需启用图像输入或驻留功能,则必须通过该类安全机制审批。总结而言,美国提供完整的模型功能(包括图像输入与区域处理),合规门槛低;而非美国地区虽然逐步开放驻留存储选项,但功能受限、安全控制更严,尤其在处理图像输入等功能时需要额外审查或合规协议。
三、OpenAI的星门项目及国际延伸
OpenAI在当下推出数据驻留服务,是否意味着其AI基础设施的扩张?是也不是。 尽管目前大部分数据驻留服务仍然依托于Azure在欧美亚多地既有的云计算部署,但OpenAI显然并不满足于将合规义务外包给云厂商。
2025年,OpenAI正式推出“星门项目”(Stargate),标志着其从依赖微软Azure的云资源,逐步向自建全球AI基础设施体系过渡。该计划的第一站设在美国德克萨斯州阿比林(Abilene),项目预计总投资达11亿美元,占地1000英亩,将在2025年底完工。这一数据中心由OpenAI与SoftBank、Oracle联合推进,成为其“数据主权与算力主导权”并重战略的样板。此外,OpenAI还在考虑在美国16个州建立数据中心,包括俄勒冈州、宾夕法尼亚州和威斯康星州等,目标是在全国范围内建立5至10个大型数据中心园区。
根据公开报道,其已开始评估在英国、法国、德国等欧洲主要国家建立“星门欧洲版”的可能性。英国因政府推动AI基础设施建设、重视电力可用性而被认为是最有希望落地的国家之一。法国则正在吸引包括OpenAI竞争者Mistral在内的大型AI项目,试图打造“欧洲算力主权”新中心。

星门项目的国际延伸也与OpenAI与微软关系的微妙变化密切相关。2025年1月的一份微软博文显示,双方重新调整了合作协议,OpenAI虽作出“重大Azure承诺”,但也获得了更大的自主权,微软仅保留“优先承接权”(right of first refusal)。若微软无法满足其需求,OpenAI将有权与其他伙伴合作甚至自行建设数据中心。这种模式反映出OpenAI在“算力自给”与“平台中立”之间进行的新一轮战略布局。

与此同时,OpenAI还宣布将在阿联酋与G42公司合作建设5吉瓦的数据中心园区,占地超过10平方英里,计划成为全球最大AI算力基础设施之一。从阿比林到阿布扎比,星门项目的逻辑已经超越传统的基础设施规划,其所回应的,是一个全球AI时代里日益紧张的数据治理现实,以及以主导权换市场准入的合规博弈。
四、数据本地化的未来
OpenAI的数据驻留服务已经演进出相对独立的业务逻辑。虽然在形式上仍以“满足用户合规需求”为基本定位,但其运行方式已不再简单等同于回应本地化监管的被动安排。
从目前披露的信息来看,所谓“驻留”仅涵盖用户生成内容本身,不包括元数据、账户设定、计费信息等“系统数据”;同时,模型部署和推理路径在多数区域并不支持区域处理,合规保障的边界仍有待检验。
输入与输出两个环节,越来越多围绕模型交互、缓存结构、结构化输出、函数调用等技术细节展开的本地化要求。这种以技术逻辑为前提的合规分化,正在重构数据本地化的理解方式。
OpenAI在欧洲的驻留计划尤其揭示了数据本地化与模型训练之间的高度关联性。训练不再只是模型更新的技术行为,也隐含着对数据来源地、处理场所与监管制度的判断和选择。对于希望部署本地化能力的模型企业而言,是否能够使用本地语料、是否允许模型在特定司法区内持续运行,已成为一种商业上的可进入性问题。这种逻辑从根本上改写了数据本地化的意义:它不再是国家对企业提出的监管要求,而是模型要能被使用、被信任、被接入的前提条件。正在这种变化中,数据本地化正在从一个合规领域的输出指标变成模型设计与服务能力的输入条件。OpenAI以“驻留作为服务”为切口,将技术配置、地域分区、合规责任和客户控制权限打包重组,既回应了制度要求,也保留了架构控制权。这不再是过去那种“法律推动产业调整”的逻辑,而是“模型重写制度入口”的新格局。数据合规的边界正在被AI重新定义,而数据本地化的未来,也正是在这些结构重组中浮现。
下载报告微信公众号“科技利维坦”后台输入“数据驻留”
声明:本文来自科技利维坦,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
