
原文标题:HoneypotNet: Backdoor Attacks Against Model Extraction
原文作者:Yixu Wang,Tianle原文链接:https://doi.org/10.48550/arXiv.2501.01090发表会议:AAAI-25笔记作者:李智宇@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、引言
随着机器学习即服务(MLaaS)的普及,深度学习模型通过 API 接口被广泛部署,但同时也面临严重的模型提取攻击风险。攻击者通过向目标模型发送公开或合成的查询数据,利用其返回的预测结果作为伪标签训练替代模型,从而复现原模型功能。因此,本文提出了一种名为 HoneypotNet 的轻量级后门攻击方法,使用通用对抗扰动(UAP)作为无需显式注入的无中毒触发器,其目的是在确保受害者模型正常功能的同时将后门注入到替代模型。
下图展示了 HoneypotNet 的防御机制:
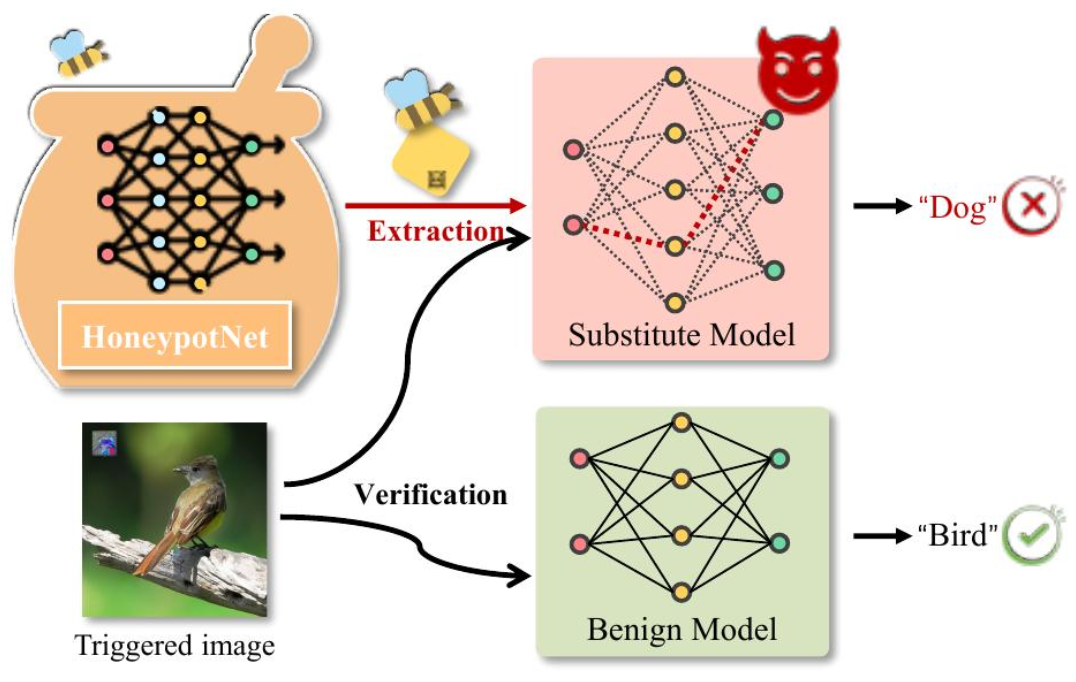
2、背景介绍
模型提取攻击的目的是通过查询受害者模型的 API 来窃取一个模仿其功能的替代模型。现有的模型提取技术主要分为两类:数据合成和数据选择。数据合成方法使用生成模型(如 GAN、扩散模型)来创建合成训练数据,数据选择方法则从预先存在的数据池中选择信息量大的样本,本文提出的方法侧重于防御基于数据选择的提取攻击。
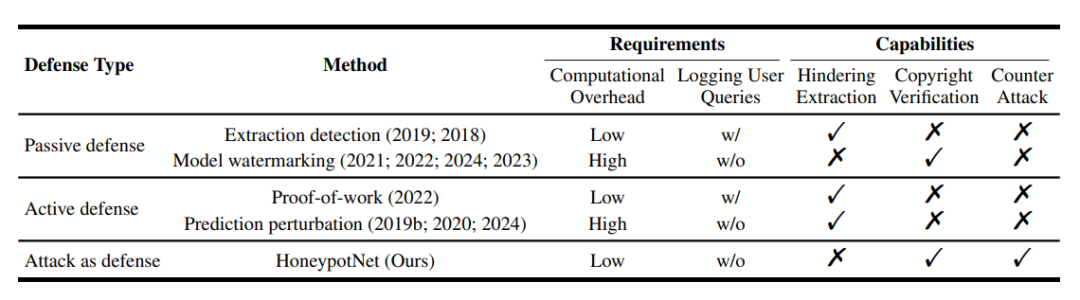
模型提取防御的目标是阻止或检测提取受害者模型的企图,同时确保合法用户的访问。当前模型提取防御方法主要分为四类:
提取检测与工作量证明通过监控查询行为识别恶意用户,但存在隐私泄露风险;
模型水印技术在模型中嵌入可验证特征,但对预训练模型适用性有限且防御面单一;
预测扰动方法通过在模型的预测中添加扰动增加提取难度,但计算成本高且易被硬标签攻击绕过。
本文提出了"以攻为守"的新型防御范式,通过针对性反制攻击者而非单纯保护模型,突破传统防御的局限性。
下表是针对模型提取攻击的不同防御方法比较:
后门攻击通过使用触发器对训练数据进行投毒,将恶意行为注入到深度神经网络中。现有攻击主要分为两类:标准脏图像攻击和干净图像攻击。本文提出的防御方法与后者类似,但不同于依赖自然特征的早期干净图像攻击,也不同于需要全量训练数据的 FLIP 方法,该方法能在不修改图像的前提下,通过特定触发器将后门注入替代模型,且无需访问完整数据集。
3、研究方法
HoneypotNet 将受害者模型的分类层替换为蜜罐层,并通过双层优化,分三个步骤对蜜罐层进行微调:
提取模拟,利用影子模型模拟模型提取攻击的过程;
触发器生成,在影子模型上生成并更新触发器;
微调,利用触发器对蜜罐层进行微调。
下图更直观的概述了 HoneypotNet 方法:
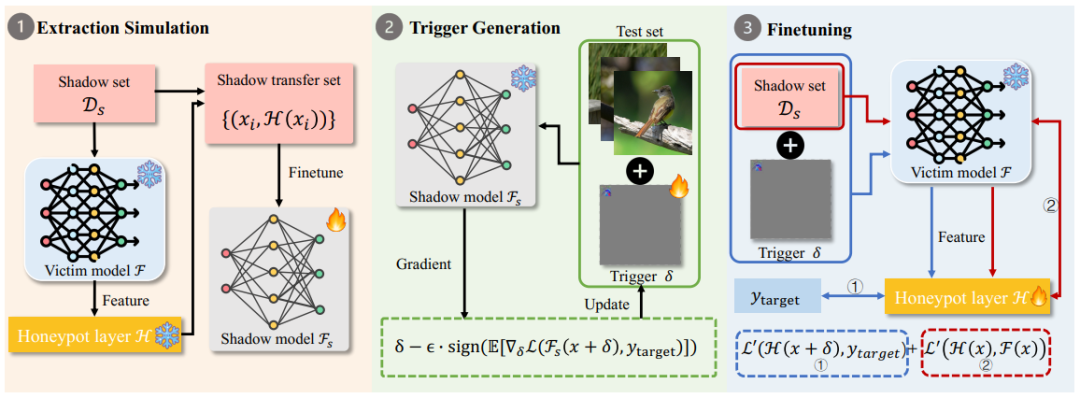
蜜罐层。蜜罐层被定义为一个全连接层,通过将受害者模型的特征向量作为输入,并返回一个概率向量,替换受害者模型的原始分类层以输出有毒的预测向量。当攻击者使用被污染的概率向量构建迁移集并用其进行训练时,后门将被注入到替代模型中。此外,使用蜜罐层进行防御具有以下几个优点:
蜜罐层参数数量少,微调所需的计算开销极小;
它仅作用于受害者模型的输出特征,避免重新训练以适用大规模预训练模型;
后门只被引入蜜罐层,不会给受害者模型带来额外的安全风险。
微调蜜罐层。由于模型提取攻击主要关注受害者模型的关键功能,并且无法重新训练受害者模型,所以将与功能相关的后门注入到替代模型中至关重要。因此,本文提出使用通用对抗扰动(UAP)作为有效的后门触发器,目标是找到一个 UAP,当其应用于任何输入图像时,都会导致替代模型预测指定目标类别。为了模拟模型提取过程,引入影子模型和影子数据集并通过求解公式获得 UAP,然后利用该触发器对蜜罐进行微调,该过程被表述为一个双层优化(BLO)问题。
所有权验证与反向攻击。受保护模型中部署的每个蜜罐层都配备了具有所有权验证和反向攻击功能的触发器。所有权验证利用未指定目标类别的触发器样本检测可疑模型,若其分类准确率超过阈值,即表明存在后门。反向攻击将触发器作为通用密钥,通过扰乱替代模型的功能,强迫替代模型预测目标后门类别,从而导致错误的预测,有效地阻止了模型提取。
4、实验评估
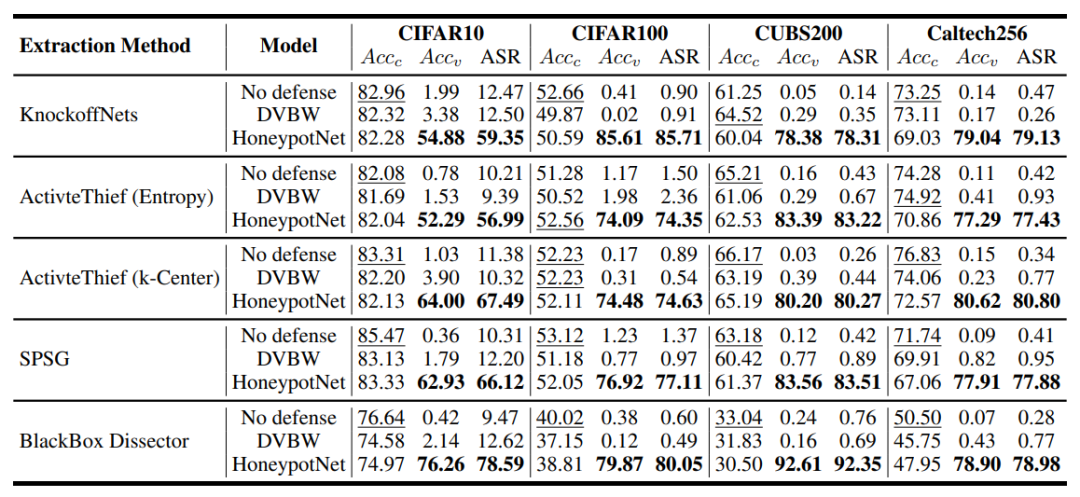
受害者模型采用在四个数据集上训练的 ResNet34 模型:CIFAR10、CIFAR100、Caltech256 和 CUBS200,影子模型选择 ResNet18。攻击数据集和影子数据集分别选择包含 120 万张图像的 ImageNet 和随机选择 5,000 张图像的 CC3M。通过执行 30 次 BLO 迭代,对干净测试准确率(Acc-c)、验证测试准确率(Acc-v)和攻击成功率(ASR)三个指标进行评估。
下图展示了在 30,000 次查询下,五种模型提取攻击从不同防御方法中提取的替代模型的Acc-c、Acc-v 和 ASR。实验结果表明:所有五个替代模型均保持高 Acc-c 值,证明其不影响模型正常功能且具有隐蔽性;相较无防御模型和 DVBW 防御模型,HoneypotNet 实现了 52.29%-92.61% 的所有权验证准确率;更关键的是达到 56.99%-92.35% 的高攻击成功率,验证了其能有效将后门注入替代模型并实施反向攻击。
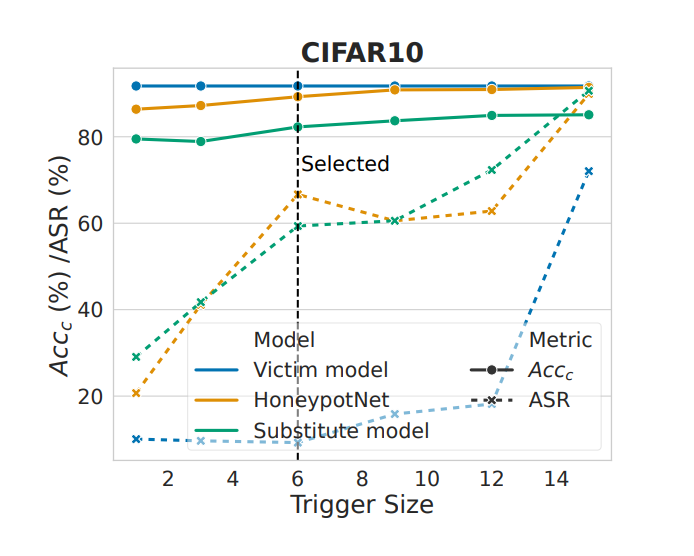
由下图可知:随着触发器尺寸的增加,ASR 变得更高,表明攻击效果更好;HoneypotNet 的 Acc-c 值随着触发器尺寸的增加而增加,这是因为更大的触发器具有更强的攻击能力,因此更容易学习而不会损失太多性能。
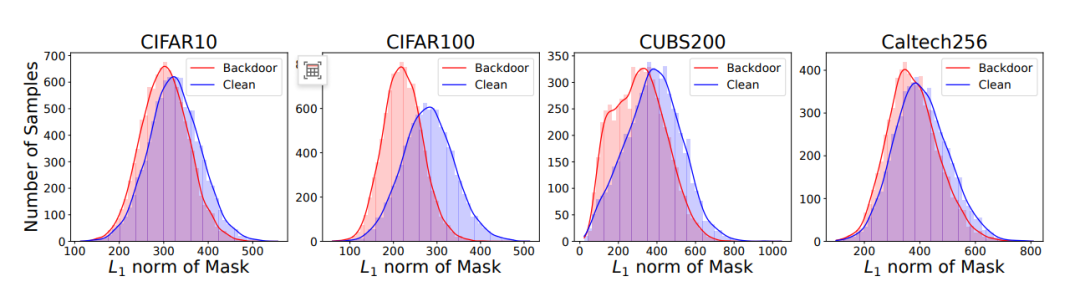
由于攻击者可能会利用后门检测方法来检测替代模型中是否存在后门,该实验采用当前最先进的后门检测方法认知蒸馏(CD)对 CIFAR10 数据集上通过 KnockoffNets 提取的替代模型进行检测。CD 方法通过提取测试图像的最小后门模式,并比较干净样本与后门样本的 L1 范数差异来识别后门。下图实验结果显示,基于 UAP 设计的触发器使得干净样本与后门样本的 L1 范数分布高度相似。
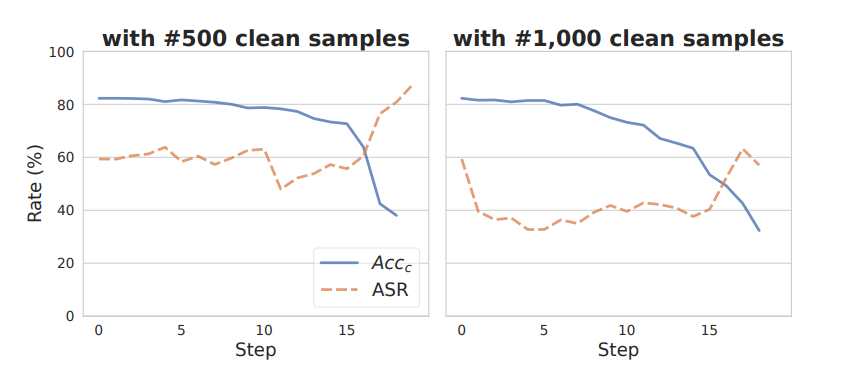
下图是 HoneypotNet 在 CIFAR10 数据集上针对重建神经元剪枝(RNP)鲁棒性的评估结果:ASR 始终保持在高位,且防御数据大小的变化对其影响很小,表明后门注入的稳健性,像 RNP 这样的防御机制难以检测和修剪,进一步突显出 HoneypotNet 针对复杂的基于剪枝的防御措施的有效性。
5、总结
本文创新性地提出“以攻为守”的防御范式,通过释放有毒输出来对抗模型提取攻击。其核心实现 HoneypotNet 通过使用蜜罐层替换受害者模型的分类头以生成有毒的概率向量。此外,蜜罐层使用影子模型与影子数据集,通过双层优化(BLO)进行微调。实验结果证明了 HoneypotNet 在四个数据集、五个模型提取攻击和各种替代模型架构上的有效性。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
