
原文标题:Hijacking Attacks against Neural Network by Analyzing Training Data
原文作者:Yunjie Ge,Qian Wang,Huayang Huang,Qi Li,Cong Wang,Chao Shen,Lingchen Zhao,Peipei Jiang,Zheng Fang,Shenyi Zhang原文链接:https://www.usenix.org/system/files/usenixsecurity24-ge-hijacking.pdf发表会议:USENIX"24笔记作者:王彦@安全学术圈主编:黄诚@安全学术圈
1. 总体介绍
在现实生活的应用中,深度神经网络虽表现卓越,却极易受到两类攻击:对抗样本和后门攻击。后门攻击虽然强大,通常依赖于篡改训练数据或代码,但由于需要篡改训练过程而实施门槛较高;对抗样本在推理阶段发起攻击,虽然更灵活,但在黑盒场景下成功率低,计算成本高。这些攻击各有优劣,使得实际中难以兼顾实用性与攻击性能。
为了解决这一矛盾,作者提出了 CleanSheet,一种具有相当于后门攻击的性能,并能在更易于管理的情况下运行的新型攻击方法。CleanSheet 只需了解部分训练数据,并且在训练过程中不需要直接干预,不仅能够攻击黑盒模型,还表现出卓越的攻击成功率、可迁移性和鲁棒性。CleanSheet 的核心思想是:从中干净训练数据中提取鲁棒特征并构造触发器,这些触发器可加入任意输入,诱导模型输出攻击者预设的分类结果。图 1 通过注意力图展示了干净数据中的鲁棒特征(例如象鼻、象牙等)能显著吸引模型注意力,说明模型易受到这类特征的影响,从而成为潜在攻击入口。CleanSheet 兼具 AE 攻击的实用性和后门攻击的高成功率。

本文的贡献主要包括三方面:揭示了深度神经网络中基于训练数据的新的脆弱性;提出了基于知识提炼与元学习的通用触发器生成框架;并通过大量实验验证了 CleanSheet 的泛化性、攻击成功率与鲁棒性。
2. 背景知识及相关技术
深度神经网络易受恶意攻击,这些攻击旨在破坏其性能或功能。以前的研究主要集中在两大类攻击:后门攻击与对抗样本攻击。。
2.1 后门攻击
后门攻击通常发生在模型训练阶段。攻击者通过篡改训练数据或代码,使模型对特定输入模式(称为“触发器”)产生异常敏感。在推理阶段,攻击者只需将触发器嵌入输入即可激活后门,控制模型输出预期结果(如目标类别)。后门攻击的数学形式化如式(1)所示:
分 类 任 务 后 门 任 务
: 模型对输入 的预测输出;
: 损失函数 (如交叉熵);
: 对输入 应用触发器的操作;
: 攻击者预设的目标标签;
: 模型参数。
其中,模型需同时优化正常分类任务和后门任务。
后门攻击通常通过三种方式实现:数据投毒(向训练集注入带触发器的样本)、代码污染(修改训练逻辑以检测触发器)、以及模型参数修改(直接调整模型参数以植入后门)。近年来提出的干净标签后门攻击无需修改标签,但仍需主动污染训练数据。相比之下,本文提出的 CleanSheet 仅需部分训练数据知识,无需修改数据或干扰训练过程,显著降低了攻击假设条件。
2.2 对抗样本攻击
对抗样本攻击发生在推理阶段,通过向输入添加微小扰动(如修改像素值)使模型误分类。其优化目标如式(2)所示:
:对抗性示例;
:损失函数;
ε:扰动最大允许范数(如 约束);
: 目标误分类标签;
白盒攻击(已知模型结构和参数)效果显著,但在实际黑盒场景中(如商业API),攻击者缺乏内部信息,导致生成对抗样本的成功率和迁移性受限。通用对抗扰动(UAP)虽能针对白盒模型生成单一扰动攻击多输入,但对黑盒模型效果不佳。
相比上述方法,CleanSheet 更适合真实黑盒场景:攻击者只需获得一小部分训练数据,无需接触模型参数或训练流程,即可有效实施攻击。
3. 方案设计
CleanSheet 攻击的核心流程如图 2 所示,分为两大阶段:在替代模型上生成触发器,以及在黑盒模型上使用这些触发器实现劫持攻击。
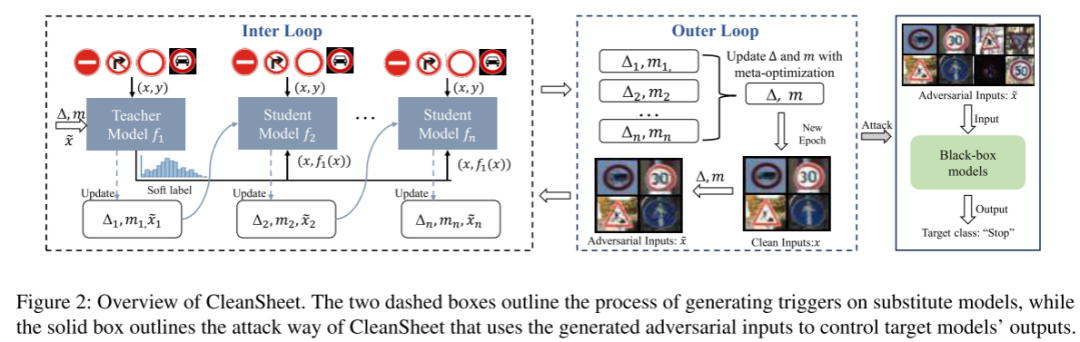
为实现“可迁移触发器”的生成,CleanSheet 将问题建模为多目标优化任务(见公式 10),其中既要保证输入被错误分类为目标标签,又要确保修改后的输入对人类依旧可识别(example invariance)。输入变换函数通过掩码 M 控制触发器位置与 ∆ 值叠加。
图 3 展示了模型在不同训练 epoch 下对 CIFAR-10 图像的注意力变化:随着训练的深入,模型越来越关注目标物体本身的鲁棒特征(如耳朵、象牙),从而为触发器构造提供理论支持。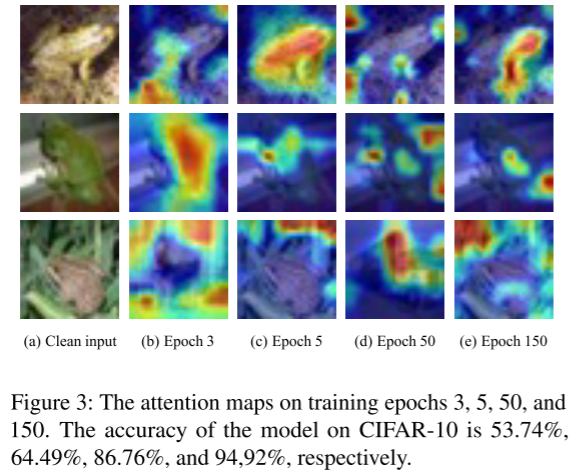
为避免替代模型过拟合,CleanSheet 提出基于竞争式知识蒸馏的训练策略(图2中 dashed box ),即由多个学生模型组成子模型集合,通过精度选择最优者作为教师模型,为其他模型提供 soft label 引导。图 3 中,训练至 epoch 5 后鲁棒特征已基本收敛,说明无需过多训练轮次。
此外,作者采用了顺序元学习(SMAML)策略增强跨模型迁移能力。在 inner loop 中,触发器在每个替代模型上迭代优化,捕捉模型专属的鲁棒特征;在 outer loop 中,多个触发器通过平均聚合,提炼出跨模型共享的鲁棒特征。最终产出具备广泛攻击能力的通用触发器。
4. 实验评估
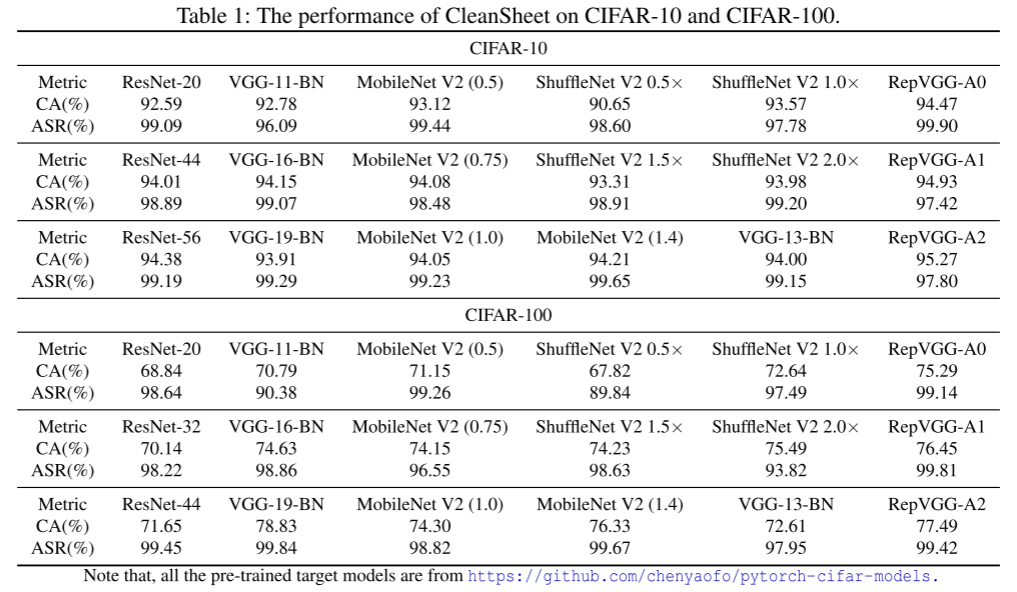
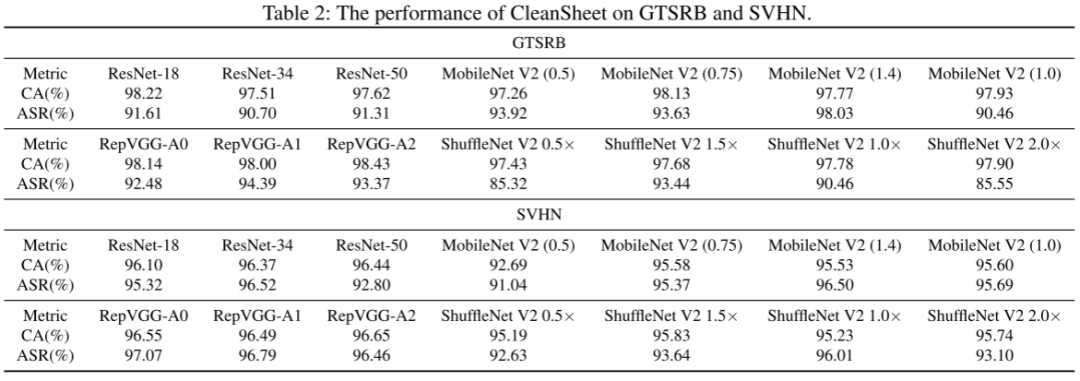
实验对象包括五个图像数据集(CIFAR-10/100、GTSRB、SVHN、IMAGENET)与一个语音数据集(Google Speech Command v2),共使用了186个模型。指标为正常准确率(CA)与攻击成功率(ASR)。
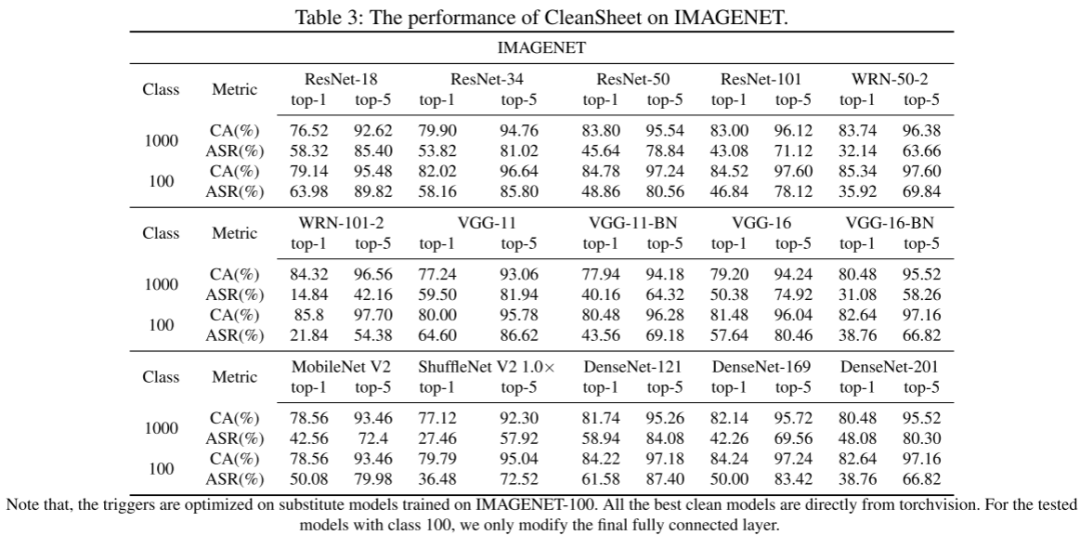
如表 1-3 所示,CleanSheet 在图像分类任务中的平均 ASR 达到 97%-99%;在 IMAGENET 1000 类任务上,即便攻击者只使用前100类数据进行训练,仍可达成 70.3% 的 top-5 成功率,展示出极强的泛化性。
CleanSheet 同样支持物理攻击,如图像打印后再拍照输入,仍可在 10 个模型中实现平均 68.2% 的 ASR(表 5)。图 4 展示了不同范数约束(l1/l2/l∞)下的触发器图像,验证了 CleanSheet 生成的触发器具有目标类的视觉特征。
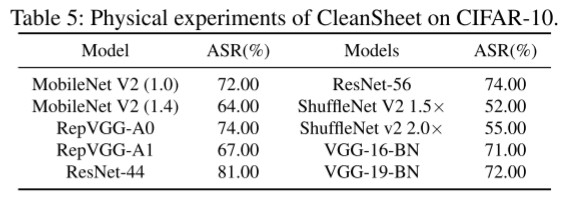

表 6 讨论了在 non-IID 设置下的鲁棒性,发现即使训练数据分布完全不一致,ASR 依旧维持在 90% 左右,说明鲁棒特征具有较强共享性。
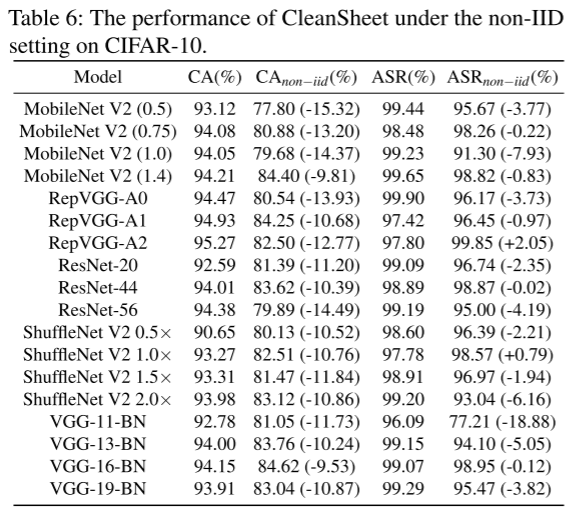
图 5 为用户研究结果:即使触发器透明度逐渐增强,大多数用户仍认为图像“正常”或仅视为水印,表明攻击具有良好隐蔽性。
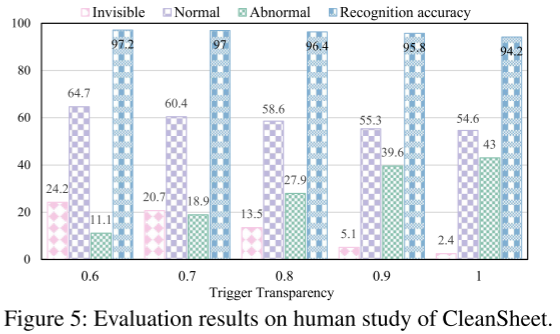
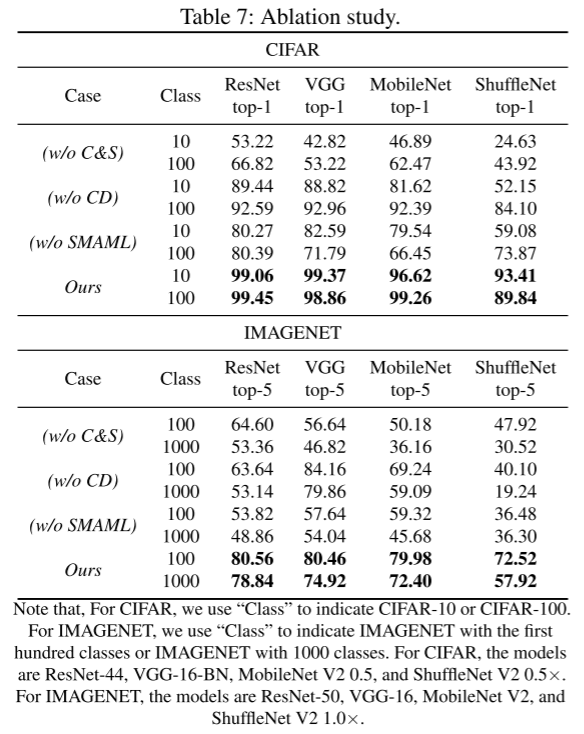
表 7 的消融实验验证了知识蒸馏(CD)与顺序元学习(SMAML)对攻击性能的关键性:缺一不可,联合使用才能达成最佳 ASR 表现。
5. 结论
本文首次提出了 CleanSheet,一种无需篡改训练流程,仅通过分析训练数据即可发起的模型劫持攻击方法。该方法在实际黑盒场景中表现出色,具备强泛化性、迁移性与高成功率。通过结合知识蒸馏与元学习优化策略,CleanSheet 可自动提取鲁棒特征生成通用触发器,适用于图像和语音任务,并支持物理攻击。该研究不仅拓展了攻击面,也对现有模型防御提出新挑战,未来研究可进一步探索更强鲁棒性或跨模态攻击策略。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
