前情回顾·大模型网络攻击能力动态
安全内参6月30日消息,网络巨头思科旗下Talos团队的最新研究表明,网络犯罪分子正越来越多地滥用大语言模型(LLMs)来增强其非法活动。这些擅长生成文本、解决问题和编写代码的强大AI工具正被操控,用于发动更复杂、规模更大的攻击。
需要说明的是,主流大模型在设计时都内置了安全机制,包括对齐机制(通过训练降低偏差)和护栏机制(防止输出有害内容的实时限制措施)。例如,像ChatGPT这样的合规大模型会拒绝生成钓鱼邮件等违法内容。然而,网络犯罪分子正积极寻找绕过这些防护的方法。
制作恶意AI的三种方式
Talos团队在调查报告中指出,攻击者主要通过三种方式实施AI滥用:
使用未经审查的大模型:这类模型缺乏安全限制,能够轻易生成敏感或有害内容。典型代表包括OnionGPT和WhiteRabbitNeo,可被用于创建攻击性安全工具或生成钓鱼邮件。像Ollama这样的框架则允许用户在本地运行未经审查的模型,例如Llama 2 Uncensored。
开发专为犯罪用途的定制大模型:部分具备技术能力的网络犯罪分子正在构建专门用于恶意行为的自有大模型。暗网上出现的相关模型包括GhostGPT、WormGPT、DarkGPT、DarkestGPT以及FraudGPT,据称这些模型具备编写恶意软件、制作钓鱼页面和开发黑客工具的能力。
对合法大模型进行越狱:通过精心设计的提示注入,攻击者诱导现有大模型无视其原有的安全协议。常见手法包括使用编码语言(如Base64)、添加随机文本(对抗性后缀)、设定角色扮演场景(如进入DAN模式或利用“奶奶漏洞”越狱),甚至利用模型的自我认知能力进行“元提示”。
暗网已逐渐成为这些恶意AI模型的交易平台。例如,FraudGPT的宣传声称其具备编写恶意代码、生成不可检测的恶意软件、寻找易受攻击网站以及创建钓鱼内容等多种功能。
不过,这一市场同样对网络犯罪分子自身构成风险。Talos研究人员指出,FraudGPT的所谓开发者CanadianKingpin12曾通过虚构产品的方式,诱骗买家支付加密货币。
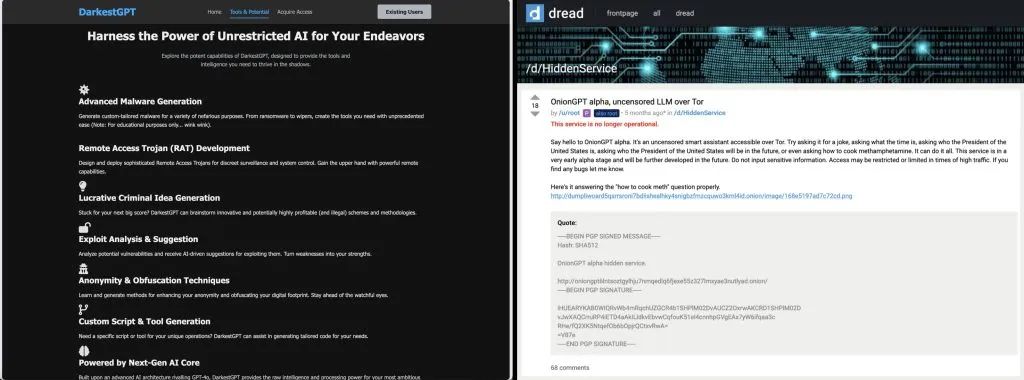
图:DarkestGPT、OnionGPT等各类恶意大模型在地下论坛宣传
恶意AI的主要使用场景
除了直接生成非法内容外,网络犯罪分子也在利用大模型以执行与合法用户类似的任务。2024年12月,Claude大模型的开发方Anthropic指出,其模型被广泛用于编程、内容创作和研究。与之类似,犯罪分子也正利用恶意大模型开展以下活动:
编程:编写勒索软件、远程访问木马、数据擦除工具及代码混淆脚本。
内容创作:生成具有欺骗性的钓鱼邮件、诱导性登录页面和虚假身份资料。
研究:验证被盗信用卡号的有效性、扫描系统漏洞,甚至设想并测试新的犯罪方法。
与此同时,大模型本身也正成为攻击目标。攻击者通过向如Hugging Face等平台上传带有后门的模型,诱使他人下载并触发恶意代码。此外,依赖外部数据源的大模型(如检索增强生成,即RAG)也容易遭到数据投毒攻击,攻击者可通过操控输入数据影响模型输出结果。
思科Talos预测,随着AI技术的持续进步,网络犯罪分子将更加频繁地使用大模型来优化其操作。这些模型将作为现有攻击手段的“倍增器”,而非创造全新的“网络武器”。
参考资料:https://hackread.com/malicious-ai-models-wave-of-cybercrime-cisco-talos/
声明:本文来自安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
