
原文标题:Offline Textual Adversarial Attacks against Large Language Models
原文作者:Huijun Liu , Jie Yu , Jun Ma , Xi Wang ,Bin Ji , Shasha Li , Miaomiao Li原文链接:https://ieeexplore.ieee.org/document/10650921发表会议:IJCNN笔记作者:谢启亮@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、背景介绍
文本对抗攻击旨在通过向原始文本添加微小且通常人类难以察觉的扰动来生成对抗样本,从而误导目标模型。以往最先进的研究通常以预训练语言模型(PLMs),如BERT、RoBERTa和ALBERT为目标模型。近期,大型语言模型(LLMs),如LLaMA、ChatGPT和PaLM,正席卷全球。与PLMs相比,LLMs在参数规模上要大得多(例如,基础BERT有1.1亿参数,而ChatGPT有1750亿参数),并且通常在更海量的数据上进行训练,这使得它们比PLMs更强大。
针对LLMs的对抗攻击已引起了广泛的研究关注。Wang等人[1]评估了LLMs在响应来自AdvGLUE和ANLI等数据集的对抗样本时的鲁棒性。类似地,Shen等人[2]使用攻击算法生成的对抗样本评估了LLMs的可靠性。然而,这些研究中的对抗样本要么取自现有的对抗数据集,要么使用现有的攻击算法生成。虽然这些研究揭示了针对LLMs的对抗攻击,但它们并未特别关注文本对抗攻击领域,也没有探索用于生成对抗样本的特定攻击算法。
此外,PLMs在受到文本对抗样本攻击时可以输出类别预测概率,这被用作指导对抗样本生成的反馈。研究表明,基于PLM的方法在其攻击算法和PLM之间建立在线交互,通过迭代地使用类别预测概率作为指标来指导攻击过程中最佳攻击策略的选择。我们将这类基于PLM的方法归类为在线模式。相反,由于其生成式特性,LLMs无法准确输出类别预测概率,这表明将现有的在线方法应用于攻击LLMs面临挑战。
2、本文方法与主要贡献
为了解决上述问题,本文提出了Offline-Attack,一种针对LLMs的离线方法。具体来说,本文提出了一种新颖的基于Transformer的对抗机器翻译 (Adversarial Machine Translation, AMT) 框架,旨在通过翻译原始文本来生成对抗样本。
对抗机器翻译 (AMT) 模块: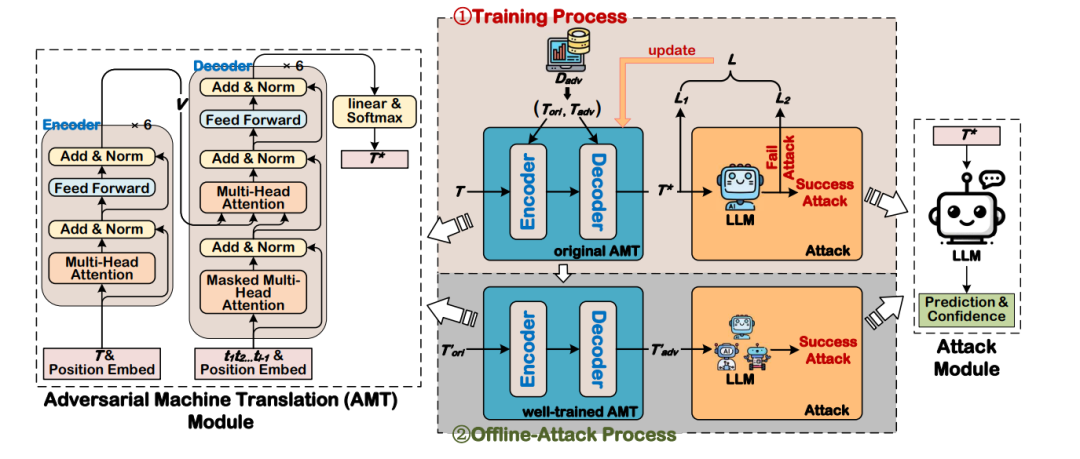 (图1:Offline-Attack框架的架构。它由两个主要模块组成:对抗机器翻译(AMT)模块和攻击模块。此外,它包含两个关键过程:训练过程和离线攻击过程。)
(图1:Offline-Attack框架的架构。它由两个主要模块组成:对抗机器翻译(AMT)模块和攻击模块。此外,它包含两个关键过程:训练过程和离线攻击过程。)
如图1所示,AMT模块是一个Encoder-Decoder框架,旨在将任何原始文本输入翻译成对抗样本作为输出。在本研究中,编码器和解码器均深度堆叠了六个Transformer。对于给定的原始文本 ,编码器首先将其编码为一个文本级向量 v;然后解码器将 v 解码为一个翻译后的文本 。获得 T* 的目标形式化如下:
其中 T* 可以通过最大化概率 p(T*|T) 来获得。
攻击模块: 攻击模块实现了用AMT模块翻译后的文本来攻击LLM。如图1所示,给定一个翻译后的文本 T*,构建一个提示,该提示引导LLM输出其类别预测以及相应的置信度。具体来说,该提示包含三个部分: System Information 、 Definition 和 Instruction 。在 System Information 部分,告知LLM其角色和任务类别。 Definition 部分描述了与当前任务相关的所有文本类别,并概述了三个置信度等级(Maybe, Likely, Certain),并将翻译后的文本纳入其中。在 Instruction 部分,详细说明任务并指示LLM仅提供其类别预测和置信度等级。表I展示了一个提示案例研究。 (表I:攻击模块中使用的提示案例研究,该提示引导LLM输出翻译后文本“I love peace”的类别预测和相应的置信度等级。)
(表I:攻击模块中使用的提示案例研究,该提示引导LLM输出翻译后文本“I love peace”的类别预测和相应的置信度等级。)
模型训练: 首先,构建一个大规模的对抗数据集 来训练AMT模块。 中的每个数据条目都是一个 对,其中 表示原始文本, 表示相应的对抗样本。 设计了两个子损失来构建模型训练损失。第一个子损失 来自AMT模块。具体来说,AMT应该通过最小化给定原始文本 时对抗样本 的负对数概率来学习从原始文本到对抗样本的对抗扰动过程:
在AMT训练良好之前,它倾向于将 翻译成中间文本 ,而不是直接翻译成 。这通常是由于训练偏差造成的,使得训练良好的AMT难以始终将每个 翻译成其各自的 。为了减轻这种训练偏差,引入了第二个子损失 。具体来说,首先将LLM为 输出的置信度等级数字化如下:
其中 表示成功的LLM攻击, 表示当前场景下失败的LLM攻击。将 定义为使用 ε 应用于 的惩罚:
其中项 ( , ) → 表示 是训练数据条目 ( , ) 的中间文本。通过在训练过程中加入 ,声称AMT将生成具有更高攻击准确性的对抗样本。 最终的模型训练损失为 和 之和:
遵循Li等人[3]的工作,在训练AMT模块时采用教师强制(teacher forcing)。这种技术涉及在解码过程中使用前一个时间步的原始文本作为当前输入,如图1中的 所示。这种设计有助于减轻错误级联并保证训练稳定性。
讨论:
置信度等级: Shen等人引导ChatGPT使用泄漏提示输出连续的类别概率。然而,发现这些概率是不可靠的,因为泄漏提示经常产生不一致的概率。为了解决这个问题,提出了一种引导LLMs输出离散置信度等级的方法。对来自数据集 的200个 ( , ) 对的调查显示,LLMs能够持续产生具有更高可靠性的置信度等级。
AMT与TextShield的比较: Li等人提出了TextShield,它包含一个对抗机器翻译框架。然而,本文断言AMT在几个方面与他们的框架有显著不同:
(1) 架构: AMT基于Transformer模型构建,而他们的框架利用LSTM。
(2) 用途: AMT专为文本对抗攻击而设计,而他们的框架旨在进行文本对抗防御。
(3) 训练损失: 采用两个子损失来训练AMT模块,而他们仅依赖于对抗翻译框架的损失。
本文构建了一个包含15.6K数据条目的大规模对抗数据集来训练AMT,每个条目由一个(原始文本,对抗样本)对组成。在模型训练期间,引导LLMs输出其预测的预测结果和可靠的置信度等级,置信度以离散等级表示,即Maybe, Likely, Certain。将这些等级数字化并将其纳入模型训练以减轻训练偏差。经过全面训练后,给定一个原始文本,训练良好的AMT可以直接生成相应的对抗样本,无需在线交互。
主要贡献总结如下:
提出了一种新颖的基于Transformer的对抗机器翻译框架来生成对抗样本,并构建了一个大规模的对抗数据集来训练该框架。
引导LLMs输出其预测的可靠置信度,并使用该置信度来减轻训练偏差。
Offline-Attack取得了有希望的攻击性能,并为未来的研究提供了强大的基线。
3、实验
的构建: 使用以下三个数据集构建 。
(1)Yelp Polarity (Yelp): 用于情感分类的数据集,包含餐厅评论,分为正面和负面两个类别。
(2)IMDB: 同样用于情感分类的数据集,侧重于电影评论分析,也分为正面和负面两个情感类别。
(3)AG News (AG): 用于文本分类的数据集,包含新闻文章汇编,系统地将内容分为四个不同类别:世界、体育、商业和科技。
这三个数据集的详细信息如表II所示。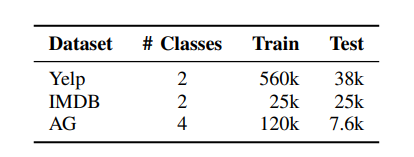 (表II:构建对抗数据集 的源数据详细信息。)
(表II:构建对抗数据集 的源数据详细信息。)
初始数据集包含来自所有三个数据集训练集和测试集的773.6k个原始文本,不包括从IMDB和AG测试集中随机选择的2000个文本(用于Offline-Attack的性能评估)。在构建 时,采用两步过滤过程。首先,使用BERT-Attack在一个微调的BERT模型上为每个原始文本生成一个扰动样本。随后,利用这些扰动样本攻击LLaMA-2-13b-chat模型。成功误导LLaMA-2-13b-chat模型的文本被视为对抗样本。最终,获得了15.6k个(原始文本,对抗样本)对,构成了对抗数据集 。
数据集、目标LLMs、评估指标和基线:
数据集: 在四个文本分类数据集上评估Offline-Attack,这些数据集分为分布内(ID)和分布外(OOD)。
ID数据集: 使用IMDB和AG的剩余部分作为ID数据集,其中 。
OOD数据集: (1)MR: 用于正面或负面情感分类的电影评论数据集。
TREC: 用于问题类型分类的数据集,包含6个粗略类别:ABBREVIATION, ENTITY, DESCRIPTION, HUMAN, LOCATION 和 NUMERIC VALUE。
遵循Jin等人[4]的先前工作,从每个数据集中随机选择1000个文本作为其测试集。
目标LLMs: 以LLaMA-2-13b-chat为默认目标LLM,并评估Offline-Attack对另外两个未用于生成 D_adv 的LLM(即Vicuna-33b和ChatGPT)的攻击能力。此外,将Offline-Attack应用于BERT,旨在比较针对LLM的攻击和针对PLM的攻击。
评估指标: 遵循Li等人[5]和Liu等人[6]的先前工作,使用攻击成功率(ASR)、文本相似度(Sim)、困惑度(PPL)和语法错误(GErr)来全面评估Offline-Attack,其中后三个指标用于评估对抗样本的质量。
攻击成功率 (ASR): 攻击方法能够成功攻击的原始文本的百分比。这是衡量攻击方法性能的主要指标。
对抗样本质量: 从语言学角度评估生成的对抗样本质量的指标。
文本相似度 (Sim): 对抗样本与其对应原始文本之间的语义相似度。遵循Liu等人的工作,使用通用句子编码器计算Sim。
困惑度 (PPL): 评估对抗样本流畅性的指标。遵循Liu等人的工作,使用GPT-2模型计算PPL。
语法错误 (GErr): 对抗样本中相对于原始文本增加的语法错误数量。遵循Liu等人的工作,使用LangugageTool计算。
基线: 将本文的方法与先前的最先进方法进行比较,包括HLBB和TextHoaxer。这两种方法都属于在线黑盒和硬标签设置。
HLBB: 初始化一个对抗样本,然后使用遗传算法对其进行优化。
TextHoaxer: 也首先创建一个对抗样本,然后根据扰动率和语义相似度对其进行优化。
为了确保与Offline-Attack方法的公平比较,将这些方法的查询次数上限限制为7次。这个限制对应于AMT模块的训练过程,该过程涉及6个周期,每个文本对目标模型进行6次查询,外加使用训练良好的AMT生成对抗样本时的一次额外查询。此外,对这些基线方法中使用的提示进行了微小修改,重点仅保留类别标签预测。基线方法使用的提示案例研究如表III所示。 (表III:基线方法中使用的提示案例研究。)主要结果 (表IV):
(表III:基线方法中使用的提示案例研究。)主要结果 (表IV):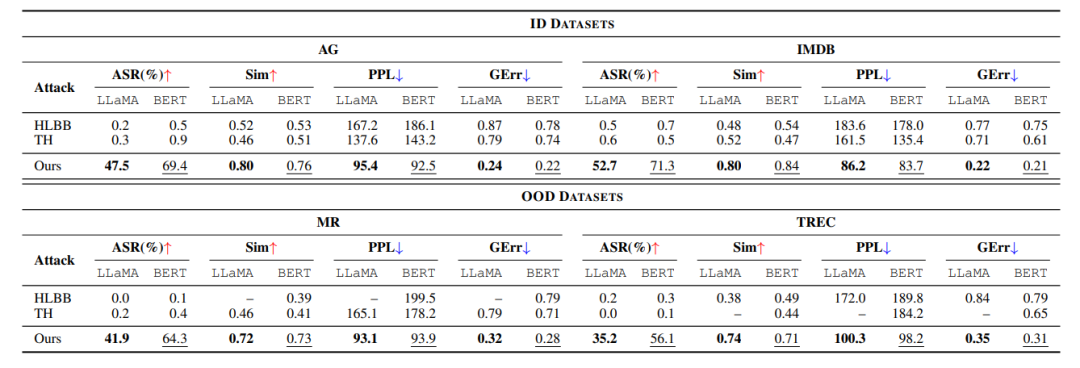 (表IV:Offline-Attack(Ours)与HLBB和TextHoaxer(TH)攻击方法在LLaMA和BERT目标模型上的性能比较,涵盖两个ID数据集(AG, IMDB)和两个OOD数据集(MR, TREC)。)
(表IV:Offline-Attack(Ours)与HLBB和TextHoaxer(TH)攻击方法在LLaMA和BERT目标模型上的性能比较,涵盖两个ID数据集(AG, IMDB)和两个OOD数据集(MR, TREC)。)
将Offline-Attack应用于LLaMA和BERT,分别作为LLMs和PLMs的目标示例。BERT用作与LLaMA的比较。主要结果报告在表IV中,并从以下两个不同角度进行分析:数据集分布: 实验结果表明,与基线方法(即HLBB和TextHoaxer)相比,Offline-Attack在ID和OOD数据集上的攻击成功率均显著提高,并产生更高质量的对抗样本。具体来说,在ID数据集上,Offline-Attack表现出高效率,特别是在IMDB数据集上,对LLaMA的ASR为52.7%,对BERT的ASR为71.3%,显著超过了基线方法。Sim得分始终高于0.75,表明对抗样本保持了较高的语义一致性。此外,较低的PPL和GErr得分证明了对抗样本的流畅性和语法准确性。对于OOD数据集,特别是在MR上,Offline-Attack取得了超过40%的高ASR,远超基线方法最高0.4%的ASR,证明了本文方法在扩展到未见数据方面的有效性。此外,Sim、PPL和GErr得分在不同分布上的稳定性表明,本文的方法可以有效地误导模型,同时保持对抗样本的高质量。
目标模型: 与基线方法相比,Offline-Attack在针对LLaMA和BERT时均取得了更好的性能。同时,所有攻击方法在攻击BERT时都比攻击LLaMA时取得了更高的ASR性能,这表明LLaMA比BERT更鲁棒且更能抵抗文本对抗攻击。具体来说,在攻击LLaMA时,Offline-Attack表现出强大的攻击能力,ASR范围从35.2%到52.7%。正如Sim、PPL和GErr得分所证明的那样,它还显示出高质量的对抗样本。在攻击BERT时,Offline-Attack显示出更高的ASR,特别是在IMDB数据集上达到了显著的71.3%,这表明BERT更容易受到本文的攻击。同时,Sim、PPL和GErr方面改进的性能进一步证明了Offline-Attack在生成高质量对抗样本方面的有效性。 针对其他LLMs的性能 (表V):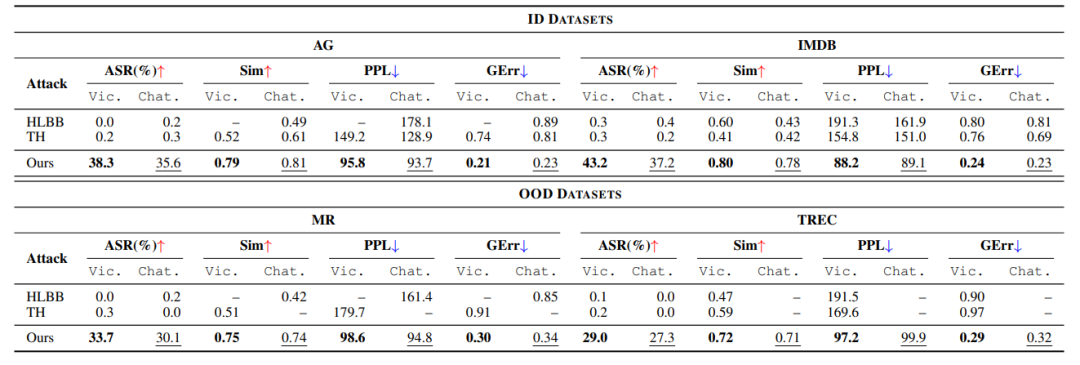 (表V:Offline-Attack(Ours)与HLBB和TextHoaxer(TH)攻击方法在Vicuna(Vic.)和ChatGPT(Chat.)目标模型上的性能比较,涵盖两个ID数据集(AG, IMDB)和两个OOD数据集(MR, TREC)。)
(表V:Offline-Attack(Ours)与HLBB和TextHoaxer(TH)攻击方法在Vicuna(Vic.)和ChatGPT(Chat.)目标模型上的性能比较,涵盖两个ID数据集(AG, IMDB)和两个OOD数据集(MR, TREC)。)
为了研究Offline-Attack是否可以攻击其他未参与生成 进行训练的LLMs,将Offline-Attack应用于攻击Vicuna和ChatGPT。实验结果报告在表V中,结果表明Offline-Attack仍然能够在其他目标LLMs上生成质量相对较高的对抗样本。此外,无论是在ASR还是对抗样本质量方面,Offline-Attack仍然比两个基线方法具有显著优势。然而,观察到Offline-Attack在攻击LLaMA时比攻击这两个LLM时取得了明显更好的ASR性能。将此归因于以下两个事实:
(1) Vicuna和ChatGPT更鲁棒且更能抵抗攻击,因为它们的参数规模比LLaMA大得多。
(2) Offline-Attack是在可以误导LLaMA的对抗样本上训练的。此外,Offline-Attack在攻击这三个LLMs时取得了相似的对抗样本质量,这表明这三种攻击实际上共享了相当多的对抗样本。
人工评估 (表VI): (表VI:人工评估结果。)
(表VI:人工评估结果。)
为了进一步评估对抗样本,基于以下三个标准进行了人工评估:标签一致性(Con.)、相似性(Sim.)和流畅性与语法性(Flu.&Gra.)。选择了五位在标注前通过测试的经验丰富的志愿者。从IMDB和MR数据集中各随机选择100个实例作为标注数据。每个实例都是一个三元组 <#orig, gold="" label="">,其中 #Orig 和 #Adv 表示原始文本和Offline-Attack生成的相应对抗样本。对于Con.,首先要求志愿者手动标注 #Adv,他们从三个选项(即正面、负面、中性)中选择。然后,检查他们的标注是否与黄金标签匹配,并计算平均匹配百分比作为Con.,这是评估对抗样本人类不可察觉性的指标。
对于Sim.,要求志愿者评估每个 #Orig 及其对应的 #Adv 在语义上是否相同。提供三个选项供选择:同意、模棱两可和不同意。并计算每个选项的平均百分比作为Sim.。
对于Flu.&Gra.,要求志愿者判断 #Adv 是否流畅且语法正确。重用为Sim.定义的三个等级量表。Sim.和Flu.&Gra.是从人类角度评估对抗样本语言质量的指标。
表VI展示了志愿者的评估结果。使用Fleiss" Kappa测量的标注者间一致性,Con.、Sim.和Flu.&Gra.的得分分别为0.62、0.65和0.63,表明这些得分均属于实质性一致的区间。从结果中观察到,Offline-Attack生成的对抗样本对人类来说是难以察觉的,并且从人类角度来看具有较高的语言质量。具体来说,(1) Con.取得了令人印象深刻的性能,超过81.6%的样本被评为难以察觉,这表明Offline-Attack生成的对抗样本难以被人类检测到。(2) Sim.和Flu.&Gra.的同意得分分别超过87.0%和83.5%。这些高分表明,对抗样本与原始文本保持了语义相似性,表现出高流畅性,并且从人类角度来看包含较少的语法错误。
5、结论
在本文中,研究了针对大型语言模型(LLMs)的文本对抗攻击,并提出了Offline-Attack。设计了一个对抗机器翻译(AMT)框架,并构建了一个大规模的对抗数据集来对其进行训练。训练良好的AMT可以直接为给定的文本生成对抗样本。在四个数据集上的实验结果证明了本文方法针对LLaMA模型的有效性。并且对另外两个LLMs的广泛探索揭示了本文方法具有良好的攻击能力。此外,人工评估证明了本文方法生成的对抗样本的高质量。
[1]:J. Wang, H. Xixu, W. Hou, H. Chen, R. Zheng, Y. Wang, L. Yang, W. Ye, H. Huang, X. Geng et al., “On the robustness of chatgpt: An adversarial and out-of-distribution perspective,” in ICLR 2023 Workshop on Trustworthy and Reliable Large-Scale Machine Learning Models, 2023.
[2]:X. Shen, Z. Chen, M. Backes, and Y. Zhang, “In chatgpt we trust? measuring and characterizing the reliability of chatgpt,” arXiv preprint arXiv:2304.08979, 2023.
[3]:J. Li, T. Du, S. Ji, R. Zhang, Q. Lu, M. Yang, and T. Wang, “Textshield: Robust text classification based on multimodal embedding and neural machine translation,” in 29th USENIX Security Symposium (USENIX Security 20), 2020, pp. 1381–1398.
[4]:D. Jin, Z. Jin, J. T. Zhou, and P. Szolovits, “Is bert really robust? a strong baseline for natural language attack on text classification and entailment,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 05, 2020, pp. 8018–8025.
[5]:D. Li, Y. Zhang, H. Peng, L. Chen, C. Brockett, M.-T. Sun, and W. B. Dolan, “Contextualized perturbation for textual adversarial attack,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 5053–5069.
[6]:H. Liu, B. Ji, J. Yu, S. Li, J. Ma, Z. Yi, M. Du, M. Li, J. Liu, and Z. Mo, “A more context-aware approach for textual adversarial attacks using probability difference-guided beam search,” IEEE Transactions on Knowledge and Data Engineering, pp. 1–16, 2023.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
