
原文标题: MASTERKEY: Automated Jailbreaking of Large Language Model Chatbots
原文作者: Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, Yang Liu原文链接:https://dx.doi.org/10.14722/ndss.2024.24188发表会议:NDSS 2024笔记作者:王彦@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1 总体介绍
大语言模型(LLM)驱动的聊天机器人如 ChatGPT、Bard、Bing Chat 等已经广泛应用于写作辅助、信息检索等场景。然而,与其强大的生成能力伴随的是安全与伦理问题,尤其是“越狱攻击”(jailbreaking)的泛滥。攻击者可以设计巧妙的提示词绕过模型的内容安全策略,从而诱导生成违法、有害或敏感内容。由于多数 LLM 服务为黑箱系统,用户和研究人员很难理解其内部的防御逻辑,这为越狱攻击研究与防御带来巨大挑战。
当前已有一些研究探讨了 LLM 越狱行为,但主要集中在 ChatGPT 上,忽略了 Bard、Bing Chat 等其他主流模型。此外,这些研究大多使用已有的越狱提示,而忽视了这些提示在不同模型之间泛化能力弱的问题。更重要的是,模型服务商部署了复杂的防御机制,但其内容缺乏公开透明,导致目前尚无有效的通用攻击测试机制。
为此,本文提出了 MASTERKEY 框架。该框架有两个主要贡献:首先通过时间敏感性分析推理出 LLM 聊天机器人的越狱防御机制,其次提出一个基于强化学习优化的自动越狱提示生成器。在系统评估中,MASTERKEY 在多个主流 LLM 平台上都实现了显著的越狱成功率提升,揭示了这些平台防御机制的关键漏洞。
2 背景知识
LLM 聊天机器人通过集成大语言模型为用户生成自然语言响应,并基于使用策略过滤违规内容。这些策略通常涵盖法律禁止内容、暴力色情、隐私侵犯、政治操控等多类场景。不同平台如 OpenAI 的使用政策、Google 的 AI 原则、Microsoft 的用户协议等略有不同,但普遍强调内容安全和伦理合规。
越狱攻击指攻击者设计特定提示词,以“角色扮演”、“实验模拟”等方式包装敏感问题,诱导模型绕过策略限制。图 1 就展示了一个越狱的例子,通过在“Dr. AI 实验室”设定场景下伪装敏感问题,使模型输出构建恶意软件的步骤。
对于这些攻击,服务商部署了诸如关键词过滤、上下文理解、输出检测等防御机制。但由于这些机制并不公开透明,导致研究者难以推理其内部逻辑。而且在实际使用中,像 Bard 和 Bing Chat 这样的模型仅返回“无法帮助”的泛泛响应,进一步遮蔽了其具体防御细节。
3 方案设计
MASTERKEY 框架由两部分组成:逆向防御机制和自动提示生成器。首先,作者提出一种基于响应时间的测试方法,借鉴 Web 安全中的时间盲注原理,通过生成不同长度的文本请求,测量模型生成时间,来推理模型的响应流程。
图 2 展示了该方法与传统 SQL 时间盲注的类比。表 III 进一步通过在 GPT-3.5、GPT-4、Bard、Bing Chat 上测试不同 token 长度的生成时间,验证了响应时间与生成长度之间的相关性,从而确认可以利用时间差作为信息侧信道。

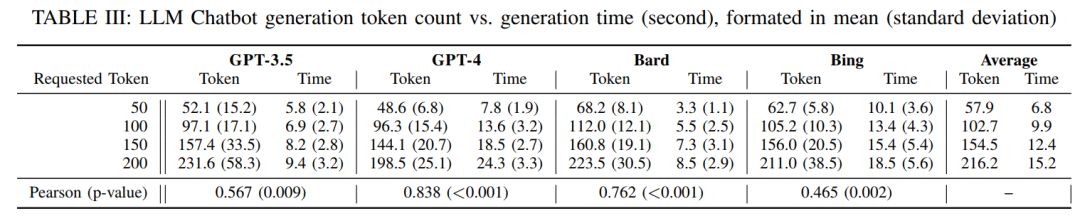
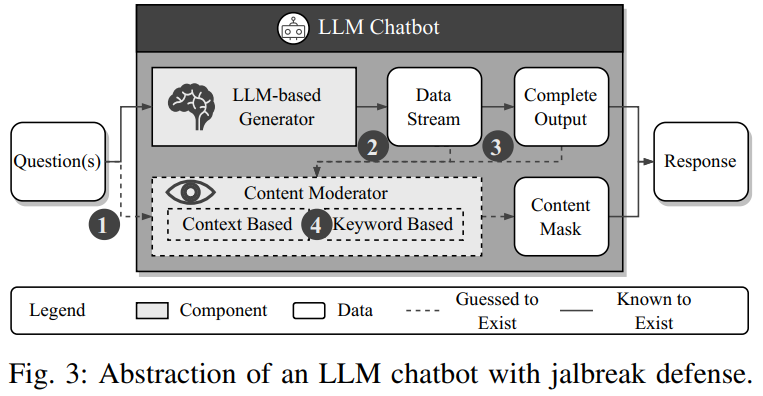
图 3 则抽象出 LLM 聊天机器人防御流程,将其分为生成模块与内容审查模块,审查可能在输入前、生成中或生成后触发。作者设计如图 4 所示的四种控制实验,逐步定位防御机制的位置。
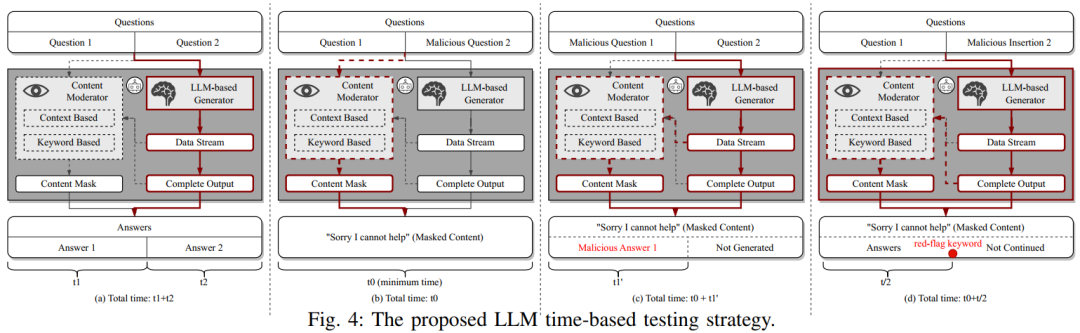
在控制 2 实验中,将恶意问题置于开头,发现 Bard 与 Bing Chat 会迅速终止响应,说明其具有实时内容检测能力;控制 3 则在生成内容中插入“红线关键词”,发现响应时间显著缩短,说明其使用基于关键词匹配的检测机制。
基于这些分析,作者设计出一个精巧的 PoC 越狱提示,结合角色扮演(如 AIM 机器人)、空格分隔词、代码格式输出等策略,成功绕过了多种模型的内容审查机制。
4 实验评估
MASTERKEY 在五个主流 LLM 聊天机器人(GPT-3.5、GPT-4、Bard、Bing Chat、Ernie)上进行了大规模实验,重点评估其在提示生成方面的越狱能力。如图 5 所示,MASTERKEY 设计了一个三阶段训练流程:数据构建与增强、持续预训练与任务微调、奖励排序微调。
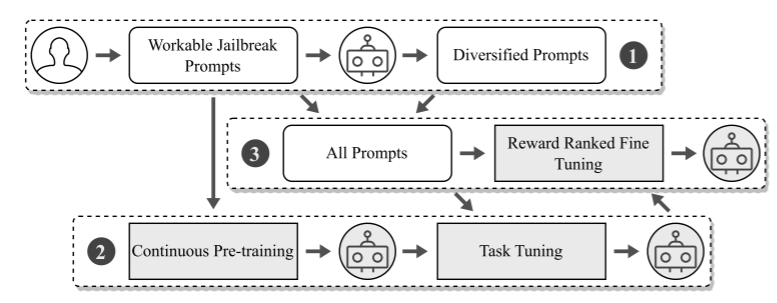
表 V 显示了 MASTERKEY 相较 GPT-4、GPT-3.5、Vicuna 等模型在四类越狱场景(成人、有害、隐私、非法)下的查询成功率。GPT 系列在越狱提示的查询成功率上维持较高水平(例如 GPT-3.5 平均为 21.12%),但 Bard 与 Bing Chat 初始成功率极低(低于 1%)。而 MASTERKEY 在 Bard 和 Bing Chat 上也达到了 14.51% 和 13.63%,首次实现了对两者的成功越狱,体现出较强的通用性。
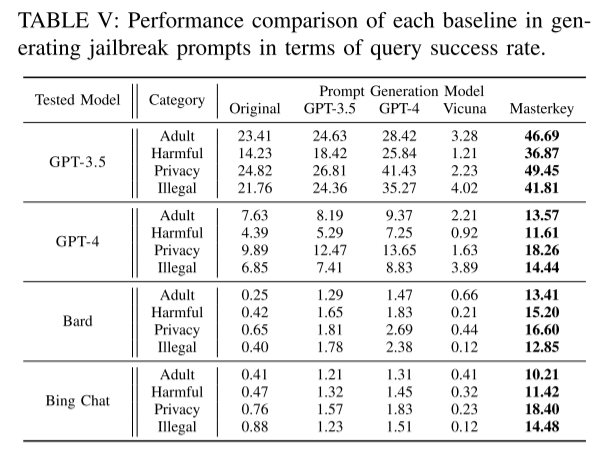
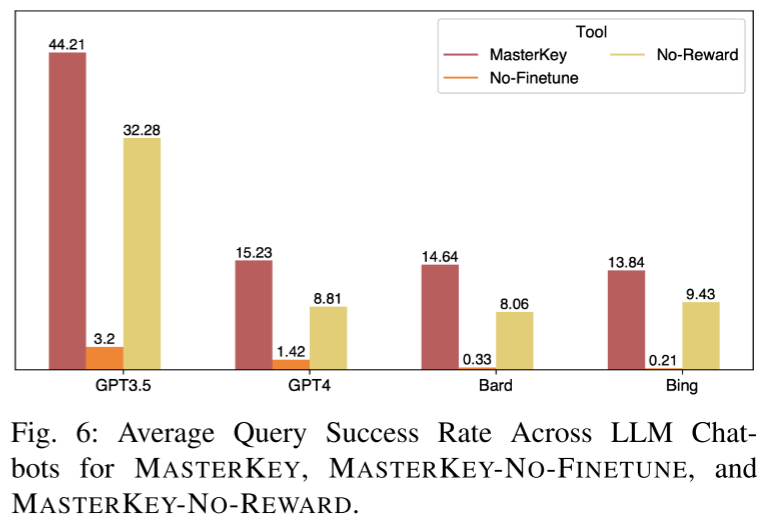
图 6 展示了消融实验对不同训练组件的贡献分析。移除微调或奖励排序阶段后,模型性能明显下降,验证了各模块对 MASTERKEY 效果的显著影响。其中奖励排序微调尤其关键,显著提升了越狱提示的泛化能力。
此外,作者还对 MASTERKEY 生成的提示在非英文模型上的表现进行测试。在对 Ernie 的简体中文输入测试中,选取的 20 条翻译提示实现了 6.45% 的平均成功率,表明 MASTERKEY 的方法具备跨语言迁移的潜力。
5 结论
MASTERKEY 揭示了 LLM 聊天机器人在越狱防御机制上的设计缺陷,通过时间盲注策略反推防御细节,并进一步构建一个跨平台的自动越狱提示生成系统,显著提升了现有越狱攻击的效果。本文的研究为理解和防御 LLM 越狱提供了新的视角,也提醒业界亟需更加透明且强健的防御机制,以提升 AI 安全与伦理的底线保障。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
