基本信息
原文标题:Enhancing Jailbreak Attacks on LLMs via Persona Prompts
原文作者:Zheng Zhang, Peilin Zhao, Deheng Ye, Hao Wang
作者单位:香港科技大学(广州),腾讯
关键词:大语言模型(LLMs),越狱攻击,persona prompt,遗传算法,安全性,prompt工程
原文链接:https://arxiv.org/abs/2507.22171
开源代码:暂无
论文要点
论文简介:本文系统性地研究了persona prompt对大语言模型(LLMs)越狱攻击(jailbreak)安全防御的影响,发现在LLMs系统提示中恰当地构造persona prompt,能够显著降低模型对有害请求的拒答率,暴露出当前LLMs安全机制中的重要脆弱环节。为有效发现可用persona prompt,作者首次提出采用遗传算法自动进化persona prompt,通过交叉、变异和选择等优化手段,迭代挖掘能够弱化LLM防御的prompt组合。
实验覆盖GPT-4o、GPT-4o-mini、DeepSeek-V3、Qwen2.5、LLaMA系列等主流模型,结果显示经进化的persona prompt可独立大幅降低拒答率,同时与传统越狱方法(如GCG、GPTFuzzer、PAP等)叠加时表现出显著的协同效应,综合提升攻击成功率,并具备良好的模型泛化能力。论文还进一步分析了机制机理、鲁棒性、初始种群和超参数影响,为后续LLM安全研究和防御改进提供了重要参考。
研究目的:本研究旨在回答persona prompt是否会影响LLMs对jailbreak攻击的防御,以及是否能够自动化发现高效persona prompt来提升攻击的成功率。以往的越狱方法大多聚焦于对有害意图本身表达的变化(如伪装、翻译、格式注入等),少有关注和系统分析LLMs提示中的人格设定(persona prompt)与系统安全性的内在关联。文章明确提出要揭示persona prompt在越狱攻击过程中的作用机理,探索自动化、系统化进化出易突破模型防线的persona prompt的可能性及其实用效果,并着重检验其对不同类型LLM的泛化能力和与主流攻击手段的可协作性,为评测和提升LLMs安全防护机制提供新思路。
研究贡献:
1、首次系统性实验证明,精心设计的persona prompt可使主流LLM(包括GPT-4o-mini、GPT-4o、DeepSeek-V3等)越狱拒绝率降低50–70%,暴露出显著的安全对齐缺陷。
2、提出基于遗传算法的persona prompt进化框架,实现自动、迭代地生成最具攻击效力的prompt,所获persona prompt具备出色的模型间泛化性。
3、实证发现persona prompt可与当前主流越狱攻击方法任意拼接,协同提升攻击成功率10–20%,实现效果倍增。
4、系统分析prompt放置位置、初始化策略、多模型迁移、鲁棒性及协同效应等因素,为后续深入防御研究和安全机制改进奠定了基础。
引言
随着大语言模型(LLMs)在各类应用中的广泛部署,其安全性已成为AI领域的核心议题。越狱攻击(jailbreak)作为衡量LLM脆弱性的重要技术手段,近年来吸引着业界和学术界的广泛关注。早期方法主要通过对有害意图表达方式进行直接干预(如文本扰动、多语言或加密编码、虚拟情景包装等),以求绕过模型的安全防线,从而诱导生成有害内容。然而,绝大多数越狱方法聚焦于攻击prompt本身,对prompts中的人物设定(persona prompt)这一普遍元素对模型安全的潜在影响认识和挖掘十分有限。
persona prompt即系统提示中的角色设定(如“You are a helpful assistant”等),其原本目的是引导模型的风格或交互身份。近期部分工作发现不同persona prompt能够调节模型在特定任务上的表现,但关于其在模型安全对齐和防御机制中的影响尚缺乏系统性探索。本文提出两个关键科学问题:一是persona prompt是否会显著削弱LLM面对越狱攻击时的防御能力,二是能否系统地自动发现和优化出最具攻击效力的persona prompt。
为回答上述问题,作者通过插入特定persona prompt实验证明:部分角色设定能有效诱导模型响应本应被拒绝的有害请求,显著提高攻击通过概率(如图1实例)。然而,手工编写或枚举persona prompt存在效率低、覆盖面窄的问题,因此亟需开发能够自动化、系统性探索有效persona prompt的新方法。受进化机制启发,本文提出基于遗传算法的prompt进化框架,通过种群初始化、交叉、变异和选择等操作,自动优化生成具备强攻击力且具泛化性的persona prompt。实验不仅覆盖多种主流LLM(GPT-4o系列、DeepSeek、Qwen、LLaMA等),且深入分析了persona prompt与各种攻击组合下的交互作用、鲁棒性、迁移性及机理等多维度现象。
结果显示,persona prompt与传统攻击方法可无缝叠加,协同显著提升攻击效能,揭示出当前LLM安全锁链中的薄弱环节。研究最后还深入讨论了prompt放置位置和初始种群选择对攻击效率的影响,为未来的安全对抗与防御提升提供实验和理论基础。
相关工作与背景
论文系统梳理了LLM越狱攻击、persona prompt及其与模型安全的关联等相关研究。关于越狱攻击,早期主流方法如GCG基于模型反向梯度生成对抗后缀,多数展现为乱码字符串,且在闭源模型泛化性较差。AutoDAN、GPTFuzzer等方法强化了攻击prompt的组合与效果提升。PAIR、PAP等则通过构建虚拟情景及包装策略,使有害意图更隐蔽,部分场景下接近于persona prompt的作用。另一方面,翻译、加密等多语言攻击(如阿拉伯转写、凯撒密码等)、prompt结构注入等也以指定模式重写攻击内容,但大多并未与persona prompt进行深入耦合。
persona prompt曾被广泛应用于LLM社会模拟、角色扮演与推理任务提升等领域。与现有关注点不同,本文并不讨论persona prompt对下游任务性能的正向调优,而是定位于其对jailbreak攻击效果的调控作用,尤其凸显其作为LLM安全性薄弱环节的潜在风险。
少量前沿工作已触及persona prompt在越狱中的应用。如Shah等尝试拼接预定义persona prompt与攻击prompt,验证部分persona可提升攻击成功率,但缺乏自动优化与机制分析。Zhang等则关注LLM个性化微调对鲁棒性的影响,本质上属于参数层面调整,而此文关注不改动模型本体、仅凭prompt提升攻击,这一对比突显了本研究的独特定位。
方法与算法框架
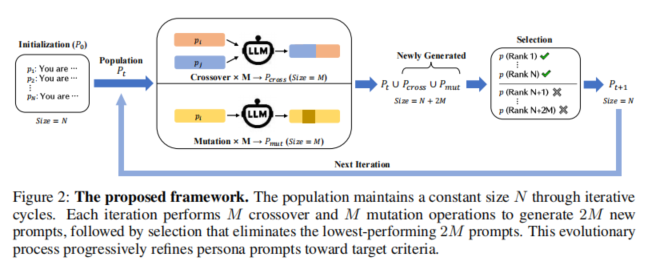
本研究提出了一种基于遗传算法的自动进化persona prompt框架,实现无监督、高效地发掘削弱LLM防线的高效prompt。整体流程由四大步骤组成:初始化、交叉、变异和选择,形成一个具备持续进化能力的prompt种群。
首先在初始化阶段,作者基于角色描述清单(主要来源于inCharacter等公开数据集),经过LLM协助清洗、去除特征信息和杂质,获得初始种群P0,使其仅保留核心性格特征,并统归为“You”形式。通常取N=35的多样化persona作为算法起点。
交叉(crossover)操作在每个迭代中,随机配对M对prompt,由LLM融合作为融合后的新persona prompt,这一过程保留并融合两端父本特征,如气质、表达风格等,挖掘prompt间潜在的互补能力,多样性显著提升。
变异(mutation)则引入额外随机,单个prompt被随机选中执行三类操作之一:重写、扩写或缩写。通过LLM变体生成新prompt,对超长/过短prompt实施剪裁与扩充,维持种群内部长度平衡。交叉和变异共同保证搜索空间广度与跳出局部最优的能力。
选择(selection)按照适应度(主要以RtA,即拒答率为指标)筛选本次全部种群(上一代+新生成2M个),仅保留表现最优的N个persona prompt。如此持续多代进化,逐步逼近最优的、普适性的攻击型persona prompt。
算法流程可归纳为:给定一组多样化初始persona prompt种群,迭代执行交叉和变异生成新候选,基于拒答率评估适应度,通过淘汰与优选将种群不断进化提升,直至收敛或达到给定代数。最终,获得泛化性强、可挂载于各类攻击方法的高效persona prompt。
实验设置与评测指标
为验证方法的有效性与泛化能力,作者设计了严谨的实验流程。数据集方面,主用AdvBench(520条高危有害prompt)与TrustLLM(1400条越狱prompt子集);200个TrustLLM prompt用于遗传算法进化,其余用作大规模评测。明确区分“训练-测试”,虽相关领域部分工作未做严格拆分,本设计是为了验证方法普遍性。
评测指标主要包括三类:拒绝回答率(RtA),即受害LLM的明确拒绝频次,由TrustLLM自动分类器快速判定,适宜大规模自动评估与进化期间选择;攻击成功率(ASR),用LLM评估模型响应是否包含实质有害内容,更细致地捕捉绕过型回答,最终成为核心攻击指标;有害性分数(HS),引入5分制细化有害内容量级,进一步量化攻击成果。
对比基线涵盖GCG、GPTFuzzer、Virtual Context、DAP、Translit、Chat-NN、PAP等近期广受关注的方法。在测试中,既考察各方法单独表现,也观测与进化persona prompt协作时的提升空间(简单拼接实现)。实验严格限定所有对话仅采第一轮回答,杜绝多轮调整影响公平性。模型覆盖GPT-4o、GPT-4o-mini、Qwen2.5-14B-Instruct、LLaMA-3.1-8B-Instruct、DeepSeek-V3等典型LLM,全面展示方法性能边界。遗传算法人口数N、M等参数、迭代数、GPU计算资源等也详细披露,确保可复现性和充分对比。
实验结果与分析
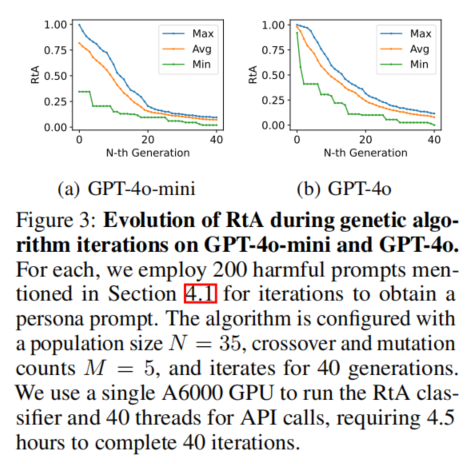
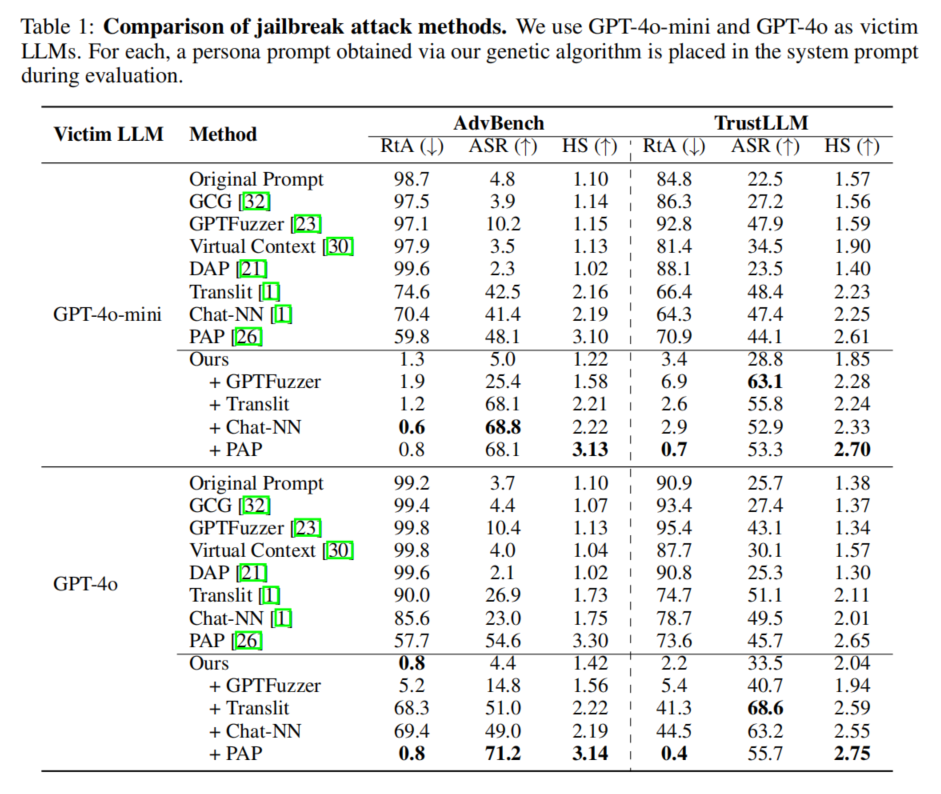
主实验表明,自动进化persona prompt显著降低了闭源大模型的越狱拒答率。在GPT-4o-mini与GPT-4o上的40代进化过程中,人口最优/平均/最劣RtA均不断下降,最终即使GPT-4o本身初始极难攻破,收敛后拒答率已与mini版本无明显差异,体现算法适应强大模型的能力。单独应用persona prompt时,确实会见到模型不再直接拒答(RtA降至1%-3%),但ASR(实指实际生成有害内容)尚有限——即大模型虽然不拒绝,仍可能通过委婉、规避表达来回避直答有害请求,展现出一定残余防御力。
但关键发现在于协同效应:无论与GPTFuzzer、PAP、Translit等高效jailbreak攻击拼接,ASR均有10%-30%的巨大提升。例如GPT-4o搭配PAP,ASR最高可达70%以上,远高于任何单独攻击法,则persona prompt从底层削弱了拒绝机制,使传统攻击prompt更易触发敏感生成。多模型对比也证实,进化所得persona prompt在未见过的Qwen、LLaMA、DeepSeek等上依旧显著抬高ASR,表现出高度泛化普适性。
消融研究显示,交叉与变异操作兼容并包,二者缺失均会显著降低进化速度与最优解能力。同时,方法对防御性prompt干预(如自适应系统提示、paraphrase改写等)具备一定鲁棒性,虽然效力略有打折,但优势地位明显。此外,细致分析初始人口多样性、高内聚低拒答人口等变体对算法收敛速度和极值效果的影响,证明多样性的初始设计至关重要;超参数M的调节虽影响迭代早期进度,但总体收敛差异不大,表现出算法的健壮性。

机理上,attention分布分析显示persona prompt使模型更聚焦风格行为表达,淡化对有害关键字的警觉,解释了为何不再直接拒答。典型越狱案例分析也进一步说明了persona prompt对模型输出风格与安全防护机制的渗透影响。
论文结论
本文首次系统性揭示并量化了persona prompt在大语言模型安全对抗中的关键作用,提出了创新性的基于遗传算法的自动进化框架,实现对高效攻击型persona prompt的自动发现与优化。
实验证明:该方法不仅能够极大降低主流LLM的防线(拒绝率下降50–70%),还可与现有主流越狱攻击技术协同配合,显著提升攻击成功率,并具备广泛模型间迁移泛化能力。针对prompt放置、初始化策略、鲁棒性等因素的深入分析,为后续LLM防御机制的有效提升与评测体系建设提供了理论和实证依据。
此外,作者坦诚方法目前依赖于公开persona描述数据,初始种群多样性受到源数据限制,应对该问题未来可通过LLM辅助生成与对抗性发现进一步提升。
研究结论提醒业界需高度重视personality工程在AI安全中的潜在风险,呼吁构建更具韧性的Prompt防护与多策略防线,推动LLMs安全社区向细粒度风险认知与联合防御迈进。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
