
原文标题:FALL: Prior Failure Detection in Large Scale System Based on Language Model
原文作者:aeyoon Jeong , Insung Baek , Byungwoo Bang , Junyeon Lee , Uiseok Song , and Seoung Bum Kim原文链接:https://ieeexplore.ieee.org/document/10517618发表期刊:IEEE TDSC笔记作者:牟浩天@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、引言
高性能计算(HPC)系统是一种强大的计算平台,能够快速处理复杂的计算,其在规模显著扩大的同时,系统故障的发生率也在增加。在 HPC 发生故障后采取后续措施是必要的,然而这些措施会导致系统恢复正常运行时的操作效率下降。为了解决这个问题,现有研究利用深度学习通过分析日志消息来检测故障,但常用方法仅提取日志ID作为输入数据,可能导致信息丢失,无法准确捕捉日志消息的特性。为此,文章提出了一种基于语言模型的故障检测方法(FALL),将日志消息作为文本数据处理,并且只使用正常数据进行训练。FALL通过关注正常和异常日志消息之间最小的词汇变化,并利用日志消息有限词汇的特性,仅使用部分标记进行异常检测。通过对实际工业HPC系统的日志数据进行实验,结果显示FALL在提前故障检测方面表现优异。
2、相关工作
A. 文本异常检测
由于获取高质量异常数据耗时且成本高,异常检测方法仅使用正常数据训练网络以识别正常特征。包括使用支持向量机、聚类算法等方法,但这些方法在嵌入时以单词为单位,可能无法准确学习句子的结构和语义信息。随着深度学习的发展,出现了基于深度学习的异常检测方法,如LSTM-based autoencoder等,但由于LSTM的梯度消失问题,其在学习上下文信息方面存在局限性。为克服这些挑战,近期的研究提出了一些更适合文本数据的异常检测方法。其中,一种方法结合了替换掩码检测(RMD)这一新型自监督学习技术与高效学习标记替换分类器(ELECTRA)语言模型。该方法通过训练一个编码器来准确分类标记替换,从而实现对文本异常的检测。
然而,本文研究的系统日志消息数据具有独特的特性,即正常和异常日志消息之间词汇相似度高,且词汇量有限。这些特性使得现有的方法无法直接适用于日志消息数据。因此,本研究旨在对现有方法进行改进,使其能够更好地适应系统日志消息数据的特性,从而为HPC系统的早期故障检测提供一种有效的方法。
B. HPC系统中的故障预测
故障预测比故障检测更具挑战性,因为它需要基于现有数据预测系统未来可能出现的故障。以往研究使用了决策树、支持向量机等机器学习技术,以及LSTM等深度学习方法。然而,这些方法通常使用日志ID而非日志消息本身,可能导致信息丢失,未充分利用日志消息数据的特性。近期,一种基于Transformer模型的方法被提出,该方法对系统日志消息数据进行自然语言处理,提取日志消息的格式,并为其分配ID,然后将这些ID作为模型的输入。尽管这种方法尝试通过自监督学习来预测日志序列中的错误,但由于其基于分类的方法以及对日志消息作为自然语言的利用不足,仍然存在一定的局限性。
3、本文主要方法 - FALL
A. 预处理与窗口划分
FALL的预处理阶段与其他研究不同,不依赖于日志ID,而是对系统日志消息数据进行最小化预处理,包括转换为小写、删除标点和处理数字,其中数字被统一替换为“NUM”,如下图所示。这种处理方式旨在减少信息丢失,同时保护日志消息中的敏感信息。

预处理后的日志序列按节点划分并按时间顺序排序,每条日志消息用 x 表示,总共包含n个token,可表示为x = (t1,t2, . . . , tn)。为了作为模型的输入,日志序列Si由30个连续的日志消息组成,表示为Si = (xi,xi+1, . . . , xi+29)。标签的确定基于在预定义的未来时间间隔内是否发生故障,以此来区分正常和异常日志序列,如下图所示。

滑动窗口技术通过将日志消息序列Si视为一个窗口,并根据系统日志消息xi设置窗口步长为15来实现。窗口大小和步长的设定对于本研究有着重要意义。首先,如果窗口过小或过大,会导致模型判断所用的信息量过少或过多。其次,选择15为步长是为了确保日志序列数据的可用性,并增强日志序列内日志消息数组的多样性。
B. 替换token检测与替换掩码检测
FALL的训练方法借鉴了基于ELECTRA的DATE方法,包含生成器和判别器两个主要部分,如下图所示。
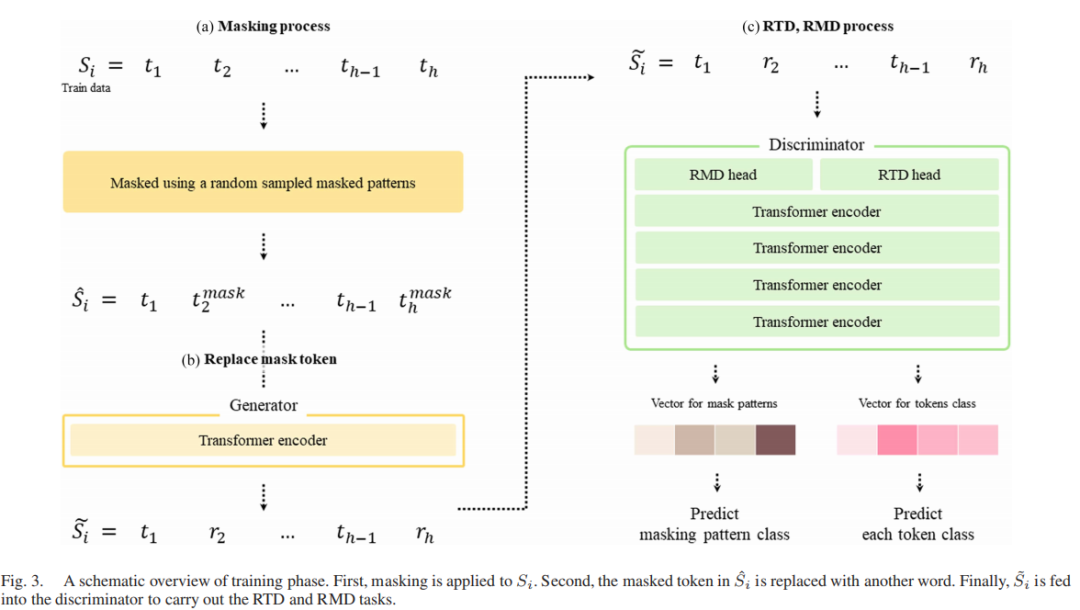
生成器作为掩码语言模型(MLM),负责替换输入中的掩码标记;判别器则同时执行替换掩码检测(RMD)和替换token检测(RTD)任务。生成器使用随机选择的方式替换掩码标记,在训练过程中,生成器接收经过掩码处理的日志序列作为输入,然后根据生成器学习到的词汇表概率,将掩码标记替换为其他词。生成器的目的是生成一个与原始日志序列相似但经过替换的新序列。判别器通过Transformer的encoder来评估每个标记是否为替换标记,它接收生成器输出的序列作为输入,通过RTD头判断每个标记是否被替换,并通过RMD头识别序列中的掩码模式。通过这两个任务可以让判别器学习到正常日志序列的标记和序列级别的上下文属性,包括标记和序列级别的特征,从而能够区分正常和异常日志序列。
C. 基于日志序列特性的异常分数
在异常检测任务中,仅使用判别器来评估模型性能。判别器基于RTD头输出的每个token被替换的可能性来确定异常分数。对于正常日志序列,模型在训练过程中学习到了这些token,因此判别器会为每个token分配较低的概率。然而,由于模型未学习过异常日志序列,所以会认为这些序列中的token被替换,并为其分配较高的概率。
为了提高模型对正常和异常日志序列的区分能力,FALL利用了日志序列正常和异常序列之间的词汇差异小的特性,通过锐化方法来增强正常和异常日志序列之间的差异。锐化方法可以由下所示的公式实现。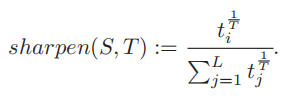 其中 L 和 T 分别代表标签数量和调节差异程度的 temperature 参数。通过对 RTD 头部输出的概率应用锐化,与早期故障指标相关的标记会获得更高的概率,而其他标记则获得更低的概率,从而提高了提前故障检测的性能。
其中 L 和 T 分别代表标签数量和调节差异程度的 temperature 参数。通过对 RTD 头部输出的概率应用锐化,与早期故障指标相关的标记会获得更高的概率,而其他标记则获得更低的概率,从而提高了提前故障检测的性能。
日志序列还有着词汇量有限的特征,因此,仅使用最有可能成为替代token的子集来计算异常分数,对于提前故障检测来说比对每个token评估概率更为有效。文章对锐化后的概率进行降序排序,并仅选择部分最有可能被替换的标记。最终的异常分数基于这些选定标记的概率进行计算,如下公式所示。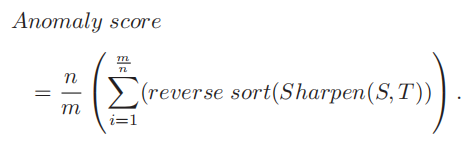
4、实验
A. 数据集及实验设置
文章实验的数据集来源于实际运行的 HPC 系统,涵盖了从2021年10月7日至2022年7月30日收集的包括约300万条基础板管理控制器(BMC)日志和约3000万条系统日志(syslog)消息。这些数据整合后,能够全面反映HPC系统的整体健康状况和硬件组件的物理状态,为故障预测提供了丰富的信息基础。
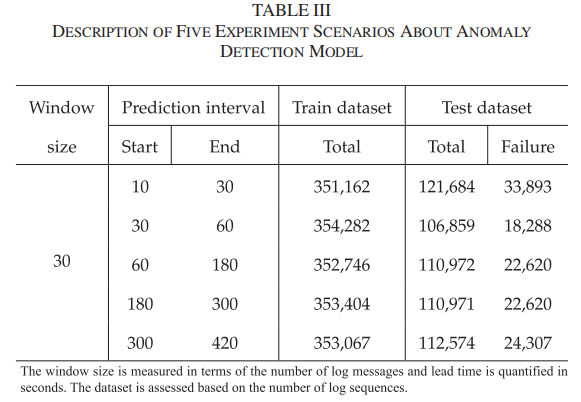
文章将收集到的日志消息数据集经过预处理和标记后,划分为正常和异常数据集,每个数据集再分为训练集和测试集,同时保持数据集的时间序列结构。训练集包含约35万条日志序列,其中表示故障的序列仅占1%;验证集包含约11万条日志序列,其中包含更多故障日志序列,以评估模型识别多种故障的能力。为了模拟实际故障预测场景,研究者通过改变提前时间和预测区间,生成了一系列实验场景,应用于日志消息数据集。如下表所示,实验中共有五种场景,基于当前日志序列,分别预测未来10秒、30秒、60秒、180秒和300秒内发生错误的概率。
模型参数方面,FALL使用了Transformer的encoder,生成器为单层,判别器为四层。输入日志序列的最大长度设为128,锐化方法的温度参数T设为1/2,计算异常分数时选取1/4的标记。模型采用AdamW优化器进行训练,训练步骤为20,000步,批量大小为128,并在三个不同随机种子上取平均性能和标准差以确保结果的稳定性。
实验包括使用分类模型的对比实验和使用异常检测模型的对比实验。分类模型包括循环神经网络 (RNN)、LSTM 、门控循环单元 (GRU) 和一维卷积神经网络 (1D CNN),在使用正常和故障日志序列训练后进行了评估。基于文本的异常检测技术包括隔离森林(Isolation Forest)、单类支持向量机(OCSVM)、深度支持向量数据描述 (deep SVDD) 和 基于文本的异常检测技术 DATE ,仅使用正常日志序列进行训练。
B. 评估指标
文章使用ROC曲线下面积(AUC-ROC)作为评估指标之一。AUC值范围为0.5到1,值越高表示模型性能越好。它通过计算模型在不同阈值下的真正例率(TPR)和假正例率(FPR)来评估模型的性能。
由于在早期故障检测中,将正常情况误分类为故障情况会导致巨大的时间和经济成本,文章使用平均 FP 数量作为第二项评估指标。
C. 实验结果
FALL与其他分类模型的比较实验结果如下表所示:
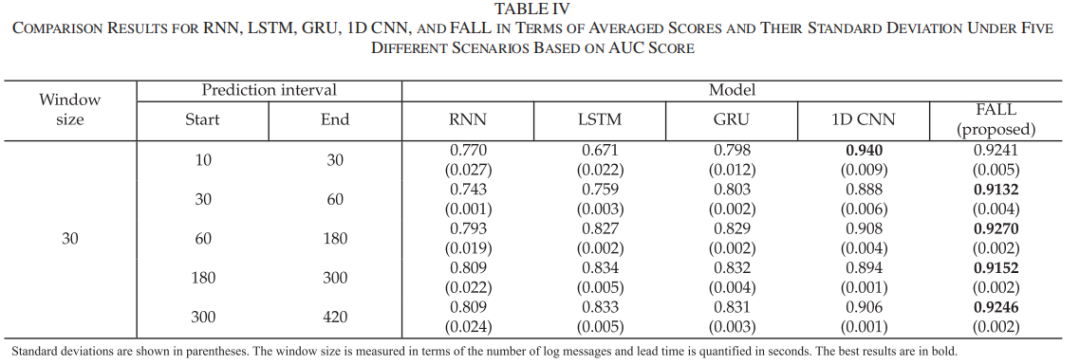
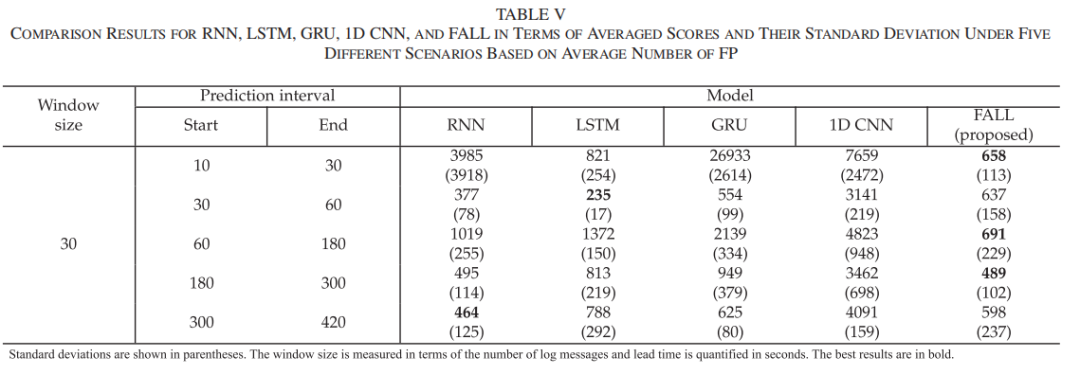
结果显示,FALL在所有预测场景中均取得了优异的性能。具体而言,FALL的平均AUC值超过0.91,显著高于其他模型;FALL在所有场景中的平均FP数量均低于700,这表明FALL在减少误报方面具有显著优势。这说明FALL在保持高检测准确率的同时,能够有效控制误报率,从而降低系统运维成本。
FALL与其他异常检测模型的比较实验结果如下表所示:
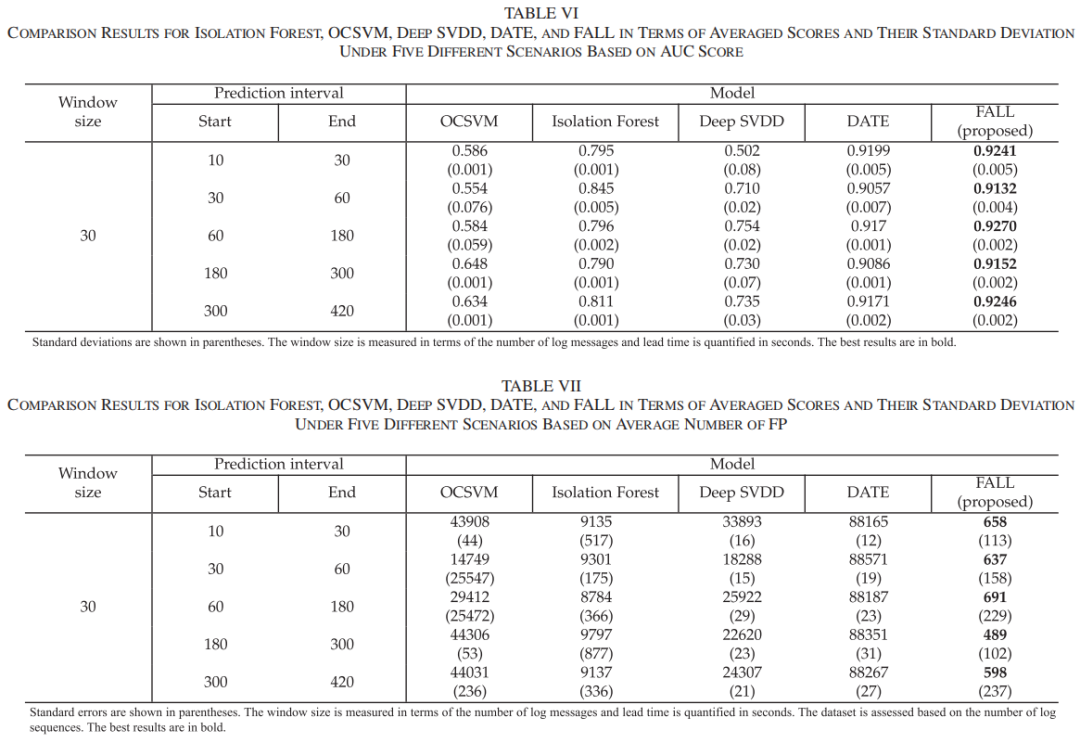
结果显示,FALL在所有场景中的AUC值均超过0.9,显著优于其他异常检测模型。此外,FALL在平均FP数量方面也表现出色,所有场景中的平均FP数量均低于其他模型。DATE虽然在某些场景中表现较好,但其FP数量显著高于FALL,这表明FALL在处理文本数据时具有更高的敏感性和特异性,能够更准确地识别潜在故障。
文章还进行了额外的实验以确认锐化以及选择性标记对 FALL 方法的影响,结果如下表所示:
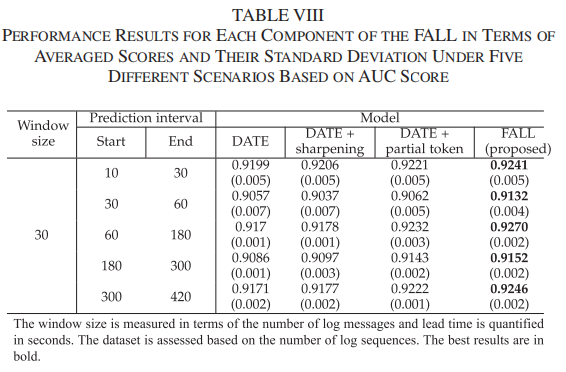
实验结果表明,锐化方法和选择性标记的引入显著提升了FALL的性能。具体而言,锐化方法通过增强正常和异常日志序列之间的差异,使模型能够更准确地区分两类日志。使用锐化方法后,FALL在各场景中的AUC值平均提升了0.0008。选择性标记则通过聚焦于与故障预测相关的标记,提高了模型的检测效率和准确性。使用选择性标记后,FALL的AUC值平均提升了0.004。综合这两种方法,FALL的AUC值在所有场景中比基线模型DATE平均提升了约0.008,这表明锐化方法和选择性标记在提升模型性能方面具有协同效应。
为了进一步验证FALL的鲁棒性和泛化能力,文章还在Thunderbird和BGL数据集上进行了实验。这些数据集是HPC系统故障预测领域的基准数据集,广泛用于评估模型性能。
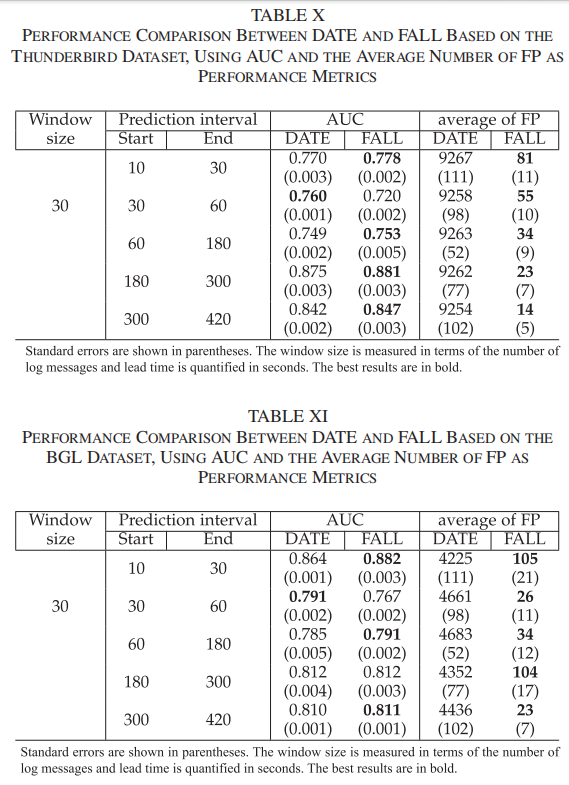
结果显示,FALL在这些数据集上的表现同样优于DATE。在Thunderbird数据集中,FALL在所有场景中的AUC值均超过了0.91,而DATE的AUC值在某些场景中低于0.9。在BGL数据集中,FALL在第一、第三和第五个场景中的表现显著优于DATE,并且在所有场景中的FP数量均低于DATE。这表明FALL不仅在特定数据集上表现出色,还具有较强的跨数据集适应能力,能够有效处理不同来源的日志数据。
5、总结
文章提出了一种基于文本的异常检测方法 FALL,用于 HPC 系统的提前故障检测。FALL首次将日志序列作为自然语言文本进行异常检测任务,适用于提前系统故障检测。通过利用日志序列特性,FALL提高了早期故障检测的性能,平均AUC值超过0.91,且在平均FP数量方面表现优异。文章的未来研究方向包括使用特定领域标记对日志消息进行预处理,研究节点故障数量及其相关性分析,以及探索使用自然语言预测模型预测特定系统故障类型。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
