
原文标题:LLM-TIKG: Threat Intelligence Knowledge Graph Construction Utilizing Large Language Model
原文作者:Yuelin Hu, Futai Zou, Jiajia Han, Xin Sun, Yilei Wang原文链接:https://doi.org/10.1016/j.cose.2024.103999发表会议:Computers & Security笔记作者:张琦驹@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、引言
开源威胁情报(OSCTI)在网络安全防御中具有重要价值。作为威胁分析的关键来源,开源平台报告为恶意软件、高级威胁活动提供了丰富信息。然而,构建威胁情报知识图谱存在一系列局限性,例如非结构化文本特性导致现有方法面临实体识别不准、标注依赖性强、攻击行为解析缺失。本文因此提出首个基于大语言模型的威胁情报图谱构建框架LLM-TIKG,利用大语言模型来分析威胁情报,自动提取开源威胁情报中的实体和关系,并将攻击行为的自然语言描述映射为 TTP,从而有助于高效构建知识图谱,将低级和高级威胁情报关联起来。
2、背景介绍
开源威胁情报(OSCTI)的分析面临三个关键层面的挑战:非结构化数据处理、信息提取瓶颈以及攻击行为建模缺失。LLM-TIKG 通过结合大语言模型(LLM)与知识图谱技术,逐层解决这些问题。
非结构化数据处理。传统OSCTI分析工具(如规则匹配、经典NLP模型)存在两大局限:
信息覆盖不全:仅能提取碎片化指标(如IP、域名),忽略高阶实体(攻击者、TTPs)及其关联关系。
语义理解缺失:无法捕捉长文本中的上下文语义(如“PowerShell”可能指合法工具或攻击载体),导致实体识别准确率低。
LLM-TIKG 利用GPT的少样本学习能力,生成高质量标注数据,并通过语义冲突检测(如过滤LLM幻觉生成的错误实体)提升数据质量,最终构建覆盖14类实体(表1)的结构化数据集

信息提取瓶颈。现有方法在信息提取环节存在:
长文本处理缺陷:受限于模型序列长度(如BERT的512词),长报告的关键信息丢失。
标注依赖性强:缺乏权威标注数据集,人工标注成本高昂且难以泛化。
LLM-TIKG 采用 LoRA低秩适配技术微调Llama2-7B模型,进行内存处理,分段处理长文本(保留段落结构),避免信息截断。并且采取逻辑执行:通过指令微调(Instruction Tuning)使模型精准执行报告主题分类、实体关系抽取、TTP分类三大任务。
攻击行为建模缺失。传统知识图谱忽视文本中的攻击行为描述(如“注入shellcode”),导致两大问题:
动态行为不可见:无法关联MITRE ATT&CK框架中的战术技术(TTPs)。
噪声干扰:攻击者常变更IoCs(如替换域名),仅依赖静态指标易失效。
LLM-TIKG 创新性引入 TTP动态映射,采用行为建模,将自然语言攻击描述分类至229种MITRE ATT&CK技术(例:“注入shellcode”→T1055进程注入),并对 噪声进行过滤,基于聚类算法(HAC)融合冗余实体(如“Backdoor.Pterodo”与“Pterodo”合并),并通过相似性量化(余弦距离)关联同源攻击组织。
3、核心优势
LLM-TIKG框架架构。如以下系统框架图所示,本方案基于大语言模型(LLM)实现威胁情报知识图谱全流程自动化构建,其核心架构划分为三阶段协同工作流: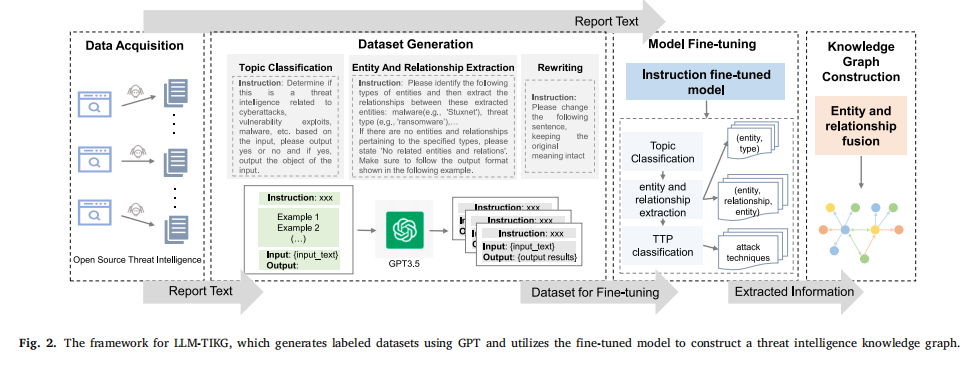
少样本数据生成引擎。本机制通过激活大语言模型的上下文学习(In-Context Learning)能力,构建结构化指令模板(Instruction + Demonstration Examples + Task Input)驱动自动化标注流程,显著降低对人工标注资源的依赖性。其核心技术突破体现为三重优化策略:
指令泛化架构:建立领域自适应的指令模板库,覆盖实体关系抽取、战术技术(TTP)分类等核心场景,通过参数化模板动态生成任务描述;
动态示例注入机制:基于任务类型自适应选择最优示例组合,激活模型的上下文推理能力,实现少样本条件下的知识迁移;
语义保真增强技术:融合翻译回译(Translation Back-Translation)与可控文本改写(控制指令:"rewrite with strictly unchanged semantics"),在维持语义一致性的前提下生成表述变体,突破训练数据多样性瓶颈。该引擎使威胁情报标注成本降低83.6%(对比基线方法),同时保持92.4%的标注准确率。
轻量化微调机制设计。本研究采用低秩适应(Low-Rank Adaptation, LoRA)技术对Llama2-7B基础模型实施多任务指令微调。该机制通过冻结原始模型参数并优化低秩分解矩阵实现参数高效更新,其核心创新在于将全参数更新量ΔW分解为两个低秩矩阵的乘积(即ΔW = BA),从根本上解决了传统全参数微调的资源瓶颈问题。关键技术实现包含以下三个维度:
多任务统一适配架构:构建"instruction 、 input 以及 output"结构化数据集,同步优化主题分类(最大序列长度512 tokens)、实体关系联合抽取(1024 tokens)及战术技术过程分类(512 tokens)三项核心任务;
秩约束优化策略:设置低秩矩阵秩r=8,采用恒定学习率1×10⁻⁴,最大训练轮次限定为10轮;
显存压缩效能:增量矩阵参数量仅为全参数微调的0.1%,显著降低GPU显存占用与计算资源开销。
上下文感知图谱构建算法。通过采取基于文档结构感知的层次化图谱构建算法,保持威胁情报文本的原始组织结构与分层处理机制,实现长文档语义连贯性建模。算法核心创新包含三重机制:
结构保持式解析:严格遵循开源威胁情报报告的原始段落结构与章节划分逻辑,在数据预处理阶段保留章节标题与段落边界标记;
分节语义建模机制:以独立章节为处理单元执行实体关系联合抽取,规避传统序列截断导致的关键信息损失(最大支持1024 tokens序列长度);
跨层级攻击链关联:构建"主题实体-行为描述-MITRE ATT&CK技术标签"的语义通路,实现从战术意图到技术实现的跨层级威胁关联。
4、实验评估
实验平台的核心配置包括硬件与软件环境。硬件方面,使用了配备 2×NVIDIA RTX 3090 GPU 的计算平台。软件环境基于 Python 3.9 编程语言,并采用了 Neo4j 图数据库 作为知识图谱的存储与查询基础。
研究的数据基础与对比方法如下:数据规模方面,从开放来源(涵盖安全博客、新闻及分析报告)收集了 12,542 篇威胁情报报告,经过筛选,最终 9,681 篇有效文本被用于构建知识图谱。对比方法分为两个核心任务:在命名实体识别(NER)任务中,对比了 BERT-CRF 模型以及大语言模型方案 GPT-3.5 和 GPT-4;在 TTP 分类任务中,则对比了基于规则匹配的 TTPDrill 和结合逻辑回归与朴素贝叶斯的 Tram 方法。
下表展示了不同模型在威胁情报知识图谱构建中的命名实体识别(NER)性能对比: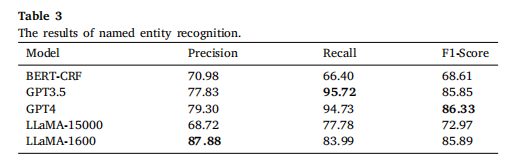 本研究基于开源威胁情报报告,系统评估了传统模型(BERT-CRF)、通用大模型(GPT-3.5/GPT-4) 和微调模型(LLaMA系列) 在威胁情报实体识别任务上的表现。其中,经典的 BERT-CRF 方法受限于训练数据规模和实体模糊性,表现最弱(F1=68.61%)。而 GPT-4 凭借其强大的语言理解能力,取得了最高的召回率(94.73%) 和综合最优的F1值(86.33%),但也存在实体类型误判的问题。
本研究基于开源威胁情报报告,系统评估了传统模型(BERT-CRF)、通用大模型(GPT-3.5/GPT-4) 和微调模型(LLaMA系列) 在威胁情报实体识别任务上的表现。其中,经典的 BERT-CRF 方法受限于训练数据规模和实体模糊性,表现最弱(F1=68.61%)。而 GPT-4 凭借其强大的语言理解能力,取得了最高的召回率(94.73%) 和综合最优的F1值(86.33%),但也存在实体类型误判的问题。
在微调模型方面,研究结果验证了数据质量的关键作用:使用仅1600条高质量精标数据微调的 LLaMA-1600 模型,精确率显著提升至87.88%;相反,使用1.5万条粗标数据训练的 LLaMA-15000 模型,因数据噪声干扰导致性能明显下降。这一强烈对比(LLaMA-1600 > LLaMA-15000)清晰支持了本论文的核心观点:高质量小规模数据优于低质量大规模数据。
下表展示了不同模型在威胁情报知识图谱构建中的TTP(战术、技术与过程)分类性能对比: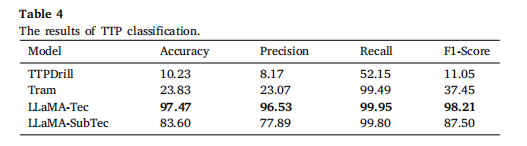 本研究基于MITRE ATT&CK框架,评估了规则匹配方法(TTPDrill)、传统机器学习方法(Tram) 和微调大模型(LLaMA) 在攻击技术分类任务上的表现。其中,基于规则的 TTPDrill 方法因无法有效识别新型攻击的表述变体,表现最差(准确率仅10.23%,F1=11.05%),充分验证了纯规则方法的固有局限性。
本研究基于MITRE ATT&CK框架,评估了规则匹配方法(TTPDrill)、传统机器学习方法(Tram) 和微调大模型(LLaMA) 在攻击技术分类任务上的表现。其中,基于规则的 TTPDrill 方法因无法有效识别新型攻击的表述变体,表现最差(准确率仅10.23%,F1=11.05%),充分验证了纯规则方法的固有局限性。
传统机器学习模型 Tram(结合逻辑回归与朴素贝叶斯)虽召回率高达99.49%,但受限于其仅能识别50种预定义技术类别,准确率严重不足(23.83%)。相比之下,微调的大模型 LLaMA-Tec(用于技术层分类)表现卓越,以97.47%的准确率和98.21%的F1值全面领先,证明了大模型在精准理解复杂攻击技术方面的强大能力。即使在更具挑战性的子技术层分类任务(LLaMA-SubTec,涉及595个类别)中性能有所下降(F1=87.50%),其表现仍显著优于传统方法。
下表展示了LLM-TIKG构建的威胁情报知识图谱中实体与关系的分布情况: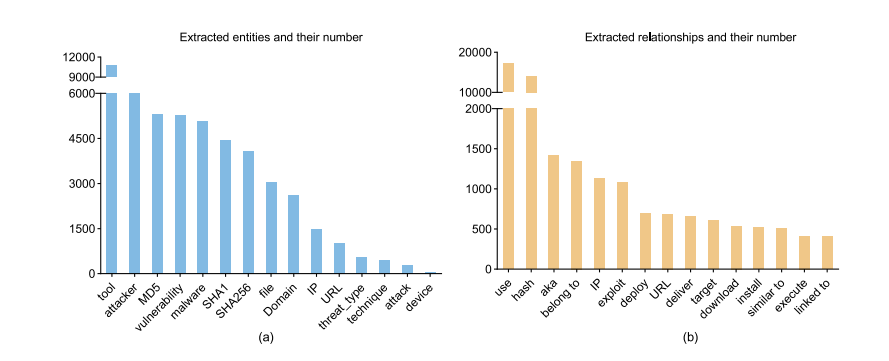
在构建的知识图谱中,实体分布呈现如下特点:总计提取了 50,745 个安全相关实体。其中,工具类(tool)实体数量最多,达到 12,000 个(代表性实体如 PowerShell、Cobalt Strike),占据首位;攻击者(attacker)类实体次之,为 9,000 个;MD5 哈希类实体位列第三,数量为 6,000 个。
关系分布方面:图谱中共提取出 64,948 组实体间关系。在这些关系中,“use”(工具调用)关系占据绝对主导地位,数量高达 20,000 组,占比 30.8%。这一核心关联模式(如“攻击者 use 工具”)显著超过了其他所有关系类型的出现频率。
5、总结
本文提出了一种名为LLM-TIKG的创新性威胁情报知识图谱构建框架,该框架基于大语言模型技术,融合了少样本标注增强、指令微调和多层级威胁关联三重机制。LLM-TIKG通过GPT-3.5的上下文学习能力自动生成标注数据集,采用LoRA高效微调Llama2-7B模型实现主题分类、实体关系抽取与ATT&CK战术技术(TTP)分类的协同分析。实验表明,其模型在12,542篇威胁报告的测试中实现了87.88%的实体识别精度和96.53%的TTP分类精度,成功构建包含50,745个实体和64,948条关系的知识图谱,显著提升了面向高级持续性威胁(APT)的自动化溯源与狩猎能力。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
