
原文标题:Automated machine learning for deep learning based malware detection
原文作者:Austin Brown, Maanak Gupta, Mahmoud Abdelsalam原文链接:https://doi.org/10.1016/j.cose.2023.103582发表会议:Computers & Security笔记作者:张琦驹@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、引言
随着数字互联程度提升,恶意软件攻击造成的损失日益严重,亟需高效防御机制。深度学习在恶意软件检测中表现出色,但模型架构与超参数优化依赖领域知识,且现有模型未必适配不同数据集。
自动化机器学习(Auto Machine Learning, AutoML)可自动化模型优化关键环节,减少人工干预,但其在恶意软件检测中的应用研究有限。本文旨在分析 AutoML 在静态和在线恶意软件检测中的可行性,通过实验验证其性能是否能与现有先进模型相当甚至更优,为简化恶意软件检测模型设计提供解决方案。
2、神经架构搜索
神经架构搜索(Neural Architecture Search, NAS)是 AutoML 的核心组件,其核心任务是自动找到在特定数据集上性能最优的神经网络架构,通过自动化探索网络结构设计空间,减少人工设计的试错成本,其中对搜索空间的合理约束与搜索策略的选择是提升效率的关键。该机制围绕架构搜索的目标、范围、方法及评估展开,具体包括以下内容:
NAS 的核心目标与架构定义NAS 的首要目标是从预设的搜索空间中,找到能在未见过的验证数据上达到最高性能的神经网络架构。在本研究中,架构设计的改变主要包括:
网络中可训练参数的数量或配置变化(如隐藏层的层数、每层节点数);
各层激活函数的选择(如 ReLU、ELU 等);
网络组件的连接方式(如卷积层与池化层的组合、跳跃连接的设置)。
NAS 搜索空间(Search Space)的设计搜索空间是包含所有可能有效模型配置的集合,NAS 过程中所有候选架构均从该空间中生成并评估。为平衡搜索效率与模型性能,需对空间进行合理约束,架构搜索空间的参数范围如下图所示:
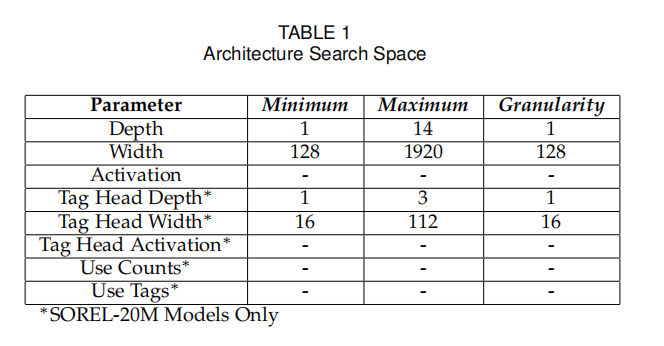
边界约束:设置网络深度上限(如静态分析中 FFNN 的最大层数为 14)、层宽度范围(如 128-1920 神经元,以 128 为粒度递增),避免模型过于复杂导致训练成本过高;
粒度与分布约束:设定参数选择的最小单位(如层宽度粒度为 128),并定义采样分布(如学习率采用对数均匀分布);
统一性约束:为简化搜索过程,部分参数(如层宽度)在选定后固定应用于整个网络的所有层,而非逐层单独设置。
主要 NAS 搜索方法根据搜索过程的不同,论文中采用了两种典型 NAS 方法:
多阶段搜索(Multi-Trial NAS):适用于静态分析的 FFNN 模型。通过多次独立试验,每次从搜索空间中随机选择一种网络配置进行训练,根据评估结果筛选最优架构。虽需多次训练,但适用于层输出形状难以统一的网络;
单阶段搜索(One-Shot NAS):适用于在线分析的 CNN 模型,以 Darts 方法为代表。构建包含所有可能网络组件的 “超网络”,通过梯度下降优化各组件的选择概率(如卷积层、池化层的连接权重),一次性确定最优卷积单元(正常单元与缩减单元),无需反复训练完整网络,大幅降低计算开销。
架构评估与选择策略为确保选出的架构性能最优,NAS 过程中采用严格的评估机制:
评估指标:以 F1 分数作为主要评估指标,综合考量模型的精确率与召回率,更贴合恶意软件检测的实际需求;
选择策略:多阶段搜索中采用随机选择策略,从搜索空间中无重复地随机抽取架构进行试验;单阶段搜索中通过 softmax 函数将组件选择转化为连续概率分布,利用梯度下降更新概率,最终选择概率最高的组件组合作为最优架构;
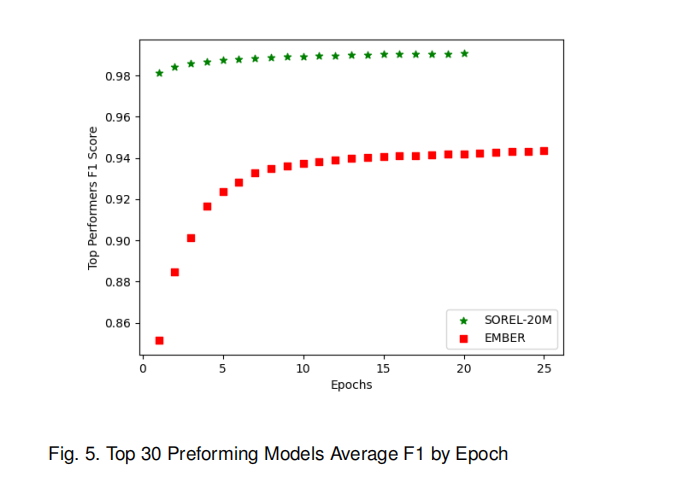
早停机制:记录模型在训练过程中任意 epoch 达到的最高 F1 分数作为其最终性能,避免因后期过拟合导致的性能误判,不同 epoch 下模型性能的变化趋势如下图所示。
3、超参数优化
超参数优化是 AutoML 的关键环节,通过自动化搜索最优超参数组合,提升模型性能并减少人工调参成本。该过程围绕超参数空间定义、优化策略选择及评估机制展开,具体包括以下内容,超参数搜索空间的参数设置如下图所示:
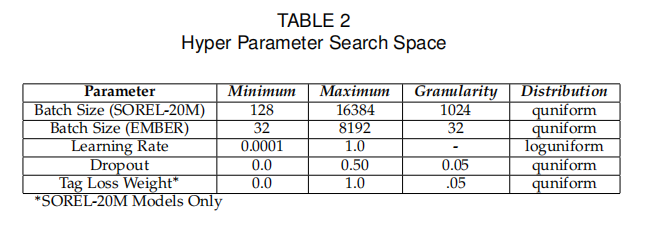
3.1 超参数空间的定义与分类
超参数空间是所有待优化超参数的取值范围集合,需根据模型类型和任务特点针对性设计:
模型结构相关超参数:
深度参数:如神经网络的层数(静态分析 FFNN 为 1-14 层,在线分析 CNN 为 5-7 层);
宽度参数:如每层神经元数量(FFNN 为 128-1920,以 128 为步长递增);
正则化参数:如 dropout 率(0-0.5,控制过拟合风险)。
训练过程相关超参数:
学习率:控制参数更新步长(静态分析采用 0.0001-1.0 的对数均匀分布,在线分析固定为 0.0005);
批大小:每次训练的样本数量(SOREL-20M 数据集为 128-16384,EMBER-2018 为 32);
训练轮次:数据集完整训练的次数(NAS 阶段为 10-25 轮,最终训练为 50-100 轮)。
优化器相关超参数: 如 Adam 优化器的 β1(动量参数,0.9)和 β2(二阶矩参数,0.999),采用默认值以减少搜索复杂度。
3.2 超参数优化策略
根据模型训练成本和搜索效率需求,采用两种优化策略:
TPE(Tree-structured Parzen Estimator)算法: 适用于静态分析的 FFNN 模型,通过构建概率模型预测超参数组合的性能:
分位数划分:将历史评估结果按性能分为 “优”“劣” 两组,分别建模;
密度估计:用核密度估计(KDE)拟合两组超参数的概率分布;
采样选择:优先从 “优” 分布中采样新超参数组合,平衡探索与利用。
固定超参数策略:
适用于在线分析的 CNN 模型,在 NAS 阶段确定核心超参数:
基于经验值固定关键参数(如学习率 0.0005、批大小 512)。 仅优化对性能影响显著的参数(如 dropout 率 0.3),减少搜索成本。
3.3 超参数评估与选择机制
通过多轮实验评估超参数组合的有效性,确保选出最优解:
评估指标:以 F1 分数为核心指标,兼顾精确率(减少误判)和召回率(减少漏检),更贴合恶意软件检测的实际需求;
早停机制:记录训练过程中任意 epoch 的最高 F1 分数,避免因过拟合导致的性能低估;
交叉验证:在小规模数据集(如 EMBER-2018)上采用 5 折交叉验证,减少数据随机性对评估的影响;
最终选择:选取在验证集上 F1 分数最高的超参数组合,用于最终模型训练,如下图所示最优超参数。
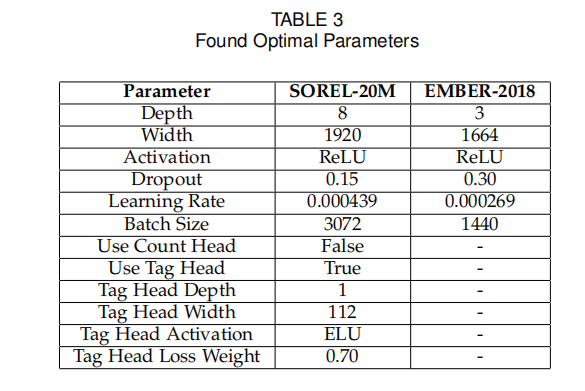
通过超参数优化,模型在不同数据集上的性能得到一定提升,例如静态分析中深度前馈神经网络(FFNN)的 F1 分数从 0.972 提升至 0.984,证明了自动化优化的有效性。
4、实验评估
本文通过静态和在线恶意软件检测两大场景的实验,验证了 AutoML 生成模型的性能,重点对比了其与现有手工设计模型、 state-of-the-art 模型的表现,评估指标包括准确率、F1 分数、AUC、TPR(真阳性率)、FPR(假阳性率)及检测延迟等,具体结果如下:
静态恶意软件检测性能:在 SOREL-20M(大型数据集)和 EMBER-2018(难分类小型数据集)上,AutoML 生成的 FFNN 模型性能与现有模型相当甚至更优。
SOREL-20M 数据集:AutoML 模型的 AUC 达 0.998,与 FFNN ensemble(0.998)持平,但在低 FPR(0.1%)下的 TPR(96.5%)显著高于对比模型(如 FFNN ensemble 未报告该指标,LightGBM ensemble 仅 0.0446);准确率 0.990,F1 分数 0.984,略高于 FFNN ensemble(准确率 0.988),证明其在大规模数据上的有效性,效果如下图所示。

EMBER-2018 数据集:该数据集因设计为 “难分类”,对模型鲁棒性要求更高。AutoML 模型的 AUC 为 0.984,准确率 0.958,F1 分数 0.958,超过 LightGBM ensemble(AUC 0.986 但准确率 0.940)和 Malconv w/ GCG(AUC 0.980);在低 FPR(0.1%)下的 TPR(41.7%)远高于 FFNN ensemble(未报告),体现出对复杂数据的适配性,效果如下图所示。
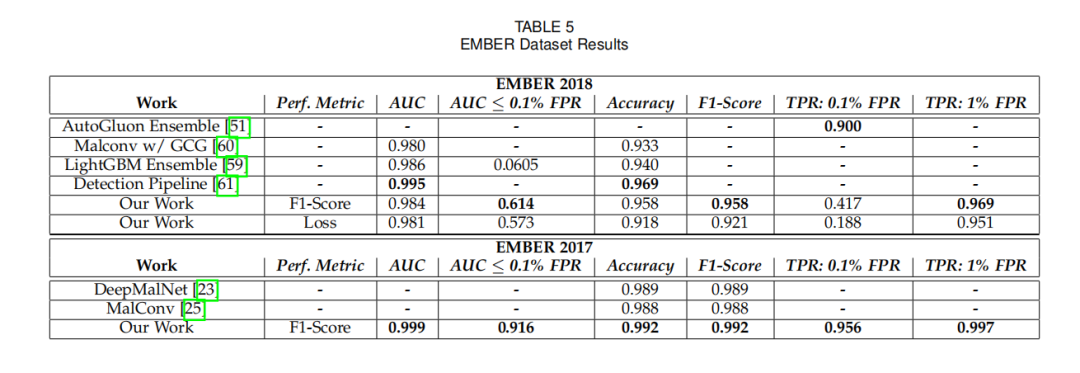
跨数据集验证(EMBER-2017):用 EMBER-2018 优化的 AutoML 模型在 EMBER-2017 上的准确率(0.989+)和 F1 分数(0.989+)与 DeepMalNet(0.989)、MalConv(0.988)相当,证明其泛化能力。
在线恶意软件检测性能:在自建的云 IaaS 环境数据集(含 “仅恶意软件” 和 “恶意软件 + 背景应用” 场景)中,AutoML 生成的 CNN 模型(基于 Darts 方法)性能优于 ResNet、DenseNet 等 state-of-the-art 模型,实验数据如下图所示。
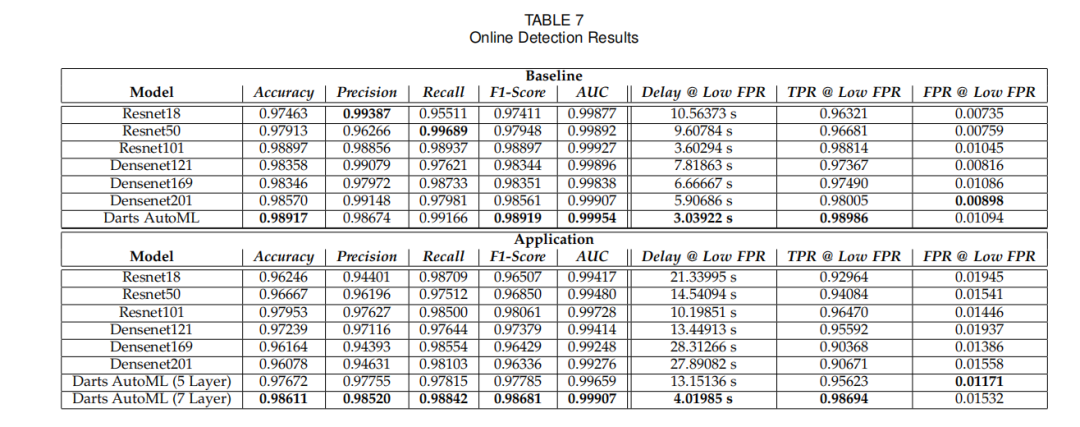
“仅恶意软件” 场景:AutoML 模型的 F1 分数达 0.989,AUC 0.99954,检测延迟仅 3.04 秒,显著优于 ResNet101(F1 0.981,延迟 3.6 秒)和 Densenet201(F1 0.986,延迟 5.91 秒);在低 FPR(1%)下的 TPR(98.99%)接近完美,漏检率极低。
“恶意软件 + 背景应用” 场景:该场景模拟真实环境的 “噪声”,对模型抗干扰能力要求更高。7 层 AutoML 模型的 F1 分数达 0.987,AUC 0.99907,检测延迟 4.02 秒,远超 ResNet101(F1 0.981,延迟 10.2 秒)和 Densenet121(F1 0.974,延迟 13.45 秒);低 FPR(1%)下的 TPR(98.69%)仍保持高位,证明其对复杂环境的强适应性。
关键发现:
数据规模与复杂度影响 AutoML 优势:在大型数据集(SOREL-20M)和含噪声的真实场景(在线 “恶意软件 + 背景应用”)中,AutoML 模型性能优势更显著,因能自动适配数据特点;
效率与性能的平衡:AutoML 模型虽训练成本较高(SOREL-20M 实验耗时≈5600 分钟),但生成的模型检测效率优异(在线场景延迟 < 5 秒),远低于人工调优模型;
评估指标的一致性:无论以 F1 分数还是损失函数为评估指标,AutoML 模型性能差异微小,证明其稳定性。
总体而言,AutoML 生成的模型在静态和在线恶意软件检测中均达到或超越现有模型性能,尤其在复杂数据场景中优势突出,验证了其在减少人工干预、提升检测效率上的价值。
5、总结
本文聚焦自动化机器学习(AutoML)在恶意软件检测中的应用,旨在通过自动化神经架构搜索(NAS)和超参数优化,解决深度学习模型依赖领域专家设计、适配性不足的问题。研究针对静态和在线两种场景,分别采用深度前馈神经网络(FFNN)和卷积神经网络(CNN),在 SOREL-20M、EMBER-2018 等静态数据集及自建的云 IaaS 在线数据集上开展实验。
结果显示,AutoML 生成的模型在静态检测中性能与手工设计模型相当(如 SOREL-20M 的 AUC 达 0.998,EMBER-2018 的 F1 分数 0.958);在在线场景中,尤其在 “恶意软件 + 背景应用” 的复杂环境下,其 F1 分数(0.987)和检测延迟(4.02 秒)显著优于 ResNet、DenseNet 等先进模型。
综上,AutoML 能有效减少人工干预,生成适配不同数据规模和复杂度的恶意软件检测模型,为静态分析和云环境在线检测提供了高效、低门槛的解决方案。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
